Продолжаю выкладывать доклады с Pixonic DevGAMM Talks — нашего сентябрьского митапа для разработчиков высоконагруженных систем. Много делились опытом и кейсами, и сегодня публикую расшифровку выступления backend-разработчика из Saber Interactive Романа Рогозина. Он рассказывал про практику применения акторной модели на примере управления игроками и их состояниями (другие доклады можно посмотреть в в конце статьи, список дополняется).
Наша команда работает над backend'ом для игры Quake Champions, и я расскажу о том, что такое акторная модель, и как она используется в проекте.
Немного о стэке технологий. Мы пишем код на С#, соответственно, все технологии завязаны на нем. Хочу заметить, что будут какие-то специфичные вещи, которые я буду показывать на примере этого языка, но общие принципы останутся неизменными.

На данный момент мы хостим наши сервисы в Azure. Там есть несколько очень интересных примитивов, от которых мы не хотим отказываться, такие как Table Storage и Cosmos DB (но стараемся сильно на них не завязываться ради кроссплатформенности проекта).
Сейчас я бы хотел рассказать немного о том, что такое модель актора. И начну с того, что она, как принцип, появилась более 40 лет назад.

Актор — это модель параллельных вычислений, которая гласит, что есть некий изолированный объект, который имеет свое внутреннее состояние и эксклюзивный доступ к изменению этого состояния. Актор умеет читать сообщения, причем последовательно, выполнять какую-то бизнес-логику, при желании изменять свое внутреннее состояние, и отправлять сообщения внешним сервисам, в том числе и другим акторам. И еще он умеет создавать другие акторы.
Акторы общаются между собой асинхронными сообщениями, что позволяет создать высоконагруженные распределенные облачные системы. В связи с этим акторная модель и получила широкое распространение в последнее время.
Немного резюмируя сказанное, представим, что у нас есть клауд, где есть какой-то кластер серверов, и на этом кластере крутятся наши акторы.

Акторы друг от друга изолированы, общаются посредством асинхронных вызовов, и внутри самих себя акторы потокобезопасны.
Как это примерно может выглядеть. Допустим, у нас есть несколько пользователей (не очень большая нагрузка), и в какой-то момент мы понимаем, что идет наплыв игроков, и нам нужно срочно сделать upscale.

