На определенном этапе своего проекта AI вам придется решить, какую среду машинного обучения вы будете использовать. Для некоторых задач традиционных алгоритмов машинного обучения будет достаточно. Однако, если вы работаете с большим объемом текстов, изображений, видео или речевых данных, рекомендуется использовать глубокое обучение.
Итак, какую среду глубокого обучения выбрать? Эта статья посвящена сравнительному анализу существующих сред глубокого обучения.

Среды глубокого обучения упрощают разработку и обучение моделей глубокого обучения за счет предоставления простейших элементов высокого уровня для сложных и ненадежных математических преобразований, например, функции градиентного спуска, обратного распространения и логического вывода.
Правильно выбрать среду нелегко, потому что эта сфера до сих пор развита мало, и на сегодняшний момент не существует абсолютно выигрышного варианта. Также выбор среды может зависеть от ваших целей, ресурсов и команды.
Мы сделаем упор на средах, у которых есть версии, оптимизированные Intel, и которые могут эффективно работать на новых ЦП (например, процессорах Intel Xeon Phi), оптимизированных для матричного умножения.
Оценку сред мы производили в два этапа.
Каждую среду мы оценили исходя из активности сообщества и оценок участников.
GitHub
Stack Overflow
По результатам нашего анализа популярных сред мы составили следующую таблицу для оценки каждой среды по популярности и активности.
Общая популярность и активность разных сред
Согласно этим данным, наиболее популярными средами являются TensorFlow, Caffe, Keras, Microsoft Cognitive Toolkit (ранее известна как CNTK), MXNet, Torch, Deeplearning4j (DL4J) и Theano. Популярность среды neon также растет. Мы расскажем об этих средах в следующем разделе.
Среды глубокого обучения различаются по своему уровню функциональности. Некоторые из них, такие как Theano и TensorFlow, позволяют определять нейронные сети произвольного уровня сложности, используя самые базовые структурные элементы. Среды такого типа даже можно назвать языками. Другие среды, такие как Keras, являются движками или оболочками, призванными повысить производительность разработчиков, но ограниченными в функциональности из-за более высокого уровня абстракции.
При выборе среды глубокого обучения сначала необходимо выбрать среду низкого уровня. Оболочка высокого уровня может оказаться хорошим дополнением, но она не обязательна. По мере созревания экосистемы все больше сред низкого уровня будут дополняться спутниками более высокого уровня.
Caffe представляет собой среду глубокого обучения, которая создавалась с учетом выражения, скорости и модульного принципа. Она была создана компанией Berkeley AI Research (BAIR) при участии членов сообщества. Янгквин Джиа (Yangqing Jia) создал проект во время своей работы над докторской диссертацией в Калифорнийском университете в Беркли. Библиотека Caffe издана под лицензией 2 статьи о распространении программного обеспечения университета Беркли.
Важные особенности:
Microsoft Cognitive Toolkit (прежнее название — CNTK) — это унифицированный набор инструментов для глубокого обучения, который представляет нейронные сети как серию вычислительных действий через направленный граф. В графе листья представляют входные значения или параметры сети, а другие узлы — операции матрицы в ответ на входные значения. Набор инструментов позволяет легко реализовывать и комбинировать популярные типы моделей, например, упреждающие глубокие нейронные сети, сверточные нейронные сети, рекуррентные нейронные сети (RNN) и сети с долгой краткосрочной памятью (LSTM). Он реализует обучение по принципу стохастического градиентного спуска (SGD, обратное распространение ошибки) с автоматической дифференциацией и распараллеливанием по нескольким графическим процессорам и серверам. Библиотека доступна по лицензии на ПО с открытым исходным кодом с апреля 2015 года.
Важные особенности.
Keras представляет собой API для нейронных сетей высокого уровня, написанный на Python. Эту библиотеку можно использовать дополнительно к TensorFlow или Theano. Библиотека Keras главным образом предназначена для ускорения экспериментов. Важным условием удачного исследования является возможность перехода от замысла к результату с минимальной возможной задержкой.
Важные особенности.
Deeplearning4j (DL4J) — это первая библиотека распределенного глубокого обучения с открытым исходным кодом для коммерческой эксплуатации, написанная для Java* и Scala*. Библиотека DL4J интегрирована с Hadoop* и Apache Spark* и предназначена для использования в корпоративных средах на распределенных графических процессорах (GPU) и ЦП. DL4J представляет собой новейшую готовую библиотеку, больше ориентированную на стандарт, чем на настройку и обеспечивающую быстрое создание прототипов для специалистов, не являющихся профессиональными исследователями. DL4J можно настраивать при масштабировании. Библиотека доступна по лицензии Apache 2.0, при этом все производные продукты от DL4J принадлежат их создателям. DL4J позволяет импортировать модели нейронных сетей из большинства основных сред через Keras, включая TensorFlow, Caffe, Torch и Theano, закрывая брешь между экосистемой Python и виртуальной машиной Java (JVM) с помощью общего набора инструментов, предназначенного для аналитиков-исследователей, инженеров данных и разработчиков. В качестве прикладного программного интерфейса DL4J на Python используется Keras.
