Больше возможностей для совместной работы и дополнительные уведомления
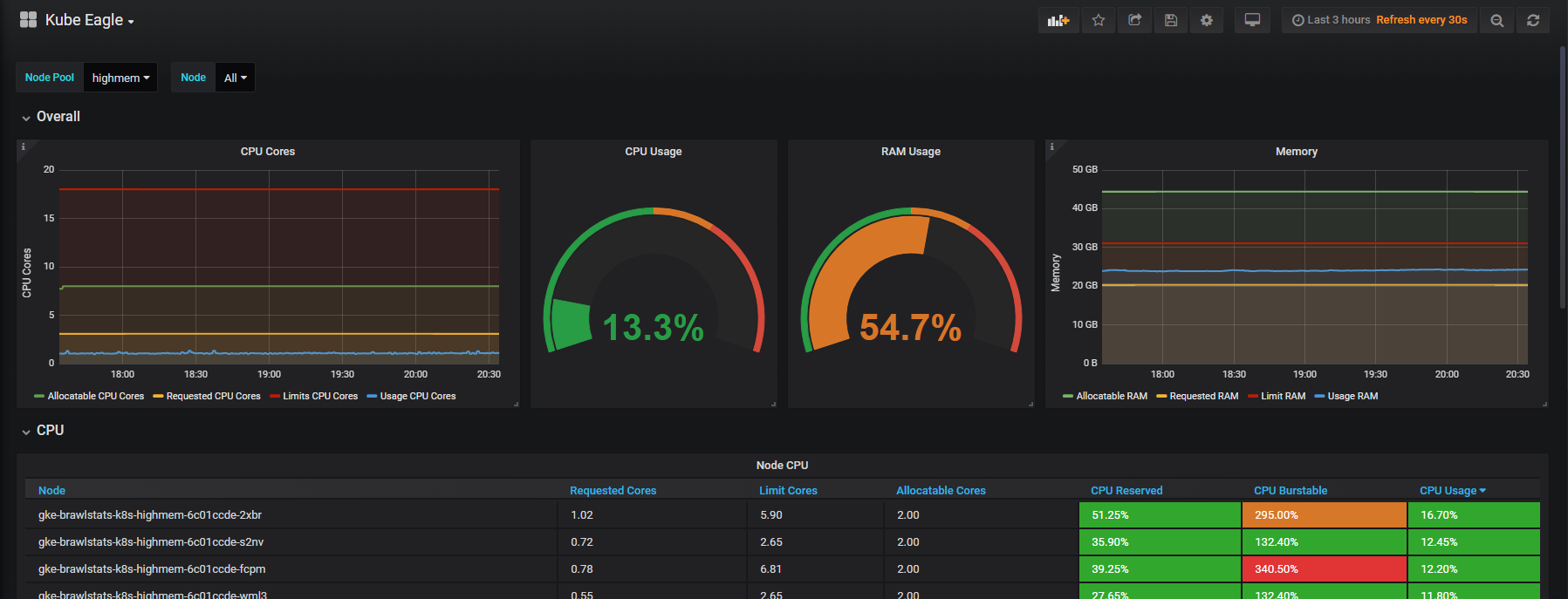
Мы в GitLab постоянно ищем новые способы улучшить совместную работу по всему жизненному циклу DevOps. Мы с радостью объявляем, что с этого выпуска поддерживаем несколько ответственных лиц для одного мердж-реквеста! Эта функция доступна с уровня GitLab Starter и по-настоящему воплощает наш девиз: «Каждый может внести свой вклад». Мы знаем, что с одним мердж-реквестом может работать много людей, чтобы все точно было в порядке, и теперь у вас есть возможность назначать несколько ответственных за мердж-реквесты!
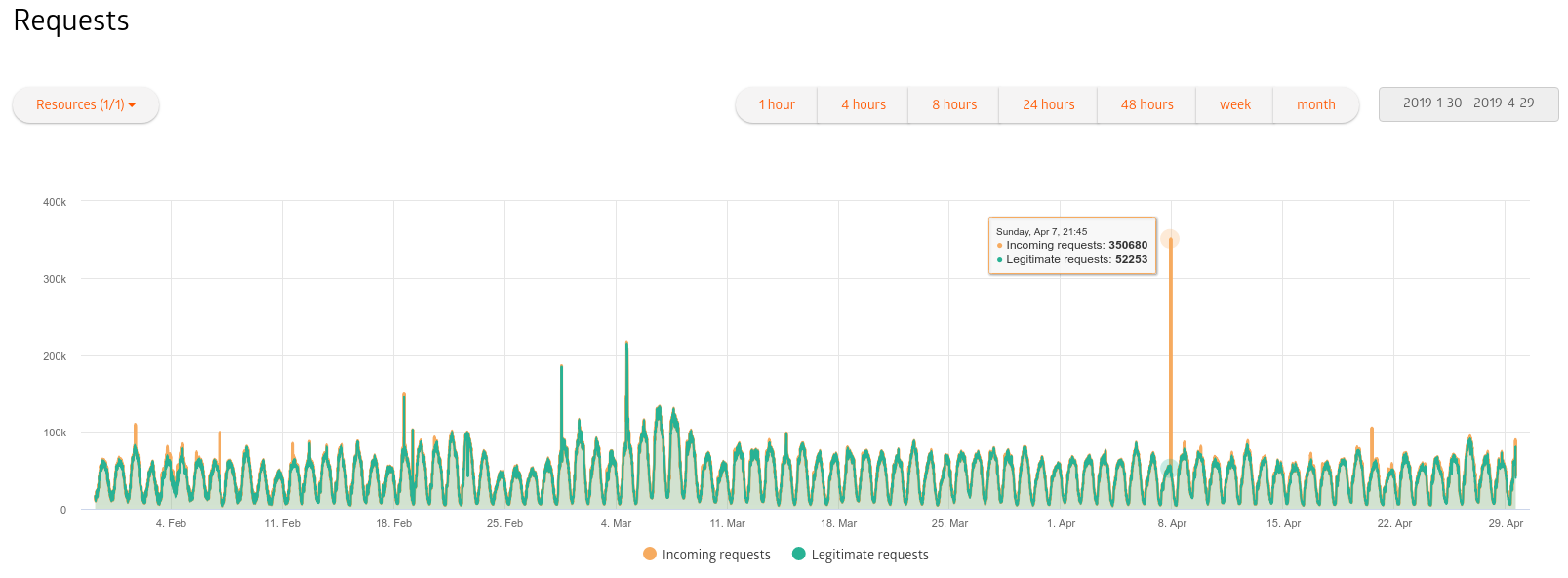
А еще команды DevOps теперь получают автоматические уведомления о событиях деплоя в Slack и Mattermost. Добавьте новые уведомления в список событий отправки в этих двух чатах, и ваша команда будет почти моментально узнавать о новых деплоях.