
В предыдущих своих заметках я описал основу, на которой строятся lock-free структуры данных, и базовые алгоритмы управления временем жизни элементов lock-free структур данных. Это была прелюдия к описанию собственно lock-free контейнеров. Но далее я столкнулся с проблемой: как построить дальнейший рассказ? Просто описывать известные мне алгоритмы? Это довольно скучно: много [псевдо-]кода, обилие деталей, важных, конечно, но весьма специфических. В конце концов, это есть в опубликованных работах, на которые я даю ссылки, и в гораздо более подробном и строгом изложении. Мне же хотелось рассказать интересно об интересных вещах, показать пути развития подходов к конструированию конкурентных контейнеров.
Хорошо, — подумал я, — тогда метод изложения должен быть такой: берем какой-то тип контейнера — очередь, map, hash map, — и делаем обзор известных на сегодняшний день оригинальных алгоритмов для этого типа контейнера. С чего начать? И тут я вспомнил о самой простой структуре данных — о стеке.
Казалось бы, ну что можно сказать о стеке? Это настолько тривиальная структура данных, что и говорить-то особо нечего.
Действительно, работ о реализации конкурентного стека не так уж и много. Но зато те, что есть, посвящены в большей степени подходам, нежели собственно стеку. Именно подходы меня и интересуют.
Lock-free стек
Стек — это, пожалуй, первая из структур данных, для которой был создан lock-free алгоритм. Считается, что его первым опубликовал Treiber в своей статье 1986 года, хотя есть сведения, что впервые этот алгоритм был описан в системной документации IBM/360.
Историческое отступление
Вообще, статья Treiber'а — своего рода Ветхий Завет, пожалуй, первая статья о lock-free структуре данных. Во всяком случае, более ранних мне не известно. Она до сих пор очень часто упоминается в списках литературы (reference) современных работ, видимо, как дань уважения к родоначальнику lock-free подхода.
Алгоритм настолько простой, что я приведу его адаптированный код из libcds (кому интересно — это интрузивный стек
cds::intrusive::TreiberStack):// m_Top – вершина стека bool push( value_type& val ) { back_off bkoff; value_type * t = m_Top.load(std::memory_order_relaxed); while ( true ) { val.m_pNext.store( t, std::memory_order_relaxed ); if (m_Top.compare_exchange_weak(t, &val, std::memory_order_release, std::memory_order_relaxed)) return true; bkoff(); } } value_type * pop() { back_off bkoff; typename gc::Guard guard; // Hazard pointer guard while ( true ) { value_type * t = guard.protect( m_Top ); if ( t == nullptr ) return nullptr ; // stack is empty value_type * pNext = t->m_pNext.load(std::memory_order_relaxed); if ( m_Top.compare_exchange_weak( t, pNext, std::memory_order_acquire, std::memory_order_relaxed )) return t; bkoff(); } }
Этот алгоритм неоднократно разобран по косточкам (например, тут), так что я повторяться не буду. Краткое описание алгоритма сводится к тому, что мы долбимся с помощью атомарного примитива CAS в
m_Top, пока не получим желаемый результат. Просто и довольно примитивно.Отмечу две интересных детали:
- Safe memory reclamation (SMR) необходим только в методе
pop, так как только там мы читаем поляm_Top. Вpushникакие поляm_Topне читаются (нет обращения по указателюm_Top), так что и защищать Hazard Pointer'ом ничего не нужно. Интересно это потому, что обычно SMR требуется во всех методах класса lock-free контейнера - Таинственный объект
bkoffи его вызовbkoff(), если CAS неуспешен
Вот на этом самом
bkoff я хотел бы остановиться подробнее.Back-off стратегии

Почему CAS неуспешен? Очевидно потому, что между прочтением текущего значения
m_Top и попыткой применить CAS какой-то другой поток успел изменить значение m_Top. То есть мы имеем типичный пример конкуренции. В случае сильной нагрузки (high contention), когда N потоков выполняют push/pop, только один из них выиграет, остальные N – 1 будут впустую потреблять процессорное время и мешать друг другу на CAS (вспомним протокол MESI кеша). Как разгрузить процессор при обнаружении такой ситуации? Можно отступить (back off) от выполнения основной задачи и сделать что-либо полезное или просто подождать. Именно для этого предназначены back-off стратегии.
