Как я нашел способ отследить всех водителей «Ситимобил»
5 min
В субботу вечером я, как всегда, сидел и снифил трафик со своего телефона. Внезапно, открыв приложение «Ситимобил» я увидел, что один интересный запрос выполняется без какой-либо аутентификации.
Это был запрос на получение информации о ближайших машинах. Выполнив этот запрос несколько раз с разными параметрами я понял, что можно выгружать данные о таксистах практически в реалтайме. Вы только представьте, сколько интересного можно теперь узнать!
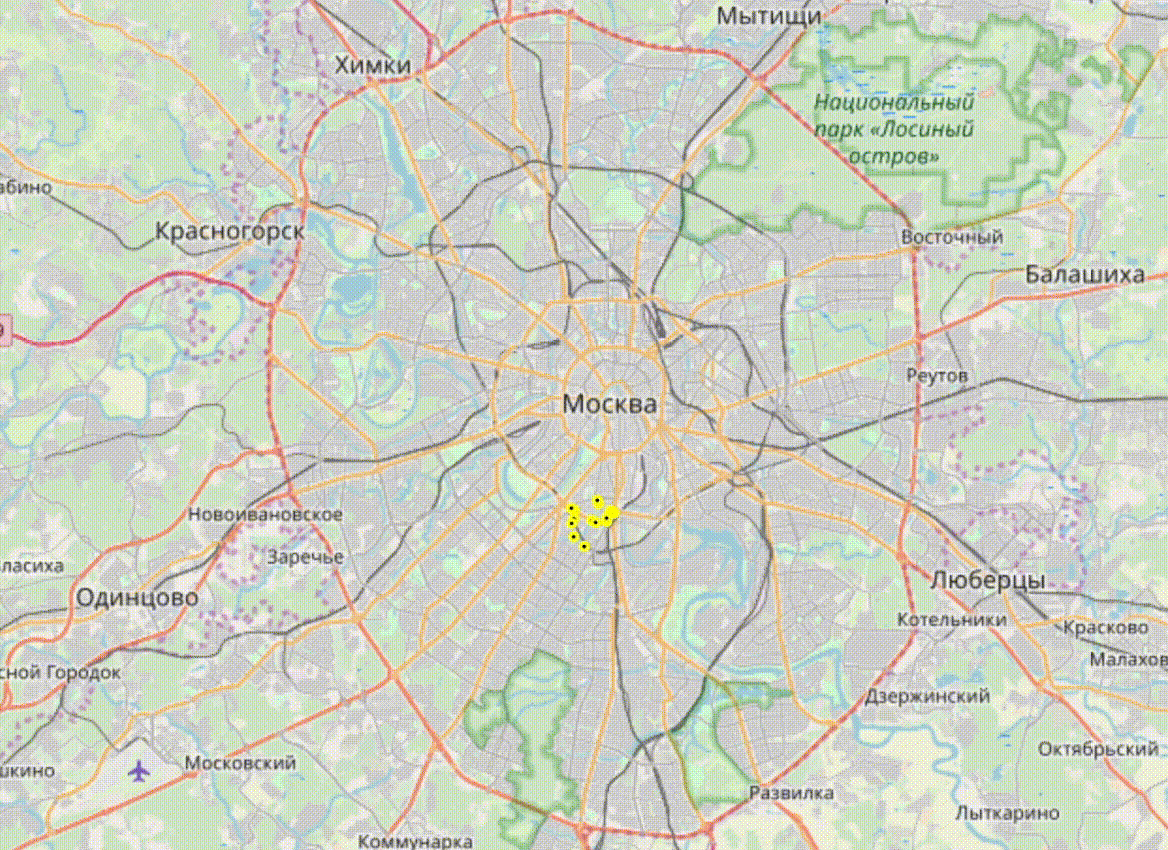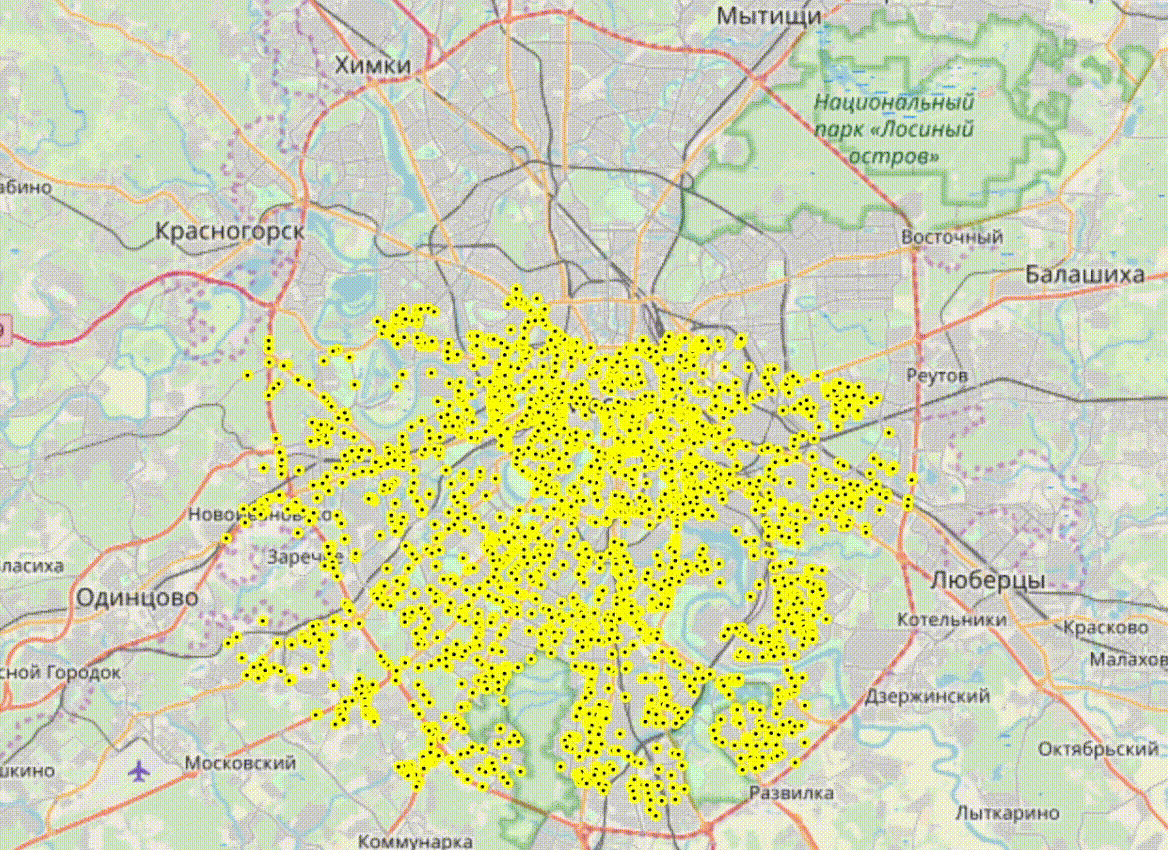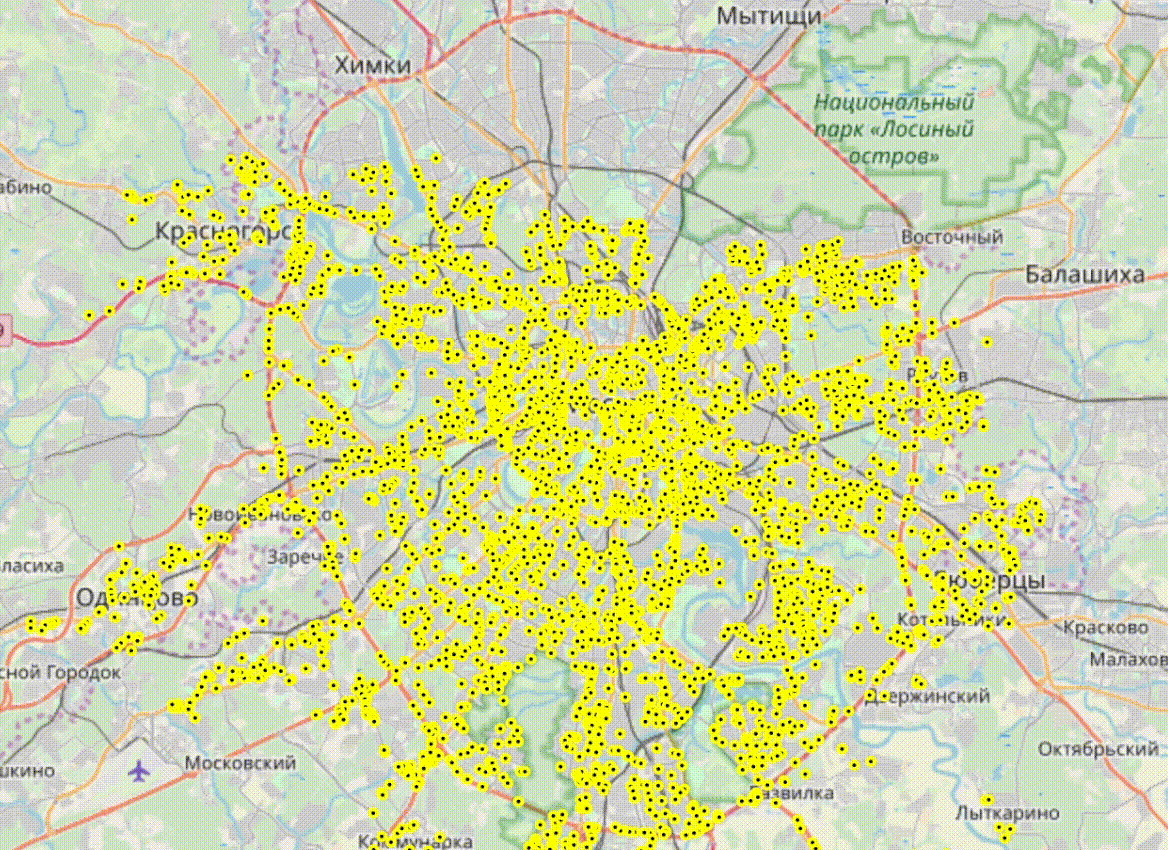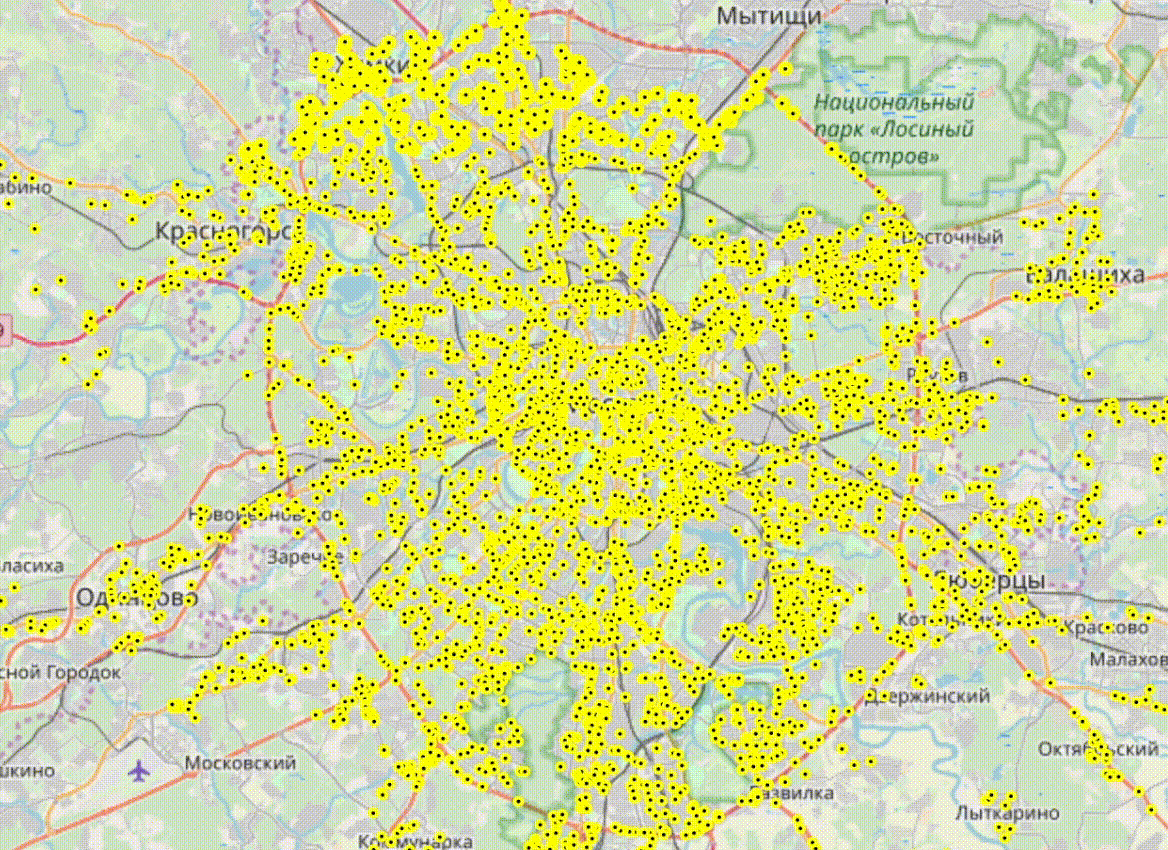
Это был запрос на получение информации о ближайших машинах. Выполнив этот запрос несколько раз с разными параметрами я понял, что можно выгружать данные о таксистах практически в реалтайме. Вы только представьте, сколько интересного можно теперь узнать!
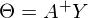 , где
, где 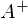 — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).