Пару месяцев назад мы запустили у себя СХД на базе Нексенты для нужд массовой виртуализации. Поставили ее под хорошую нагрузку и не все пошло как по маслу и по книжке. Кому интересны шокирующие детали и опыт эксплуатации, прошу под кат.

postdig @postdig
User
Пилим Adblock
9 min

Стратегия
Итак, Адблок… Но здесь я буду говорить не столько о блокировке рекламы, сколько об оптимизации и правильном использовании этого интересного своей универсальностью дополнения. Не отношусь к тем, кого раздражает сама реклама — меня раздражает способ ее доставки.
BitTorrent Sync передал уже 1 петабайт файлов
1 min

Всего за пару недель с момента публичного запуска альфа-версии BitTorrent Sync пользователи синхронизировали более 1 петабайта файлов. Каждый день пользователи передают между своими компьютерами более 70 терабайт.
Компания BitTorrent не имеет доступа к зашифрованным файлам, не размещает файлы у себя и никак не контролирует процесс, но собирает анонимную статистику. Отсюда и стали известны эти цифры.
Linux/Cdorked.A: хроники нового Apache-бэкдора
5 min
На прошлой неделе коллеги из Sucuri прислали нам модифицированную версию бинарного файла веб-сервера Apache, который перенаправлял некоторые, адресованные к нему запросы, на набор эксплойтов Blackhole Exploit Kit. Проведенный экспертами нашей антивирусной лаборатории анализ показал, что эта Linux-угроза, получившая название Linux/Cdorked.A, предназначена для перенаправления трафика на вредоносные сайты. Информация Sucuri об этом инциденте.
В процессе анализа мы пришли к выводу, что Linux/Cdorked.A представляет из себя наиболее сложный Linux-бэкдор из всех, что мы видели прежде. С помощью нашей облачной технологии ESET Live Grid мы получили статистику о сотнях скомпрометированных веб-серверов. В отличии от других подобных угроз, бэкдор не оставляет каких-либо следов своей деятельности на жестком диске скомпрометированного хоста, что заметно усложняет его обнаружение. Вместо этого, он хранит всю используемую им информацию в памяти, без привлечения жесткого диска. Кроме этого, злоумышленники используют обфусцированные HTTP-запросы для передачи служебной информации вредоносному коду, которые не фиксируются в лог-файле работы Apache. Таким образом следы взаимодействия вредоносного кода с C&C сервером также отсутствуют.
В процессе анализа мы пришли к выводу, что Linux/Cdorked.A представляет из себя наиболее сложный Linux-бэкдор из всех, что мы видели прежде. С помощью нашей облачной технологии ESET Live Grid мы получили статистику о сотнях скомпрометированных веб-серверов. В отличии от других подобных угроз, бэкдор не оставляет каких-либо следов своей деятельности на жестком диске скомпрометированного хоста, что заметно усложняет его обнаружение. Вместо этого, он хранит всю используемую им информацию в памяти, без привлечения жесткого диска. Кроме этого, злоумышленники используют обфусцированные HTTP-запросы для передачи служебной информации вредоносному коду, которые не фиксируются в лог-файле работы Apache. Таким образом следы взаимодействия вредоносного кода с C&C сервером также отсутствуют.
StrongSwan. Remote Access VPN с использованием MSCHAPv2-EAP
4 min
Tutorial
О чем пойдет речь?
В данной статье я расскажу о том как настроить на Linux-сервере демон StrongSwan для подключения удаленных пользователей (Remote Access VPN) по протоколу IPSEC IKEv2, а в качестве протокола аутентификации клиентов будет использоваться связка MSCHAPv2-EAP.
Обзор IPSEC демона StrongSwan
5 min
Введение
На хабре много статей про настройку IPSEC на разных девайсах, но относительно мало про Linux, а StrongSwan представлен поверхностно всего одной статьей.
В своем обзоре я затрону следующие вопросы:
- Обзор демона StrongSwan;
- Настройка Remote Access VPN на сертификатах.
Как заставить сайт летать и сэкономить десятки часов системного администрирования
10 min
 Скорость работы вашего сайта, его стабильность и отказоустойчивость всегда зависят от трех составляющих:
Скорость работы вашего сайта, его стабильность и отказоустойчивость всегда зависят от трех составляющих:1. Платформа (CMS) и ее настройки, которые влияют на производительность (параметры кэширования и т.п.)
