
Александр Крижановский ( krizhanovsky, NatSys Lab.)
По Сети уже давно бегает эта картинка, по крайней мере, я ее часто видел на Фейсбуке, и появилась идея рассказать про нее:


SRE


Это практическое пособие познакомит вас c Ansible. Вам понадобится виртуальная или реальная машина, которая будет выступать в роли узла для Ansible. Окружение для Vagrant идет в комплекте с этим пособием.
Ansible — это программное решение для удаленного управления конфигурациями. Оно позволяет настраивать удаленные машины. Главное его отличие от других подобных систем в том, что Ansible использует существующую инфраструктуру SSH, в то время как другие (chef, puppet, и пр.) требуют установки специального PKI-окружения.
Пособие покрывает такие темы:
Ansible использует так называемый push mode: конфигурация «проталкивается» (push) с главной машины. Другие CM-системы обычно поступают наоборот – узлы «тянут» (pull) конфигурацию с главной машины.
Этот режим интересен потому что вам не нужно иметь публично доступную главную машину для удаленной настройки узлов; это узлы должны быть доступны (позже мы увидим, что скрытые узлы также могут получать конфигурацию).
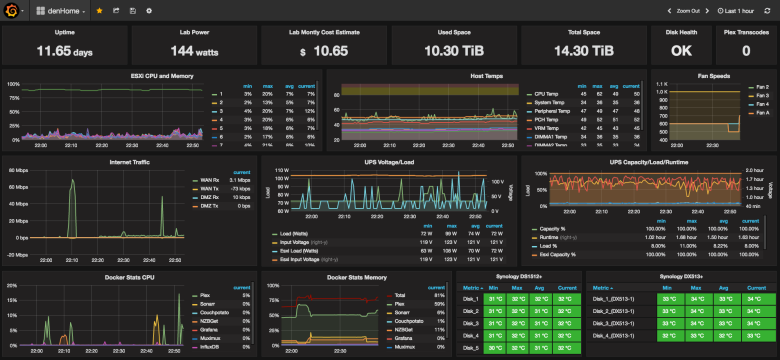

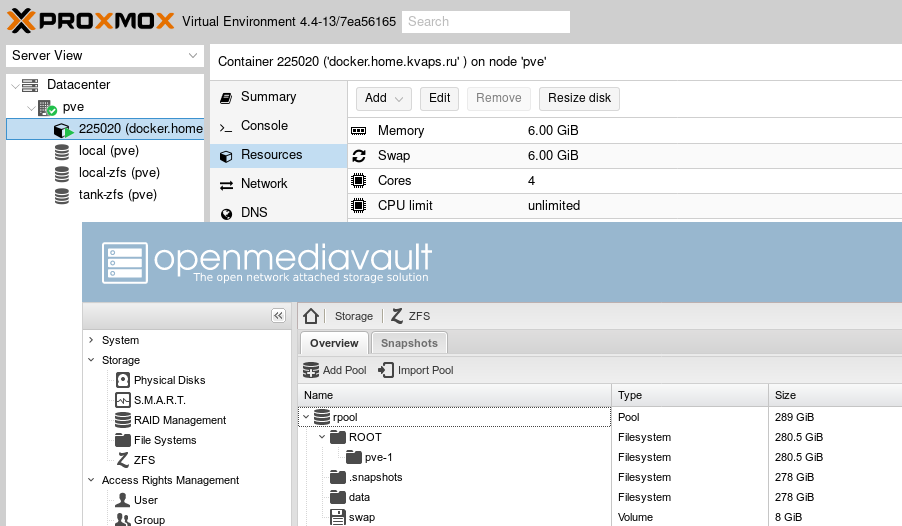
Астрологи объявили месяц статей о домашних NAS на Хабре, так что поделюсь и своей историей успеха...
Не так давно я попробовал новый FreeNAS Coral. Понравилось мне в нем если не все, то очень многое: это и новый гипервизор bhyve, и повсеместное использование 9P для проброса файловой системы на гостя, а так же идея с docker и многое другое.
Кроме того я ещё больше влюбился в ZFS со всеми её плюшками, такими как дедупликация и сжатие на лету.
Но к сожалению не все было так гладко как хотелось бы и, к тому же, флешка с установленной системой приказала долго жить, так что настало время для новых экспериментов! На этот раз я задумал реализовать что-то похожее, но только лучше и целиком на Linux.
В статье так же будет немного рассказано про Docker и автоматический прокси с автоматическим получением сертификатов Letsencrypt.