Мы можем добавить серверов на наш клауд и с помощью акторной модели распихать отдельных юзеров — закрепить за каждый отдельный актор и выделить под этого актора в клауде пространство по памяти и процессорному времени.
Таким образом, актор, во-первых, выполняет роль кэша, а во-вторых, это а-ля «умный кэш», который умеет обрабатывать какие-то сообщения, выполнять бизнес-логику. Опять же, если необходимо сделать downscale (к примеру, игроки вышли) — тоже нет никакой проблемы вывести эти акторы из системы.
Мы в backend’e используем не классическую акторную модель, а на основе Orleans-фреймворк. В чем отличие — я сейчас постараюсь рассказать.

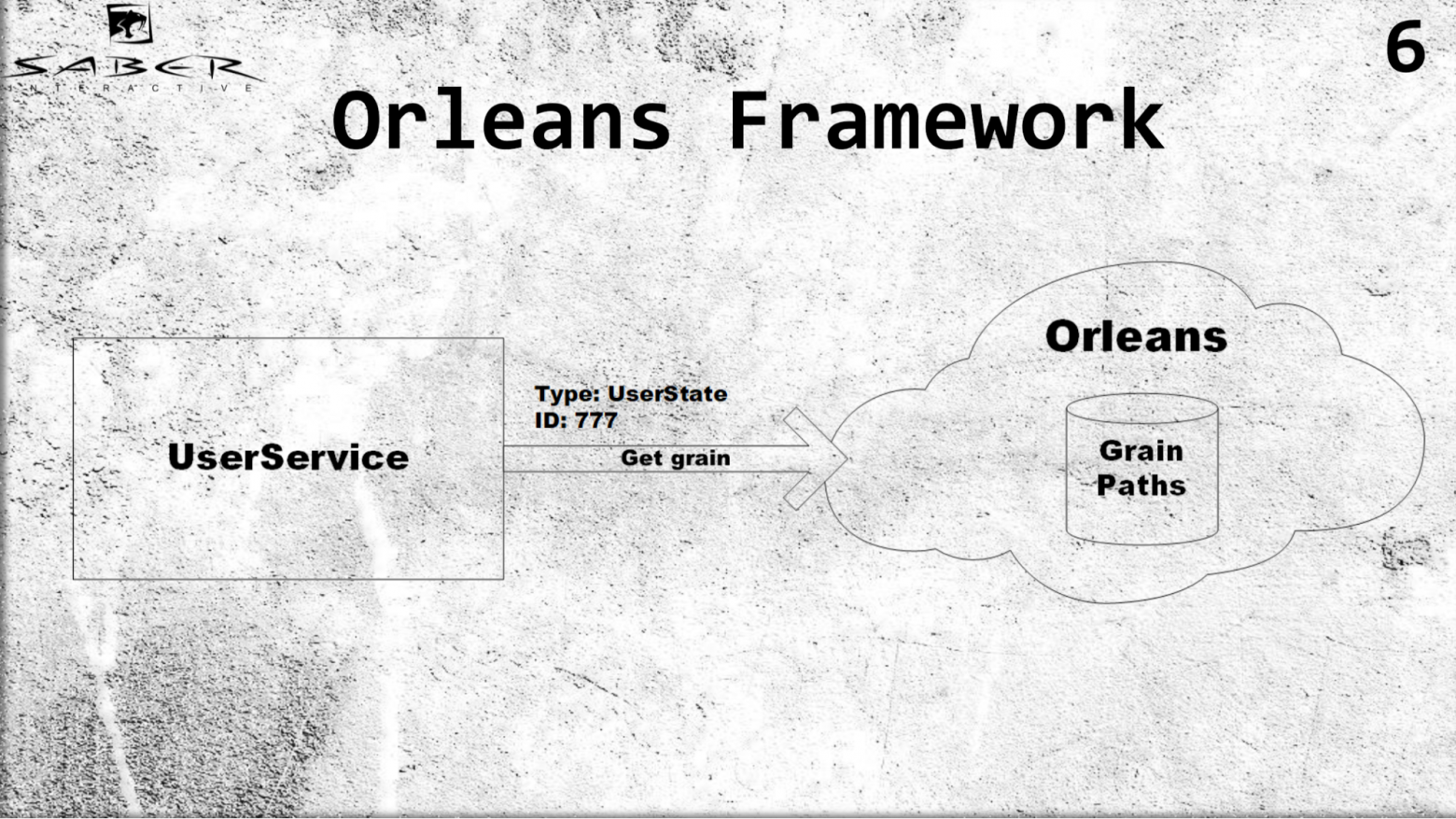
Во-первых, Orleans вводит понятие virtual-актор или, как он еще называется, грейн (grain). В отличие от классической акторной модели, где какой-либо сервис отвечает за то, чтобы создать этот актор и поместить его на какой-то из серверов, Orleans берёт эту работу на себя. Т.е. если некий user service запрашивает некий грейн, то Orleans поймет, какой из серверов сейчас менее загружен, сам разместит там актора и вернет результат в user service.
Пример. Для грейна важно знать только тип актора, допустим user states, и ID. Допустим, ID пользователя 777, мы получаем грейн данного юзера и не задумываемся о том, как этот грейн хранить, мы не управляем жизненным циклом грейна. Orleans же внутри себя хранит пути всех акторов очень хитрым образом. Если актора нет, он их создает, если актор живой, он его возвращает, и для юзер-сервисов все выглядит так, что все акторы всегда живые.
Какие преимущества это нам дает? Во-первых, прозрачную балансировку нагрузки за счет того, что программист не нуждается в том, чтобы самому управлять расположением актора. Он просто говорит Orleans, который развёрнут на нескольких серверах: дай мне из своих серверов такого-то актора.

При желании можно сделать downscale, если нагрузка на процессор и память небольшая. Опять же, можно сделать и в обратную сторону upscale. Но сервис ничего об этом не знает, он просит грейн, и Orleans дает ему этот грейн. Таким образом, Orleans берет на себя инфраструктурную заботу за жизненный цикл грейнов.
Во-вторых, Orleans обрабатывает падение серверов.

Это значит, что если в классической модели программист ответственен за то, чтобы обрабатывать такой случай самостоятельно (разместили актор на каком-то сервере, а этот сервер упал, и мы сами должны поднять этого актора на одном из живых серверов), что добавляет больше механической или сложно-сетевой работы для программиста, то в Orleans это выглядит прозрачно. Мы запрашиваем грейн, Orleans видит, что он недоступен, поднимает его (размещает на каком-то из живых серверов) и возвращает сервису.
Чтобы стало чуть более понятно, разберем небольшой пример, как пользователь читает некоторый свой state.

Стейтом может быть его экономическое состояние, которое хранит доспехи, оружие, валюту или чемпионов этого пользователя. Для того, чтобы получить эти стейты, он обращается в PublicUserService, который и обращается к Orleans за стейтом. Что происходит: Orleans видит, что такого актора (т.е. грейна) еще нет, он его создает на свободном сервере, и грейн читает свое состояние из некоторого Persistence-хранилища.
Таким образом, при следующем чтении ресурсов из клауда, как показано на слайде, всё чтение будет происходить ��з кэша грейна. В случае, если пользователь вышел из игры, чтения ресурсов не происходит, поэтому Orleans понимает, что грейн никем больше не используется и его можно деактивировать.
Если у нас несколько клиентов (игровой клиент, гейм-сервер), они могут запросить стейты пользователя, и кто-то из них поднимет этот грейн. Точнее — заставит Orleans поднять его, а затем все вызовы, как мы уже знаем, происходят в нем потокобезопасно, последовательно. Сначала стейт получит клиент, а затем и гейм-сервер.

Такой же флоу на обновлении. Когда клиент захочет обновить какой-то стейт, он передаст эту ответственность на грейн, т.е. скажет ему: «дай этому пользователю 10 золота», и грейн поднимается, в нем происходит обработка этого стейта с какой-то бизнес-логикой внутри грейна. И далее идет обновление кэша грейна и, при желании, сохранение в Persistence.

Зачем здесь нужно сохранение в Persistence? Это отдельная тема и она заключается в том, что иногда нам не особо важно, чтобы грейн постоянно сохранял в Persistence свои стейты. Если это состояние игрока онлайн, мы готовы рискнуть потерять его в угоду производительности, если же это касается экономики, то мы должны быть уверены в том, что его стейтс сохранен.
Простейший случай: на каждый вызов сохранения стейта, записывайте это обновление в Persistence. Таким образом, если грейн вдруг неожиданно свалится, следующее поднятие грейна на каком-то из других серверов вызовет обновление кэша с актуальными данными.
Небольшой пример того, как это выглядит.

Как я уже говорил, грейн состоит из типа и какого-то ключа (в данном случае тип это IPlayerState, ключ — IGrainWithGuidKey, что означает, что это Guid). И у нас есть интерфейс, который мы реализуем, т.е. GetStates возвращает какой-то список стейтов и ApplyState, который какой-то стейт применяет. Методы Orleans возвращают Task. Что это значит: Task — это promise, который говорит нам о том, что, когда состояние вернется, promise будет в состоянии resolved. Также у нас есть какой-то PlayerState, который мы получаем с помощью GrainFactory. Т.е. здесь мы получаем ссылку, и ничего не знаем о физическом расположении этого грейна. При вызове GetStates Orleans поднимет наш грейн, прочитает state из Persistence-хранилища себе в память, а при ApplyState применит новый стейт, а также обновит этот стейт и у себя в памяти, и в Persistence.
Хотелось бы еще разобрать чуть более сложный пример на High level архитектуре нашего UserStates сервиса.

У нас есть какой-то игровой клиент, который получает свои стейты через OfferSevice. У нас есть GameConfigurationService, ответственный за экономическую модель какой-то группы юзеров, в данном случае и нашего пользователя. И у нас есть оператор, который меняет эту экономическую модель. В соответствии с ней пользователь запрашивает OfferSevice для получения своих стейтов. А OfferSevice уже обращается к UserOrleans сервису, который состоит из этих грейнов, поднимает это состояние пользователя у себя в памяти, возможно, выполняет какую-то бизнес-логику, и возвращает данные обратно пользователю через OfferService.
Вообще, хотел бы обратить внимание на то, что Orleans хорош своей способностью высокого параллелизма за счет того, что грейны независимы друг от друга. И с другой стороны, внутри грейна мы не нуждаемся в использовании примитивов синхронизации, потому что мы знаем, что каждый вызов в этот грейн так или иначе будет последовательным.