2. Конфигурация сервера (реального физического или виртуального) и настройки системного ПО (веб-сервер, база данных и т.д.)
3. Качество разработки, кода, интеграции с платформой.
Зачастую веб-разработчик может написать хороший качественный код, но при этом мало что смыслит в системном администрировании и настройке серверов. А хороший сисадмин редко бывает по совместительству еще и классным программистом.
В общем-то, это — совершенно нормально, каждый должен заниматься своим делом. Но, к сожалению, в небольших веб-студиях, которых большинство, редко есть админы в штате. Настройкам хостинга уделяется мало внимания. В лучшем случае — полагаются на суппорт хостера и настройки «по умолчанию».
В итоге сайт может «хромать» из-за проблем и «узких» мест в любой из составляющих: CMS, хостинг, разработка. Клиент в нюансы не вникает и остается не удовлетворен проектом в целом. Его негатив переносится на всех: «Тормозной хостинг! Ужасная система! Разработчики ничего не умеют!»
Такая картина нас, конечно, никогда не устраивала. И мы решили, что надо что-то делать…
Оперативная реакция на DDoS-атаки
4 min
Один из ресурсов, за которым я присматриваю, вдруг стал неожиданно популярным как у хороших пользователей, так и у плохих. Мощное, в общем-то, железо перестало справляться с нагрузкой. Софт на сервере самый обычный — Linux,Nginx,PHP-FPM(+APC),MySQL, версии — самые последние. На сайтах крутится Drupal и phpBB. Оптимизация на уровне софта (memcached, индексы в базе, где их не хватало) чуть помогла, но кардинально проблему не решила. А проблема — большое количество запросов, к статике, динамике и особенно базе. Поставил следующие лимиты в Nginx:
на соединения
и скорость запросов на динамику (fastcgi_pass на php-fpm)
Сильно полегчало, по логам видно, что в первую зону никто не попадает, зато вторая отрабатывает по полной.
Но плохиши продолжали долбить, и захотелось их отбрасывать раньше — на уровне фаервола, и надолго.
Сначала сам парсил логи, и особо настырных добавлял через iptables в баню. Потом парсил уже по крону каждые 5 минут. Пробовал fail2ban. Когда понял, что плохишей стало очень много, перенёс их в ipset ip hash.
Почти всё хорошо стало, но есть неприятные моменты:
— парсинг/сортировка логов тоже приличное (процессорное) время отнимает
— сервер тупит, если началась новая волна между соседними разборками (логов)
Нужно было придумать как быстро добавлять нарушителей в черный список. Сначала была идея написать/дописать модуль к Nginx + демон, который будет ipset-ы обновлять. Можно и без демона, но тогда придётся запускать Nginx от рута, что не есть красиво. Написать это реально, но понял, что нет столько времени. Ничего похожего не нашёл (может плохо искал?), и придумал вот такой алгоритм.
При привышении лимита, Nginx выбрасывает 503-юю ошибку Service Temporarily Unavailable. Вот я решил на неё и прицепиться!
Для каждого location создаём свою страничку с ошибкой
И соответствующий именованный location
Дальше интересней.
Нам нужна поддержка CGI-скриптов. Ставим, настраиваем, запускаем spawn-fcgi и fcgiwrap. У меня уже было готовое для collectd.
Сам CGI-скрипт
на соединения
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn perip 100;
и скорость запросов на динамику (fastcgi_pass на php-fpm)
limit_req_zone $binary_remote_addr zone=dynamic:10m rate=2r/s;
limit_req zone=dynamic burst=10 nodelay;
Сильно полегчало, по логам видно, что в первую зону никто не попадает, зато вторая отрабатывает по полной.
Но плохиши продолжали долбить, и захотелось их отбрасывать раньше — на уровне фаервола, и надолго.
Сначала сам парсил логи, и особо настырных добавлял через iptables в баню. Потом парсил уже по крону каждые 5 минут. Пробовал fail2ban. Когда понял, что плохишей стало очень много, перенёс их в ipset ip hash.
