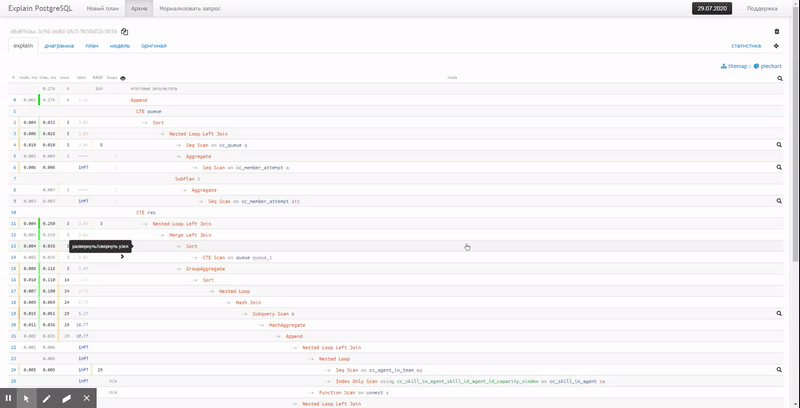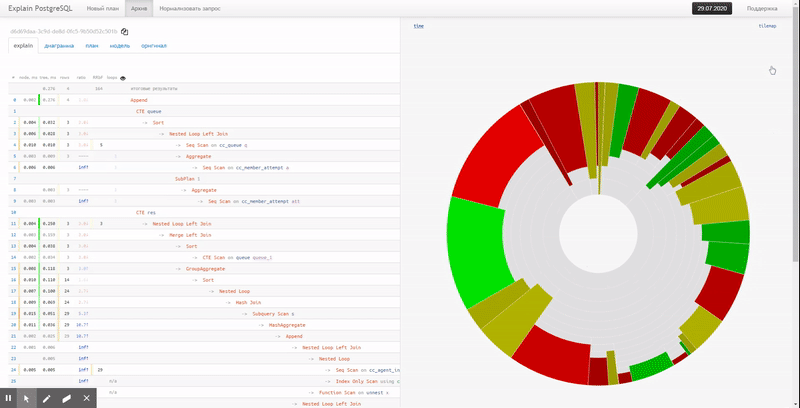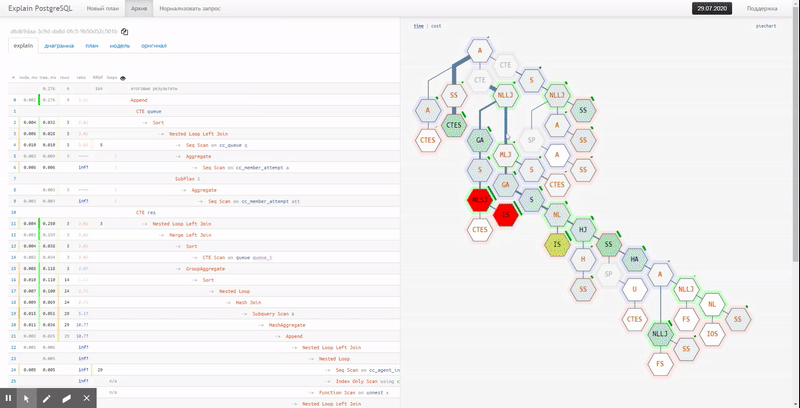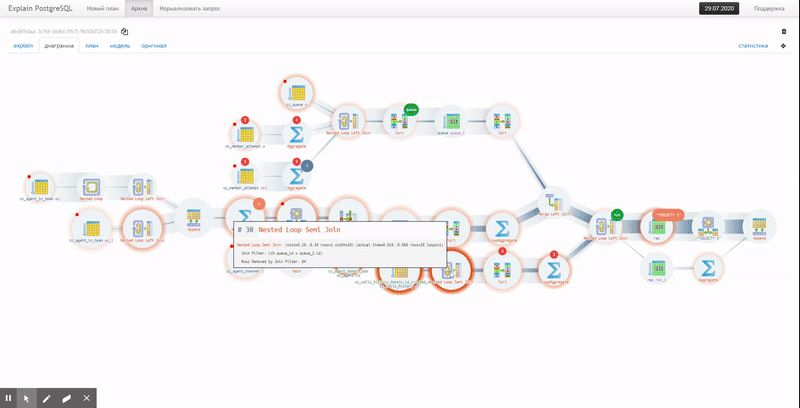
На SQL вы описываете «что» хотите получить, а не «как» это должно исполняться. Поэтому проблема разработки SQL-запросов в стиле «как слышится, так и пишется» занимает свое почетное место, наряду с
особенностями вычисления условий в SQL.
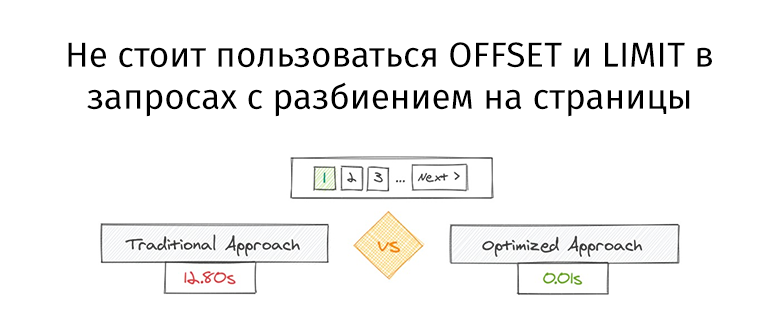
Сегодня на предельно простых примерах посмотрим, к чему это может приводить в контексте использования
GROUP/DISTINCT и
LIMIT вместе с ними.
Вот если вы написали в запросе
«сначала соедини эти таблички, а потом выкинь все дубли, должен остаться только один экземпляр по каждому ключу» — именно так и будет работать, даже если соединение вовсе не было нужно.
И иногда везет и это «просто работает», иногда — неприятно сказывается на производительности, а иногда дает абсолютно неожидаемые с точки зрения разработчика эффекты.
Ну, может, не настолько зрелищные, но…
«Сладкая парочка»: JOIN + DISTINCT
SELECT DISTINCT
X.*
FROM
X
JOIN
Y
ON Y.fk = X.pk
WHERE
Y.bool_condition;
Как бы понятно, что хотели
отобрать такие записи X, для которых в Y есть связанные с выполняющимся условием. Написали запрос через
JOIN — получили какие-то значения pk по несколько раз (ровно сколько подходящих записей в Y оказалось). Как убрать? Конечно
DISTINCT!