

User
Format preserving encryption или как правильно шифровать номера кредиток
5 min
Tutorial
Привет, %username%! Сегодня у нас немного пятничная криптотема. В марте 2016 года вышла интересная публикация от NIST под номером 800-38G (pdf) и с очень интересным называнием Recommendation for Block Cipher Modes of Operation:Methods for Format-Preserving Encryption, в которой отписываются два алгоритма, позволяющие не менять формат данных при шифровании. То есть, если это будет номер кредитки 1234-3456-4567-6678, то после шифрования он тоже останется номером, просто другим. Например 6243-1132-0738-9906. И это не простой xor, там AES и вообще всё серьезно. Давайте немного поговорим о FPE вообще, и об одной из реализаций в частности.
learnopengl. Урок 1.1 — OpenGL
7 min
Tutorial
Translation
 Здравствуйте. Несколько недель назад я начинал серию переводов статей по изучению OpenGL. Но на 4 статье один хабровчанин заметил, что мои переводы могут нарушать лицензию, по которой распространяются учебные материалы, предоставленные в исходной статье. И действительно, мои переводы нарушали лицензию. Для разрешения этой проблемы я обратился к авторам того набора уроков, но так и не смог добиться нормального ответа. По этой причине я связался с автором другого, не менее (а возможно даже и более) крутого, набора уроков по OpenGL: Joey de Vries. И он дал полное разрешение на перевод его набора уроков. Его уроки гораздо более обширные, чем прошлый набор, поэтому эти переводы растянутся на долго. И я обещаю, будет интересно. Заинтересовавшихся прошу под кат.
Здравствуйте. Несколько недель назад я начинал серию переводов статей по изучению OpenGL. Но на 4 статье один хабровчанин заметил, что мои переводы могут нарушать лицензию, по которой распространяются учебные материалы, предоставленные в исходной статье. И действительно, мои переводы нарушали лицензию. Для разрешения этой проблемы я обратился к авторам того набора уроков, но так и не смог добиться нормального ответа. По этой причине я связался с автором другого, не менее (а возможно даже и более) крутого, набора уроков по OpenGL: Joey de Vries. И он дал полное разрешение на перевод его набора уроков. Его уроки гораздо более обширные, чем прошлый набор, поэтому эти переводы растянутся на долго. И я обещаю, будет интересно. Заинтересовавшихся прошу под кат.Также я встал на распутье: либо я опишу все основы вроде создания окна и контекста в одной статье, чтобы не плодить статьи, но в таком случае такую огромную статью не всякий осилит; либо я также как и раньше буду переводить, опираясь на иерархию оригинала. Я решил выбрать второй вариант.
На счет уроков по Vulkan: к сожалению мне тяжело сейчас написать уроки по данному API по причине скудной видеокарты на данный момент, которая просто не поддерживает Vulkan API, поэтому уроки по данному API будут только после обновления видеокарты.
[ В закладки ] Алгоритмы и структуры данных в ядре Linux, Chromium и не только
9 min
Translation
Многие студенты, впервые сталкиваясь с описанием какой-нибудь хитроумной штуки, вроде алгоритма Кнута – Морриса – Пратта или красно-чёрных деревьев, тут же задаются вопросами: «К чему такие сложности? И это, кроме авторов учебников, кому-нибудь нужно?». Лучший способ доказать пользу алгоритмов – это примеры из жизни. Причём, в идеале – конкретные примеры применения широко известных алгоритмов в современных, повсеместно используемых, программных продуктах.

Посмотрим, что можно обнаружить в коде ядра Linux, браузера Chromium и ещё в некоторых проектах.
Посмотрим, что можно обнаружить в коде ядра Linux, браузера Chromium и ещё в некоторых проектах.
Как отлаживать Android ядро без UART, JTAG и прочих
4 min
Довольно часто разработчики ядер под Android устройства сталкиваются с тем, что собранное из исходников ядро просто напросто не работает. И при этом часто разработчик, собравший ядро, не имеет никаких специальных средств для отладки. В данной ситуации без kmsg логов довольно трудно что либо сделать. Конечно же в Linux ядре уже имеется несколько способов копирования содержимого kmsg буфера в специальную область памяти, но если вам интересно узнать ещё об одном способе, то прошу под кат.
Так вы думаете, что знаете Const?
