
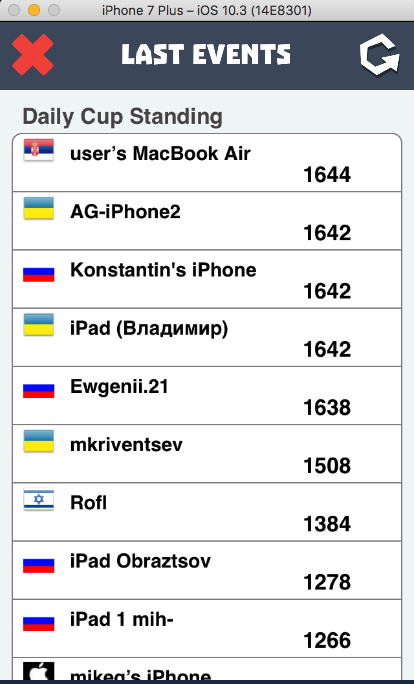
«Нельзя просто так взять и написать классный тест. Один тест написать можно, но сделать, так чтобы по мере того, как количество этих классных тестов росло, как количество людей, которые пишут эти классные тесты, и вы не теряли ни в скорости, ни во времени...»
Эта мысль красной нитью пойдет сквозь материал под катом, и она, пожалуй, требует пояснения. Статья основана на докладе Николая Алименкова, к которому он подошёл не просто прогретым, а горящим после дискуссии с Алексеем Виноградовым о подходах к написанию тестов: методом прямого кода или при помощи паттернов. Нужны ли какие-то еще паттерны, кроме PageElement, Steps, PageObject?! С чего кто-то решил, что паттерны усложняют код, заставляют нас тратить время на создание ненужных (?) boilerplate-простыней? SOLID вам не угодил? А ведь все они создавались с учётом всего накопленного опыта сообщества разработчиков и они знали, что делают.
Николай xpinjection Алименков – известный Java-разработчик, Java техлид и delivery-менеджер, основатель XP Injection. В настоящее время является независимым разработчиком и консультантом, Agile/XP коучем, спикером и организатором различных конференций
Автоматизация тестирования имеет собственный набор задач, так что существует и набор полезных паттернов проектирования для этой области. В докладе Николай рассказывает обо всех известных паттернах и подробно описывает их с практическими примерами.
В основу этого материала легло выступление Николая Алименкова на конференции Heisenbug 2017 Piter под названием «Паттерны проектирования в автоматизации тестирования». Слайды здесь.








 Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «
Эта статья представляет собой адаптацию разделов 2 и 3 из главы 9 моей книги «