Важные особенности.
MXNet представляет собой простую, универсальную и ультрамасштабируемую среду для глубокого обучения. Среда поддерживает современные модели глубокого обучения, включая сверточные нейронные сети и LSTM. Библиотека берет свое начало в научной среде и является продуктом совместной и индивидуальной работы исследователей из нескольких ведущих университетов. Библиотека, активно поддерживаемая компанией Amazon, разрабатывалась с особым упором на машинное зрение, обработку и понимание речи и языка, порождающие модели, сверточные и рекуррентные нейронные сети. MXNet позволяет определять, обучать и развертывать сети в самых разных условиях: начиная от мощных облачных инфраструктур и заканчивая мобильными и подключенными устройствами. Библиотека обеспечивает универсальную среду с поддержкой многих распространенных языков, давая возможность использовать как императивные, так и символические программные конструкции. Библиотека MXNet также занимает мало места. Благодаря этому ее можно эффективно масштабировать на нескольких графических процессорах и машинах, что хорошо подходит для обучения на больших наборах данных в облачной среде.
Важные особенности.
Благодаря языку на основе Python с открытым исходным кодом и набору библиотек для разработки моделей глубокого обучения, neon является быстрым, мощным и простым в использовании инструментом.
Важные особенности.
TensorFlow представляет собой открытую программную библиотеку для числовых вычислений с использованием графов потоков данных. Узлы в графе представляют математические операции, а ветви графа — многомерные массивы данных (тензоры), которыми они обмениваются. Благодаря универсальной архитектуре вычисления можно развертывать на одном или нескольких ЦП или графических процессорах настольного компьютера, сервера или мобильного устройства с одним API. TensorFlow изначально был разработан научными сотрудниками и инженерами, работавшими в группе Google Brain в подразделении Google по изучению машинного интеллекта, для проведения машинного обучения и изучения нейронных сетей, однако благодаря своему общему характеру систему также можно использовать в других областях.
Theano — это библиотека Python, предназначенная для определения, оптимизации и оценки математических выражений, особенно выражений с многомерными массивами (numpy.ndarray). Theano позволяет достичь скоростей работы с большими объемами данных, которые могут конкурировать только со специально изготовленными программами на языке СИ. Theano также превосходит СИ на ЦП во много раз за счет использования последних версий графических процессоров. Theano совмещает в себе аспекты системы компьютерной алгебры (СКА) с аспектами оптимизирующего компилятора. С помощью Theano также можно создавать пользовательский код на языке СИ для многих математических операций. Такое сочетание СКА с оптимизирующей компиляцией особенно хорошо подходит для задач, в которых сложные математические выражения оцениваются многократно, поэтому для них важна скорость оценки. В ситуациях, когда оценивается множество разных выражений только один раз, Theano помогает уменьшить количество непроизводительных компиляций и анализов, по-прежнему обеспечивая символьные функции, такие ка�� автоматическая дифференциация.
Важные особенности.
Torch представляет собой научную вычислительную среду с широкой поддержкой алгоритмов машинного обучения, в которой упор сделан на графические процессоры (GPU). Она отличается удобством в использовании и быстродействием благодаря простому и быстрому языку скриптов, LuaJIT и базовой программе на основеC/CUDA.
Важные особенности.
Большинство сред имеют общие черты: скорость, портативность, сообщество и экосистема, простота разработки, совместимость и масштабируемость.
Входные данные для процесса поиска в среде для нашего проекта создания приложения автоматического видеомонтажа должны удовлетворять следующим требованиям.
Производительность разработчиков представляет большую важность, особенно на этапе создания прототипов, поэтому необходимо выбирать среду, соответствующую навыкам и знаниям участников вашей команды. По этой причине мы исключим все среды, основывающиеся на альтернативных языках.
Большинство проектов, включая наш учебный проект, используют только некоторый существующий алгоритм нейронной сети, такой как AlexNet или LSTM. В нашем случае должна подойти любая среда глубокого обучения. Однако, если вы работаете над исследовательским проектом (например, разрабатываете новый алгоритм, тестируете новую гипотезу или оптимизируете библиотеку), высокоуровневые системы, такие как Keras, вам не подойдут. Среды низкого уровня, скорее всего, потребуют от вас написания нового алгоритма на языке C++.
Наш перечень (сред глубокого обучения) остается прежним.
