Ранее мы говорили о том, что любая информация имеет как внешнюю форму, так и внутренний смысл. Внешняя форма — это то, что именно мы, например, увидели или услышали. Смысл — это то, какую интерпретацию этому мы дали. И внешняя форма, и смысл могут быть описаниями, составленными из определенных понятий.
Было показано, что если описания удовлетворяют ряду условий, то давать им интерпретацию можно, просто заменяя понятия исходного описания на другие понятия, применяя определенные правила.
Правила трактовки зависят от тех сопутствующих обстоятельств, в которых мы пытаемся дать интерпретацию информации. Эти обстоятельства принято называть контекстом, в котором трактуется информация.
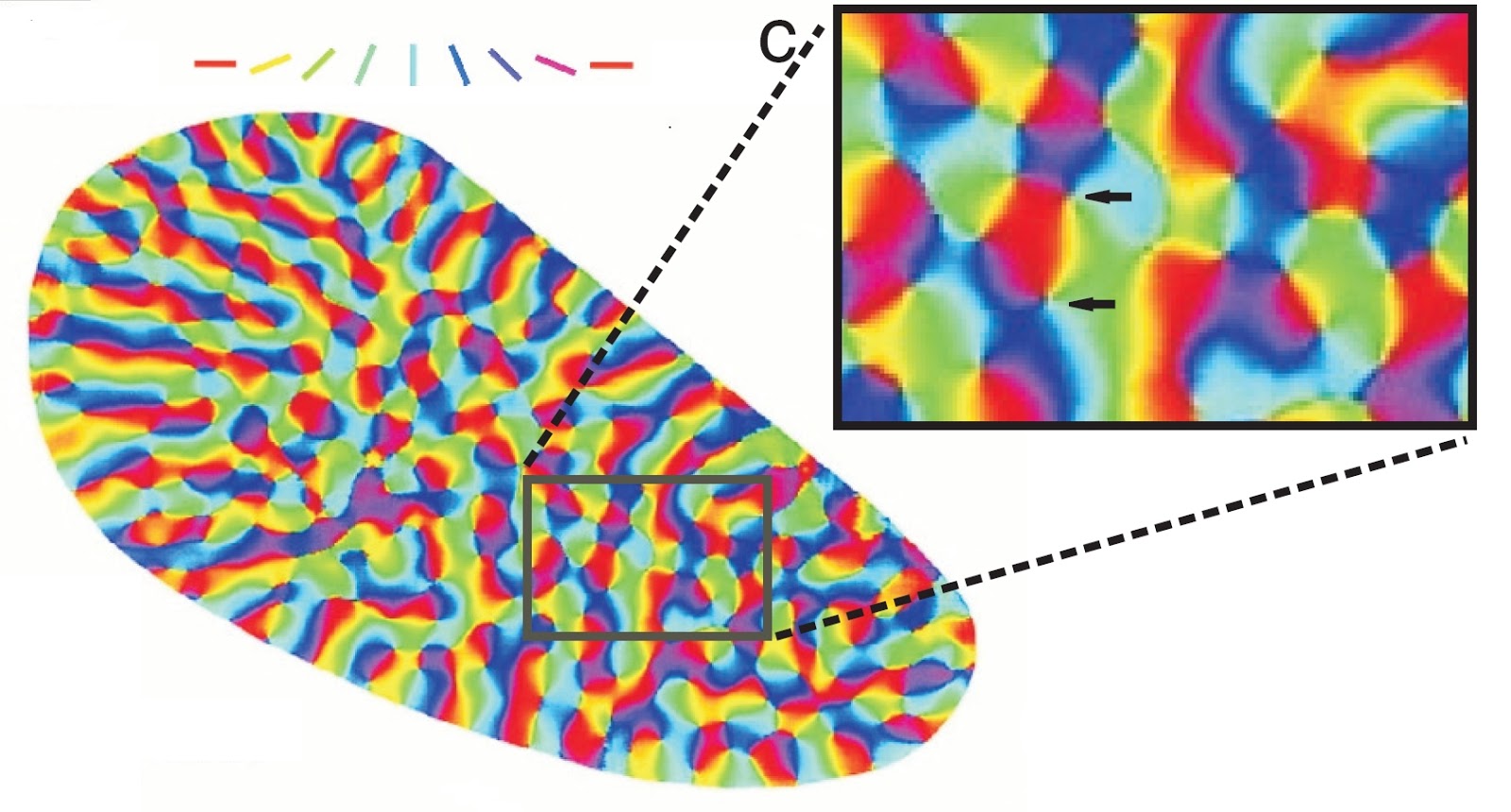
Кора мозга состоит из нейронных миниколонок. Мы предположили, что каждая миниколонка коры — это вычислительный модуль, который работает со своим информационным контекстом. То есть каждая зона коры содержит миллионы независимых вычислителей смысла, в которых одна и та же информация получает свою собственную трактовку.
Был показан механизм кодирования и хранения информации, который позволяет каждой миниколонке коры иметь свою полную копию памяти о всех предыдущих событиях. Наличие собственной полной памяти позволяет каждой миниколонке проверить, насколько ее интерпретация текущей информации согласуется со всем предыдущим опытом. Те контексты в которых трактовка оказывается «похожа» на что-то ранее знакомое составляют набор смыслов, содержащихся в информации.


 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности. 
 Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.
Данное занятие мы посвятим методам обучения без учителя (unsupervised learning), в частности методу главных компонент (PCA — principal component analysis) и кластеризации. Вы узнаете, зачем снижать размерность в данных, как это делать и какие есть способы группирования схожих наблюдений в данных.






 Поэзия — та же добыча радия.
Поэзия — та же добыча радия. В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой.
В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой. В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.
В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей. Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!
Приходит ветеринар к терапевту. Терапевт: — На что жалуетесь? Ветеринар: — Нет, ну так каждый может!
 Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований
Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований