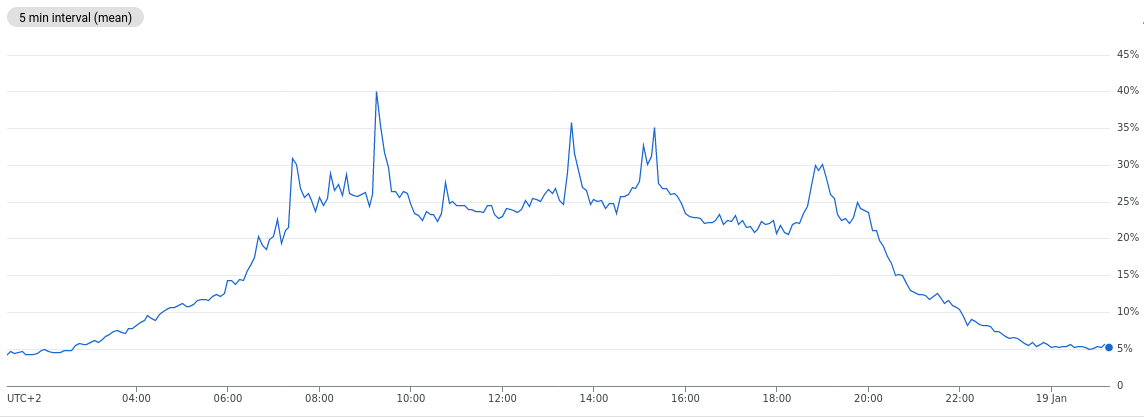
Синдром приобретённого иммунодефицита - безжизненная и формальная фраза, описывающая состояние, развивающееся на фоне ВИЧ инфекции. Терминальная стадия заражения, заболевания Вирусом иммунодефицита человека - последний этап чумы 21 века в вашем теле. Около 40 млн человек живут с этой болезнью, медленно ожидая трагической развязки. Всемирная организация здравоохранения, ученые и средства массовой информации бесконечно тиражируют страх перед глобальной угрозой, предрекая нам катастрофу.
Но с чего все началось? От первой капли крови до эпицентра пандемии, от первого межвидового заражения до всемирной войны с вирусом. Кто был истинным «пациентом ноль»? Откуда появилось заболевание? Отчего мы все умрём и умрем ли? Каков этот длинный путь эволюции от похотливых лемуров до парада колумбийских наркотиков в южных штатах, от гей-сообществ и наркомании до африканских рабов. Что мы натворили? Что мы сделали такого, из-за чего теперь имеем дело с ВИЧ. Предлагаю вам погрузиться в небольшое расследование Scientae Vulgaris и отправиться на поиски нулевого пациента вместе со мной.
Часть 1. Рождение мифа
В начале 80-х в США на фоне растущих опасений и роста числа больных новой, по-видимому, смертельной инфекции, поражающей иммунитет, начинаются первые масштабные исследования. Произошло это до того, как разгорелось пламя мировой эпидемии и вирус проник во все слои общества и все страны нашей планеты. В этот миг ученые пытались остановить его и изучали в рамках связанных между собой пациентов.
Дело было так, Центр по контролю и профилактике заболеваний публиковал еженедельные отчеты о заболеваемости и смертности, и несколько недель подряд в них отображались необычно высокие данные по числу сарком, пневмонии Pneumocystis carinii pneumonia (PCP) и оппортунистических инфекций. То, чем обычно болеют достаточно редко. Общее состояние пациентов выделили в отдельный синдром, собрали рабочую группу и стали разбираться.
И вот спустя пару месяцев, в марте 1984 года в Центре по контролю и профилактике заболеваний в США уже вовсю тщательному анализу и исследованию подвергались сексуальные связи нескольких геев и бисексуальных мужчин. По странному стечению обстоятельств из всех заболевших мужчин, женщин и детей именно эта группа была наиболее многочисленной. Одним из подопытных «содомитов» стал канадский бортпроводник Гаэтан Дугас. Он работал в Эйр Кэнада и умер в 1984-м от почечной недостаточности, вызванной оппортунистической инфекцией на фоне ослабленного иммунитета. Множество журналистов и публицистов 80-х впоследствии опишут Дугаса, как очаровательного и сексуального спортсмена с необъёмным гомосексуальным либидо. Ошибочно определённый как пациент «Ноль», Гаэтан на самом деле не были ни «пациентом О», ни нулевым как таковым. Касательно канадского бортпроводника, его случай числился за номером 57, а обозначение «О» относилось к слову «outside» - то есть, прибывшим из-за пределов США. Именно с Дугаса вообще начинается использование термина «нулевой пациент» в эпидемиологии. Но, как часто бывает, это всего лишь опечатка, вернее, неправильно воспринятая аббревиатура. 57-й пациент был ответственнен за, по меньшей мере, 40 из 248 случаев заражения ВИЧ в 1983 году (исследования Уильяма Дароу в Центре контроля заболеваний). Многие нити на нарисованной эпидемиологами схеме распространения вируса сводились к Гаэтану. Но ,во-первых, далеко не все из них и, во-вторых, на нем они не заканчивались. Молодой человек был продуктом своей эпохи, ВИЧ в его случае и его положении был скорее вопросом времени.Чтобы вы понимали, что за радужные времена в Канаде были в эти годы, нужно упомянуть, что к 1970-м ЛГБТ сообщество игривой походкой праздновало свои победы. В 1971 году в Оттаве состоялся первый в Канаде марш за права геев. Стала выпускаться первая Канадская газета на тему освобождения гомосексуалистов - The body politic - в Торонто. Вышел документальный ЛГБТ сериал «Выход» («каминг аут»). В 73-м году сразу несколько городов в Канаде провели масштабные мероприятия по защите прав геев, назвав это всё «неделей гордости» («прайд вик»). В 74-м году молодому Дугасу было 22 года, быть геем было дерзко и даже немного модно. Во время полётов в самолётах всё ещё курили и подавали крепкий алкоголь крупными порциями, небо пахло романтикой и приключениями. Дугас рос в небольшой семье в пригороде Квебека L’ansien-lorette, возле пригородного аэропорта, он учился на парикмахера и с восторгом наблюдал за пролетающими самолётами. Как только авиакомпании вслед за волной всеобщей либерализации сняли запрет на работу мужчин на борту самолётов, Дугас понял, что всю жизнь мечтал стать стюардессой: белоснежная рубашка с длинными лацканами воротника, голубые обтягивающие штаны и платочек на поясе. Он делился советами по макияжу с коллегами-женщинами и был на острие хипстерской моды 80-х, крутил романы, посещал гей бары и жил полной активной жизнью гейской стюардессы.