Ну в линуксе вроде пока всё по-старому(скорее всего потому что пользователи данной OS не ЦА для «телемоста»). Но даже тот же линукс-клиент попадает под условия лицензионного соглашения, так что даже cli-версия теоретически может быть модифицирована.
Один маленький комментарий может повлиять на что-то большее, не так ли ;).
Теперь точно до 4 числа буду писать/публиковать последнюю часть своего исследования.
Честно говоря — пока еще нет. И причины тут две.
1.Я уехал в теплые страны несколько месяцев назад, так что покупка пока откладывается.
2.У текущего решения есть одна особенность, которая выплыла внезапно, но об этом расскажу в следующей части. Stay tuned.
Наверное джанго можно использовать не только для простых запросов.
К примеру с использованием поддержки JSON(B), кастомного Manager/переопределением objects + RawSQL можно делать уже вещи поинтересней. В джанге очень много основано на переопределении и сделав свой собственный QuerySet на основе стандартного, можно написать свою альтернативу взамен EAV.
А «сырой» SQL… да, может он и очевиден, но зачастую не так удобно поддерживать его после тех кто писал этот SQL.
Если ваш английский достаточно хорош (Pre-Intermediate+) и вы испытываете ту самую пресловутую проблему «плато», то возможно стоит послушать «Breaking the Intermediate Plateau» Part 1 и Part 2
Ответил в личные собщения дабы не разводить здесь полемику о данном аспекте.
В тоже время, если у вас Advanced — возможно пригодится вот этот выпуск подкаста TWIML & AI. Там речь как раз о новых подходах в NLP
Это конечно сугубо моё мнение… но выглядит немного… неоднородно что ли.
Понятно что исходные данные представлены на русском языке и это стоит использовать как есть(недаром же упоминается Word2Vec for Russian). Но графики с различными метриками тоже содержат русские слова(например «Точность», «Нынешний алгоритм»). И если мы можем ожидать что достаточно много русскоговорящих людей на Хабре смогут понять графики с англоязычными подписями, то англоязычные хоть и прочтут её без проблем(теоретически) — споткнутся на русскоязычных подписях.
Также складывается впечатление что статью просто пропустили через автоматический транслятор из одного языка в другой, поправили основные ошибки через чеккер граматики типа Grammarly. Или я ошибаюсь и вы давали её вычитывать как минимум человеку с уровнем Upper Intermediate?
Спасибо за Ваш вопрос. Сперва попробую пояснить почему заполнено 0. О природе исходных данных
Как уже было упомянуто — датасет основан на на PDF отчете (также известном как Enron Statement of Financial Affairs). Компания, которая производила проверку счетов сотрудников/движений по ним — просто не нашла данных по некоторым из них. И поэтому приняла за основу что таких данных и не существует, и посчитала итоговые суммы.
Почему не заполнить средним/чем то еще? Потому что некоторые столбцы содержат очень мало данных (например данные о займах — loan advance) и заполнять пробелы на их основе — просто нелогично(не не может что у 140 человек были займы в одинаковую сумму). Также есть столбцы которые связаны с определенными людьми(director fees — жалованье для управленцев) — среднее по которым не может быть перенесена на всех людей, т.к среди них есть и рядовые сотрудники. Также есть и другие столбцы заполнение которых подобным образом внесет еще большую сумятицу в исходные данные, а как следствие придется перерассчитывать итоговые суммы, поскольку они также не будут совпадать. Иными словами — используя привычное заполнение средним/медианой — мы только исказим исходные данные, а не приблизимся к настоящим значениям.
Может возникнуть резонный вопрос — "А почему значения по email — признакам заполнены средним?" Тут дело в том что данные по ним — как раз неполные. Enron email dataset это только часть всех email сотрудников. Но часть email всё равно отсутствует. Поэтому и использовано среднее значение по всем сотрудникам.
Иными словами, тут используется принцип — "платежи, акции — мы доверяем источнику. поскольку у нас нет причин не доверять и способов доказать это", "email — мы знаем что данные неполные(в текущий момент вроде бы версия 2) — поэтому заполняем средним"
Матрица корреляций и NaN.
