Comments 55
Оптимизации не даются бесплатно. В таком коде например намного проще совершить ошибку, выбрав неправильную маску или опечатавшись, тогда как в дуболомном byte[] result = source.Where(b => b >= 32).ToArray() ошибиться просто негде. Есть такой парень, Кнут, мне кажется он что-то про подобные вещи писал...
Например, >= с > перепутать?
Большинство программ тормозят не потому, что SIMD не заюзали, а из-за большой буковки О. Если оптимизация бесплатная (ie компилятора), то я только за, а если ручная, то нужно взвесить за и против. В моей практике обычно больше "против". Ниже уже посчитали, что это позволяет обрабатывать 12ГБ/С символов. Медленный вариант в 4 раза медленнее. Если мы берем стандартный 32битный процесс (щас много где распространено, у нас на одном проекте например библиотеки типа OCR были все 32-битные, и приходилось поэтому писать продукт тоже под 32) с флагом на 3ГБ, то "медленный скаляр" переварит всю строку за секунду, а быстрый SIMD — за 0.25 секунды. Только пользователю все равно 3ГБ строку из базы/с диска поднимать чуть ли не минуту.
Я понимаю, что пример в статье это просто абстрактное "смотри как я умею". Но ваш вариант писать все в таком стиле меня настораживает. Я представляю продукт, где все написано в таком духе. Вместо однострочника за 5 секунд пишется и отлаживается SIMD-версия. У меня бы это заняло пару часов, просто чтобы без багов написать, покрыть тестами (однострочник в тестах не нуждается как правило) и т.п. Нужно найти элемент в множестве — снова вместо 5 минут тратим пару часов. Пофиг, что функция вызывается один раз на старте приложения, чтобы подгрузить плагины — скорость! Быстродействие! Все любят быстрые программы, но что-то никто не любит потом их дорабатывать и искать баги.
Кроме того, можно заметить, что вырезание пробелов O(n) задача, тогда как затыки в реальных задачах чаще возникают в другом классе задач. То есть, замечание справедливо.
Другое дело, что это PoC, показывающий как что-то можно ускорить SIMD инструкциями. И этот пример может быть полезен в совершенно других задачах.
Автор смог заставить x86_64 тратить четверть такта на символ. При частоте 3ГГц процессор смог бы обрабатывать 12гигабайт текста в секунду. Повторите это на бейсике…
Красиво, что это можно сделать. Некрасивый код, который в итоге получается. В идеале я бы хотел написать как в примере выше byte[] result = source.Where(b => b >= 32).ToArray(), а компилятор к такому виду привел (пусть даже с хинтами). А некоторые считают, что оптимизирующие компиляторы вообще трата времени. Аргументация была как раз что-то типа "все равно 95% кода выполняются очень редко, а компилятор оптимизирует все равномерно. Давайте пусть будет пользователь сам свои 5% горячего кода оптимзиировать, а на остальное забьем. Да, будет медленее, зато смотрите. какой компактный и быстрый компилятор!". Для кого-то вот это понятие красоты верно. Хотя например на мой взгляд аргументация бредовая.
Вы это серьезно, что ли?
Это же чисто исследовательская задача. Игры разума. Погружения в пучины ассемблера ради максимального быстродействия. Именно такие как этот автор и делали DivX.
Это я к тому, что при оптимизации работы со строками частенько забывают про обработку мультибайтов, надо хотя бы проверку этой самой локали и fallback-метод предусматривать на всякий случай.
size_t i=0;
char *i = bytes, *pos = bytes;
while (i < howmany) {
register char c = i++;
if (c>' ') { *pos++ = c;};
};
Вот это - оптимизированная программа, и с ней надо сравнивать векторный вариант, а не с тем ужасом, что приведен в начале поста.
char *i = bytes, *pos = bytes;
const char *end = bytes + howmany;
while (i < end) {
register char c = *i++;
if (c>' ') { *pos++ = c;};
};
return pos - bytes;
Он медленнее того, что в начале статьи почти в 2 раза.
Почему то Gobbolt.org утверждает (и я ему склонен верить), что этот вариант порождает код меньшего времени исполнения, поскольку:
1) отсутствует превращение индекса в указатель, который занимает 2 команды
2) отсутствует постоянная запись, которая есть в первоначальном варианте
3) проверка занимает ровно столько же времени, сколько тернарный оператор (но она понятнее)
Все это верно для оптимизации -O2.
Каким же образом этот вариант оказывается медленнее?
Вот результаты:
despace(buffer, N): 0.79 ns per operation
despace2(buffer, N): 1.40 ns per operation
1) Превращение индекса в указатель занимает 0 инструкции (ldrsb w10, [x9], #0x1)
2) Безусловная запись быстрее чем условная, т.к. нет лишнего условного перехода.
