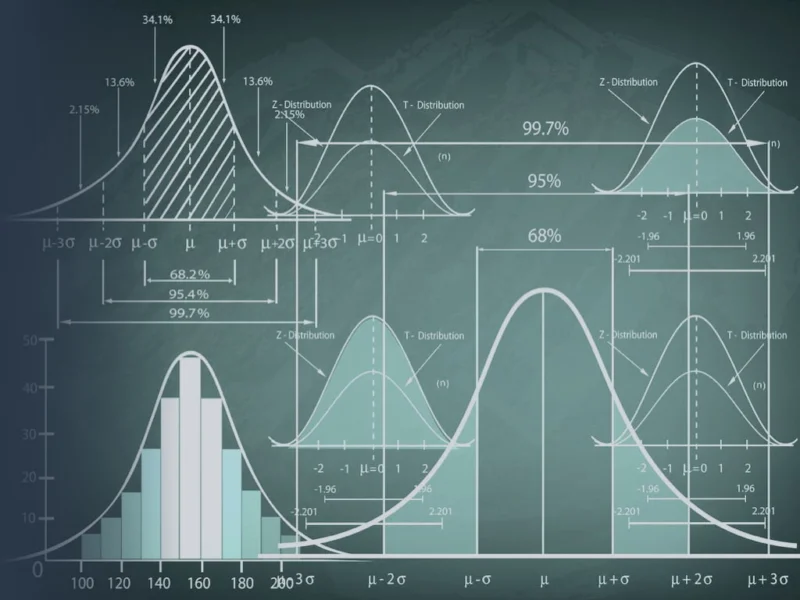
В этой статье вы узнаете
-В чем суть глубокого обучения
-Для чего нужны функции активации
-Что такое FCNN
-Какие задачи может решать FCNN
-Каковы недостатки FCNN и с помощью чего с ними бороться