Наш учебный проект предполагает решение двух традиционных задач глубокого обучения:
все среды поддерживают сверточные нейронные сети (применяются в основном для обработки изображений) и рекуррентные нейронные сети (применяются для моделирования последовательности).
Наш перечень остается прежним:
Поскольку у нас нет большого набора данных (например, 6000 аннотированных изображений) для обучения модели нашего проекта, мы должны использовать предварительно обученные модели.
Все выбранные среды поддерживают парки моделей. Кроме того, существуют преобразователи, позволяющие использовать модели, обученные с помощью другой библиотеки. Библиотека Caffe первой вошла в парк моделей и имеет самый широкий выбор моделей. Существуют средства для преобразования моделей парка Caffe в модель практически любой другой среды:
У всех этих сред также есть свои собственные парки моделей.
Наш перечень остается прежним:
Модель можно определить двумя способами: с помощью файла конфигурации (например, при использовании Caffe) или с помощью скриптов (в других средах). Файлы конфигурации удобны с точки зрения портативности модели, но их сложно использовать при создании сложной архитектуры нейронной сети (например, попробуйте вручную скопировать слои в ResNet-101). С другой стороны, с помощью скриптов можно создавать сложные нейронные сети с минимальным повторением кода, однако возможность переноса такого кода в другую среду будет под вопросом. Обычно предпочтительнее использовать скрипты, потому что переходы из одной среды в другую в рамках одного проекта случаются редко.
Теперь наш перечень изменится следующим образом:
Библиотека Intel Math Kernel Library (Intel MKL) для векторного и матричного умножения была доработана для глубокого обучения и теперь включает интегрированную многоядерную архитектуру Intel Many Integrated Core Architecture. Это процессорная архитектура с широким распараллеливанием, которая существенно ускоряет процессы глубокого обучения на ЦП. Все существующие на сегодняшний день конкурирующие среды уже интегрировали Intel MKL и предлагают версии, оптимизированные Intel.
Важно также знать, поддерживается ли распределенное обучение нескольких ЦП. Исходя из этих критериев, наш измененный перечень будет выглядеть следующим образом:
TensorFlow поддерживает специальный инструмент, который носит название TensorFlow Serving. Он берет обученную модель TensorFlow в качестве входных данных и преобразует ее в веб-сервис, позволяющий оценивать входящие запросы. Если вы собираетесь использовать обученную модель на мобильном устройстве, TensorFlow Mobile обеспечивает немедленную компрессию модели.
Подробнее о TensorFlow Serving
TensorFlow Mobile
MXNet обеспечивает развертывание через слияние, при котором модель вместе со всеми необходимыми привязками помещается в автономный файл. Такой файл потом можно перенести на другую машину, и получить к нему доступ через другие языки программирования. Например, его можно использовать на мобильном устройстве. Подробнее.
Microsoft Cognitive Toolkit (предыдущее название — CNTK) обеспечивает развертывание модели через облачную среду машинного обучения Azure*. Мобильные устройства пока не поддерживаются. Их поддержка ожидается в следующей версии. Подробнее.
Хотя мы не собираемся развертывать готовое приложение на мобильном устройстве, в некоторых ситуациях такая возможность может быть весьма кстати. Например, представьте приложение для видеомонтажа, с помощью которого можно будет создавать видео из только что сделанных снимков (такая функция уже доступна в Google Photos).
Теперь у нас осталось два конкурента: TensorFlow и MXNet. В конце концов команда, работающая над этим проектом, решила использовать библиотеку TensorFlow в связке с Keras, потому что у нее более активное сообщество, у участников команды есть опыт работы с этими инструментами, а также потому что для TensorFlow зафиксировано больше успешных проектов. См. перечень пользователей TensorFlow.
В этой статье мы представили несколько популярных сред для глубокого обучения и сравнили их по ряду критериев. Простота создания прототипов, развертывания и отладки модели, наряду с размером сообщества и масштабируемостью на нескольких машинах, являются одними из самых важных критериев, на которые следует ориентироваться при выборе среды глубокого обучения. Все современные среды сейчас поддерживают сверточные и рекуррентные нейросети, имеют парки предварительно обученных моделей и предлагают версии, оптимизированные для современных процессоров Intel Xeon Phi. Как показал наш анализ, для целей нашего проекта прекрасным выбором будет Keras на основе версии TensorFlow, оптимизированной Intel. Другим удачным вариантом будет библиотека MXNet, оптимизированная Intel.
Хотя по результатам этого сравнительного анализа победила библиотека TensorFlow, мы не учитывали эталоны сравнения, которые имеют ключевое значение. Мы планируем написать отдельную статью, в которой сравним время вывода и обучения библиотек TensorFlow и MXNet для широкого набора моделей глубокого обучения, чтобы определить окончательного победителя.
Итак, какую среду глубокого обучения выбрать? Эта статья посвящена сравнительному анализу существующих сред глубокого обучения.
