Главные отличия от существующих учебников:
— реальный язык программирования JavaScript (а не специализированный язык для обучения)
— не требуется устанавливать среду разработки (разве что редактор кода)
Что-то в последнее время технические статьи о виртуализации (да и не только о виртуализации) скатываются к формату «в новой версии ожидается такая фича». Складывается ощущение, что разбор механизмов и описание опыта, проблем и решений интересны только зарубежным экспертам. С другой стороны, есть такая проблема у экспертов — если что-то изучил, оно становится элементарным и воспринимается само собой разумеющимся, настолько, что писать об этом как-то глупо. Особенно если уже было кем-то описано где-то. Когда-то. На каком-то языке. Ниженаписанное — плод консолидации личных заметок, сначала предназначавшийся для личного упорядочивания мыслей, но наупорядочив значительный объём текста, подумал, что кому-то может пригодиться.
Типовая проблема «виртуализаторов» — владелец сервиса, заказчик или пользователь жалуется, что у него «тормозит» виртуальная машина. Так как виртуализация предполагает консолидацию большого количества ВМ на базе одного комплекта аппаратных ресурсов, переподписку (overprovision — когда мы предполагаем, что серверы не затребуют одновременно максимум своих ресурсов, а значит, например, в 40 ГБ физической памяти мы можем натолкать не 10 серверов по 4 ГБ RAM, а 15, используя Dynamic Memory), а кроме того, серверы могут тормозить и из-за ошибок в программных компонентах и их настройках, то каждый раз приходится решать за что хвататься и куда смотреть в первую очередь. Особенно, если с таким ёмким описанием проблемы, как «тормозит машина» не предоставлено никакой диагностической информации, как чаще всего и бывает. Под катом небольшое руководство для этого случая.
Перевод инфраструктуры hexlet.io на Docker потребовал от нас определенных усилий. Мы отказались от многих старых подходов и инструментов, переосмыслили значение многих привычных вещей. То, что получилось в итоге, нам нравится. Самое главное – этот переход позволил сильно все упростить, унифицировать и сделать гораздо более поддерживаемым. В этой статье мы расскажем о той схеме для разворачивания инфраструктуры и деплоя, к которой в итоге пришли, а так же опишем плюсы и минусы данного подхода.
Ни для кого сегодня уже не является секретом (или даже новостью) успех технологий контейнеризации в общем и платформы Docker, как успешного практического решения, в частности. Каждый, кто хотя бы раз попробовал упаковать своё приложение в контейнер, испытал это ощущения чисто детского счастья от понимания того, что вот она — упакованная и готовая к работе компонента, которая развернется где-угодно, в каких-угодно количествах и заработает там так же хорошо, как работала на компьютере разработчика. Деплоймент стал удовольствием, а не наказанием. «Гибкость» и «масштабируемость» перестали быть маркетинговой чушью из рекламных буклетов и стали реально достижимыми вещами. Писать микросервисы стало не просто «модно», но попросту логично и практично. Контейнеры навсегда изменили мир. (Была, тут правда, вчера мысль о том, что контейнеры — это зло, но в комментариях вроде бы разобрались, что не в контейнерах конкретно беда, а в общем подходе к безопасности)
Не прошло и 100 лет, как это заметила компания Amazon, выпустив в конце 2014-го в бету свой новый сервис — Amazon EC2 Container Service. Общий смысл сервиса — дать возможность разворачивать Docker-контейнеры удобным способом. «Удобным» — означает без необходимости углубляться во внутренности Docker, да и вообще делать что-либо руками в консоли хост-машины. Вы просто создаёте новый кластер, добавляете в него виртуалки, на которых будут работать контейнеры, а потом указываете сколько и каких контейнеров нужно запустить. Всё остальное (выбор на какой машине запустить контейнер, права доступа, проброс портов) Амазон берёт на себя. Кроме того, вы можете использовать из Docker-контейнера всю инфраструктуру Амазона — сохранять файлы на S3, пользоваться очередями SQS, прикрутить на входе амазоновский балансировщик нагрузки, а на выходе — амазоновские логи и сервисы аналитики. Контейнеры могут «видеть» друг друга, делиться (или не делиться) ресурсами, стартовать и быть остановленными из консоли AWS (вручную либо по заданным правилам).
Давайте попробуем что-нибудь запустить в Amazon EC2 Container Service. Например, поднимем Wordpress + Mysql.