Здесь я бы хотел разобрать некоторые подводные камни этой модели.

Первое — это слишком большой грейн. Поскольку все вызовы в грейне проходят потокобезопасно, друг за другом, и если у нас есть какая-то жирная логика на грейне, нам придется слишком долго ждать. Опять же, слишком много памяти выделяется под один такой грейн. Здесь нет точного алгоритма того, какой размер грейна должен быть, потому что слишком мелкий грейн это тоже плохо. Здесь скорее нужно исходить из оптимальной величины. Точно не скажу какой, это уже решает сам программист.
Вторая проблема не так очевидна — это так называемая цепная реакция. Когда пользователь поднимает какой-то грейн, а тот в свою очередь может неявно поднять другие грейны в системе. Как это происходит: пользователь получает свои состояния, а у пользователя есть друзья и он получает состояния своих друзей. Таким образом, вся система держит все свои грейны в памяти и если у нас 1000 пользователей, и у каждого 100 друзей, то 100 000 грейнов могут быть активны просто так. Такого случая тоже нужно избегать — как-то хранить стейты друзей в какой-то общей памяти.

Ну и какие технологии существуют для реализации модели акторов. Самая, пожалуй, известная — это Akka, которая пришла к нам с Java. Есть ее форк, называется Akka.NET для .NET. Есть Orleans, который open-source и есть в других языках, как реализация. Есть Azure-примитивы, такие как Service Fabric Actor — технологий очень много.
— Как вы решаете классические проблемы, как CICD, обновление этих акторов, используете ли Докер и нужен ли он вообще?
— Докер пока ещё не используем. Вообще, разверткой занимается DevOps, они разворачивают наши сервисы в клауд-сервисе Azure.
— Непрерывное обновление, без даунтаймов, каким образом происходит? Orleans же сам решает, на какой сервер пойдет грейн, на какой сервер пойдет запрос и каким образом этот сервис обновлять. Т.е. появилась новая бизнес-логика, появилось обновление того же актора — как накатываются эти обновления?
— Если речь идет о том, чтобы обновить весь сервис целиком, и если мы обновили какую-то бизнес-логику актора, мы можем выкатить под него новый Orleans сервис. Обычно у нас это решается через наши примитивы под названием топология. Мы выкатили какой-то новый сервис Orleans, который еще пока что, предположим, пустой, и без актора, выводим старый сервис и подменяем его новым. Акторов не будет в системе вообще, но при следующем запросе пользователя эти актора уже будут созданы. Будет, возможно, какой-то спайк в начале. В таких случаях обычно обновление проходит утром, так как утром у нас наименьшее число игроков.
— Как Orleans понимает, что сервак упал? Вот ты рассказывал, что он быстренько ��кторов перекидывает на другой сервер...
— У него есть пингатор, который периодически понимает, какие из серваков живые.
— Он пингует конкретно актор или сервер?
— Конкретно сервер.
— Такой вопрос: внутри актора произошла ошибка, ты говоришь он идет шаг за шагом, каждая инструкция. А вот произошла ошибка и что происходит с актором? Допустим такая ошибка, которая не обработана. Актора просто умирает?
— Нет, Orleans кидает exception в стандартной схеме .NET.
— Смотри, мы не обработали exception, актор видимо сдох. У игрока я не знаю, как это будет выглядеть, но что потом происходит? Вы пытаетесь как-то этот актор перезапустить или еще что-то сделать в этом духе?
— Смотря какой кейс, зависит от того, какое поведение. Например retriable или не retriable.
— Т.е. это все конфигурируется?
— Скорее программируется. Какие-то исключения мы обрабатываем. Т.е. явно видим, что такой код ошибки, а какие-то, как необработанные исключения, уже дальше прокидываются.
— У вас несколько Persistence’ов — это типа базы данных?
— Persistence, да, база данных с постоянным хранилищем.
— Допустим, легла база данных, в которой (условно) игровые деньги. Что происходит, если актор не может до нее достучаться? Это вы как обрабатываете?
— Во-первых, это Storage. На данный момент у нас используется Azure Table Storage и такие проблемы на самом деле случаются — Storage падает. Обычно в этом случае приходится его переконфигурировать.
— Если актор не смог получить что-то в Storage, у игрока это как выглядит? У него просто этих денег нет или у него игра сразу закрывается?
— Это критичные изменения для пользователя. Поскольку каждый сервис имеет свою severity, в данном случае, то юзер сервис это состояние terminal, и клиент просто вылетает.
— Мне показалось, что сообщения акторов происходят через асинхронные очереди. Насколько это оптимизированное решение? Разве это не раздувается, разве это не заставляет игрока подзависнуть? Не лучше ли использовать реактивный подход?
— Проблема очередей в акторах достаточно известная, потому что мы так явно не можем контролировать размер очереди, вы правы. Но Orleans, во-первых, берет на себя какую-то работу по менеджменту и, во-вторых, я думаю, что просто по таймауту доступ к актору будет падать, т.е. не можем достучаться до актора, к примеру.
— А как это на игроке отразится?
— Поскольку юзер-сервис обращается к актору, ему бросят исключение таймаут exception и, если это «критичный» сервис, то клиент выкинет ошибку и закроется. А если менее критично — то подождет.
— Т.е. у вас есть угроза DDoS? Большое количество мелкий действий может положить игрока? Допустим, кто-то быстро начнет приглашать друзей и т.д.
— Нет, там стоит request-лимитер, который не позволит слишком часто обращаться к сервисам.
— Как вы справляетесь с консистентностью данных? Допустим, у нас есть два юзера, надо у одного что-то забрать, а другому что-то начислить, и чтобы это было транзакционно.
— Хороший вопрос. Во-первых, Orleans 2.0 поддерживает Distributed Actor Transaction — это первый выход. Более точно нужно уже про экономику рассказывать. А как самый простой способ — в последнем Orleans транзакции между акторами без проблем реализуются.
— Т.е. оно уже умеет гарантировать, что в персистентность данные уйдут целостно?
— Да.
Наша команда работает над backend'ом для игры Quake Champions, и я расскажу о том, что такое акторная модель, и как она используется в проекте.
Немного о стэке технологий. Мы пишем код на С#, соответственно, все технологии завязаны на нем. Хочу заметить, что будут какие-то специфичные вещи, которые я буду показывать на примере этого языка, но общие принципы останутся неизменными.
На данный момент мы хостим наши сервисы в Azure. Там есть несколько очень интересных примитивов, от которых мы не хотим отказываться, такие как Table Storage и Cosmos DB (но стараемся сильно на них не завязываться ради кроссплатформенности проекта).
Сейчас я бы хотел рассказать немного о том, что такое модель актора. И начну с того, что она, как принцип, появилась более 40 лет назад.
Актор — это модель параллельных вычислений, которая гласит, что есть некий изолированный объект, который имеет свое внутреннее состояние и эксклюзивный доступ к изменению этого состояния. Актор умеет читать сообщения, причем последовательно, выполнять какую-то бизнес-логику, при желании изменять свое внутреннее состояние, и отправлять сообщения внешним сервисам, в том числе и другим акторам. И еще он умеет создавать другие акторы.
Акторы общаются между собой асинхронными сообщениями, что позволяет создать высоконагруженные распределенные облачные системы. В связи с этим акторная модель и получила широкое распространение в последнее время.
Немного резюмируя сказанное, представим, что у нас есть клауд, где есть какой-то кластер серверов, и на этом кластере крутятся наши акторы.
Акторы друг от друга изолированы, общаются посредством асинхронных вызовов, и внутри самих себя акторы потокобезопасны.
Как это примерно может выглядеть. Допустим, у нас есть несколько пользователей (не очень большая нагрузка), и в какой-то момент мы понимаем, что идет наплыв игроков, и нам нужно срочно сделать upscale.
Мы можем добавить серверов на наш клауд и с помощью акторной модели распихать отдельных юзеров — закрепить за каждый отдельный актор и выделить под этого актора в клауде пространство по памяти и процессорному времени.
Таким образом, актор, во-первых, выполняет роль кэша, а во-вторых, это а-ля «умный кэш», который умеет обрабатывать какие-то сообщения, выполнять бизнес-логику. Опять же, если необходимо сделать downscale (к примеру, игроки вышли) — тоже нет никакой проблемы вывести эти акторы из системы.
Мы в backend’e используем не классическую акторную модель, а на основе Orleans-фреймворк. В чем отличие — я сейчас постараюсь рассказать.
