
Небольшая подборка интересных докладов с конференций для C# и .NET разработчиков за последние несколько лет.

User
Небольшая подборка интересных докладов с конференций для C# и .NET разработчиков за последние несколько лет.
 День Победы!
День Победы!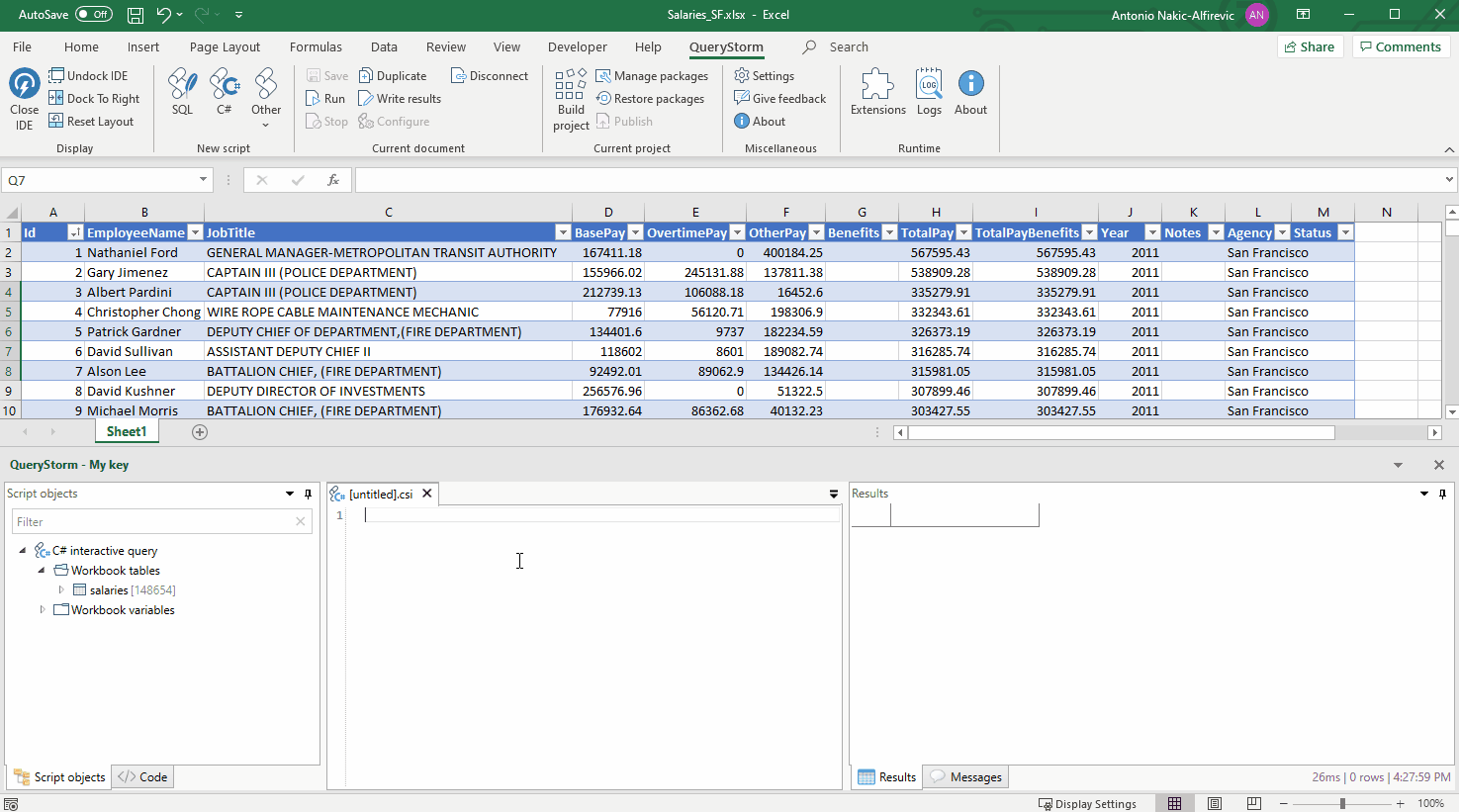