Сейчас многие покупают точки доступа 802.11n, но хороших скоростей достичь удается не всем. В этом посте поговорим о не очень очевидных мелких нюансах, которые могут ощутимо улучшить (или ухудшить) работу Wi-Fi. Всё описанное ниже применимо как к домашним Wi-Fi-роутерам со стандартными и продвинутыми (DD-WRT & Co.) прошивками, так и к корпоративным железкам и сетям. Поэтому, в качестве примера возьмем «домашнюю» тему, как более родную и близкую к телу. Ибо даже самые администые из админов и инженеристые из инженеров живут в многоквартирных домах (или поселках с достаточной плотностью соседей), и всем хочется быстрого и надежного Wi-Fi. [!!]:после замечаний касательно публикации первой части привожу текст целиком. Если вы читали первую часть — продолжайте отсюда.
Недавно я повстречал компьютер с Windows 7, который периодически отказывался связываться с интернетом. Подробности оставлю за кадром, скажу только, что проблема была явно не в железе. Неисправности надо исправлять, и так вышло, что первым кандидатом на претворение этого постулата в жизнь оказался я.
Переустановкой системы можно исправить любой косяк
Админ из меня не очень, я роутер то настраиваю с трудом, не говоря уж о починке таких нетривиальных вещей как спонтанные дисконнекты, но люди опытные и искушённые в таких случаях рекомендуют проверку на вирусы и, если оная не поможет, переустановку системы.
Предвидя возмущение в комментариях, хочу сделать лирическое отступление. Переустановка займёт, допустим, день, а поиск первопричин при моей квалификации продлится не менее недели, поэтому вдумчивый и методичный подход тут не вариант.
Приложения растут, становятся сложнее. Растет количество манипуляций, необходимых для их развертывания и обновления.
Одни и те же повторяющиеся действия занимают существенное количество времени
Про какие-то действия забывают, другие путают местами
Человеческий фактор, легкомысленность и недальновидность
В этой статье я расскажу о том, как превратить увлекательное и, местами, непредсказуемое приключение в простую, рутинную и скучную операцию с предсказуемым результатом.
Для того чтобы установить на свой компьютер Linux и начать его использовать для конкретных задач существует масса способов. Выбор дистрибутивов чрезвычайно широк, на любой вкус и цвет — и «для домохозяек» и для продвинутых пользвателей, допускающие любой уровень кастомизации, в том числе и сборку из исходников под конкретное железо. Установка системы в принципе доступна любому, мало-мальски грамотному пользователю ПК. И, если не погружаться в популярные по сей дей холивары на тему «Linux vs Другая ОС», то и спользование данной системы не требует знаний, которые были обязательными для новоиспеченного линуксоида скажем десять лет назад. С моей, глубоко субъективной точки зрения, за более чем десять лет, которые я наблюдаю за развитием этой системы, линукс стал более дружественен к новичкам и избавился от многих проблем, присущих ему в прошлом. И это хорошо.
Пингвины ручной сборки...
На Хабре уже мелькала пара статей на тему LFS, например эта, или вот эта. Комментарии к последней наводят на закономерную мысль — если набор возможностей для установки Linux и его изучения и так исчерпывающе широк, зачем нужен LFS?
Не буду витеивато излагать истории о том «как космические корабли бороздят… и когда Земля была огненным шаром...». Я отвечу на поставленный вопрос исходя из своей позиции — я собираю LFS потому, что мне просто интересно это сделать. Я вижу в этом процессе хорошую возможность заглянуть «под капот» системы. Допускаю, что этот путь сложно назвать оптимальным. Тем не менее, данная статья, и последующие за ней будут посвящены процессу ручной сборки Linux-системы. Данные статьи не будут переводом документации по сборке — в этом нет особой нужды. Акценты будут расставлены на специфике и ньюансах процесса, с которыми пришлось столкнуться автору лично. Будем считать этот цикл чем-то вроде дневника неофита.