11 min
Tutorial
Translation
От переводчика:
Предлагаю вам перевод поста из блога Мэтта Стэнклиффа (Matt Stancliff), автора нашумевшей на хабре статьи Советы о том, как писать на С в 2016 году.
Здесь Мэтт делится знаниями о квалификаторе типа
Приятного чтения.
Думаете, что вы знаете все правила использования
Предлагаю вам перевод поста из блога Мэтта Стэнклиффа (Matt Stancliff), автора нашумевшей на хабре статьи Советы о том, как писать на С в 2016 году.
Здесь Мэтт делится знаниями о квалификаторе типа
const. Несмотря на вызывающий заголовок, возможно, многое из того что здесь описывается будет вам известно, но, надеюсь, и что-нибудь новое тоже найдется.Приятного чтения.
Думаете, что вы знаете все правила использования
const для С? Подумайте еще раз.Жаргон функционального программирования
10 min
Translation

У функционального программирования много преимуществ, и его популярность постоянно растет. Но, как и у любой парадигмы программирования, у ФП есть свой жаргон. Мы решили сделать небольшой словарь для всех, кто знакомится с ФП.
В примерах используется JavaScript ES2015). (Почему JavaScript?)
Работа над материалом продолжается; присылайте свои пулл-реквесты в оригинальный репозиторий на английском языке.
В документе используются термины из спецификации Fantasy Land spec по мере необходимости.
Arity (арность)
Количество аргументов функции. От слов унарный, бинарный, тернарный (unary, binary, ternary) и так далее. Это необычное слово, потому что состоит из двух суффиксов: "-ary" и "-ity.". Сложение, к примеру, принимает два аргумента, поэтому это бинарная функция, или функция, у которой арность равна двум. Иногда используют термин "диадный" (dyadic), если предпочитают греческие корни вместо латинских. Функция, которая принимает произвольное количество аргументов называется, соответственно, вариативной (variadic). Но бинарная функция может принимать два и только два аргумента, без учета каррирования или частичного применения.
Оптимизация кода: процессор
Hard
18 min
Все программы должны быть правильными, но некоторые программы должны быть быстрыми. Если программа обрабатывает видео-фреймы или сетевые пакеты в реальном времени, производительность является ключевым фактором. Недостаточно использовать эффективные алгоритмы и структуры данных. Нужно писать такой код, который компилятор легко оптимизирует и транслирует в быстрый исполняемый код.
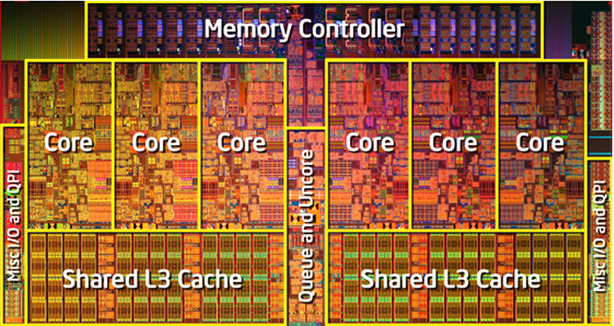
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
О выравнивании памяти на ARM процессорах на простом примере
1 min
Допустим у нас есть функция, которая принимает в себя указатель. Мы знаем, что в указателе лежит нуль-терминальная строка, а за ней 4-байтное целое. Задача — вывести в консоль строку и целое. Решить можно вот так:
Довольно тривиальная задача, не так ли? Проверяем на компе (x86), все ОК. Загружаем на борду с ARM. И, не успев выстрелить себе в ногу, наступаем на грабли. В зависимости от содержания строки, целое значение выводится то нормальным, то кривым. Поверяем указатели, проверяем память, на которые они указывают. Все в норме.
void foo(void* data_ptr)
{
//Ставим указатель на строку на начало данных
char* str = (char*)data_ptr;
//А указатель на целое смещаем на длину строки и еще один байт
int* value = (int*)(str+strlen(str)+1);
//и выводим содержимое указателей
printf("%s %d", str, *value);
}
Довольно тривиальная задача, не так ли? Проверяем на компе (x86), все ОК. Загружаем на борду с ARM. И, не успев выстрелить себе в ногу, наступаем на грабли. В зависимости от содержания строки, целое значение выводится то нормальным, то кривым. Поверяем указатели, проверяем память, на которые они указывают. Все в норме.
Миф о RAM и O(1)
7 min
Translation

Городская библиотека Стокгольма. Фото minotauria.