Общая информация
Среды глубокого обучения упрощают разработку и обучение моделей глубокого обучения за счет предоставления простейших элементов высокого уровня для сложных и ненадежных математических преобразований, например, функции градиентного спуска, обратного распространения и логического вывода.
Правильно выбрать среду нелегко, потому что эта сфера до сих пор развита мало, и на сегодняшний момент не существует абсолютно выигрышного варианта. Также выбор среды может зависеть от ваших целей, ресурсов и команды.
Мы сделаем упор на средах, у которых есть версии, оптимизированные Intel, и которые могут эффективно работать на новых ЦП (например, процессорах Intel Xeon Phi), оптимизированных для матричного умножения.
Критерии оценки
Оценку сред мы производили в два этапа.
- Сначала мы их быстро оценили на предмет их соответствия базовому критерию активности сообщества.
- После этого мы выполнили более глубокий и тщательный анализ каждой среды.
Предварительная оценка
Каждую среду мы оценили исходя из активности сообщества и оценок участников.
GitHub
- Звезды репозитория (отслеживание интересных проектов)
- Форки репозитория (свободное экспериментирование с изменениями)
- Количество коммитов за последний месяц (показывает, активен ли проект)
Stack Overflow
- Количество заданных и отвеченных вопросов по программированию
- Неформальный рейтинг популярности по цитированию (веб-поисковики, статьи, блоги и т. д.)
Подробный анализ
- Каждая среда была тщательно проанализирована, исходя из следующих критериев:
- Наличие предварительно обученных моделей.
- Модель лицензирования.
- Подключение к исследовательскому университету или академии.
- Наличие информации о масштабных развертываниях уважаемыми компаниями.
- Эталоны сравнения:
- Наличие выделенной облачной среды, оптимизированной под библиотеку;
- Наличие средств отладки (например, визуализация и контрольные точки модели).
- Обучение;
- Производительность инженерного труда;
- Совместимость (поддерживаемые языки для написания приложений);
- Open Source;
- Поддерживаемые операционные системы и платформы;
- Язык реализации среды.
- Поддерживаемые семейства алгоритмов и модели глубокого обучения
Среды глубокого обучения
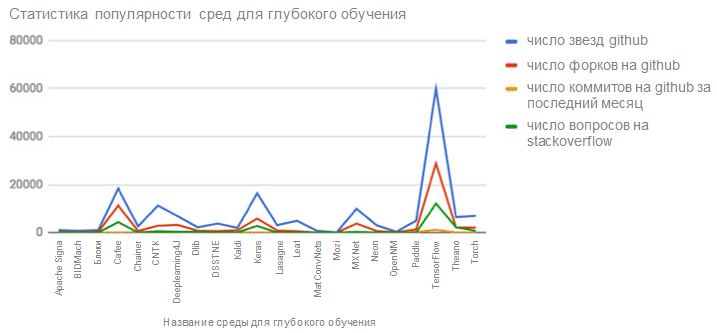
По результатам нашего анализа популярных сред мы составили следующую таблицу для оценки каждой среды по популярности и активности.
Общая популярность и активность разных сред
| Среда глубокого обучения | Количество звезд GitHub | Количество форков GitHub | Количество коммитов GitHub за последний месяц | Количество вопросов Stack Overflow |
|---|---|---|---|---|
| TensorFlow | 60 030 | 28 808 | 1127 | 12 118 |
| Caffe | 18 354 | 11 277 | 12 | 4355 |
| Keras | 16 344 | 5788 | 71 | 2754 |
| Microsoft Cognitive Toolkit | 11 250 | 2823 | 337 | 545 |
| MXNet | 9951 | 3730 | 230 | 289 |
| Torch | 6963 | 2062 | 7 | 722 |
| Deeplearning4J | 6800 | 3168 | 172 | 316 |
| Theano | 6417 | 2154 | 100 | 2207 |
| Среда neon | 3043 | 665 | 38 | 0 |
Согласно этим данным, наиболее популярными средами являются TensorFlow, Caffe, Keras, Microsoft Cognitive Toolkit (ранее известна как CNTK), MXNet, Torch, Deeplearning4j (DL4J) и Theano. Популярность среды neon также растет. Мы расскажем об этих средах в следующем разделе.
Подробнее о самых популярных средах
Среды глубокого обучения различаются по своему уровню функциональности. Некоторые из них, такие как Theano и TensorFlow, позволяют определять нейронные сети произвольного уровня сложности, используя самые базовые структурные элементы. Среды такого типа даже можно назвать языками. Другие среды, такие как Keras, являются движками или оболочками, призванными повысить производительность разработчиков, но ограниченными в функциональности из-за более высокого уровня абстракции.