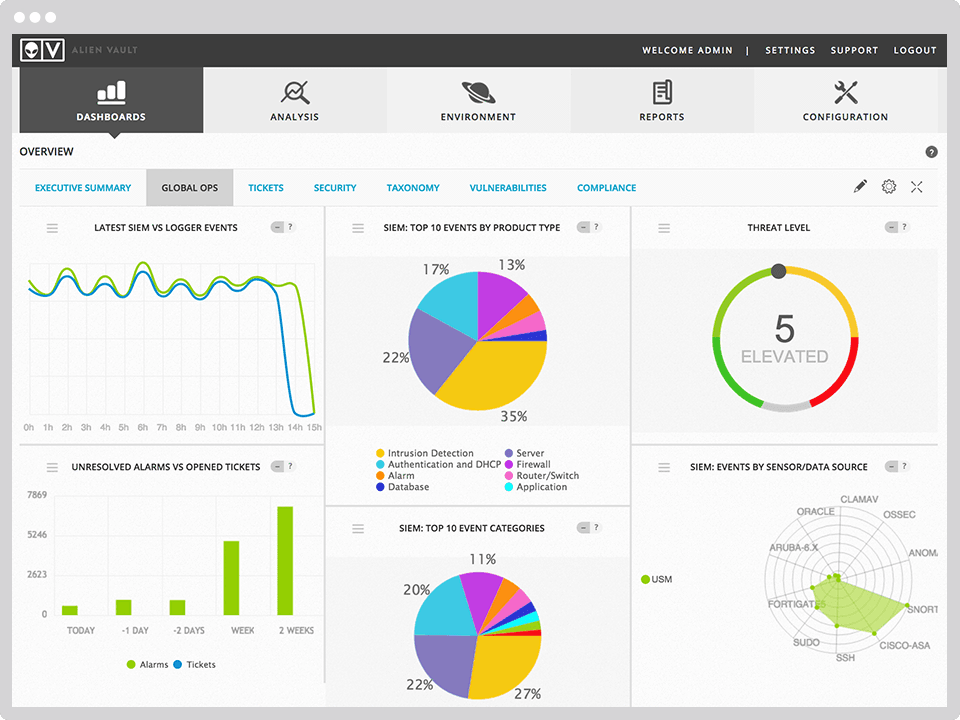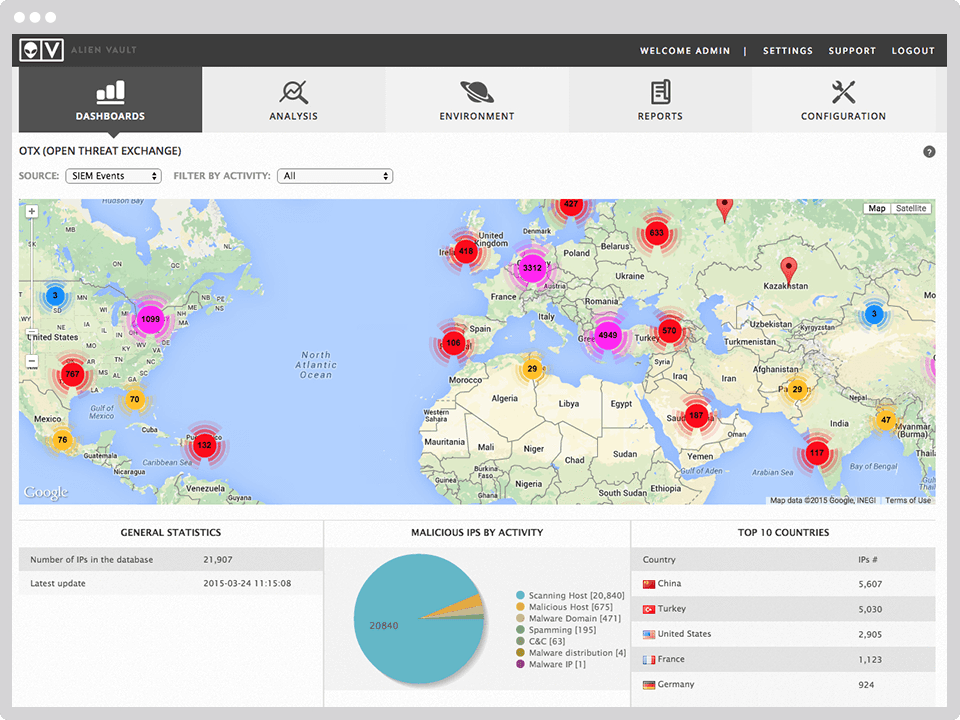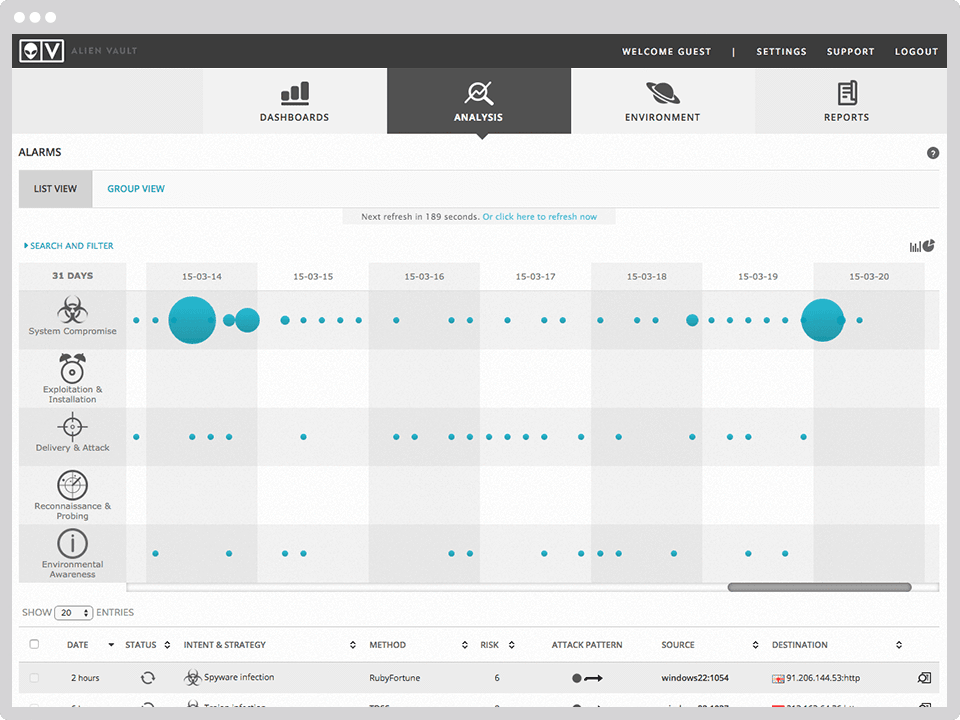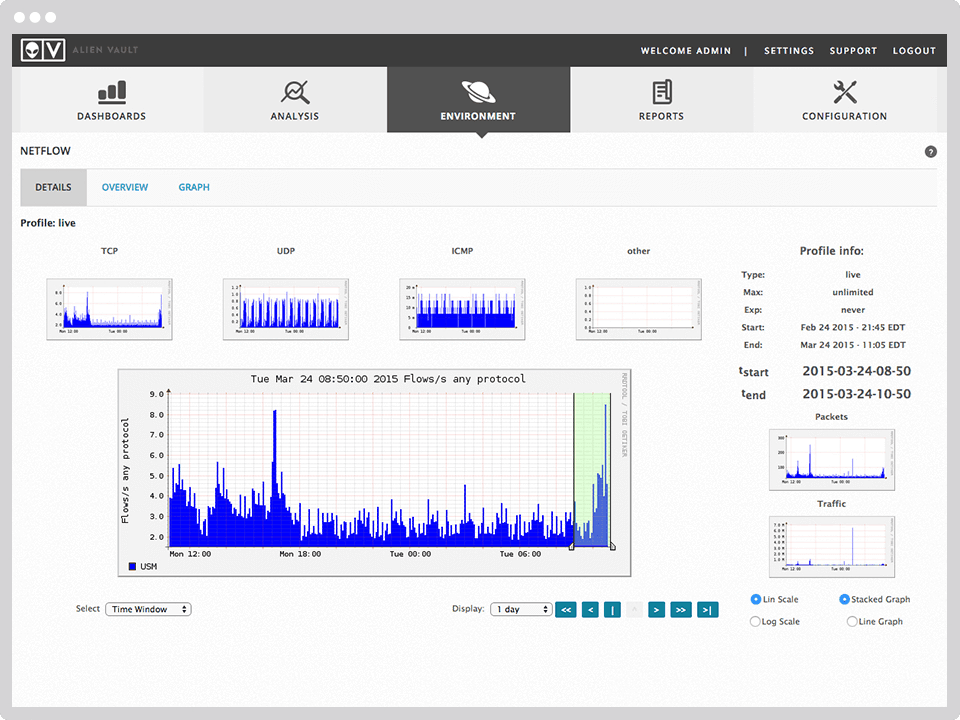
OSSIM (Open Source Security Information Management) — система управления, контроля и обеспечения информационной безопасности.