Во-первых, Orleans вводит понятие virtual-актор или, как он еще называется, грейн (grain). В отличие от классической акторной модели, где какой-либо сервис отвечает за то, чтобы создать этот актор и поместить его на какой-то из серверов, Orleans берёт эту работу на себя. Т.е. если некий user service запрашивает некий грейн, то Orleans поймет, какой из серверов сейчас менее загружен, сам разместит там актора и вернет результат в user service.
Пример. Для грейна важно знать только тип актора, допустим user states, и ID. Допустим, ID пользователя 777, мы получаем грейн данного юзера и не задумываемся о том, как этот грейн хранить, мы не управляем жизненным циклом грейна. Orleans же внутри себя хранит пути всех акторов очень хитрым образом. Если актора нет, он их создает, если актор живой, он его возвращает, и для юзер-сервисов все выглядит так, что все акторы всегда живые.
Какие преимущества это нам дает? Во-первых, прозрачную балансировку нагрузки за счет того, что программист не нуждается в том, чтобы самому управлять расположением актора. Он просто говорит Orleans, который развёрнут на нескольких серверах: дай мне из своих серверов такого-то актора.
При желании можно сделать downscale, если нагрузка на процессор и память небольшая. Опять же, можно сделать и в обратную сторону upscale. Но сервис ничего об этом не знает, он просит грейн, и Orleans дает ему этот грейн. Таким образом, Orleans берет на себя инфраструктурную заботу за жизненный цикл грейнов.
Во-вторых, Orleans обрабатывает падение серверов.
Это значит, что если в классической модели программист ответственен за то, чтобы обрабатывать такой случай самостоятельно (разместили актор на каком-то сервере, а этот сервер упал, и мы сами должны поднять этого актора на одном из живых серверов), что добавляет больше механической или сложно-сетевой работы для программиста, то в Orleans это выглядит прозрачно. Мы запрашиваем грейн, Orleans видит, что он недоступен, поднимает его (размещает на каком-то из живых серверов) и возвращает сервису.
Чтобы стало чуть более понятно, разберем небольшой пример, как пользователь читает некоторый свой state.
Стейтом может быть его экономическое состояние, которое хранит доспехи, оружие, валюту или чемпионов этого пользователя. Для того, чтобы получить эти стейты, он обращается в PublicUserService, который и обращается к Orleans за стейтом. Что происходит: Orleans видит, что такого актора (т.е. грейна) еще нет, он его создает на свободном сервере, и грейн читает свое состояние из некоторого Persistence-хранилища.
Таким образом, при следующем чтении ресурсов из клауда, как показано на слайде, всё чтение будет происходить ��з кэша грейна. В случае, если пользователь вышел из игры, чтения ресурсов не происходит, поэтому Orleans понимает, что грейн никем больше не используется и его можно деактивировать.
Если у нас несколько клиентов (игровой клиент, гейм-сервер), они могут запросить стейты пользователя, и кто-то из них поднимет этот грейн. Точнее — заставит Orleans поднять его, а затем все вызовы, как мы уже знаем, происходят в нем потокобезопасно, последовательно. Сначала стейт получит клиент, а затем и гейм-сервер.
Такой же флоу на обновлении. Когда клиент захочет обновить какой-то стейт, он передаст эту ответственность на грейн, т.е. скажет ему: «дай этому пользователю 10 золота», и грейн поднимается, в нем происходит обработка этого стейта с какой-то бизнес-логикой внутри грейна. И далее идет обновление кэша грейна и, при желании, сохранение в Persistence.
Зачем здесь нужно сохранение в Persistence? Это отдельная тема и она заключается в том, что иногда нам не особо важно, чтобы грейн постоянно сохранял в Persistence свои стейты. Если это состояние игрока онлайн, мы готовы рискнуть потерять его в угоду производительности, если же это касается экономики, то мы должны быть уверены в том, что его стейтс сохранен.
Простейший случай: на каждый вызов сохранения стейта, записывайте это обновление в Persistence. Таким образом, если грейн вдруг неожиданно свалится, следующее поднятие грейна на каком-то из других серверов вызовет обновление кэша с актуальными данными.
Небольшой пример того, как это выглядит.
