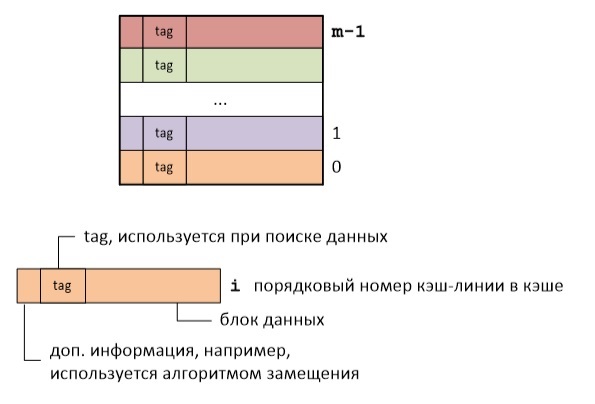
Давайте знакомиться: меня зовут Анатолий Семятнёв, я и моя команда разрабатываем ПО для опорных сетей 5G в YADRO. В IT-сфере работаю давно, и мой опыт в основном связан с языком С: занимался Board Support Package (BSP) и драйверами, много работал с операционной системой QNX.
До того, как начал полноценно работать на С++, сталкивался с языком в нулевые, писал на С++98. Тем не менее все это время я краем глаза поглядывал, что происходит в С++, и хотел вернуться к программированию на этом языке. Читал книги, делал пет-проекты, смотрел записи конференций и митапов по С++. А когда пришел в YADRO, стал писать на С++.
Мне с ходу дали большую фичу для имплементации, я писал много кода, и получал комментарии от коллег. В этом материале собрал все, что изучил или вспомнил по итогам код-ревью. Что рассмотрим в статье:
• Ключевые концепции — explicit, final, default, string — и как их использовать.
• Инициализацию мемберов с помощью пустого брейс-листа.
• Синглтон Майерса в корутинах.
• «Смертельный ромб» и все, что связано с виртуальным наследованием.