В этой статье я хочу рассказать о том, что оценивать время обращения к памяти как O(1) — это очень плохая идея, и вместо этого мы должны использовать O(√N). Вначале мы рассмотрим практическую сторону вопроса, потом математическую, на основе теоретической физики, а потом рассмотрим последствия и выводы.
Введение
Если вы изучали информатику и анализ алгоритмической сложности, то знаете, что проход по связному списку это O(N), двоичный поиск это O(log(N)), а поиск элемента в хеш-таблице это O(1). Что, если я скажу вам, что все это неправда? Что, если проход по связному списку на самом деле O(N√N), а поиск в хеш-таблице это O(√N)?
Не верите? Я вас сейчас буду убеждать. Я покажу, что доступ к памяти это не O(1), а O(√N). Этот результат справедлив и в теории, и на практике. Давайте начнем с практики.
Измеряем
Давайте сначала определимся с определениями. Нотация “О” большое применима ко многим вещам, от использования памяти до запущенных инструкций. В рамках этой статьи мы O(f(N)) будет означать, что f(N) — это верхняя граница (худший случай) по времени, которое необходимо для получения доступа к N байтов памяти (или, соответственно, N одинаковых по размеру элементов). Я использую Big O для анализа времени, но не операций, и это важно. Мы увидим, что центральный процессор подолгу ждет медленную память. Лично меня не волнует, что делает процессор пока ждет. Меня волнует лишь время, как долго выполняется та или иная задача, поэтому я ограничиваюсь определением выше.
Const и оптимизации в C
3 min
Translation
Сегодня на /r/C_Programming задали вопрос о влиянии const в C на оптимизацию. Я много раз слышал варианты этого вопроса в течении последних двадцати лет. Лично я обвиняю во всём именование const.
Биткойн — деньги для всех
71 min
Translation
Перевод книги Adam Tepper «Bitcoin — The People's Money». Книга представляет собой отличное введение в биткойн «с нуля», но может оказаться полезной и тем, кто уже разбирается в теме.
Let the Holy War begin: Java vs С++
19 min

В преддверии Joker 2016 мы накатали пост про Java Performance, который вызвал бурю эмоций у читателей. Дабы вбросить топлива в вентилятор и попытаться все-таки прийти к какому-то единому решению, мы решили привлечь экспертов из разных «лагерей»:
- Дмитрий Нестерук. Эксперт по .NET, С++ и инструментам разработки, автор курсов по технологиям и математике, квант.
- Андрей Паньгин. Ведущий программист компании Одноклассники, специализирующийся на высоконагруженных бэкендах. Знает JVM как свои пять пальцев, поскольку ранее на протяжении нескольких лет разрабатывал виртуальную машину HotSpot в Sun Microsystems и Oracle. Любит ассемблер и низкоуровневое системное программирование.
- Владимир Ситников. Десять лет работает над производительностью и масштабируемостью NetCracker OSS — ПО, используемого операторами связи для автоматизации процессов управления сетью и сетевым оборудованием. Увлекается вопросами производительности Java и Oracle Database.
- Олег Краснов. CTO компании SEMrush и адепт ANSI C.