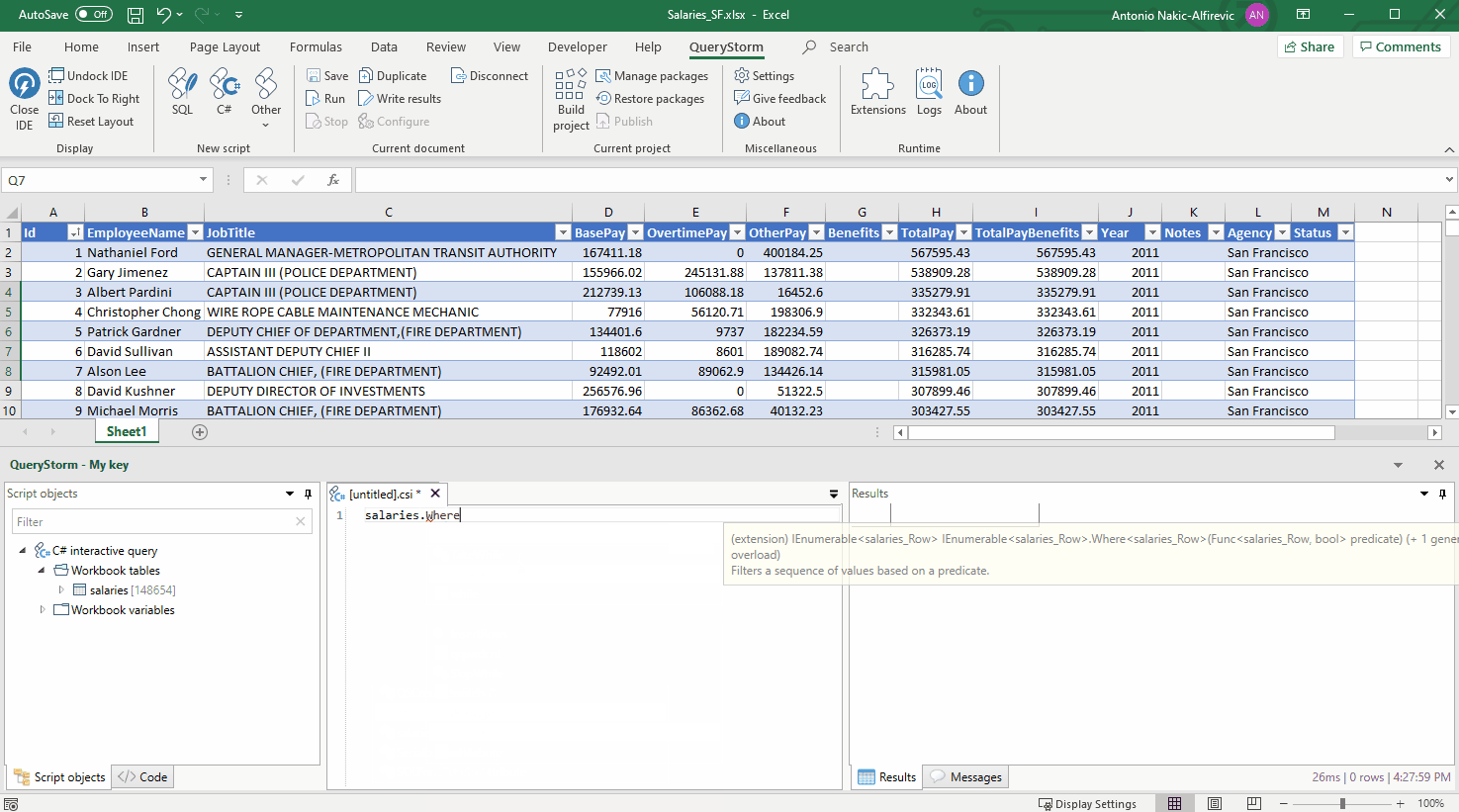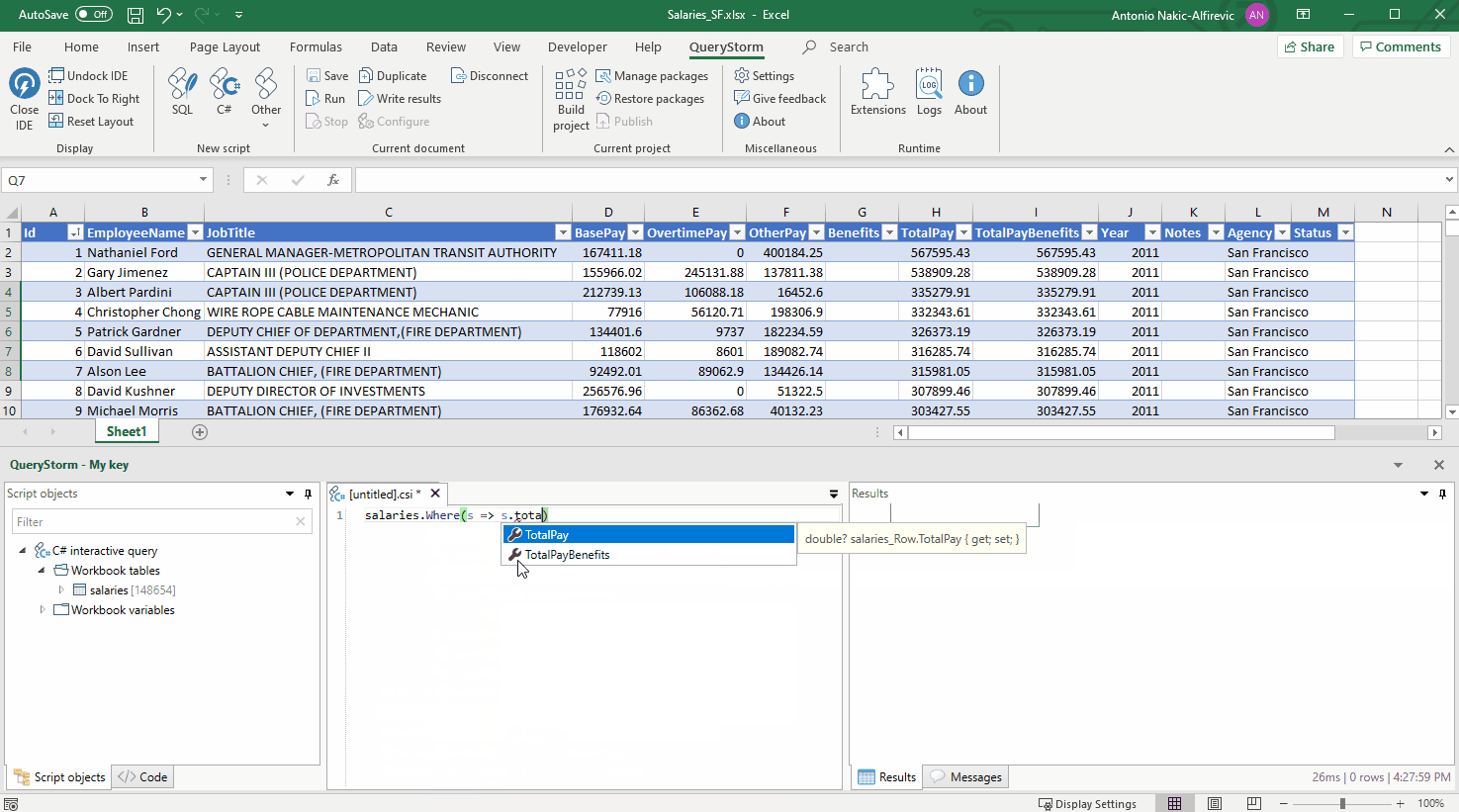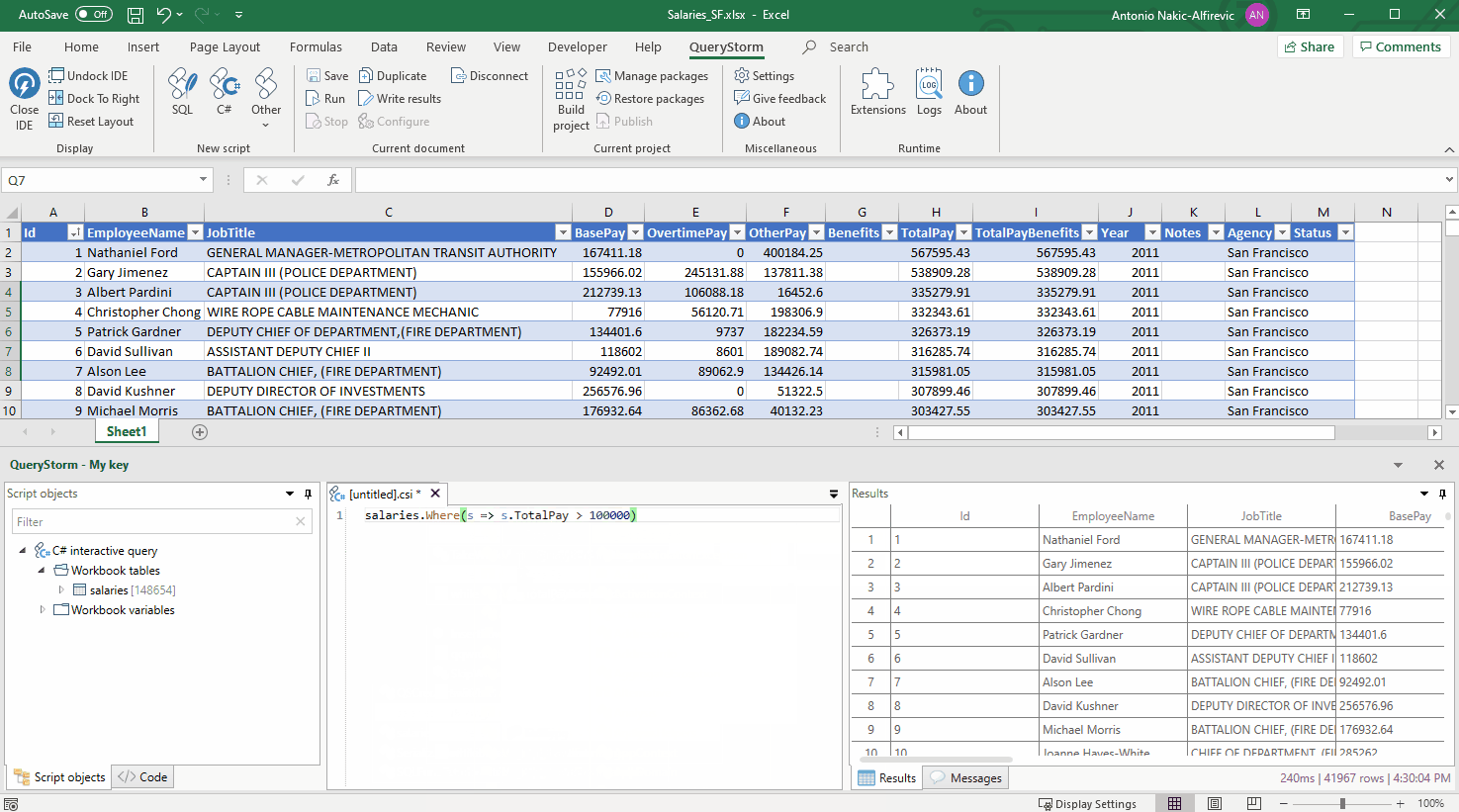

Тема тредпула, скажем так, complex and hard. У меня в жизни было два «осознания», когда я гордо говорил себе — вот теперь-то я точно понял, как устроен и как работает тредпул в дотнете! Впрочем, после второго раза я неоднократно осознавал, как же я ошибался.
Привет всем, кто пишет код для .NET, особенно многопоточный. Редко встретишь потокобезопасный код без потокобезопасных коллекций, а значит, нужно уметь ими пользоваться. Я расскажу о самой популярной из них — ConcurrentDictionary. В ней спрятано на удивление много интересных сюрпризов: как приятных, так и не очень.
Сначала разберём устройство ConcurrentDictionary и вычислительную сложность операций с ним, а затем поговорим об удобных трюках и подводных камнях, связанных с memory traffic и сборкой мусора.