Почти всё хорошо стало, но есть неприятные моменты:
— парсинг/сортировка логов тоже приличное (процессорное) время отнимает
— сервер тупит, если началась новая волна между соседними разборками (логов)
Нужно было придумать как быстро добавлять нарушителей в черный список. Сначала была идея написать/дописать модуль к Nginx + демон, который будет ipset-ы обновлять. Можно и без демона, но тогда придётся запускать Nginx от рута, что не есть красиво. Написать это реально, но понял, что нет столько времени. Ничего похожего не нашёл (может плохо искал?), и придумал вот такой алгоритм.
При привышении лимита, Nginx выбрасывает 503-юю ошибку Service Temporarily Unavailable. Вот я решил на неё и прицепиться!
Для каждого location создаём свою страничку с ошибкой
error_page 503 =429 @blacklist;
И соответствующий именованный location
location @blacklist {
fastcgi_pass localhost:1234;
fastcgi_param SCRIPT_FILENAME /data/web/cgi/blacklist.sh;
include fastcgi_params;
}
Дальше интересней.
Нам нужна поддержка CGI-скриптов. Ставим, настраиваем, запускаем spawn-fcgi и fcgiwrap. У меня уже было готовое для collectd.
Сам CGI-скрипт
Скрипт получения информации с удаленных unix-like серверов
13 min
Приветствую, уважаемые хабрачитатели.
Предлагаю Вашему вниманию свою небольшую наработку, которая, по моему мнению, может облегчить жизнь администраторам операционных систем «породы» UNIX. Мне, как администратору Unix серверов, часто приходится предоставлять некую информацию по множеству серверов архитектурному комитету, по этому пришла идея написания «всего этого безобразия».
Смысл работы скрипта — выдача всей (ну почти всей) информации о сервере, работающем на Linux или AIX (других ОС семейства UNIX под рукой нет, но я над этим работаю).
Предлагаю Вашему вниманию свою небольшую наработку, которая, по моему мнению, может облегчить жизнь администраторам операционных систем «породы» UNIX. Мне, как администратору Unix серверов, часто приходится предоставлять некую информацию по множеству серверов архитектурному комитету, по этому пришла идея написания «всего этого безобразия».
Смысл работы скрипта — выдача всей (ну почти всей) информации о сервере, работающем на Linux или AIX (других ОС семейства UNIX под рукой нет, но я над этим работаю).
Обеспечение бесперебойности (HA) с платформой OpenStack: варианты топологий
9 min
Автор: Piotr Siwczak
Когда я разрабатывал свою первую инфраструктуру OpenStack, я с трудом находил информацию о том, как следует распределять многочисленные ее компоненты по оборудованию. Я изучил множество документов, в том числе справочник по архитектуре Rackspace (который ранее был размещен по ссылке referencearchitecture.org, но сейчас, похоже, эта ссылка устарела). Я также просмотрел проектные схемы в документации OpenStack. Должен признать, что тогда у меня были только базовые знания о том, как взаимодействуют компоненты, поэтому я остановился на достаточно простой схеме: один “управляющий узел”, который включал все компоненты, в том числе API-сервисы, nova-scheduler, Glance, Keystone, базу данных и RabbitMQ. Под управление узла я поместил ферму “рабочих лошадок” — вычислительных узлов. Я также организовал три сети: частную (для трафика с фиксированным IP-адресом и управления серверами), общедоступную (для трафика с динамическим IP-адресом) и для хранения (для трафика по протоколу iSCSI сервиса nova-volume).
Когда я начал работать в Mirantis, я значительно изменил свой подход. Я понял, что все мои идеи по созданию фермы выделенных вычислительных узлов с одним или двумя управляющими узлами, были неверными. С одной стороны, мой подход был хорош в плане разделения компонентов, но на практике мы можем с легкостью смешивать и компоновать рабочие компоненты без перегрузки OpenStack (например, сервис nova-compute с сервисом nova-scheduler на одном узле). Оказывается в OpenStack “управляющий узел” и “вычислительный узел” могут иметь разные значения в зависимости от того, как гибко распределены компоненты OpenStack.