Как я уже говорил, грейн состоит из типа и какого-то ключа (в данном случае тип это IPlayerState, ключ — IGrainWithGuidKey, что означает, что это Guid). И у нас есть интерфейс, который мы реализуем, т.е. GetStates возвращает какой-то список стейтов и ApplyState, который какой-то стейт применяет. Методы Orleans возвращают Task. Что это значит: Task — это promise, который говорит нам о том, что, когда состояние вернется, promise будет в состоянии resolved. Также у нас есть какой-то PlayerState, который мы получаем с помощью GrainFactory. Т.е. здесь мы получаем ссылку, и ничего не знаем о физическом расположении этого грейна. При вызове GetStates Orleans поднимет наш грейн, прочитает state из Persistence-хранилища себе в память, а при ApplyState применит новый стейт, а также обновит этот стейт и у себя в памяти, и в Persistence.
Хотелось бы еще разобрать чуть более сложный пример на High level архитектуре нашего UserStates сервиса.
У нас есть какой-то игровой клиент, который получает свои стейты через OfferSevice. У нас есть GameConfigurationService, ответственный за экономическую модель какой-то группы юзеров, в данном случае и нашего пользователя. И у нас есть оператор, который меняет эту экономическую модель. В соответствии с ней пользователь запрашивает OfferSevice для получения своих стейтов. А OfferSevice уже обращается к UserOrleans сервису, который состоит из этих грейнов, поднимает это состояние пользователя у себя в памяти, возможно, выполняет какую-то бизнес-логику, и возвращает данные обратно пользователю через OfferService.
Вообще, хотел бы обратить внимание на то, что Orleans хорош своей способностью высокого параллелизма за счет того, что грейны независимы друг от друга. И с другой стороны, внутри грейна мы не нуждаемся в использовании примитивов синхронизации, потому что мы знаем, что каждый вызов в этот грейн так или иначе будет последовательным.
Здесь я бы хотел разобрать некоторые подводные камни этой модели.
Первое — это слишком большой грейн. Поскольку все вызовы в грейне проходят потокобезопасно, друг за другом, и если у нас есть какая-то жирная логика на грейне, нам придется слишком долго ждать. Опять же, слишком много памяти выделяется под один такой грейн. Здесь нет точного алгоритма того, какой размер грейна должен быть, потому что слишком мелкий грейн это тоже плохо. Здесь скорее нужно исходить из оптимальной величины. Точно не скажу какой, это уже решает сам программист.
Вторая проблема не так очевидна — это так называемая цепная реакция. Когда пользователь поднимает какой-то грейн, а тот в свою очередь может неявно поднять другие грейны в системе. Как это происходит: пользователь получает свои состояния, а у пользователя есть друзья и он получает состояния своих друзей. Таким образом, вся система держит все свои грейны в памяти и если у нас 1000 пользователей, и у каждого 100 друзей, то 100 000 грейнов могут быть активны просто так. Такого случая тоже нужно избегать — как-то хранить стейты друзей в какой-то общей памяти.
Ну и какие технологии существуют для реализации модели акторов. Самая, пожалуй, известная — это Akka, которая пришла к нам с Java. Есть ее форк, называется Akka.NET для .NET. Есть Orleans, который open-source и есть в других языках, как реализация. Есть Azure-примитивы, такие как Service Fabric Actor — технологий очень много.
Вопросы из зала
— Как вы решаете классические проблемы, как CICD, обновление этих акторов, используете ли Докер и нужен ли он вообще?
— Докер пока ещё не используем. Вообще, разверткой занимается DevOps, они разворачивают наши сервисы в клауд-сервисе Azure.
— Непрерывное обновление, без даунтаймов, каким образом происходит? Orleans же сам решает, на какой сервер пойдет грейн, на какой сервер пойдет запрос и каким образом этот сервис обновлять. Т.е. появилась новая бизнес-логика, появилось обновление того же актора — как накатываются эти обновления?
— Если речь идет о том, чтобы обновить весь сервис целиком, и если мы обновили какую-то бизнес-логику актора, мы можем выкатить под него новый Orleans сервис. Обычно у нас это решается через наши примитивы под названием топология. Мы выкатили какой-то новый сервис Orleans, который еще пока что, предположим, пустой, и без актора, выводим старый сервис и подменяем его новым. Акторов не будет в системе вообще, но при следующем запросе пользователя эти актора уже будут созданы. Будет, возможно, какой-то спайк в начале. В таких случаях обычно обновление проходит утром, так как утром у нас наименьшее число игроков.
