
Недавно я столкнулся с интересным поведением языковой модели, которое меня по-настоящему удивило, и хочу поделиться этим наблюдением с сообществом.

Пользователь
Недавно я столкнулся с интересным поведением языковой модели, которое меня по-настоящему удивило, и хочу поделиться этим наблюдением с сообществом.

CodebaseGPT — это приложение, которое позволяет разработчикам "общаться" с полной кодовой базой программного проекта.
Главная особенность CodebaseGPT заключается в том, что он создает краткие описания каждого файла проекта и предоставляет эти описания LLM в первом системном промпте. Таким образом, модель имеет обобщенную информацию обо всем проекте в своем контексте на каждом этапе общения с пользователем.

Добрый день
В этой статье я бы хотел поделиться моим опытом классификации комментариев к Youtube видео при помощи OpenAI моделей gpt-3.5 и gpt-4.
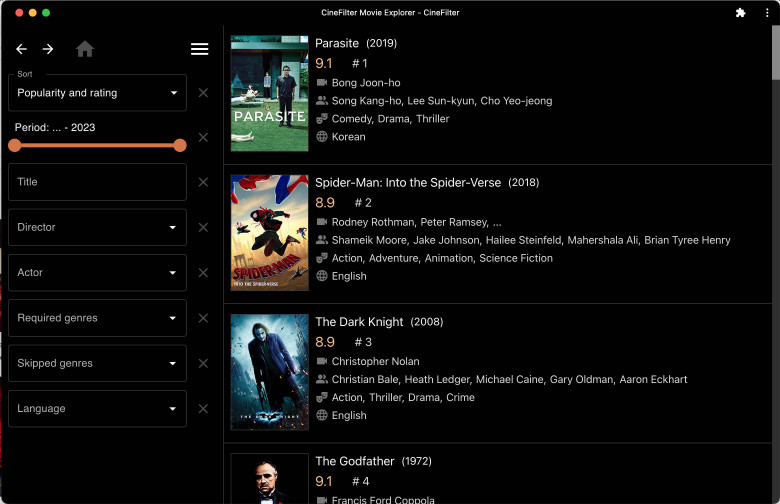
В прошлой статье я описывал, как безуспешно пытался применить алгоритмы коллаборативной фильтрации для практически ценной рекомендации фильмов. Однако в процессе экспериментов обнаружилось, что простое усреднение оценок фильма пользователями сервиса (рейтинг IMDB, Кинопоиска и т.д.) является очень неплохим предсказателем оценки фильма новым зрителем, что было продемонстрировано математически. Это, в частности, объясняет, почему все знают рейтинг Кинопоиска, а о рекомендациях Кинопоиска никто не слышал, хотя такой сервис у них есть.

Некоторое время назад я решил написать рекомендательную систему для фильмов. Подобные системы умеют предсказывать оценку фильма, который пользователь еще не смотрел, на основании его оценок других, ранее просмотренных фильмов.

Хотел бы продемонстрировать сообществу экспериментальный подход к решению проблемы ограниченного размера контекста в GPT-4. Модель GPT-4 имеет ограничение в 8 тысяч токенов (32 тысячи токенов пока еще недоступны?), что эквивалентно примерно 32 Кбайт английского текста (128 Кбайт для 32 тысяч токенов). Это ограничение подразумевает, что суммарный размер вашего запроса и ответа модели должен быть в пределах этих ограничений. В результате модель не может отвечать на вопросы о больших документах (или обширных программных проектах), так как они не умещаются в контексте модели.