Конечно, в общем случае «сделать что-либо полезное» у нас не получится, так как мы не имеем понятия о конкретной задаче, так что мы можем только подождать. Как ждать? Вариант со
sleep() отметаем — немногие операционные системы могут обеспечить нам столь малые тайм-ауты ожидания, да и накладные расходы на переключение контекста слишком велики — больше, чем время выполнения CAS.В академической среде популярностью пользуется стратегия экспоненциального back-off. Идея очень проста:
class exp_backoff { int const nInitial; int const nStep; int const nThreshold; int nCurrent; public: exp_backoff( int init=10, int step=2, int threshold=8000 ) : nInitial(init), nStep(step), nThreshold(threshold), nCurrent(init) {} void operator()() { for ( int k = 0; k < nCurrent; ++k ) nop(); nCurrent *= nStep; if ( nCurrent > nThreshold ) nCurrent = nThreshold; } void reset() { nCurrent = nInitial; } };
То есть мы в цикле выполняем
nop(), с каждым разом увеличивая длину цикла. Вместо nop() можно вызвать что-то более полезное, например, Проблема с экспоненциальным back-off проста — трудно подобрать хорошие параметры
nInitial, nStep, nThreshold. Эти константы зависят от архитектуры и от задачи. В коде выше значения для них по умолчанию взяты с потолка.Поэтому на практике довольно неплохим выбором для десктопных процессоров и серверов начального уровня будет
yield() back-off — переключение на другой поток. Тем самым мы отдаем свое время другим, более удачливым потокам, в надежде, что они сделают то, что им требуется, и не будут нам мешать (а мы — им).Стоит ли вообще применять back-off стратегии? Эксперименты показывают, что стоит: примененная в нужном узком месте правильная back-off стратегия может дать выигрыш в производительности lock-free контейнера в разы.
Рассмотренные back-off стратегии помогают решить проблему с неудачными CAS, но никак не способствуют выполнению основной задачи — операций со стеком. Можно ли каким-то образом объединить
push/pop и back-off, чтобы back-off стратегия активно помогала выполнению операции?Elimination back-off
Рассмотрим проблему неудачного CAS в
push/pop с другой стороны. Почему CAS неудачен? Потому что другой поток изменил m_Top. А что делает этот другой поток? Выполняет push() или pop(). Теперь заметим, что операции push и pop для стека комплементарны: если один поток выполняет push(), а другой в это же время — pop(), то в принципе вообще не имеет смысла обращаться к вершине стека m_Top: push-поток мог бы просто передать свои данные pop-потоку, при этом основное свойство стека — LIFO – не нарушается. Остается придумать, как свести вместе оба эти потока, минуя вершину стека.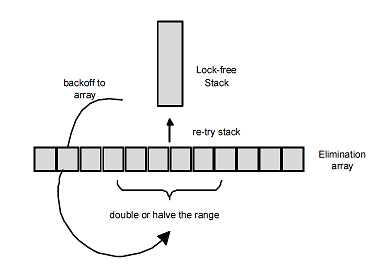
В 2004 году Hendler, Shavit и Yerushalmi предложили модификацию алгоритма Treiber'а, в котором задача передачи данных между push- и pop-потоками без участия вершины стека решается с помощью специальной back-off стратегии, названной ими исключающей back-off стратегией (elimination back-off, я бы перевел ещё как поглощающая back-off стратегия).
Имеется массив elimination array размером N (N — небольшое число). Этот массив является членом класса стека. При неуспехе CAS, уходя в back-off, поток создает дескриптор своей операции (
push или pop) и случайным образом выбирает произвольную ячейку этого массива. Если ячейка пуста, он записывает в неё указатель на свой дескриптор и выполняет обычный back-off, например, экспоненциальный. В этом случае поток можно назвать пассивным.Если же выбранная ячейка уже содержит указатель на дескриптор P операции какого-то другого (пассивного) потока, то поток (назовем его активным) проверяет, что это за операция. Если операции комплементарны —
push и pop, — то они взаимно поглощаются: - если активный поток выполняет
push, то он записывает в дескриптор P свой аргумент, передавая таким образом его в операциюpopпассивного потока; - если активный поток выполняет
pop, то он читает из дескриптора P аргумент комплементарной операцииpush.
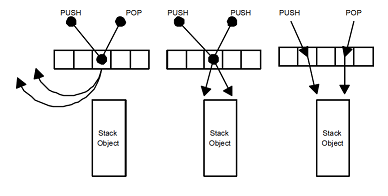
Затем активный поток помечает запись в ячейке elimination array как обработанную, чтобы пассивный поток при выходе из back-off увидел, что кто-то волшебным образом выполнил его работу. В результате активный и пассивный потоки выполнят свои операции без обращения к вершине стека.