3) Проверка генерирует дополнительный условный переход. в то время как тернарный оператор дает одну безусловную инструкцию cinc x0, x0, gt.
В итоге во втором варианте больше ветвлений, которые портят конвейер.


Я при чтении тоже споткнулся о первый пример. При решении в лоб первым на ум приходит анализ символа и запись его только в случае необходимости (в рамках более привычной x86 это должно быть более быстрым).
1) индексирование не стоит времени,
2) если вынести запись всегда, то с конвейером лучше — это надо делать.
3) операция сравнения получается точно такой же со скипом инкремента.
Так что почти Ваш вариант
char *i = bytes, *pos = bytes;
const char *end = bytes + howmany;
while (i < end) {
register char c = *i++;
pos=c;
if (c>' ') { pos++; };
};
return pos - bytes;
Единственное исправление, на котором я настаиваю, это последний оператор — ну не нужен тут тернарный оператор, а я его вообще избегаю по рекомендации MISRA.
P.S. Хотя я, вообще то, удивлен, что один переход может ТАК замедлить работу, пусть и в ARM64
despace(buffer, N): 0.79 ns per operation
despace3(buffer, N): 1.19 ns per operation
if вместо тернарного оператора генерирует код через csel + move вместо csinc, что делает цикл на одну инструкцию больше (7 vs 6). Вообще заменять работу с массивами и индексами на указатели — только мешать компилятору оптимизировать.
И для перевода в индекс для arm генерятся две команды — сложение с базой и собственно доступ. а для arm64 адресация со смещением — одна команда.
Кстати, опять таки на gcc генерится (и для arm и для arm64) еще отдельная команда инкремента указателя, а в Вашем дизассембелер ее нет — почему так?
Вот arm64, 11я строчка csinc для примера из статьи и 49я csel и 45я mov для if.
Я нашел вариант, который генерит оптимальный код из программы
register char c = *i++;
if (c>' ') { *pos++=c; };
ldrb r2, [r3], #1 @ zero_extendqisi2
cmp r2, #32
strhib r2, [ip], #1
Но почему то такой код порождает только для версии ARM gcc 4.6.4.
Для версии ARM gcc 5.4.1 получается
ldrb r2, [r3], #1 @ zero_extendqisi2
cmp r2, #32
strhib r2, [ip]
addhi ip, ip, #1
В ARM64 больше нету условного выполнения каждой инструкции, есть b, и csel.
despace(buffer, N) : 4.21 ns per operation despace_ptr(buffer, N) : 5.25 ns per operation neon_despace(buffer, N) : 3.33 ns per operation neon_despace_branchless(buffer, N) : 3.69 ns per operation
Где dspace это:
size_t i = 0, pos = 0;
while (i < howmany) {
const char c = bytes[i++];
bytes[pos] = c;
pos += (c > 32 ? 1 : 0);
}
return pos;
dspace_ptr:
char *i = bytes, *pos = bytes;
const char *end = bytes + howmany;
while (i < end) {
register char c = *i++;
if (c>' ') { *pos++ = c;}
}
return pos - bytes;
Как видно из результатов код с меньшим количеством инструкций выполняется медленнее. Подробное объяснение потянет на отдельную статью, но если кратко, то важно не только количество инструкций, но и зависимости между ними, и это то, что компилятор умеет выстраивать достаточно не плохо, если ему не мешать. Например на Cortex A7 пара ldr/str для одного и того же регистра выполняется столько же, сколько простой ldr.
Также
addhi r0, r0, #0x1 subs r1, r1, #0x1выполнятся за 1 такт потому что поддерживается dual issue для инструкций читающих по одному регистру.