OSSIM «из коробки» включает в себя такой функционал как:
Сбор, анализ и корреляция событий — SIEM
Хостовая система обнаружения вторжений (HIDS) — OSSEC
Сетевая система обнаружения вторжений (NIDS) — Suricata
Беспроводная система обнаружения вторжений (WIDS) — Kismet
Совсем недавно в разгар рабочего дня от клиента к нам поступила тревожная информация о том, что их сайт подвергается XSS/SQL атакам, часть из которых была успешной. Необходимо было срочно принять меры и настроить базовую защиту в течение нескольких часов, т.к. возможности быстро найти и устранить несовершенства кода у разработчиков не было.
После недолгих раздумий выбор пал на firewall веб-приложений для nginx под названием naxsi, который технически является модулем nginx.
Как-то раз передо мной встала задача добавить экспорт в календарь к уже написанному экспорту обычных текстовых данных через ShareActionProvider кнопку. Сходу нашлись несколько вариантов, каждый из которых мне по каким-либо причинам не подходил.
Эта статья является попыткой ответа на старый вопрос для собеседований: «Что же случается, когда вы печатаете в адресной строке google.com и нажимаете Enter?» Мы попробуем разобраться в этом максимально подробно, не пропуская ни одной детали.
Представленный контент изобилует большим количеством терминов, в переводе некоторых из них могут присутствовать различные неточности. Если вы обнаружите какую-то ошибку в нашем переводе — напишите личным сообщением, и мы всё исправим.
Мы перенесли перевод в репозиторий GitHub и отправили Pull Request автору материала — оставляйте свои правки к тексту, и вместе мы сможем значительно улучшить его.
Доброго времени суток, уважаемые читатели!
В этой статье я хочу рассказать вам о технологии балансировки нагрузки, немного об отказоустойчивости и как все это подружить с контейнерами в OpenVZ. Будут рассмотрены основы LVS, режимы работы и настройка связки LVS c контейнерами в OpenVZ. Статья содержит в себе как теоретические аспекты работы данных технологий, так и практическую часть — проброс трафика от балансировщика внутрь контейнеров. Если это вас заинтересовало — добро пожаловать!
В первой части мы начали изучение Ansible, популярного инструмента для автоматизации настройки и развертывания ИТ-инфраструктуры. Ansible был успешно установлен в InfoboxCloud, описаны принципы работы, базовая настройка. В завершении статьи мы показали как быстро установить nginx на несколько серверов.
Во второй части мы разобрались в выводе playbook, научились отлаживать и повторно использовать скрипты Ansible.
В третьей части мы узнали как написать единый Ansible playbook для разных ОС (например с rpm и deb), как обслуживать сотни хостов и не писать их все в inventory и как сгруппировать сервера по регионам InfoboxCloud. Было изучено использование переменных Ansible и файла inventory.
В четвертой части мы научились использовать модули Ansible для настройки сервера: разобрались, как запускать самые обычные скрипты на удаленных серверах в InfoboxCloud, использовать шаблонизацию для файлов конфигурации, подставляя необходимые переменные, и как использовать системы управления версиями для получения кода на сервер.
В этой части мы рассмотрим, как запускать задачу локально в рамках playbook для удаленных серверов, как использовать условия для выполнения конкретных задач только в определенной ситуации, как использовать циклы для значительного сокращения количества задач в playbook. В завершении мы разберем, как организовывать playbook в роли.
Взаимодействие различных сервисов с использованием АPI, из новаторства превращается в обыденность. Количество бесплатных и платных API уже исчисляется тысячами, и с каждым днем их число активно растет. А почему бы и нет? Продажа удаленных запросов к своему новаторскому сервису может принести больше прибыли, чем распространение услуг через свою площадку. И пусть, в таком случае, уже ваши клиенты ломают голову и тратят деньги на привлечение аудитории. Используя свой опыт работы, я предлагаю краткий обзор лучших решений по реализации API на сегодняшний день.
В первой части мы начали изучение Ansible, популярного инструмента для автоматизации настройки и развертывания ИТ-инфраструктуры. Ansible был успешно установлен в InfoboxCloud, описаны принципы работы, базовая настройка. В завершении статьи мы показали как быстро установить nginx на несколько серверов.
Во второй части мы разобрались в выводе playbook, научились отлаживать и повторно использовать скрипты Ansible.
В третьей части мы узнали как написать единый Ansible playbook для разных ОС (например с rpm и deb), как обслуживать множество хостов и не писать их все в inventory, и как сгруппировать сервера по регионам облака. Было изучено использование переменных Ansible и файла inventory.