— Как Orleans понимает, что сервак упал? Вот ты рассказывал, что он быстренько ��кторов перекидывает на другой сервер...
— У него есть пингатор, который периодически понимает, какие из серваков живые.
— Он пингует конкретно актор или сервер?
— Конкретно сервер.
— Такой вопрос: внутри актора произошла ошибка, ты говоришь он идет шаг за шагом, каждая инструкция. А вот произошла ошибка и что происходит с актором? Допустим такая ошибка, которая не обработана. Актора просто умирает?
— Нет, Orleans кидает exception в стандартной схеме .NET.
— Смотри, мы не обработали exception, актор видимо сдох. У игрока я не знаю, как это будет выглядеть, но что потом происходит? Вы пытаетесь как-то этот актор перезапустить или еще что-то сделать в этом духе?
— Смотря какой кейс, зависит от того, какое поведение. Например retriable или не retriable.
— Т.е. это все конфигурируется?
— Скорее программируется. Какие-то исключения мы обрабатываем. Т.е. явно видим, что такой код ошибки, а какие-то, как необработанные исключения, уже дальше прокидываются.
— У вас несколько Persistence’ов — это типа базы данных?
— Persistence, да, база данных с постоянным хранилищем.
— Допустим, легла база данных, в которой (условно) игровые деньги. Что происходит, если актор не может до нее достучаться? Это вы как обрабатываете?
— Во-первых, это Storage. На данный момент у нас используется Azure Table Storage и такие проблемы на самом деле случаются — Storage падает. Обычно в этом случае приходится его переконфигурировать.
— Если актор не смог получить что-то в Storage, у игрока это как выглядит? У него просто этих денег нет или у него игра сразу закрывается?
— Это критичные изменения для пользователя. Поскольку каждый сервис имеет свою severity, в данном случае, то юзер сервис это состояние terminal, и клиент просто вылетает.
— Мне показалось, что сообщения акторов происходят через асинхронные очереди. Насколько это оптимизированное решение? Разве это не раздувается, разве это не заставляет игрока подзависнуть? Не лучше ли использовать реактивный подход?
— Проблема очередей в акторах достаточно известная, потому что мы так явно не можем контролировать размер очереди, вы правы. Но Orleans, во-первых, берет на себя какую-то работу по менеджменту и, во-вторых, я думаю, что просто по таймауту доступ к актору будет падать, т.е. не можем достучаться до актора, к примеру.
— А как это на игроке отразится?
— Поскольку юзер-сервис обращается к актору, ему бросят исключение таймаут exception и, если это «критичный» сервис, то клиент выкинет ошибку и закроется. А если менее критично — то подождет.
— Т.е. у вас есть угроза DDoS? Большое количество мелкий действий может положить игрока? Допустим, кто-то быстро начнет приглашать друзей и т.д.
— Нет, там стоит request-лимитер, который не позволит слишком часто обращаться к сервисам.
— Как вы справляетесь с консистентностью данных? Допустим, у нас есть два юзера, надо у одного что-то забрать, а другому что-то начислить, и чтобы это было транзакционно.
— Хороший вопрос. Во-первых, Orleans 2.0 поддерживает Distributed Actor Transaction — это первый выход. Более точно нужно уже про экономику рассказывать. А как самый простой способ — в последнем Orleans транзакции между акторами без проблем реализуются.
— Т.е. оно уже умеет гарантировать, что в персистентность данные уйдут целостно?
— Да.
Еще доклады с Pixonic DevGAMM Talks
- Использование Consul для масштабирования stateful-сервисов (Иван Бубнов, DevOps в компании BIT.GAMES);
- CICD: бесшовный деплой на распределенные кластерные системы без даунтаймов (Егор Панов, системный администратор Pixonic);
- Архитектура мета-сервера мобильного онлайн-шутера Tacticool (Павел Платто, Lead Software Engineer в PanzerDog);
- Как ECS, C# Job System и SRP меняют подход к архитектуре (Валентин Симонов, Field Engineer в Unity);
- Принцип KISS в разработке (Константин Гладышев, Lead Game Programmer в 1C Game Studios);
- Общая игровая логика на клиенте и сервере (Антон Григорьев, Deputy Technical Officer в Pixonic).
- Cucumber в облаке: использование BDD-сценариев для нагрузочного тестирования продукта (Антон Косякин, Technical Product Manager в ALICE Platform).