Когда «О» большое подводит
8 min
Translation
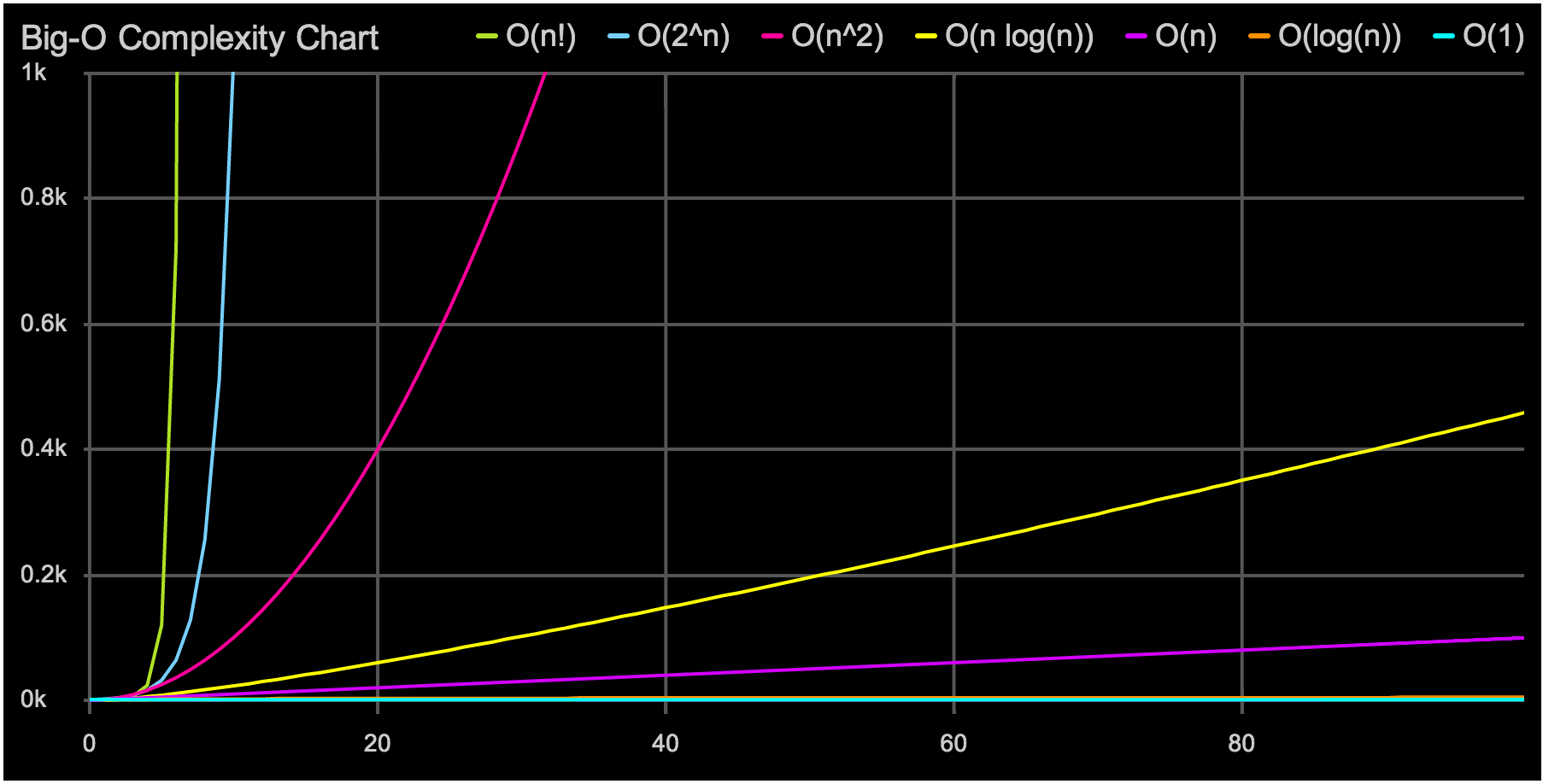
"О" большое — это отличный инструмент. Он позволяет быстро выбрать подходящую структуру данных или алгоритм. Но иногда простой анализ "О" большого может обмануть нас, если не подумать хорошенько о влиянии константных множителей. Пример, который часто встречается при программировании на современных процессорах, связан с выбором структуры данных: массив, список или дерево.
Память, медленная-медленная память
В начале 1980-х время, необходимое для получения данных из ОЗУ и время, необходимое для произведения вычислений с этими данными, были примерно одинаковым. Можно было использовать алгоритм, который случайно двигался по динамической памяти, собирая и обрабатывая данные. С тех пор процессоры стали производить вычисления в разы быстрее, от 100 до 1000 раз, чем получать данные из ОЗУ. Это значит, что пока процессор ждет данных из памяти, он простаивает сотни циклов, ничего не делая. Конечно, это было бы совсем глупо, поэтому современные процессоры содержат несколько уровней встроенного кэша. Каждый раз когда вы запрашиваете один фрагмент данных из памяти, дополнительные прилегающие фрагменты памяти будут записаны в кэш процессора. В итоге, при последовательном проходе по памяти можно получать к ней доступ почти настолько же быстро, насколько процессор может обрабатывать информацию, потому что куски памяти будут постоянно записываться в кэш L1. Если же двигаться по случайным адресам памяти, то зачастую кэш использовать не получится, и производительность может сильно пострадать. Если хотите узнать больше, то доклад Майка Актона на CppCon — это отличная отправная точка (и отлично проведенное время).