Всем салют! Меня зовут Иван, начинаю в DS и ML

2023 год можно назвать годом ИИ, особенно с учетом хайпа вокруг ChatGPT. Но действительно ли ИИ — панацея? Сможет ли он лишить работы людей? Давайте разберемся в этом вопросе.
 Привет, Хаброжители!
Привет, Хаброжители!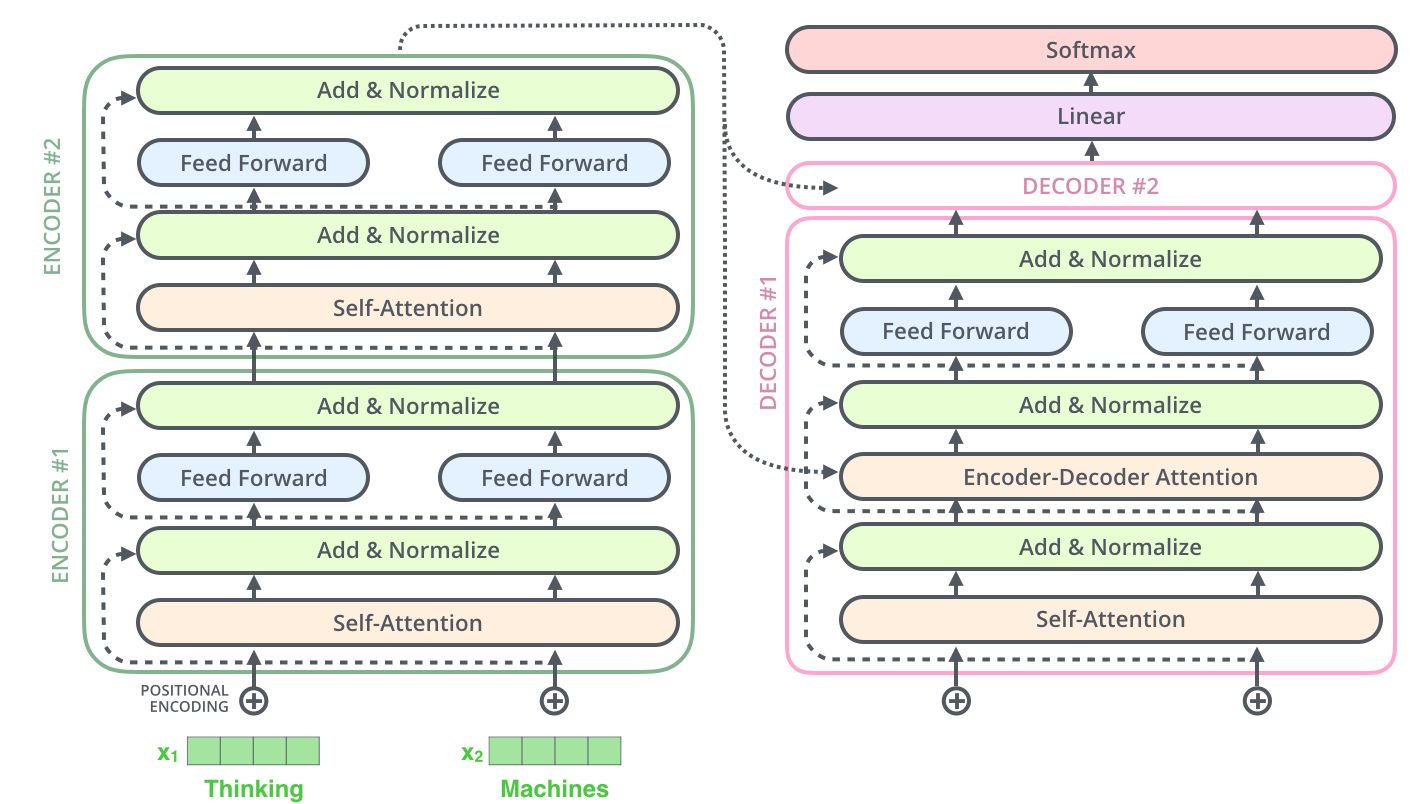
В этом посте я представлю подробный пример математики, используемой внутри модели трансформера, чтобы вы получили хорошее представление о работе модели. Чтобы пост был понятным, я многое упрощу. Мы будем выполнять довольно много вычислений вручную, поэтому снизим размерность модели. Например, вместо эмбеддингов из 512 значений мы используем эмбеддинги из 4 значений. Это позволит упростить понимание вычислений. Мы используем произвольные векторы и матрицы, но при желании вы можете выбрать собственные значения.
Как вы увидите, математика модели не так уж сложна. Сложность возникает из-за количества этапов и количества параметров. Перед прочтением этой статьи я рекомендую прочитать пост Illustrated Transformer (или читать их параллельно) [перевод на Хабре]. Это отличный пост, объясняющий модель трансформера интуитивным (и наглядным!) образом, поэтому я не буду объяснять то, что уже объяснено в нём. Моя цель заключается в том, чтобы объяснить, как работает модель трансформера, а не что это такое. Если вы хотите углубиться в подробности, то изучите известную статью Attention is all you need [перевод на Хабре: первая и вторая части].

Статья о том, как в суде при помощи разработчиков удалось оспорить кредитный договор, оформленный на человека жуликами.
Автор статьи выражает благодарность разработчикам Роману и Александру. Специалисты проделали огромную и кропотливую работу, нашли выход в безнадежной (с точки зрения юристов) ситуации.

Как и в большинстве компаний, наш основной инструмент для принятия решений — это A/B-тесты. Мы уделяем им большое внимание: проверяем на корректность все используемые критерии, пытаемся сделать результаты более интерпретируемыми, а также увеличиваем мощность критериев. В текущем посте я хочу рассказать, как дополнительно увеличить мощность, используя машинное обучение.

Это вторая часть статьи о том, как улучшить A/B-тесты. Здесь я подробно остановлюсь на методах увеличения мощности: поговорим про CUPED, бутстрап-критерии, стратификацию и парную стратификацию.

