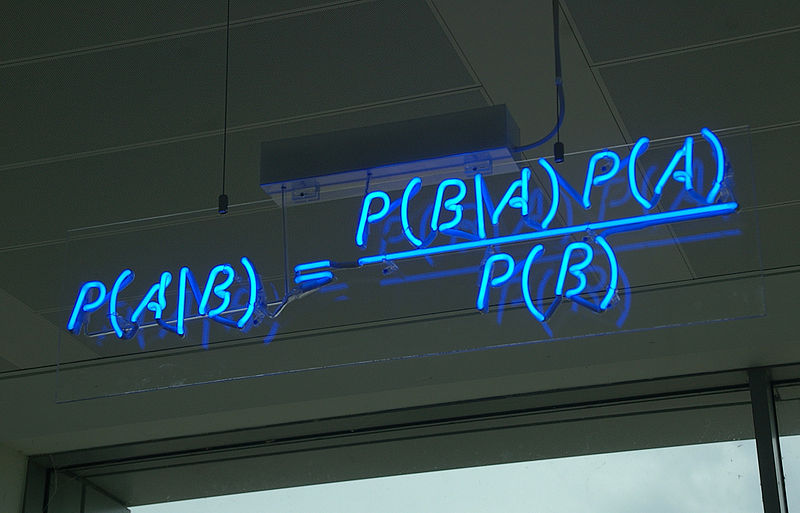В июле всех порадовала статья про deep dream или инцепционизм от Google. В статье подробно рассказывалось и показывалось как нейронные сети рисуют картины и зачем их заставили это делать. Вот эта статья на хабре.
Теперь все, у кого настроена среда caffe, кому скучно и у кого есть свободное время могут сделать собственные фотки в стиле инцепционизм. Одна проблема — почти на всех фотках получаются собаки. Как же избавится от элементов с псами в изображениях deep dream и обучить свою нейронную сеть пользоваться другими картинками?

Теперь все, у кого настроена среда caffe, кому скучно и у кого есть свободное время могут сделать собственные фотки в стиле инцепционизм. Одна проблема — почти на всех фотках получаются собаки. Как же избавится от элементов с псами в изображениях deep dream и обучить свою нейронную сеть пользоваться другими картинками?
 Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.
Но данный подход трудоемок, неточен и не позволит учесть все многообразие отличий квартир друг от друга. Поэтому я решил автоматизировать процесс выбора недвижимости, используя анализ данных путем предсказания «справедливой» цены. В данной публикации описаны основные этапы такого анализа, выбрана лучшая предиктивная модель из восемнадцати протестированных моделей на основании трех критериев качества, в итоге лучшие (недооцененные) квартиры сразу помечаются на карте, и все это используя одно web-приложение, созданное с помощью R.


 Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.
Частенько читаю Хабр и заметил что в последнее время появились Дайджесты новостей по многим тематикам, таким как веб-разработка на php, разработка на Python, мобильные приложения, но не встретил ни одного подборки по популярному сейчас направлению, а именно анализу данных и big data.