Статическая и динамическая типизация
13 min
Translation
Эта статья рассказывает о разнице между статически типизированными и динамически типизированными языками, рассматривает понятия "сильной" и "слабой" типизации, и сравнивает мощность систем типизации в разных языках. В последнее время наблюдается четкое движение в сторону более строгих и мощных систем типизации в программировании, поэтому важно понимать о чем идет речь когда говорят о типах и типизации.

Тип — это коллекция возможных значений. Целое число может обладать значениями 0, 1, 2, 3 и так далее. Булево может быть истиной или ложью. Можно придумать свой тип, например, тип "ДайПять", в котором возможны значения "дай" и "5", и больше ничего. Это не строка и не число, это новый, отдельный тип.
Статически типизированные языки ограничивают типы переменных: язык программирования может знать, например, что x — это Integer. В этом случае программисту запрещается делать x = true, это будет некорректный код. Компилятор откажется компилировать его, так что мы не сможем даже запустить такой код. Другой статически типизированный язык может обладать другими выразительными возможностями, и никакая из популярных систем типов не способна выразить наш тип ДайПять (но многие могут выразить другие, более изощренные идеи).
Динамически типизированные языки помечают значения типами: язык знает, что 1 это integer, 2 это integer, но он не может знать, что переменная x всегда содержит integer.
Среда выполнения языка проверяет эти метки в разные моменты времени. Если мы попробуем сложить два значения, то она может проверить, являются ли они числами, строками или массивами. Потом она сложит эти значения, склеит их или выдаст ошибку, в зависимости от типа.
Анонс конференции Linux Piter 2016 — второй международной Linux-конференции в России
3 min
Сейчас мы активно готовим вторую конференцию Linux Piter и, пока формируется список докладчиков, давайте вспомним как прошла её первая часть.

IT-студент с жаждой путешествий? Пора в магистратуру
9 min
Добрый день, Хабр!
Я IT-студентка, выпускница одного из старейших университетов Москвы, внезапно нашедшая себя в магистратуре в Европе. Не хочу агитировать за "утечку мозгов" или нечто подобное, правда, но по воле случая много знакомых спрашивали о процессе application, поэтому мне показалась интересной идея поделиться годом поисков и наработанными скиллами с более широкой аудиторией. Итак, поехали.
Используем Secure Boot в Linux на всю катушку
17 min
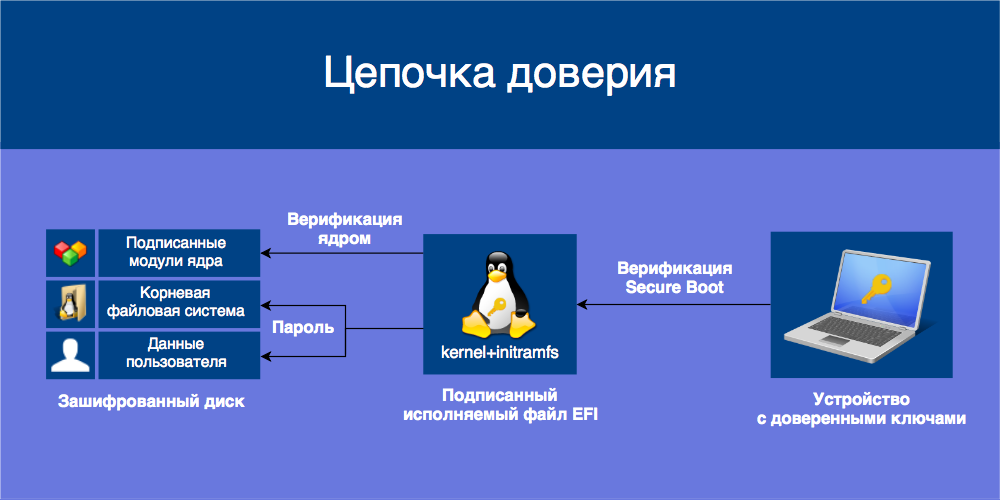
Технология Secure Boot нацелена на предотвращение исполнения недоверенного кода при загрузке операционной системы, то есть защиту от буткитов и атак типа Evil Maid. Устройства с Secure Boot содержат в энергонезависимой памяти базу данных открытых ключей, которыми проверяются подписи загружаемых UEFI-приложений вроде загрузчиков ОС и драйверов. Приложения, подписанные доверенным ключом и с правильной контрольной суммой, допускаются к загрузке, остальные блокируются.
Более подробно о Secure Boot можно узнать из цикла статей от CodeRush.