В общем, можно предположить, что в каждой установке OpenStack должны быть как минимум три типа узлов (и, возможно, четвертый), которые описал мой коллега Олег Гельбух:
Когда я разрабатывал свою первую инфраструктуру OpenStack, я с трудом находил информацию о том, как следует распределять многочисленные ее компоненты по оборудованию. Я изучил множество документов, в том числе справочник по архитектуре Rackspace (который ранее был размещен по ссылке referencearchitecture.org, но сейчас, похоже, эта ссылка устарела). Я также просмотрел проектные схемы в документации OpenStack. Должен признать, что тогда у меня были только базовые знания о том, как взаимодействуют компоненты, поэтому я остановился на достаточно простой схеме: один “управляющий узел”, который включал все компоненты, в том числе API-сервисы, nova-scheduler, Glance, Keystone, базу данных и RabbitMQ. Под управление узла я поместил ферму “рабочих лошадок” — вычислительных узлов. Я также организовал три сети: частную (для трафика с фиксированным IP-адресом и управления серверами), общедоступную (для трафика с динамическим IP-адресом) и для хранения (для трафика по протоколу iSCSI сервиса nova-volume).
Когда я начал работать в Mirantis, я значительно изменил свой подход. Я понял, что все мои идеи по созданию фермы выделенных вычислительных узлов с одним или двумя управляющими узлами, были неверными. С одной стороны, мой подход был хорош в плане разделения компонентов, но на практике мы можем с легкостью смешивать и компоновать рабочие компоненты без перегрузки OpenStack (например, сервис nova-compute с сервисом nova-scheduler на одном узле). Оказывается в OpenStack “управляющий узел” и “вычислительный узел” могут иметь разные значения в зависимости от того, как гибко распределены компоненты OpenStack.
В общем, можно предположить, что в каждой установке OpenStack должны быть как минимум три типа узлов (и, возможно, четвертый), которые описал мой коллега Олег Гельбух:
Рекомендации по планированию и развертыванию радиоканалов на оборудовании Ubiquiti AirFiber
7 min
Оборудование AirFiber, представленное компанией ubiquiti в 2012 году позволяет развертывать каналы точка-точка протяженностью до 14 км и емкостью до 750 Мбит fullduplex и неограниченную пакетную производительность. Увеличение емкости канала в несколько раз, относительно обычных решений (powerbridge, nanobridge), позволяет предложить клиентам новые тарифные планы, а также подключать через радио магистраль не только отдельные базовые станции, но и целые микрорайоны, объединяя сегменты сетей.
Однако, эти серьезные области применения требуют правильного подхода к планирования и эксплуатации радиоканала. Ведь цена ошибки на канале, подключающем целый район существенно выше, чем на одном клиентском подключении.
Перед развертыванием радио канала необходимо провести планирование: убедится, что на планируемых сайтах есть радиовидимость и энергетика системы позволит получить надежный канал связи.
Мы рекомендуем для предварительной оценки использовать бесплатную программу RadioMobile. Введя основные параметры системы, gps координаты и планируемую высоту установки устройств Вы можете рассчитать как прохождение зоны Френеля, так и энергетический бюджет радиоканала.


Скрины с радиомобайл (расчет с EIRP 33 )
Конечно, точное решение о наличии прямой видимости даст только выезд на место установки, ведь в программе нет карт городской застройки, но сделать предварительные выводы о видимости можно не выезжая из офиса.
Однако, эти серьезные области применения требуют правильного подхода к планирования и эксплуатации радиоканала. Ведь цена ошибки на канале, подключающем целый район существенно выше, чем на одном клиентском подключении.
Перед развертыванием радио канала необходимо провести планирование: убедится, что на планируемых сайтах есть радиовидимость и энергетика системы позволит получить надежный канал связи.
Мы рекомендуем для предварительной оценки использовать бесплатную программу RadioMobile. Введя основные параметры системы, gps координаты и планируемую высоту установки устройств Вы можете рассчитать как прохождение зоны Френеля, так и энергетический бюджет радиоканала.
Скрины с радиомобайл (расчет с EIRP 33 )
Конечно, точное решение о наличии прямой видимости даст только выезд на место установки, ведь в программе нет карт городской застройки, но сделать предварительные выводы о видимости можно не выезжая из офиса.
Интерфейс SAS: история, примеры организации хранения
9 min
В прошлый раз мы с вами рассмотрели все, что касается технологии SCSI в историческом контексте: кем она была изобретена, как развивалась, какие у нее есть разновидности и так далее. Закончили мы на том, что наиболее современным и актуальным стандартом является Serial Attached SCSI, он появился относительно недавно, но получил быстрое развитие. Первую реализацию «в кремнии» показала компания LSI в январе 2004 года, а в ноябре того же года SAS вошел в топ самых популярных запросов сайта storagesearch.com.