Если же в выбранной ячейке elimination array операция та же самая (ситуация push-push или pop-pop), — не повезло. В этом случае активный поток выполняет обычный back-off и далее пытается выполнить свой
push/pop как обычно, — CAS вершины стека.Пассивный же поток, окончив back-off, проверяет свой дескриптор в elimination array. Если дескриптор имеет отметку, что операция выполнена, то есть нашелся другой поток с комплементарной операцией, то пассивный поток успешно завершает свой
push/pop.Все вышеописанные действия выполняются в lock-free манере, без каких-либо блокировок, поэтому реальный алгоритм сложнее описанного, но смысл от этого не меняется.
Дескриптор содержит код операции —
push или pop, — и аргумент операции: в случае push — указатель на добавляемый элемент, в случае pop поле указателя остается пустым (nullptr), в случае успеха elimination в него записывается указатель на элемент поглощающей операции push.Elimination back-off позволяет значительно разгрузить стек при высокой нагрузке, а при малой, когда CAS вершины стека почти всегда успешен, такая схема не привносит вообще никакого оверхеда. Алгоритм требует тонкой настройки, заключающейся в выборе оптимального размера elimination array, что зависит от задачи и реальной нагрузки. Можно также предложить адаптивный вариант алгоритма, когда размер elimination array изменяется в небольших пределах в процессе работы, подстраиваясь под нагрузку.
В случае несбалансированности, когда операции
push и pop идут пачками — много push без pop, затем много pop без push, — алгоритм не даст какого-либо ощутимого выигрыша, хотя и особого проигрыша в производительности быть не должно по сравнению с классическим алгоритмом Treiber'а. Flat combining
До сих пор мы говорили о lock-free стеке. Рассмотрим теперь обычный lock-based стек:
template <class T> class LockStack { std::stack<T *> m_Stack; std::mutex m_Mutex; public: void push( T& v ) { m_Mutex.lock(); m_Stack.push( &v ); m_Mutex.unlock(); } T * pop() { m_Mutex.lock(); T * pv = m_Stack.top(); m_Stack.pop() m_Mutex.unlock(); return pv; } };
Очевидно, что при конкурентом выполнении производительность его будет весьма низка — все обращения к стеку сериализуются на мьютексе, всё выполняется строго последовательно. Можно ли как-нибудь повысить performance?
Если N потоков одновременно обращаются к стеку, только один из них захватит мьютекс, остальные будут дожидаться его освобождения. Но вместо того, чтобы пассивно ждать на мьютексе, ждущие потоки могли бы анонсировать свои операции, как в elimination back-off, а поток-победитель (владелец мьютекса) мог бы помимо своей работы выполнить и задания от своих собратьев. Эта идея легла в основу подхода flat combining, описанного в 2010 году и развивающегося и по сей день.
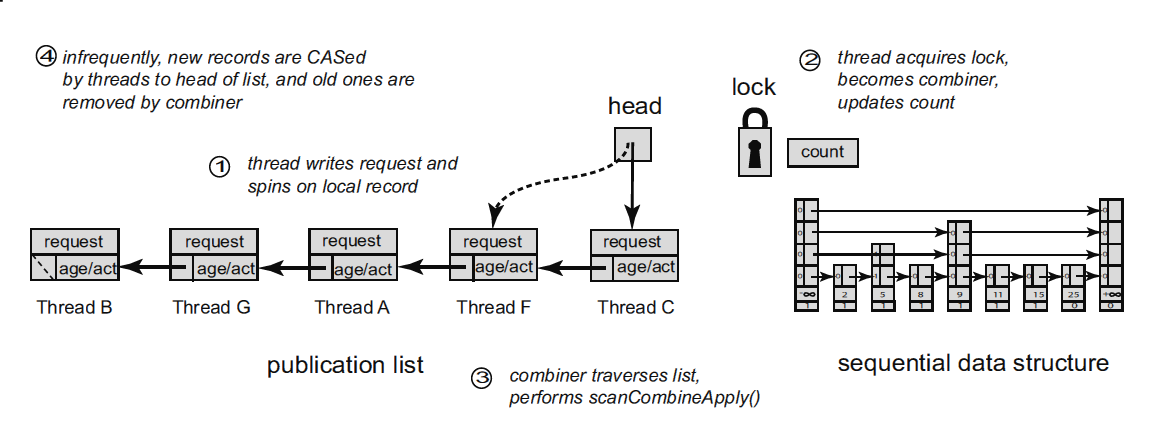
Идею подхода flat combining можно описать следующим образом. С каждой структурой данных, в нашем случае со стеком, связан мьютекс и список анонсов (publication list) размером, пропорциональным количеству потоков, работающих со стеком. Каждый поток при первом обращении к стеку добавляет к списку анонсов свою запись, расположенную в thread local storage (TLS). При выполнении операции поток публикует в своей записи запрос — операцию (