Автоматическая сборка мусора упрощает разработку программ, избавляя от необходимости отслеживать жизненный цикл объектов и удалять их вручную. Однако, чтобы сборщик мусора был полезным инструментом, а не главным врагом на пути к высокой производительности — иногда имеет смысл помогать ему, оптимизируя частые аллокации и аллокации больших объектов.
Для уменьшения аллокаций в современном .NET предусмотрены Span/Memory<T>, stackalloc с поддержкой Span, структуры и другие средства. Но если без объекта в куче не обойтись, например, если объект слишком большой для стека, или используется в асинхронном коде — этот объект можно переиспользовать. И для самых крупных объектов — массивов, в .NET встроены несколько реализаций ArrayPool<T>.
В этой статье я расскажу о внутреннем устройстве реализаций ArrayPool<T> в .NET, о подводных камнях, которые могут сделать пулинг неэффективным, о concurrent-структурах данных, а также о пулинге объектов, отличных от массивов.
Заглянуть «под капот» кода или посмотреть на внутреннее устройство CLR можно с помощью множества инструментов. Этот пост родился из твита, и я должен поблагодарить всех, кто помог составить список подходящих инструментов. Если я пропустил какие-то из них, напишите в комментариях.
Во-первых, я должен упомянуть, что хороший отладчик уже присутствует в Visual Studio и VSCode. Также существует множество хороших (коммерческих) профилировщиков .NET и инструментов мониторинга приложений, на которые стоит взглянуть. Например, недавно я попробовал поработать с Codetrack и был впечатлён его возможностями.
Однако оставшийся пост посвящён инструментам для выполнения отдельных задач, которые позволят лучше понять, что происходит. Все инструменты имеют открытый исходный код.


В новой версии .NET улучшилась производительность методов Min, Max, Average и Sum для массивов и списков. Как вы думаете, во сколько раз увеличилась скорость их выполнения? В 2 раза, в 5? Нет, они стали гораздо быстрее. Посмотрим, как этого удалось достичь.

Всем привет! Недавно мы провели два офлайн-митапа по .NET. Разработчики выступили с семью докладами — от рассказа о реальной стоимости операций под капотом платформы .NET до разбора межсервисных интеграций. Митапы прошли в Томске и Нижнем Новгороде — городах, где работают Центры разработки Тинькофф.
В перерывах между выступлениями и после участники митапов общались в неформальной обстановке на кофе-брейках, обменивались опытом и рабочими кейсами. Всех, кому интересна .NET-разработка, приглашаем под кат: мы подробнее расскажем о докладах, поделимся видео с выступлениями и полезными ссылками.

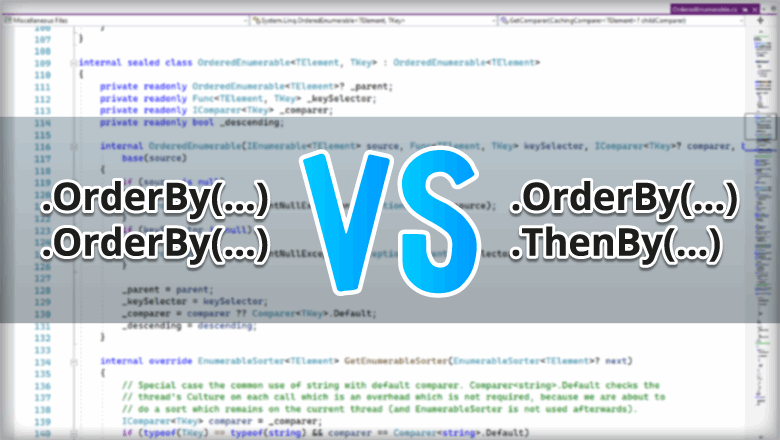
Предположим, есть задача: нужно отсортировать коллекцию по нескольким ключам. В C# это можно сделать с помощью вызовов OrderBy().OrderBy() или OrderBy().ThenBy(). Но в чём разница между этими вызовами? Чтобы ответить на этот вопрос, придётся покопаться в исходниках.
Статья состоит из трёх основных разделов:
C# 9 дал долгожданную возможность кодогенерации, интегрированную с компилятором. Тем, кто мечтал избавиться от тысяч строк шаблонного кода или попробовать метапрограммирование, стало проще это сделать.