Начнем с основ. Как же работают устройства на технологи SCSI? В стандарте SCSI все построено на концепции клиент/сервер.
Клиент, называемый инициатором (англ. initiator), отправляет разные команды и дожидается их результатов. Чаще всего, разумеется, в роли клиента выступает SAS контроллер. Сегодня SAS контроллеры — это HBA и RAID-контроллеры, а также контроллеры СХД, стоящие внутри внешних систем хранения данных.
Сервер называется целевым устройством (англ. target), его задача — принять запрос инициатора, обработать его и вернуть данные или подтверждение выполнения команды обратно. В роли целевого устройства может выступать и отдельный диск, и целый дисковый массив. В этом случае SAS HBA внутри дискового массива (так называемая внешняя система хранения данных), предназначенный для подключения к нему серверов, работает в режиме Target. Каждому целевому устройству (“таргету”) присваивается отдельный идентификатор SCSI Target ID.
Для связи клиентов с сервером используется подсистема доставки данных (англ. Service Delivery Subsystem), в большинстве случаев, это хитрое название скрывает за собой просто кабели. Кабели бывают как для внешних подключений, так и для подключений внутри серверов. Кабели меняются от поколения к поколению SAS. На сегодня имеется три поколения SAS:
— SAS-1 или 3Gbit SAS
— SAS-2 или 6Gbit SAS
— SAS-3 или 12 Gbit SAS – готовится к выходу в середине 2013 года


Начнем с основ. Как же работают устройства на технологи SCSI? В стандарте SCSI все построено на концепции клиент/сервер.
Клиент, называемый инициатором (англ. initiator), отправляет разные команды и дожидается их результатов. Чаще всего, разумеется, в роли клиента выступает SAS контроллер. Сегодня SAS контроллеры — это HBA и RAID-контроллеры, а также контроллеры СХД, стоящие внутри внешних систем хранения данных.
Сервер называется целевым устройством (англ. target), его задача — принять запрос инициатора, обработать его и вернуть данные или подтверждение выполнения команды обратно. В роли целевого устройства может выступать и отдельный диск, и целый дисковый массив. В этом случае SAS HBA внутри дискового массива (так называемая внешняя система хранения данных), предназначенный для подключения к нему серверов, работает в режиме Target. Каждому целевому устройству (“таргету”) присваивается отдельный идентификатор SCSI Target ID.
Для связи клиентов с сервером используется подсистема доставки данных (англ. Service Delivery Subsystem), в большинстве случаев, это хитрое название скрывает за собой просто кабели. Кабели бывают как для внешних подключений, так и для подключений внутри серверов. Кабели меняются от поколения к поколению SAS. На сегодня имеется три поколения SAS:
— SAS-1 или 3Gbit SAS
— SAS-2 или 6Gbit SAS
— SAS-3 или 12 Gbit SAS – готовится к выходу в середине 2013 года
Firefox: размер файла по ссылке, или через тернии к форку
9 min
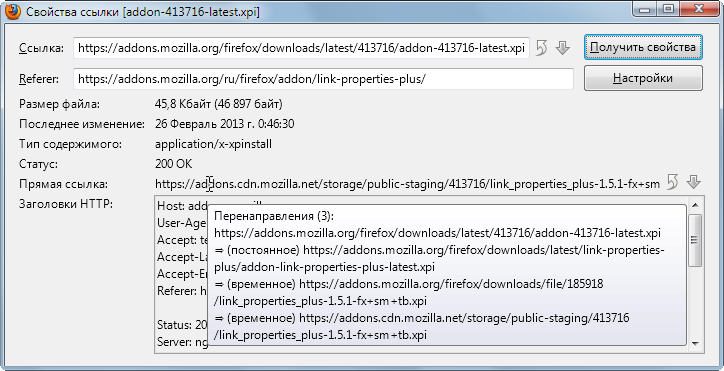
Вашему вниманию представляется небольшая история появления расширения Link Properties Plus и описание того, как работает его основная часть.