push или pop) и её аргументы — и пытается захватить мьютекс. Если мьютекс захвачен, поток становится комбайнером (combiner, не путать с комбайнёром): он просматривает список анонсов, собирает все запросы из него, выполняет их (в случае со стеком здесь может применяться поглощение (elimination), рассмотренное ранее), записывает результат в элементы списка анонсов и наконец освобождает мьютекс. Если же попытка захвата мьютекса не удалась, поток ожидает (spinning) на своем анонсе, когда комбайнер выполнит его запрос и поместит результат в запись анонса.Список анонсов построен таким образом, чтобы уменьшить накладные расходы на управление им. Ключевым моментом является то, что список анонсов редко изменяется, иначе мы получим ситуацию, когда к стеку прикручен сбоку lock-free publication list, что вряд ли как-то ускорит сам стек. Запросы на операцию вносятся в уже существующую запись списка анонсов, которая, напомню, является собственностью потоков и находится в TLS. Некоторые записи списка могут иметь статус «empty», означающий, что соответствующий поток не выполняет в настоящий момент никаких действий со структурой данных (стеком). Время от времени комбайнер прореживает список анонсов, исключая давно неактивные записи (поэтому записи списка должны иметь какой-то timestamp), тем самым уменьшая время просмотра списка.
Вообще, flat combining является очень общим подходом, который с успехом распространяется на сложные lock-free структуры данных, позволяет комбинировать разные алгоритмы, — например, добавлять elimination back-off в реализацию flat combining-стека. Реализация flat combining на C++ в библиотеке общего пользования также является довольно интересной задачей: дело в том, что в исследовательских работах список анонсов является, как правило, атрибутом каждого объекта-контейнера, что может быть слишком накладно в реальной жизни, так как каждый контейнер должен иметь свою запись в TLS. Хотелось бы иметь более общую реализацию с единым publication list для всех объектов flat combining, но при этом важно не потерять в скорости.
История развивается по спирали
Интересно, что идея анонсирования своей операции перед её выполнением восходит к началу исследований lock-free алгоритмов: в начале 1990-х годов были предприняты попытки построения общих методов преобразования традиционных lock-based структур данных в lock-free. С точки зрения теории эти попытки успешны, но на практике получаются медленные тяжелые lock-free алгоритмы. Идея этих общих подходов как раз и была — анонсировать операцию перед выполнением, чтобы конкурирующие потоки увидели её и помогли её выполнить. На практике такая «помощь» была скорее помехой: потоки выполняли одну и ту же операцию одновременно, толкаясь и мешая друг другу.
Стоило немного переставить акценты — с активной помощи до пассивного делегирования работы другому, более удачливому потоку — и получился быстрый метод flat combining.
Стоило немного переставить акценты — с активной помощи до пассивного делегирования работы другому, более удачливому потоку — и получился быстрый метод flat combining.
Заключение
Удивительно, что такая простая структура данных, как стек, где и писать, казалось бы, не о чем, позволила продемонстрировать столько интересных подходов к разработке конкурентных структур данных!
Back-off стратегии применимы повсеместно при конструировании lock-free алгоритмов: как правило, каждая операция заключена в бесконечный цикл по принципу «делаем пока не удастся», а в конце тела цикла, то есть именно тогда, когда итерация не удалась, не лишним будет поставить back-off, который может уменьшить давление на критические данные контейнера при большой нагрузке.
Elimination back-off – менее общий подход, применимый для стека и, в меньшей степени, для очереди.
Получивший развитие в последние годы flat combining является особым трендом при построении конкурентных контейнеров — как lock-free, так и fine grained lock-based.
Надеюсь, мы ещё встретимся с этими техниками в дальнейшем.
Lock-free структуры данных