При выборе среды глубокого обучения сначала необходимо выбрать среду низкого уровня. Оболочка высокого уровня может оказаться хорошим дополнением, но она не обязательна. По мере созревания экосистемы все больше сред низкого уровня будут дополняться спутниками более высокого уровня.
Caffe
Caffe представляет собой среду глубокого обучения, которая создавалась с учетом выражения, скорости и модульного принципа. Она была создана компанией Berkeley AI Research (BAIR) при участии членов сообщества. Янгквин Джиа (Yangqing Jia) создал проект во время своей работы над докторской диссертацией в Калифорнийском университете в Беркли. Библиотека Caffe издана под лицензией 2 статьи о распространении программного обеспечения университета Беркли.
Важные особенности:
- выразительная архитектура способствует применению и инновационным разработкам;
- расширяемый код стимулирует активные разработки;
- скорость — Caffe предлагает один из самых быстрых вариантов внедрения сверточных нейронных сетей (CNN).
- Используется для научно-исследовательских проектов, прототипов стартапов и даже масштабных производственных приложений в области зрения, речи и мультимедиа.
Microsoft Cognitive Toolkit
Microsoft Cognitive Toolkit (прежнее название — CNTK) — это унифицированный набор инструментов для глубокого обучения, который представляет нейронные сети как серию вычислительных действий через направленный граф. В графе листья представляют входные значения или параметры сети, а другие узлы — операции матрицы в ответ на входные значения. Набор инструментов позволяет легко реализовывать и комбинировать популярные типы моделей, например, упреждающие глубокие нейронные сети, сверточные нейронные сети, рекуррентные нейронные сети (RNN) и сети с долгой краткосрочной памятью (LSTM). Он реализует обучение по принципу стохастического градиентного спуска (SGD, обратное распространение ошибки) с автоматической дифференциацией и распараллеливанием по нескольким графическим процессорам и серверам. Библиотека доступна по лицензии на ПО с открытым исходным кодом с апреля 2015 года.
Важные особенности.
- Скорость и масштабируемость: обучает и анализирует алгоритмы глубокого обучения быстрее, чем другие доступные наборы инструментов, эффективно масштабируясь в разных средах.
- Качество на уровне коммерческих продуктов.
- Совместимость: обладает самой выразительной и простой в использовании архитектурой с известными языками и сетями, такими как C++ и Python*.
Keras
Keras представляет собой API для нейронных сетей высокого уровня, написанный на Python. Эту библиотеку можно использовать дополнительно к TensorFlow или Theano. Библиотека Keras главным образом предназначена для ускорения экспериментов. Важным условием удачного исследования является возможность перехода от замысла к результату с минимальной возможной задержкой.
Важные особенности.
- Удобство для пользователя: сводит к минимуму количество действий пользователя, необходимых в стандартных ситуациях, а также обеспечивает четкие и практические инструкции в случае ошибки пользователя.
- Модульное исполнение: модель рассматривается как последовательность или граф автономных полностью конфигурируемых модулей, которые можно соединить вместе с минимальным числом ограничений.
- Простое расширение: новые модули легко добавляются в виде новых классов и функций, а существующие модули обеспечивают достаточно примеров.
DeepLearning4j
Deeplearning4j (DL4J) — это первая библиотека распределенного глубокого обучения с открытым исходным кодом для коммерческой эксплуатации, написанная для Java* и Scala*. Библиотека DL4J интегрирована с Hadoop* и Apache Spark* и предназначена для использования в корпоративных средах на распределенных графических процессорах (GPU) и ЦП. DL4J представляет собой новейшую готовую библиотеку, больше ориентированную на стандарт, чем на настройку и обеспечивающую быстрое создание прототипов для специалистов, не являющихся профессиональными исследователями. DL4J можно настраивать при масштабировании. Библиотека доступна по лицензии Apache 2.0, при этом все производные продукты от DL4J принадлежат их создателям. DL4J позволяет импортировать модели нейронных сетей из большинства основных сред через Keras, включая TensorFlow, Caffe, Torch и Theano, закрывая брешь между экосистемой Python и виртуальной машиной Java (JVM) с помощью общего набора инструментов, предназначенного для аналитиков-исследователей, инженеров данных и разработчиков. В качестве прикладного программного интерфейса DL4J на Python используется Keras.
Важные особенности.
- Выгодно использует последние библиотеки для распределенных вычислений.
- Открытые библиотеки, которые обслуживаются сообществом разработчиков и командой Skymind.
- Написана на Java и совместима с любым языком JVM, например, со Scala, Clojure и Kotlin.