Расширение позволяет узнать размер, дату последнего изменения и некоторые другие свойства файла по ссылке (в том числе прямую ссылку после всех перенаправлений) без скачивания всего файла целиком. Если, конечно, все это сообщает сервер.
Нативное решение проблемы с дисками WD в Linux
1 min
Владельцы дисков WD серии Green сталкиваются с слишком частой парковкой головок. В этой статье было описано как решить проблему с помощью DOS-утилиты wdidle3 от поддержки WD. Со времен этой статьи прошло много времени, но проблема осталась. Да и сам метод решения с помощью DOS-утилиты не является гуманным.
В процессе решения этой проблемы наткнулся на программу idle3-tools, с помощью которой можно указать время парковки головок из Linux.
В процессе решения этой проблемы наткнулся на программу idle3-tools, с помощью которой можно указать время парковки головок из Linux.
NetFlow, Cisco и мониторинг трафика
5 min
Всем доброго времени суток! Разбираясь с NetFlow, таким простым, удобным и часто используемым протоколом, я осознал, что он не такой уж и простой, и подводных камней при его эксплуатации хватает.
Под катом я собрал все, что для начала необходимо знать о NetFlow и его настройках на Cisco, отдал дань eucariot, пишущему отличные статьи о сетях, и… Картинки, немного веселых картинок.
Под катом я собрал все, что для начала необходимо знать о NetFlow и его настройках на Cisco, отдал дань eucariot, пишущему отличные статьи о сетях, и… Картинки, немного веселых картинок.
Кластер высокой доступности на Red Hat Cluster Suite
3 min
В поисках решения для построения HA кластера на linux, я наткнулся на довольно интересный продукт, который, по моим наблюдениям, несправедливо обделен вниманием уважаемого сообщества. Судя по русскоязычным статьям, при необходимости организации отказоустойчивости на уровне сервисов, более популярно использование heartbeat и pacemaker. Ни первое, ни второе решение у нас в компании не прижилось, уж не знаю почему. Может сыграла роль сложность конфигурации и использования, низкая стабильность, отсутствие подробной и обновляемой документации, поддержки.
После очередного обновления centos, мы обнаружили, что разработчик pacemaker перестал поддерживать репозиторий для данной ОС, а в официальных репозиториях была сборка, подразумевающая совершенно другую конфигурацию (cman вместо corosync). Переконфигурировать pacemaker желания уже не было, и мы стали искать другое решение. На каком-то из англоязычных форумов, я прочел про Red Hat Cluster Suite, мы решили его попробовать.
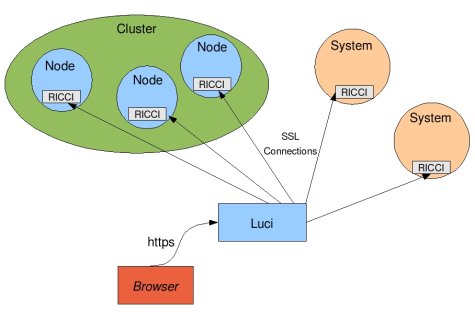
RHCS состоит из нескольких основных компонентов:
Как и в heartbeat и pacemaker, ресурсы кластера управляются стандартизированными скриптами (resource agents, RA). Кардинальное отличие от pacemaker состоит в том, что redhat не подразумевает добавления пользовательских кастомных RA в систему. Но это с лихвой компенсируется тем, что есть универсальный resource agent для добавления обычных init скриптов, он называется script.
Управление ресурсами идет только на уровне групп сервисов. Сам по себе ресурс невозможно включить или выключить. Для распределения ресурсов по нодам и приоритезации запуска на определенных нодах используются failover domains, домен представляет собой правила запуска групп ресурсов на определенных нодах, приоритезацию и failback. Одну группу ресурсов можно привязать к одному домену.
После очередного обновления centos, мы обнаружили, что разработчик pacemaker перестал поддерживать репозиторий для данной ОС, а в официальных репозиториях была сборка, подразумевающая совершенно другую конфигурацию (cman вместо corosync). Переконфигурировать pacemaker желания уже не было, и мы стали искать другое решение. На каком-то из англоязычных форумов, я прочел про Red Hat Cluster Suite, мы решили его попробовать.
Общая информация
RHCS состоит из нескольких основных компонентов:
- cman — отвечает за кластеризацию, взаимодействие между нодами, кворум. По сути, он и собирает кластер.