Вот так, примерно, будет выглядеть выполнение кода по тактам:
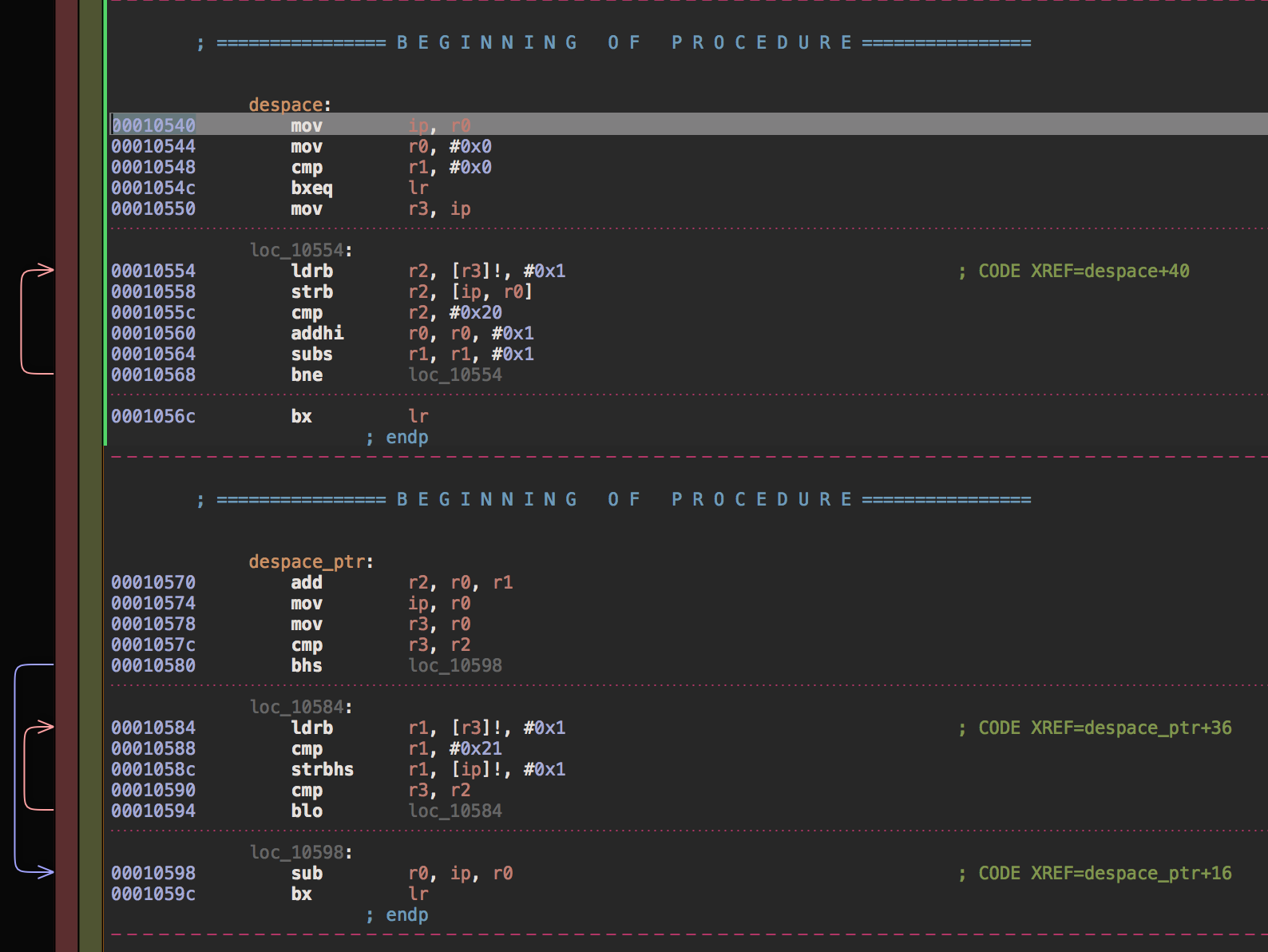
1 ldrb r2, [r3]!, #0x1
2 strb r2, [ip, r0]
3 cmp r2, #0x20
4 addhi r0, r0, #0x1
4 subs r1, r1, #0x1
5 bne loc_10554
1 ldrb r1, [r3]!, #0x1
3 cmp r1, #0x21
4 strbhs r1, [ip]!, #0x1
5 cmp r3, r2
6 blo loc_10584
Выводы.
- Оригинальная функция из статьи написана оптимальным образом
- Не надо мешать компилятору оптимизировать код
- Оптимизация с использованием NEON имела смысл
Оптимизация в помощью векторов будет очень чувствительна к проценту пробелов и даст прирост только тогда, когда пробелов не более, чем сколько-то (интересно, сколько именно).
Во втором случае запись зависит от сравнения, и не может начинаться раньше, чем выполнилось сравнение, которое в свою очередь дожидается результата ldrb. Вот и вся разница, счетчик либо указатель тут не причем.
Оптимизированный вариант neon_despace_branchless не зависит от процента пробелов.
despace(buffer, N) : 9.34 ns per operation despace_ptr(buffer, N) : 8.03 ns per operation
Примечательно так же то, что gcc 7.1.1 не сгенерировал оптимальный код, только clang 4. Gcc почему-то постеснялся использовать
strbhs r1, [ip]!, #0x1, а вместо этого сгенерировал 2 инструкции
strbhi r3, [r2] addhi r2, r2, #0x1
https://habrahabr.ru/post/334142/
Быстрое удаление пробелов из строк на процессорах ARM