MXNet
MXNet представляет собой простую, универсальную и ультрамасштабируемую среду для глубокого обучения. Среда поддерживает современные модели глубокого обучения, включая сверточные нейронные сети и LSTM. Библиотека берет свое начало в научной среде и является продуктом совместной и индивидуальной работы исследователей из нескольких ведущих университетов. Библиотека, активно поддерживаемая компанией Amazon, разрабатывалась с особым упором на машинное зрение, обработку и понимание речи и языка, порождающие модели, сверточные и рекуррентные нейронные сети. MXNet позволяет определять, обучать и развертывать сети в самых разных условиях: начиная от мощных облачных инфраструктур и заканчивая мобильными и подключенными устройствами. Библиотека обеспечивает универсальную среду с поддержкой многих распространенных языков, давая возможность использовать как императивные, так и символические программные конструкции. Библиотека MXNet также занимает мало места. Благодаря этому ее можно эффективно масштабировать на нескольких графических процессорах и машинах, что хорошо подходит для обучения на больших наборах данных в облачной среде.
Важные особенности.
- Удобство программирования: возможность смешивать императивные и символические языки.
- Совместимость: поддерживает широкий набор языков программирования в интерфейсной части библиотеки, включая C++, JavaScript*, Python, r*, MATLAB*, Julia*, Scala и Go*
- Переносимость между платформами: возможность развертывать модели в самых разных условиях, обеспечивая доступ для широчайшего спектра пользователей.
- Масштабируе��ость: создана на основе планировщика с динамической зависимостью, который анализирует зависимости данных в последовательном коде и автоматически сразу распараллеливает как декларативные, так и императивные операции.
Среда neon
Благодаря языку на основе Python с открытым исходным кодом и набору библиотек для разработки моделей глубокого обучения, neon является быстрым, мощным и простым в использовании инструментом.
Важные особенности.
- Стремление обеспечить наилучшее качество работы на любом устройстве с оптимизацией на уровне ассемблера, поддержкой нескольких графических процессоров, оптимизированной загрузкой данных и применением алгоритма Winograd для сверток вычислений.
- Синтаксис как у языка Python включает объектно ориентированные реализации всех компонентов глубокого обучения, в том числе слои, правила обучения, активации, оптимизаторы, блоки инициализации и функции стоимости.
- Утилита Nviz создает гистограммы и другие элементы визуализации, помогая вам отслеживать и лучше понимать ход процесса глубокого обучения.
- Доступно для бесплатной загрузки по лицензии Apache 2.0 с открытым исходным кодом.
TensorFlow
TensorFlow представляет собой открытую программную библиотеку для числовых вычислений с использованием графов потоков данных. Узлы в графе представляют математические операции, а ветви графа — многомерные массивы данных (тензоры), которыми они обмениваются. Благодаря универсальной архитектуре вычисления можно развертывать на одном или нескольких ЦП или графических процессорах настольного компьютера, сервера или мобильного устройства с одним API. TensorFlow изначально был разработан научными сотрудниками и инженерами, работавшими в группе Google Brain в подразделении Google по изучению машинного интеллекта, для проведения машинного обучения и изучения нейронных сетей, однако благодаря своему общему характеру систему также можно использовать в других областях.
Theano
Theano — это библиотека Python, предназначенная для определения, оптимизации и оценки математических выражений, особенно выражений с многомерными массивами (numpy.ndarray). Theano позволяет достичь скоростей работы с большими объемами данных, которые могут конкурировать только со специально изготовленными программами на языке СИ. Theano также превосходит СИ на ЦП во много раз за счет использования последних версий графических процессоров. Theano совмещает в себе аспекты системы компьютерной алгебры (СКА) с аспектами оптимизирующего компилятора. С помощью Theano также можно создавать пользовательский код на языке СИ для многих математических операций. Такое сочетание СКА с оптимизирующей компиляцией особенно хорошо подходит для задач, в которых сложные математические выражения оцениваются многократно, поэтому для них важна скорость оценки. В ситуациях, когда оценивается множество разных выражений только один раз, Theano помогает уменьшить количество непроизводительных компиляций и анализов, по-прежнему обеспечивая символьные функции, такие ка�� автоматическая дифференциация.
Важные особенности.
- Оптимизация скорости выполнения: использование g++ или nvcc для компиляции частей графа выражений в инструкции ЦП или графического процессора, которые выполняются гораздо быстрее, чем инструкции на чистом языке Python
- Символьная дифференциация: автоматическое создание символьных графов для вычисления градиентов
- Повышение устойчивости: распознавание [некоторых] неустойчивых в числовом отношении выражений и вычисление их с использованием более устойчивых алгоритмов.
Torch
Torch представляет собой научную вычислительную среду с широкой поддержкой алгоритмов машинного обучения, в которой упор сделан на графические процессоры (GPU). Она отличается удобством в использовании и быстродействием благодаря простому и быстрому языку скриптов, LuaJIT и базовой программе на основеC/CUDA.
Важные особенности.