- rgmanager — менеджер ресурсов кластера, занимается добавлением, мониторингом, управлением групп ресурсов кластера.
- ricci — демон для удаленного управления кластером
- luci — красивый веб интерфейс, который подключается к ricci на всех нодах и предоставляет централизованное управление через веб-интерфейс.
Как и в heartbeat и pacemaker, ресурсы кластера управляются стандартизированными скриптами (resource agents, RA). Кардинальное отличие от pacemaker состоит в том, что redhat не подразумевает добавления пользовательских кастомных RA в систему. Но это с лихвой компенсируется тем, что есть универсальный resource agent для добавления обычных init скриптов, он называется script.
Управление ресурсами идет только на уровне групп сервисов. Сам по себе ресурс невозможно включить или выключить. Для распределения ресурсов по нодам и приоритезации запуска на определенных нодах используются failover domains, домен представляет собой правила запуска групп ресурсов на определенных нодах, приоритезацию и failback. Одну группу ресурсов можно привязать к одному домену.
Regexponline – интерактивный анализатор и редактор регулярных выражений
4 min
Есть одна бородатая шутка: «если у вас есть проблема, и вы собираетесь решать ее с использованием регулярных выражений, то у вас есть две проблемы». Действительно, регулярные выражения – очень мощный и гибкий инструмент, применяемый для решения весьма широкого круга задач. Но, как водится, для поддержания баланса, такой серьёзный инструмент имеет весьма недружелюбный вид.
Такая чупакабра новичка приводит в трепетный ужас, да и знающего человека заставляет невольно поморщить нос. А ваша девушка вообще решит, что вы свихнулись, когда увидит вас за написанием такой конструкции.

Когда-то и мне пришлось по долгу службы подружиться с регулярными выражениями. Прочитав Фридла и несколько статей на Хабре, я, конечно, начал понимать этот синтетический язык. Тем не менее, каждый раз, когда приходилось написать очередную регулярку, я быстро закапывался в нагромождении скобок, слешей, точек, плюсов, знаков вопроса, и других хорошо вам знакомых конструкциях. Разобраться в этой каше было очень сложно, особенно если возвращаешься к задаче месячной давности. Я мечтал об инструменте, который помог бы мне разобраться в собственном творении. Приблизительно подходящих по смыслу сервисов нагуглилось с десяток, но все они приносили мало пользы. Как раз тогда я и начал разрабатывать этот проект.
Итак, regexponline – инструмент, способный наглядно изобразить структуру регулярного выражения, разобрав его по элементарным компонентам; продемонстрировать совпадающие и не совпадающие его части; помочь в написании и отладке выражения, которое почему-то не совпадает с нужной строчкой.
(<([a-z]+[^>]*)>)(.*)(</\2>)Такая чупакабра новичка приводит в трепетный ужас, да и знающего человека заставляет невольно поморщить нос. А ваша девушка вообще решит, что вы свихнулись, когда увидит вас за написанием такой конструкции.
Когда-то и мне пришлось по долгу службы подружиться с регулярными выражениями. Прочитав Фридла и несколько статей на Хабре, я, конечно, начал понимать этот синтетический язык. Тем не менее, каждый раз, когда приходилось написать очередную регулярку, я быстро закапывался в нагромождении скобок, слешей, точек, плюсов, знаков вопроса, и других хорошо вам знакомых конструкциях. Разобраться в этой каше было очень сложно, особенно если возвращаешься к задаче месячной давности. Я мечтал об инструменте, который помог бы мне разобраться в собственном творении. Приблизительно подходящих по смыслу сервисов нагуглилось с десяток, но все они приносили мало пользы. Как раз тогда я и начал разрабатывать этот проект.
Итак, regexponline – инструмент, способный наглядно изобразить структуру регулярного выражения, разобрав его по элементарным компонентам; продемонстрировать совпадающие и не совпадающие его части; помочь в написании и отладке выражения, которое почему-то не совпадает с нужной строчкой.