Чтобы Secure Boot обеспечивал безопасность, подписываемые приложения должны соблюдать некоторый «кодекс чести»: не иметь в себе лазеек для неограниченного доступа к системе и параметрам Secure Boot, а также требовать того же от загружаемых ими приложений. Если подписанное приложение предоставляет возможность недобросовестного использования напрямую или путём загрузки других приложений, оно становится угрозой безопасности всех пользователей, доверяющих этому приложению. Такую угрозу представляют загрузчик shim, подписываемый Microsoft, и загружаемый им GRUB.
Чтобы от этого защититься, мы установим Ubuntu с шифрованием всего диска на базе LUKS и LVM, защитим initramfs от изменений, объединив его с ядром в одно UEFI-приложение, и подпишем его собственными ключами.
Каламбуры типизации функций в C
8 min
Translation
У C репутация негибкого языка. Но вы знаете, что вы можете изменить порядок аргументов функции в C, если он вам не нравится?
#include <math.h>
#include <stdio.h>
double DoubleToTheInt(double base, int power) {
return pow(base, power);
}
int main() {
// приводим к указателю на функуцию с обратным порядком аргументов
double (*IntPowerOfDouble)(int, double) =
(double (*)(int, double))&DoubleToTheInt;
printf("(0.99)^100: %lf \n", DoubleToTheInt(0.99, 100));
printf("(0.99)^100: %lf \n", IntPowerOfDouble(100, 0.99));
}Этот код на самом деле никогда не определяет функцию IntPowerOfDouble — потому что функции IntPowerOfDouble не существует. Это переменная, указывающая на DoubleToTheInt, но с типом, который говорит, что ему хочется, чтобы аргумент типа int шел перед аргументом типа double.
Вы могли бы ожидать, что IntPowerOfDouble примет аргументы в том же порядке, что и DoubleToTheInt, но приведет аргументы к другим типам, или что-то типа того. Но это не то, что происходит.
Попробуйте — вы увидите одинаковый результат в обоих строчках.
emiller@gibbon ~> clang something.c
emiller@gibbon ~> ./a.out
(0.99)^100: 0.366032
(0.99)^100: 0.366032 Сопроцессы: -что, -как, -зачем?
5 min
Многие пользователи Bash знают о существании со-процессов, появившихся в 4-й версии Bash'a. Несколько меньшее количество знает о том, что сопроцессы в Bash не какая-то новая фича, а древний функционал KornShell'a появившийся ещё в реализации ksh88 в 1988 году. Ещё меньшее количество пользователей shell'ов умеющих сопроцессить знают синтаксис и помнят как это делать. Вероятно, я отношусь к четвёртой группе — знающих о сопроцессах, периодически умеющих ими пользоваться но так и не понимающих «зачем?». Я говорю «периодически», так как иногда я освежаю в голове их синтаксис, но к тому моменту, когда мне кажется что «вот тот случай когда можно применить co-proc» я уже напрочь забываю о том как это делать.
Этой заметкой я хочу свести воедино синтаксисы для разных шеллов чтобы на случай, если таки придумаю зачем они мне нужны, я если и не вспомню как это делать, то по крайней мере, буду знать где это записано.
В заголовке статьи у нас 3 вопроса. Пойдём по порядку.
Что же такое co-process? Со-процессинг — это одновременное выполнение двух процедур, одна из которых считывает вывод другой. Для его реализации необходимо предварительно запустить фоновый процесс выполняющий функционал канала. При запуске фонового процесса его stdin и stdout присваиваются каналам связанными с пользовательскими процессами. Соответственно, один канал для записи, второй для чтения. Пояснять это проще на примерах, поэтому сразу перейдём ко второму вопросу.
Этой заметкой я хочу свести воедино синтаксисы для разных шеллов чтобы на случай, если таки придумаю зачем они мне нужны, я если и не вспомню как это делать, то по крайней мере, буду знать где это записано.
В заголовке статьи у нас 3 вопроса. Пойдём по порядку.
Что?
Что же такое co-process? Со-процессинг — это одновременное выполнение двух процедур, одна из которых считывает вывод другой. Для его реализации необходимо предварительно запустить фоновый процесс выполняющий функционал канала. При запуске фонового процесса его stdin и stdout присваиваются каналам связанными с пользовательскими процессами. Соответственно, один канал для записи, второй для чтения. Пояснять это проще на примерах, поэтому сразу перейдём ко второму вопросу.