Ранее Андрей Дятлов TessenR выступил на конференции DotNext с докладом «Source Generators в действии». А теперь, пока мы готовим следующий DotNext, сделали для Хабра текстовую расшифровку его доклада.

Что вообще такое эти Source Generators? Как их использовать? Как предоставить пользователю вашего генератора необходимую гибкость конфигурации и понятные сообщения о возникающих проблемах? Как разобраться, когда что-то пошло не так?
Ответы на все эти и другие вопросы — в тексте.
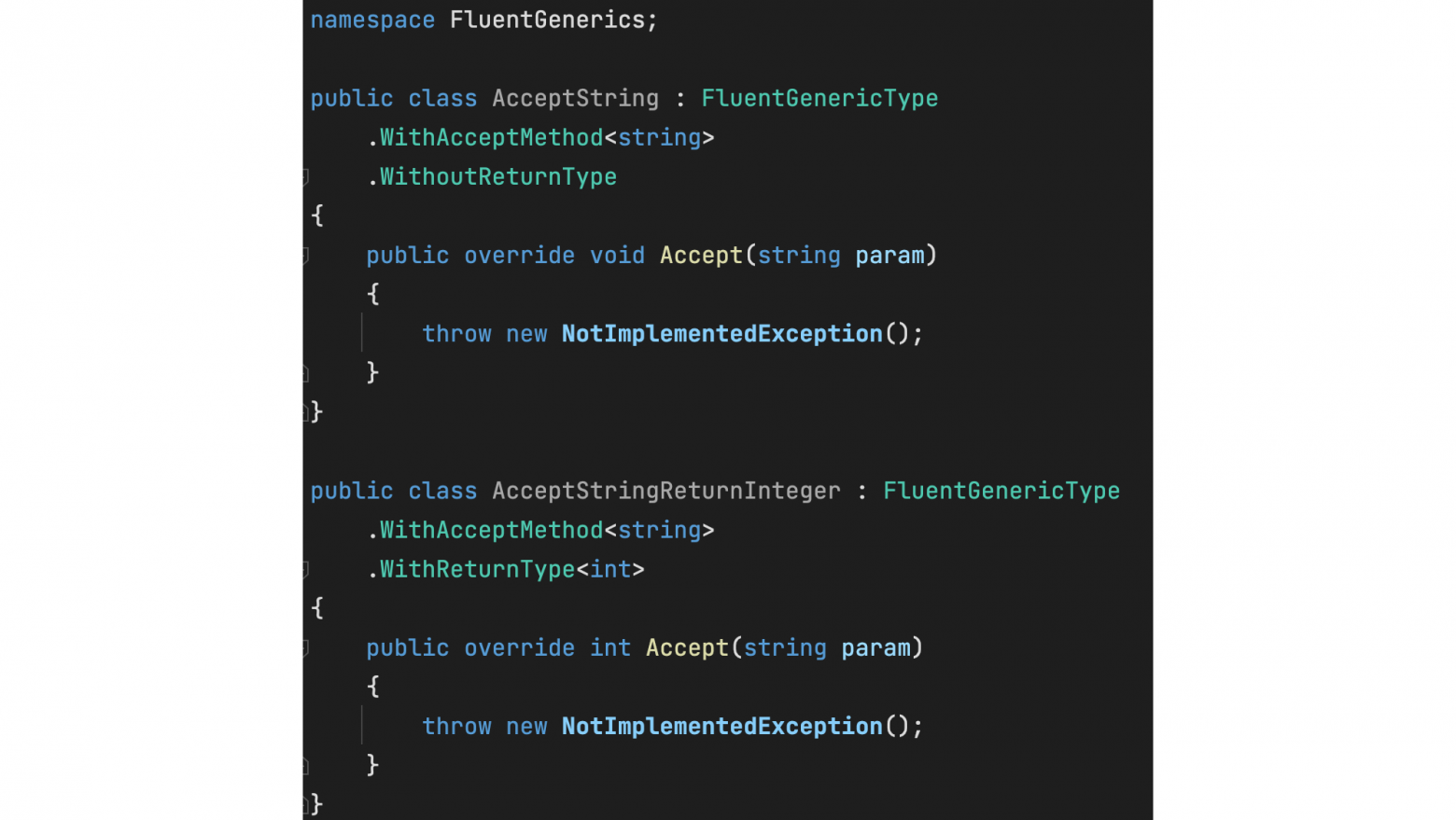
Дженерики - мощная фича доступная во многих статически типизированных языках программирования. С их помощью можно писать код, который постоянно работает со множеством разных типов, делая упор на их общие особенности, нежели на сами типы. Они позволяют создавать гибкие и переиспользуемые компоненты без нужды в дублировании кода и жертвы безопасности типов.