- Основывается на языке LuaJIT с высокой степенью оптимизации и обеспечивает доступ к ресурсам низкого уровня, например, для работы с обычными указателями C.
- Стремится обеспечить максимальную универсальность и скорость при создании научных алгоритмов, в то же время упрощая процесс.
- Имеет большую экосистему пакетов, в том числе в области машинного обучения, машинного зрения, обработки сигналов, параллельной обработки, изображений, видео, аудио и сетей, которые развиваются по инициативе сообщества, а также развивается на основе сообщества Lua.
- Простые в использовании библиотеки популярных нейронных сетей и средств оптимизации, отличающиеся максимальной универсальностью при реализации сложных топологий нейронных сетей.
- Вся среда (включая Lua) является автономной, и ее можно перенести на любую платформу без изменений.
Подробный анализ
Большинство сред имеют общие черты: скорость, портативность, сообщество и экосистема, простота разработки, совместимость и масштабируемость.
Входные данные для процесса поиска в среде для нашего проекта создания приложения автоматического видеомонтажа должны удовлетворять следующим требованиям.
- Хорошая оболочка или библиотека Python, потому что большинство аналитиков данных, включая тех, кто работает с данными учебными материалами, знакомы с языком Python.
- Версия, оптимизированная Intel для семейства продуктов Intel Xeon Phi с высокой степенью параллелизма.
- Широкий набор алгоритмов глубокого обучения, который хорошо подходит для быстрого создания прототипов и, в частности, изображений (распознавание эмоций) и данных последовательностей (аудио и музыкальные композиции).
- Предварительно обученные модели, которые можно использовать для создания моделей высокого качества, даже когда для обучения модели доступен относительно небольшой набор данных изображений (для распознавания эмоций) и музыкальных композиций (для создания музыки).
- Способность выдерживать высокие нагрузки в условиях производства на больших проектах, хотя в нашем проекте большие нагрузки не планируются.
Производительность разработчиков: Язык
Производительность разработчиков представляет большую важность, особенно на этапе создания прототипов, поэтому необходимо выбирать среду, соответствующую навыкам и знаниям участников вашей команды. По этой причине мы исключим все среды, основывающиеся на альтернативных языках.
- Оптимальные варианты: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon и Keras.
- Допустимо: DL4J (прекрасно подходит для Java/Scala; большинство библиотек больших данных, чаще всего используемых на предприятиях, пишутся на Java/Scala, например, Spark, Hadoop и Kafka).
Новые или существующие алгоритмы глубокого обучения и сетевая архитектура
Большинство проектов, включая наш учебный проект, используют только некоторый существующий алгоритм нейронной сети, такой как AlexNet или LSTM. В нашем случае должна подойти любая среда глубокого обучения. Однако, если вы работаете над исследовательским проектом (например, разрабатываете новый алгоритм, тестируете новую гипотезу или оптимизируете библиотеку), высокоуровневые системы, такие как Keras, вам не подойдут. Среды низкого уровня, скорее всего, потребуют от вас написания нового алгоритма на языке C++.
Наш перечень (сред глубокого обучения) остается прежним.
- Оптимальные варианты: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Допустимо: Не определено.
Поддерживаемые архитектуры нейронных сетей
Наш учебный проект предполагает решение двух традиционных задач глубокого обучения:
- классификация изображений (как правило, выполняется с помощью сверточных нейронных сетей, таких как AlexNet, VGG или Resnet);
- создание музыкального сопровождения (типичная задача моделирования последовательности, с которой прекрасно справляются рекуррентные нейронные сети, такие как LSTM);
все среды поддерживают сверточные нейронные сети (применяются в основном для обработки изображений) и рекуррентные нейронные сети (применяются для моделирования последовательности).
Наш перечень остается прежним:
- Оптимальные варианты: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Допустимо: Не определено.
Наличие предварительно обученных моделей
Поскольку у нас нет большого набора данных (например, 6000 аннотированных изображений) для обучения модели нашего проекта, мы должны использовать предварительно обученные модели.
Все выбранные среды поддерживают парки моделей. Кроме того, существуют преобразователи, позволяющие использовать модели, обученные с помощью другой библиотеки. Библиотека Caffe первой вошла в парк моделей и имеет самый широкий выбор моделей. Существуют средства для преобразования моделей парка Caffe в модель практически любой другой среды:
- MXNet
- Torch
- TensorFlow
- neon
- Microsoft Cognitive Toolkit (благодаря усилиям компании Майкрософт можно преобразовать почти любую модель в модель парка CNTK)
- Theano (активно поддерживаемый инструмент отсутствует, но Keras поддерживает отдельные модели обработки изображений)
У всех этих сред также есть свои собственные парки моделей.
Наш перечень остается прежним:
- Оптимальные варианты: Caffe, (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Toolkit, neon, Keras
- Допустимо: Не определено.