На пути к бесперебойному (HA) открытому облаку: введение к использованию OpenStack в коммерческих установках
7 min
Автор: Олег Гельбух
Существует несколько основных требований, которые предъявляются к развертыванию платформы OpenStack для коммерческой эксплуатации, как в качестве небольшого кластера для сред разработки в стартапах, так и в виде крупномасштабной установки для поставщика ресурсов для облачных сервисов. Чаще всего встречаются и, как следствие, являются наиболее важными следующие требования:
— Бесперебойность (HA) сервиса и резервирование
— Масштабируемость кластера
— Автоматизация технологических операций
Компания Mirantis разработала подход, который позволяет удовлетворять всем этим трем требованиям. Эта статья – первая в ряде статей, которые описывают наш подход. В статье содержится обзор используемых методов и инструментов.
В целом сервисы на базе платформы OpenStack можно разделить на несколько групп, в данном случае основываясь на подходе обеспечения бесперебойности для каждого сервиса.
API-сервисы
Первая группа включает API-серверы, а именно:
Существует несколько основных требований, которые предъявляются к развертыванию платформы OpenStack для коммерческой эксплуатации, как в качестве небольшого кластера для сред разработки в стартапах, так и в виде крупномасштабной установки для поставщика ресурсов для облачных сервисов. Чаще всего встречаются и, как следствие, являются наиболее важными следующие требования:
— Бесперебойность (HA) сервиса и резервирование
— Масштабируемость кластера
— Автоматизация технологических операций
Компания Mirantis разработала подход, который позволяет удовлетворять всем этим трем требованиям. Эта статья – первая в ряде статей, которые описывают наш подход. В статье содержится обзор используемых методов и инструментов.
Бесперебойность (HA) и резервирование
В целом сервисы на базе платформы OpenStack можно разделить на несколько групп, в данном случае основываясь на подходе обеспечения бесперебойности для каждого сервиса.
API-сервисы
Первая группа включает API-серверы, а именно:
Украинские законы в новом приложении ipLex для Windows Phone 8
1 min
Вышло новое бесплатное мобильное приложение ipLex.Законы для мобильных устройств на ОС Windows Phone 8.
ipLex.Законы — это сборник всех действующих кодексов и основных законов Украины.
Устанавливается полностью на устройство и работает в оффлайне без выхода в интернет.
Для обновления редакций и состава документов ежемесячно выпускается свежая версия приложения.
Документы можно искать по словам в тексте и реквизитам, а также по тематическому рубрикатору.
Внутри текста работает поиск по контексту.
Избранные документы, для быстрого доступа, можно поместить в папку «Мои документы».
ipLex.Законы — это сборник всех действующих кодексов и основных законов Украины.
Устанавливается полностью на устройство и работает в оффлайне без выхода в интернет.
Для обновления редакций и состава документов ежемесячно выпускается свежая версия приложения.
Документы можно искать по словам в тексте и реквизитам, а также по тематическому рубрикатору.
Внутри текста работает поиск по контексту.
Избранные документы, для быстрого доступа, можно поместить в папку «Мои документы».
Отказоустойчивая архитектура из двух веб-серверов на примере Debian Squeeze
10 min
Мне поступила задача организовать отказоустойчивость веб-приложения из двух серверов. Веб-приложение включает в себя статические файлы и данные в СУБД MySQL.
Основное требование заказчика — веб-приложение должно быть всегда доступно и в случае сбоя в течении 5 минут сбой должен быть восстановлен.
2 сервера, территориально разнесенные в разных ЦОДах, должны удовлетворить данное требование.
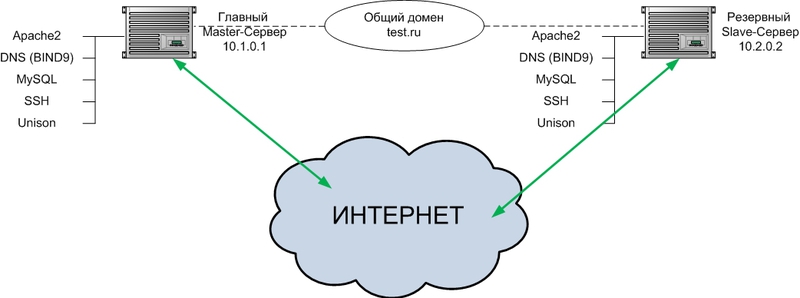
Основное требование заказчика — веб-приложение должно быть всегда доступно и в случае сбоя в течении 5 минут сбой должен быть восстановлен.
2 сервера, территориально разнесенные в разных ЦОДах, должны удовлетворить данное требование.