Да, можно попытаться посчитать корреляцию на основе данных что есть.Но в тех же финансах нет не одной строчки что не содержит пропусков.
Возможно ли при этом посчитать корреляцию? Что она будет показывать?
Исходя из этого всего и было заменено на 0, дабы сохранить изначальный строй датасета, а не исказить его.
Выражу свое мнение, как человек который разрабатывал приложения для этой системы(Odoo 8/9 тогда,2015-ый год) в течении 10 месяцев.
1. Чтобы создать новый модуль, нужно было написать несколько строк на Python 2, и наваять XML который будет отражать структуру вашего документа.XML для создания приложения в 2015 году? Серьезно?
2.После того как напишите заготовку модуля, вероятно захотите сделать несколько страничек в нем. Да, тоже XML.
3.Даже если вы создали свое приложение, то что вы описывали ранее — теперь хранится в БД. Да, XML шаблоны для отрисовки интерфейса — в БД(Postgres).
4.Локализация — не поддерживает различные варианты окончаний слова. В английском это не проблема(pen/pens), но в русском это выливается в невозможность связать числительные с разными окончаниями(ручка, ручки, ручек)
В общем впечатления от той версии продукта(Odoo 8/9) — очень негативные, даже учитывая три года в 1С =)
Внедряли в одной фирме — скорее всего получился явный Vendor lock.
Единственное чему данная система учит — как не нужно делать, и как читать чужой код, поскольку документация явно слабое место.
Угу, сразу возникает вопрос. Кто целевая аудитория у данной программы обучения?
Наверное не те ребята, что живут в провинции и имеют зарплату немногим более прожиточного минимума(который чуть выше 10тыс в нашей области).
Для них 150 тысяч это возможность неработать целый год и посвящать время самообучению (говорю об этом, поскольку знаю одного парня который хочет стать программистом, но живёт в глубинке где зп явно недостаточно на такие курсы).

Теперь точно до 4 числа буду писать/публиковать последнюю часть своего исследования.
1.Я уехал в теплые страны несколько месяцев назад, так что покупка пока откладывается.
2.У текущего решения есть одна особенность, которая выплыла внезапно, но об этом расскажу в следующей части. Stay tuned.
К примеру с использованием поддержки JSON(B), кастомного Manager/переопределением objects + RawSQL можно делать уже вещи поинтересней. В джанге очень много основано на переопределении и сделав свой собственный QuerySet на основе стандартного, можно написать свою альтернативу взамен EAV.
А «сырой» SQL… да, может он и очевиден, но зачастую не так удобно поддерживать его после тех кто писал этот SQL.
В тоже время, если у вас Advanced — возможно пригодится вот этот выпуск подкаста TWIML & AI. Там речь как раз о новых подходах в NLP
Понятно что исходные данные представлены на русском языке и это стоит использовать как есть(недаром же упоминается Word2Vec for Russian). Но графики с различными метриками тоже содержат русские слова(например «Точность», «Нынешний алгоритм»). И если мы можем ожидать что достаточно много русскоговорящих людей на Хабре смогут понять графики с англоязычными подписями, то англоязычные хоть и прочтут её без проблем(теоретически) — споткнутся на русскоязычных подписях.
Также складывается впечатление что статью просто пропустили через автоматический транслятор из одного языка в другой, поправили основные ошибки через чеккер граматики типа Grammarly. Или я ошибаюсь и вы давали её вычитывать как минимум человеку с уровнем Upper Intermediate?
Добавлено продолжение
Спасибо за Ваш вопрос. Сперва попробую пояснить почему заполнено 0.
О природе исходных данных
Как уже было упомянуто — датасет основан на на PDF отчете (также известном как Enron Statement of Financial Affairs). Компания, которая производила проверку счетов сотрудников/движений по ним — просто не нашла данных по некоторым из них. И поэтому приняла за основу что таких данных и не существует, и посчитала итоговые суммы.