Производительность разработчиков: Простота определения модели
Модель можно определить двумя способами: с помощью файла конфигурации (например, при использовании Caffe) или с помощью скриптов (в других средах). Файлы конфигурации удобны с точки зрения портативности модели, но их сложно использовать при создании сложной архитектуры нейронной сети (например, попробуйте вручную скопировать слои в ResNet-101). С другой стороны, с помощью скриптов можно создавать сложные нейронные сети с минимальным повторением кода, однако возможность переноса такого кода в другую среду будет под вопросом. Обычно предпочтительнее использовать скрипты, потому что переходы из одной среды в другую в рамках одного проекта случаются редко.
Теперь наш перечень изменится следующим образом:
- Оптимальные варианты: (py)Torch, Theano, TensorFlow, MXNet, Microsoft Cognitive Network, neon, Keras
- Допустимо: Caffe
Поддержка оптимизированных ЦП и нескольких ЦП для обучения моделей глубокого обучения
Библиотека Intel Math Kernel Library (Intel MKL) для векторного и матричного умножения была доработана для глубокого обучения и теперь включает интегрированную многоядерную архитектуру Intel Many Integrated Core Architecture. Это процессорная архитектура с широким распараллеливанием, которая существенно ускоряет процессы глубокого обучения на ЦП. Все существующие на сегодняшний день конкурирующие среды уже интегрировали Intel MKL и предлагают версии, оптимизированные Intel.
Важно также знать, поддерживается ли распределенное обучение нескольких ЦП. Исходя из этих критериев, наш измененный перечень будет выглядеть следующим образом:
- Оптимальные варианты:
- TensorFlow
- MXNet
- Microsoft Cognitive Toolkit (на наш взгляд, метод MPI немного сложнее, чем другие библиотеки)
- Допустимо:
- (py)Torch (в следующей основной версии появится возможность работы с несколькими ЦП, если ориентироваться на ответ представителя компании на официальном форуме.
- Theano (многоядерное распараллеливание на одной машине через OpenMP)
- neon (пока недоступно)
Производительность разработчиков: Развертывание модели
TensorFlow поддерживает специальный инструмент, который носит название TensorFlow Serving. Он берет обученную модель TensorFlow в качестве входных данных и преобразует ее в веб-сервис, позволяющий оценивать входящие запросы. Если вы собираетесь использовать обученную модель на мобильном устройстве, TensorFlow Mobile обеспечивает немедленную компрессию модели.
Подробнее о TensorFlow Serving
TensorFlow Mobile
MXNet обеспечивает развертывание через слияние, при котором модель вместе со всеми необходимыми привязками помещается в автономный файл. Такой файл потом можно перенести на другую машину, и получить к нему доступ через другие языки программирования. Например, его можно использовать на мобильном устройстве. Подробнее.
Microsoft Cognitive Toolkit (предыдущее название — CNTK) обеспечивает развертывание модели через облачную среду машинного обучения Azure*. Мобильные устройства пока не поддерживаются. Их поддержка ожидается в следующей версии. Подробнее.
Хотя мы не собираемся развертывать готовое приложение на мобильном устройстве, в некоторых ситуациях такая возможность может быть весьма кстати. Например, представьте приложение для видеомонтажа, с помощью которого можно будет создавать видео из только что сделанных снимков (такая функция уже доступна в Google Photos).
Теперь у нас осталось два конкурента: TensorFlow и MXNet. В конце концов команда, работающая над этим проектом, решила использовать библиотеку TensorFlow в связке с Keras, потому что у нее более активное сообщество, у участников команды есть опыт работы с этими инструментами, а также потому что для TensorFlow зафиксировано больше успешных проектов. См. перечень пользователей TensorFlow.
Заключение
В этой статье мы представили несколько популярных сред для глубокого обучения и сравнили их по ряду критериев. Простота создания прототипов, развертывания и отладки модели, наряду с размером сообщества и масштабируемостью на нескольких машинах, являются одними из самых важных критериев, на которые следует ориентироваться при выборе среды глубокого обучения. Все современные среды сейчас поддерживают сверточные и рекуррентные нейросети, имеют парки предварительно обученных моделей и предлагают версии, оптимизированные для современных процессоров Intel Xeon Phi. Как показал наш анализ, для целей нашего проекта прекрасным выбором будет Keras на основе версии TensorFlow, оптимизированной Intel. Другим удачным вариантом будет библиотека MXNet, оптимизированная Intel.
Хотя по результатам этого сравнительного анализа победила библиотека TensorFlow, мы не учитывали эталоны сравнения, которые имеют ключевое значение. Мы планируем написать отдельную статью, в которой сравним время вывода и обучения библиотек TensorFlow и MXNet для широкого набора моделей глубокого обучения, чтобы определить окончательного победителя.

