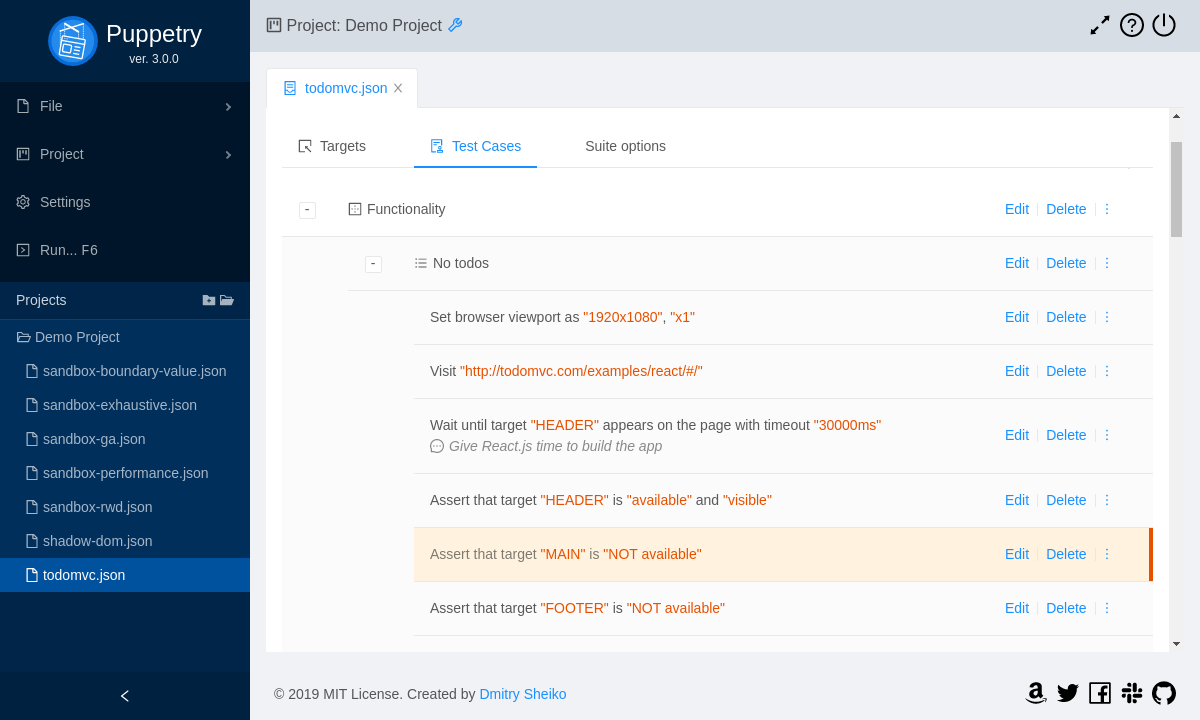
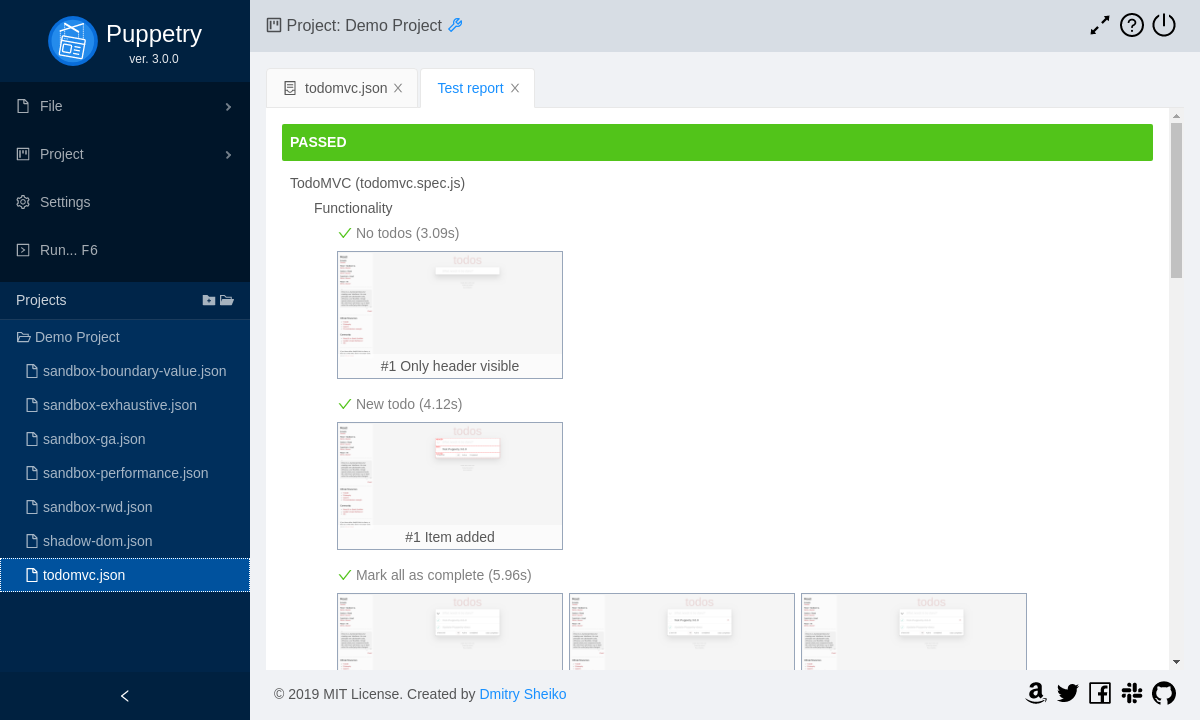
Я думаю, нет смысла убеждать кого-либо в значимости автоматизированного тестирования. Тем не менее, функциональные тесты зачастую крайне сложны в написания и еще более в поддержке. Существует немало решений, призванных упростить разработку тестов. Я хочу рассказать об одном из них — Puppetry. Это настольное приложение (Windows/Linux/Mac), которое по сути является конструктором тестов, не требуя при этом написания какого-либо кода. QA-инженер может просто записать пользовательский сценарий во встроенном браузере, расширить сгенерированные тесты браузерными командами и тестовыми утверждениями, настроить структуру и запустить тесты на выполнение. Puppetry транслирует тестовую спецификацию из удобного для чтения человеком формата (Gherkin) в проект Jest/Puppeteer. Далее он запускает проект и показывает отчет. По сути такой проект может быть включен в цепь непрерывной интеграции «как есть»