Открытый курс машинного обучения mlcourse.ai сообщества OpenDataScience – это сбалансированный по теории и практике курс, дающий как знания, так и навыки (необходимые, но не достаточные) машинного обучения уровня Junior Data Scientist. Нечасто встретите и подробное описание математики, стоящей за используемыми алгоритмами, и соревнования Kaggle Inclass, и примеры бизнес-применения машинного обучения в одном курсе. С 2017 по 2019 годы Юрий Кашницкий yorko и большая команда ODS проводили живые запуски курса дважды в год – с домашними заданиями, соревнованиями и общим рейтингом учаcтников (имена героев запечатлены тут). Сейчас курс в режиме самостоятельного прохождения.

Второе занятие посвящено визуализации данных в Python. Сначала мы посмотрим на основные методы библиотек Seaborn и Plotly, затем поанализируем знакомый нам по первой статье набор данных по оттоку клиентов телеком-оператора и подглядим в n-мерное пространство с помощью алгоритма t-SNE. Есть и видеозапись лекции по мотивам этой статьи в рамках второго запуска открытого курса (сентябрь-ноябрь 2017).
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.
Сейчас статья уже будет существенно длиннее. Готовы? Поехали!
concurrent.futures. Для второй версии Питона есть бекпорт под именем futures. Код до безобразия прост:from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor(concurrency) as executor:
for _ in executor.map(upload, queryset):
pass
concurrency — число рабочих потоков, upload — функция, выполняющую саму задачу, queryset — итератор объектов, которые по одному будут передаваться в задачу. Уже этот код при concurrency в 150 смог пропихнуть на сервера Амазона ≈450 запросов в секунду.

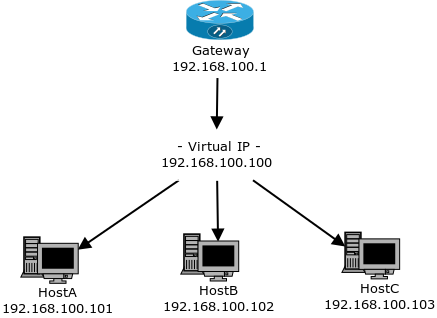
Хочу рассказать вам еще об одном способе балансировки нагрузки. Про Pacemaker и IPaddr (ресурс-агент) и настройке его для Active/Passive кластера сказано уже и так достаточно много, но информации по организации полноценного Active/Active кластера, используя этот модуль я нашел крайне мало. Постараюсь исправить эту ситуацию.
Для начала расскажу подробнее чем такой метод балансировки примечателен:


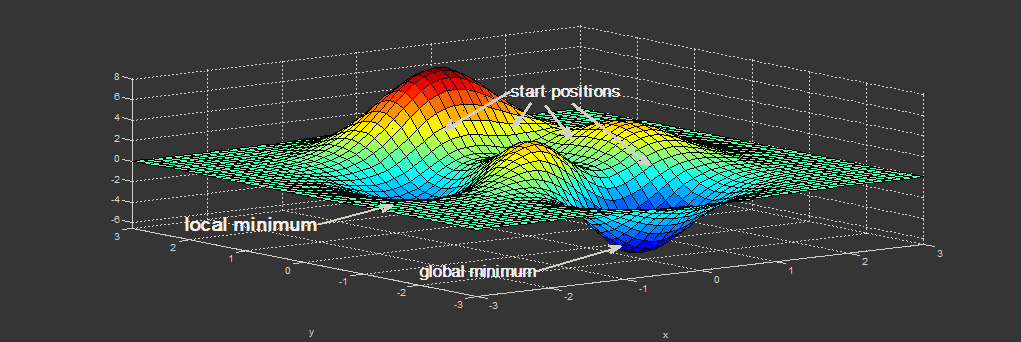
Нахождение экстремума(минимума или максимума) целевой функции является важной задачей в математике и её приложениях(в частности, в машинном обучении есть задача curve-fitting). Наверняка каждый слышал о методе наискорейшего спуска (МНС) и методе Ньютона (МН). К сожалению, эти методы имеют ряд существенных недостатков, в частности — метод наискорейшего спуска может очень долго сходиться в конце оптимизации, а метод Ньютона требует вычисления вторых производных, для чего требуется очень много вычислений.
Для устранения недостатков, как это часто бывает, нужно глубже погрузиться в предметную область и добавить ограничения на входные данные. В частности: МНС и МН имеют дело с произвольными функциями. В статистике и машинном обучении часто приходится иметь дело с методом наименьших квадратов (МНК). Этот метод минимизирует сумму квадрата ошибок, т.е. целевая функция представляется в виде
Алгоритм Левенберга — Марквардта является нелинейным методом наименьших квадратов. Статья содержит:
{kind=link}