В этой части мы научимся использовать модули Ansible для настройки сервера: разберемся, как запускать самые обычные скрипты на удаленных серверах, использовать шаблонизацию для файлов конфигурации, подставляя необходимые переменные, и как использовать системы управления версиями для получения кода на сервер.
В первой части мы начали изучение Ansible, популярного инструмента для автоматизации настройки и развертывания ИТ-инфраструктуры. Ansible был успешно установлен, описаны принципы работы, базовая настройка. В завершении статьи мы показали как быстро установить nginx на несколько серверов.
Во второй части мы разобрались в выводе playbook, научились отлаживать и повторно использовать скрипты Ansible.
В этой части вы узнаете, как писать единый Ansible playbook для разных ОС (например с rpm и deb), как обслуживать множество хостов и не писать их все в inventory, как сгруппировать сервера по регионам InfoboxCloud и многое другое.
Я уже довольно давно занимаюсь мониторингом. Поэтому по роду своей деятельности частенько сталкиваюсь с нестандартными ситуациями, когда приходится придумывать различные «велосипеды», для того, чтобы мониторить хост. Например, мы будем рассматривать ситуацию, когда у нас есть сервер (виртуалки или VDS), который очень ограничен в ресурсах.
Существует множество хороших систем мониторинга, таких как Zabbix, Nagios, Cacti и т.д. Но для нашей ситуации все они не подходят, в силу ясных причин — они сами потребляют ресурсы, которых у нас итак не очень много. Сразу возникает вопрос, как быть? И тут к нам на помощь спешит SAR.
Началось все примерено пару лет назад. Работая в небольшой компании (системный интегратор) из небольшого города столкнулся с постоянной текучкой кадров. Специфика работы такова, что системный инженер за весьма короткий срок получает большой опыт работы с оборудованием и ПО ведущих мировых вендоров. Стоимость такого человека на рынке труда сразу возрастает (особенно, если он успевает получить пару сертификатов) и он просто уходит на более оплачиваемую работу (уезжает в резиновую Москву).
Естественно, что руководство такая ситуация не устраивала, но тут ничего не поделаешь. Единственный доступный вариант — это поставить обучение специалистов на конвеер. Чтобы даже студент после окончания университета мог приступить к работе через две-три недели экспресс-обучения. Так и было решено сформировать курсы для обучения внутри компании по различным направлениям. На мою долю упала разработка мини-курса по быстрому обучению сотрудников настройке сетевого оборудования.
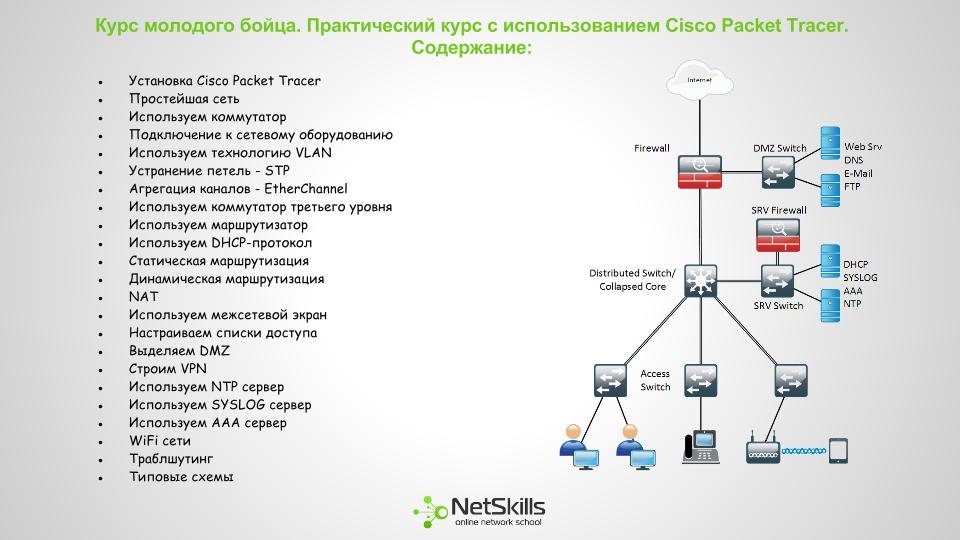
Собственно после этого и началось создание «Курса молодого бойца» по сетевым технологиям.

 Представляю вашему вниманию учебник по программированию для начинающих (подходит для школьников). Основная цель — облегчить вход в мир программирования всем желающим.
Представляю вашему вниманию учебник по программированию для начинающих (подходит для школьников). Основная цель — облегчить вход в мир программирования всем желающим.