В многопоточном программировании много сложностей, основными из которых являются работа c разделяемым состоянием и эффективное использование предоставляемых ядер. Об использовании ядер пойдет речь в следующей статье.
С разделяемым состоянием в многопоточной среде существуют два момента, из-за которых возникают все сложности: состояние гонки и видимость изменений. В состоянии гонки, потоки одновременно изменяют состояние, что ведет к недетерменированному поведению. А проблема с видимостью заключаются в том, что результат изменения данных в одном потоке, может быть невидим другому. В статье будут рассказаны шесть способов как бороться с данными проблемами.
Все примеры приведены на Java, но содержат комментарии и я надеюсь будут понятны программистам не знакомым c Java. Данная статья носит обзорный характер и не претендует на полноту. В то же время она наполнена ссылками, которые дают более подробное объяснение терминам и утверждениям.
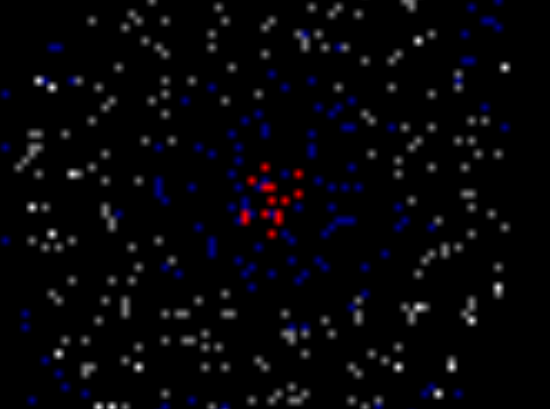
 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 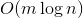 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 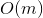 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.