Всем привет! Я Дмитрий Лунин, работаю аналитиком в команде ценообразования Авито. Наш юнит отвечает за все платные услуги площадки. Наша основная задача — сделать цены на них оптимальными.
Мы не только пытаемся максимизировать выручку Авито, но и думаем про счастье пользователей. Если установить слишком большие цены, то пользователи возмутятся и начнут уходить с площадки, а если сделать цены слишком маленькими, то мы недополучим часть оптимальной выручки. Низкие цены также увеличивают количество «спамовых» объявлений, которые портят поисковую выдачу пользователям. Поэтому нам очень важно уметь принимать математически обоснованные решения — любая наша ошибка напрямую отразится на выручке и имидже компании.
Одним из инструментов для решения наших задач является A/B-тестирование.
pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.
pandas, но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
В этой статье я расскажу про аспекты Golang, на которые стоит обратить внимание в первую очередь, а также приведу ссылки на современные ресурсы для изучения этого языка программирования, которые лучше всего подойдут начинающим разработчикам.

What's up guys!
В этой статье мы поговорим про NumPy. Это статья-шпаргалка для начинающих пользователей NumPy, надеюсь она будет вам полезна.

What”s up guys?
Математика — как говорили в школе — царица наук, а ещё очень важный и полезный скилл для программиста.
В этой статье мы поговорим о книгах и ресурсах по изучению математики, которые на мой достаточно полезны.

What’s up guys?
Computer Science – грубо говоря - наука о компьютерах. Она объединяет всё, что программист должен знать о компьютерах и работе с ними для создания эффективных программ и алгоритмов. Программисты бывают разные, и как правило отличаются только языком, на котором пишут, но всех их объединяет необходимость понимать основы этой науки для понимания того, как работает компьютер.
В этой статье мы поговорим о самых полезных книгах по Computer Science для самых разных уровней, которые дадут вам понимание того, как работают компьютеры и всё, что с этим связанно. Предлагаю незамедлительно начинать, и начнём мы с книг для новичков (по моему мнению).
«Плохие программисты думают о коде. Хорошие программисты думают о структурах данных и их взаимосвязях», — Линус Торвальдс, создатель Linux.

Привет, Хабр! Перевели для вас статью программиста-самоучки, в арсенале которого — три десятка языков программирования. Надеемся, она вдохновит вас поделиться собственными историями становления в кодинге не меньше, чем нас в beeline cloud. Приятного чтения!
Всё началось в далёком 1997 году. С тех пор прошло более 25 лет. Свои первые программы я писал еще под ОС Windows 95 и Windows 98. На тот момент мне было около 12 лет – как раз тот возраст, в котором многие из моего поколения начинали знакомство с программированием. Первым моим языком был Logo, используемый в MicroWorlds от LCSI (Logo Computer Systems Inc). Я получил эту программу от родителей в подарок.
Исчерпав возможности Logo в ограниченной среде MicroWorlds, я перешел на Visual Basic. По очень простой причине — он был мне понятен и к тому же доступен прямо в Microsoft Office. Visual Basic 6 стал первым «настоящим» языком программирования, с которым я познакомился.
В предыдущих статьях, использовался только один из видов слоев нейронной сети – полносвязанные (dense, fully-connected), когда каждый нейрон исходного слоя имеет связь со всеми нейронами из предыдущих слоев.
Чтобы обработать, например, черно-белое изображение размером 24x24, мы должны были бы превратить матричное представление изображения в вектор, который содержит 24x24 элементов. Как можно вдуматься, с таким преобразованием мы теряем важный атрибут – взаимное расположение пикселей в вертикальном и горизонтальном направлении осей, а также, наверное, в большинстве случаев пиксел, находящийся в верхнем левом углу изображения вряд ли имеет какое-то логически объяснимое влияние друг на друга в большинстве случаев.
Для исключения этих недостатков – для обработки изображений используют сверточные слои (convolutional layer, CNN).
Основным назначением CNN является выделение из исходного изображения малых частей, содержащих опорные (характерные) признаки, такие как ребра, контуры, дуги или грани. На следующих уровнях обработки из этих ребер можно распознать более сложные повторяемые фрагменты текстур (окружности, квадратные фигуры и др.), которые дальше могут сложиться в еще более сложные текстуры (часть лица, колесо машины и др.).
Например, рассмотрим классическую задачу – распознавание изображения цифр. Каждая цифра имеет свой набор характерных для них фигур (окружности, линии). В тоже самое время каждую окружность или линию можно составить из более мелких ребер (рисунок 1)