Replit Agent программиста не заменит! Или как мы пробовали писать код с помощью нейросети
Medium
10 min
Case

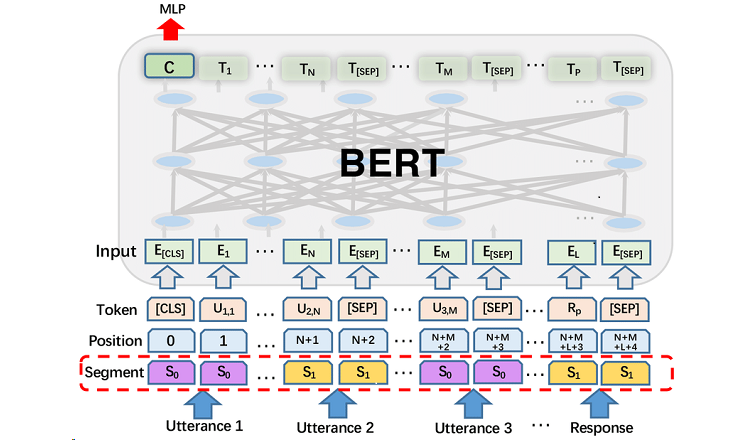
Привет, Хабр! Это компания Raft и я — руководитель AI продуктов Евгений Кокуйкин. А на фото выше — троица из нашей команды — техлид Саша Константинов, AI Project Manager & QA Lead Толя Разумовский и Data scientist Арсений Пименов на конференции Олега Бунина AIConf. Недавно в сети появился Replit Agent с многообещающими заявлениями. Мол, этот инструмент пишет код лучше программистов и скоро их заменит. Хотя в Raft мы и пишем код по старинке — вручную, но следим за технологиями и стремимся использовать новшества там, где это может быть полезно. Решили испытать Replit Agent в деле и даже устроили внутри команды мини-хакатон. Делимся впечатлениями.