Почему не заполнить средним/чем то еще? Потому что некоторые столбцы содержат очень мало данных (например данные о займах — loan advance) и заполнять пробелы на их основе — просто нелогично(не не может что у 140 человек были займы в одинаковую сумму). Также есть столбцы которые связаны с определенными людьми(director fees — жалованье для управленцев) — среднее по которым не может быть перенесена на всех людей, т.к среди них есть и рядовые сотрудники. Также есть и другие столбцы заполнение которых подобным образом внесет еще большую сумятицу в исходные данные, а как следствие придется перерассчитывать итоговые суммы, поскольку они также не будут совпадать. Иными словами — используя привычное заполнение средним/медианой — мы только исказим исходные данные, а не приблизимся к настоящим значениям.
Может возникнуть резонный вопрос — "А почему значения по email — признакам заполнены средним?" Тут дело в том что данные по ним — как раз неполные. Enron email dataset это только часть всех email сотрудников. Но часть email всё равно отсутствует. Поэтому и использовано среднее значение по всем сотрудникам.
Иными словами, тут используется принцип — "платежи, акции — мы доверяем источнику. поскольку у нас нет причин не доверять и способов доказать это", "email — мы знаем что данные неполные(в текущий момент вроде бы версия 2) — поэтому заполняем средним"
Матрица корреляций и NaN.
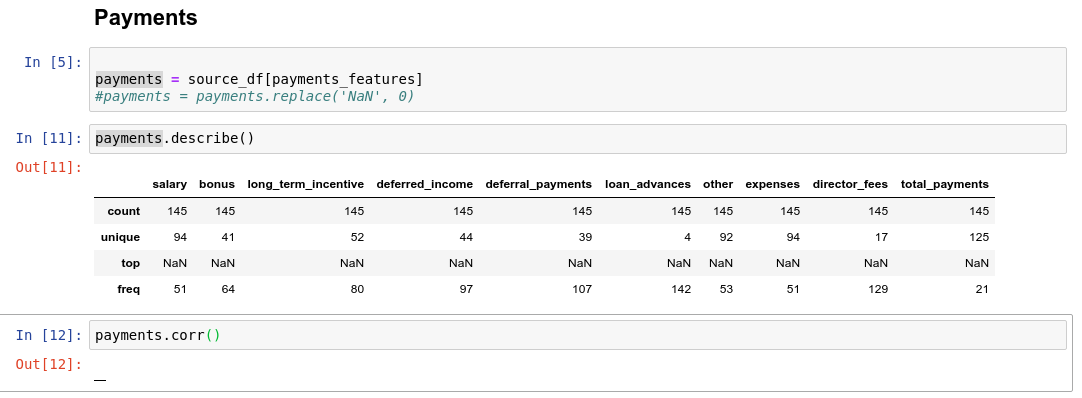
Да, можно попытаться посчитать корреляцию на основе данных что есть.Но в тех же финансах нет не одной строчки что не содержит пропусков.
Возможно ли при этом посчитать корреляцию? Что она будет показывать?
Исходя из этого всего и было заменено на 0, дабы сохранить изначальный строй датасета, а не исказить его.
Не судьба.
1. Чтобы создать новый модуль, нужно было написать несколько строк на Python 2, и наваять XML который будет отражать структуру вашего документа.XML для создания приложения в 2015 году? Серьезно?
2.После того как напишите заготовку модуля, вероятно захотите сделать несколько страничек в нем. Да, тоже XML.
3.Даже если вы создали свое приложение, то что вы описывали ранее — теперь хранится в БД. Да, XML шаблоны для отрисовки интерфейса — в БД(Postgres).
4.Локализация — не поддерживает различные варианты окончаний слова. В английском это не проблема(pen/pens), но в русском это выливается в невозможность связать числительные с разными окончаниями(ручка, ручки, ручек)
В общем впечатления от той версии продукта(Odoo 8/9) — очень негативные, даже учитывая три года в 1С =)
Внедряли в одной фирме — скорее всего получился явный Vendor lock.
Единственное чему данная система учит — как не нужно делать, и как читать чужой код, поскольку документация явно слабое место.
Наверное не те ребята, что живут в провинции и имеют зарплату немногим более прожиточного минимума(который чуть выше 10тыс в нашей области).
Для них 150 тысяч это возможность неработать целый год и посвящать время самообучению (говорю об этом, поскольку знаю одного парня который хочет стать программистом, но живёт в глубинке где зп явно недостаточно на такие курсы).