В продолжение первого урока по изучению азов RabbitMQ публикую перевод второго урока с официального сайта. Все примеры, как и ранее, на python, но по-прежнему их можно реализовать на большинстве популярных ЯП.

Пользователь






 На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.
На Yet another Conference 2013 мы представили разработчикам нашу новую библиотеку Yandex SpeechKit. Это публичный API для распознавания речи, который могут использовать разработчики под Android и iOS. Скачать SpeechKit, а также ознакомиться с документацией, можно здесь.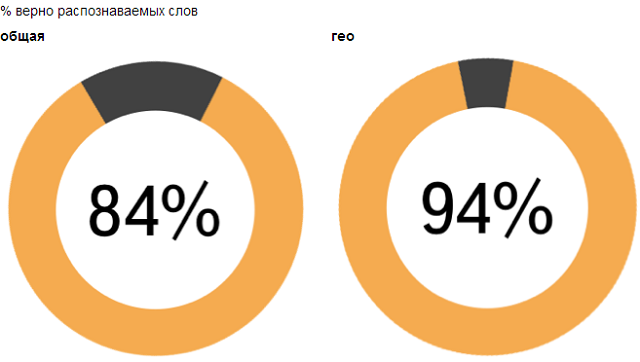

| Нормальная форма | Характеристики |
|---|---|
| МЫЛО | S (существительное), РОД (родительный падеж), ЕД (единственное число), СРЕД (средний род), НЕОД (неодушевленность) |
| МЫЛО | S (существительное), ИМ (именительный падеж), МН (множественное число), СРЕД (средний род), НЕОД (неодушевленность) |
| МЫЛО | S (существительное), ВИН (винительный падеж), МН (множественное число), СРЕД (средний род), НЕОД (неодушевленность) |
| МЫТЬ | V (глагол), ПРОШ (прошедшее время), ЕД (единственное число), ИЗЪЯВ (изъявительное наклонение), ЖЕН (женский род), НЕСОВ (несовершенный вид) |