→ Оригинал статьи
Автор: Мартин Кръстев
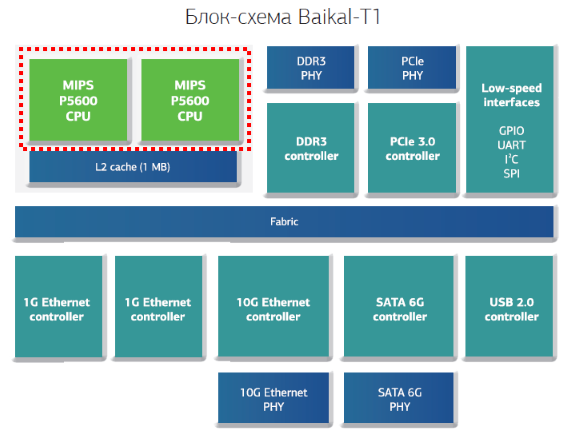
Один мой друг обратил мое внимание на интересную статью на habrahabr.ru — русский перевод статьи Дэниела Лемира Быстрое удаление пробелов из строк на процессорах ARM. Эта статья заинтриговала меня по двум причинам: во-первых, кто-то на самом деле потратил время и усилия по поиску оптимального решения общей проблемы на не-x86 архитектуре (ура!), а во-вторых, результаты автор дал в конце статьи немного озадачили меня: порядка 6-ти кратное преимущество для Intel? Автор сделал однозначный вывод, что ARM-у ну очень далеко по соотношению «эффективность на такт» до «большого железа» от Интела в этой простой задаче.
Вызов принят!

 Сегодня завершилась летняя встреча комитета ISO WG21 C++, проходившая в Торонто с 10 по 15 июля. Вскоре нас наверняка ждёт
Сегодня завершилась летняя встреча комитета ISO WG21 C++, проходившая в Торонто с 10 по 15 июля. Вскоре нас наверняка ждёт 
 Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.
Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.