Несмотря на то, что дженерики давно в C#, мне всё же удаётся найти новые интересные способы их применения. Например, в одной из моих предыдущих статей я написал об уловке, позволяющей добиться return type inference, что может облегчить работу с контейнерными union types.
Недавно, мне также довелось работать над кодом, использующим дженерики. Тогда передо мной встала нетипичная задача: было необходимо определить сигнатуру, где все типовые параметры опциональны и могут использоваться друг с другом в произвольных комбинациях. Первая попытка подступиться к решению заключалась в манипуляциях с перегрузками типов, однако такой подход оказался довольно непрактичным и не увлекательным.
После нескольких экспериментов, я нашёл способ решить проблему элегантно, используя подход схожий с паттерном проектирования fluent interface, который был применён не к объектам, а к типам. Мой подход предлагает domain-specific language, который позволяет разработчику построить нужный тип за несколько логических шагов, последовательно его "конфигурируя".
В данной статье я расскажу, что из себя представляет этот подход и как его можно использовать для того, чтобы сложные обобщённые типы писать просто.

В предыдущей публикации мы рассмотрели некоторые базовые вопросы относительно потоков и пулов потоков и готовы двигаться дальше. Давайте проведём эксперимент и найдём правильный объём работы для пула потоков. Чтобы его издержки не давлели над объёмом полезной работы
⚠️ Материал средней сложности
С другой стороны, показанные примеры доказывают, что на производительность сильно влияет гранулярность элементов работы. Имеется ввиду, конечно же, длительность работы делегатов. Чтобы достичь хороших показателей, гранулярность работы не может быть абы какой: она должна быть правильной. И помимо планирования задач на ThreadPool, планировать их можно также как через TPL так и через какой-либо свой собственный пул потоков. Например, если взять обычный ThreadPool, то можно примерно измерить издержки алгоритмов ThreadPool в тактах Time Stamp Counter счётчика времени (можно, конечно и в чём-то более привычном типа микросекунд, но там на многих сценариях вполне могут быть нули)

Эта текст покрывает ответы на некоторые совсем базовые вопросы и вместе с тем сразу погружает в проблематику получения ответа на вопрос: "как работать лучше? однопоточно, многопоточно или многопоточно, но на ThreadPool?". Ответ на этот вопрос может изначально показаться очень простым и понятным, однако реальность совершенно иная: всё как и везде сильно зависит от ситуации: от типа задачи, от её размера, от прочих условий, которые так просто в голову сами собой не придут.
А потому мы пройдёмся в первую очередь по IO-/CPU-bound операциям, стоимости создания потока, базовым основам работы пула потоков (но только основы), а далее -- углубимся в анализ чёрного ящика: от чего зависит производительность пула потоков? Каков объём работы приемлим для того чтобы в него планировать?
Закончим мы главу несколькими, возможно, пугающими выводами об объемах работы, приемлимой для того чтобы обеспечить производительную работу приложения на пуле потоков.
Также отмечу, что материал постепенно переходит от начального уровня сложности ? через ⚠️ средний уровень к ☠️ высокому, о чём вы сможете узнать по пиктограммам.

Здравствуйте, меня зовут Екатерина, уже 11 лет я работаю учителем в школе. Полгода назад я решила сменить профессию и пошла на курсы тестировщиков в одну разрекламированную онлайн школу, разочаровалась в ней, а теперь учусь в другой. Мне стало интересно сравнить методики преподавания, чтобы понять, что-то не так со мной или с курсом? Первая часть находится тут.
Напоминаю, что это очень субъективное мнение рядовой студентки. Вторая часть тут.