Классный стартап в начале своего пути похож на Сапсан. Маленькая команда стремительно набирает обороты и несётся в будущее, везя в продакшн кучу задач. Если проект получился перспективный, такой как Skyeng, то уже через несколько лет команд будет существенно больше, и не исключено, что среди них появятся паровозы, в которых нужно непрерывно подкидывать дрова в топку, чтобы хоть что-то докатилось до пользователей.

Посмотрите или прочитайте доклад Алексея Катаева на Saint TeamLead Conf, если не знаете, по каким формальным признакам определить классная ли у вас команда. Если хотите уметь измерять технический долг в часах, а не оперировать категориями «совсем чуть-чуть», «сколько-то», «ужасно много». Если ваш продакт-менеджер считает, что команда из трех человек за месяц сделает 60 задач — покажите ему эту статью. Если ваш руководитель обвешал разработку метриками и предлагает вам принимать меры на основе результатов вроде: «34% считают, что в команде есть проблема с планированием», этот доклад для вас.
О спикере: Алексей Катаев (deusdeorum) 15 лет занимается веб-разработкой. Успел поработать backend, frontend, fullstack-разработчиком и тимлидом. Сейчас занимается оптимизацией процессов разработки в Skyeng. Может быть знаком тимлидам по выступлению о работе распределенной команды.
Теперь наконец передаем слово спикеру. Начнем с контекста и постепенно перейдем к основной проблеме.

Я пришел в Skyeng в 2015 году и был одним из пяти разработчиков — это были все разработчики в компании.
Прошло чуть больше трех лет, и сейчас нас 15 команд — это 68 разработчиков.

Все разработчики работают удаленно, они разбросаны по всему миру.
Посмотрим на проблемы, которые неизбежно возникают при масштабировании компании от 5 до 68 сотрудников.
На картинке Сергей — руководитель разработки.

Когда-то у нас была одна команда, и это был Сапсан, который несся в будущее и вез за собой кучу задач в продакшн. Но не только задач, а еще чуть-чуть технического долга. Потом в какой-то момент, неожиданно для нас, команд стало гораздо больше.
Первый вопрос, который стоит перед Сергеем, это все ли наши команды — это Сапсаны, или среди нас есть паровозы, где нужно подкидывать дрова в топку.

Этот вопрос важен потому, что может возникнуть такая ситуация: к Сергею придет продакт-менеджер или представитель бизнеса и скажет, что мы ничего не успеваем, команда работает плохо. Но на самом деле проблема может быть не только в команде. Проблема может быть во взаимоотношениях команды и бизнеса или в самом бизнесе — он может плохо ставить задачи или иметь слишком оптимистичные планы.
Необходимо понимать — классная ли команда.

Второй вопрос — это ресурсы команды: сколько задач мы можем увести в прод. Этот вопрос важен потому, что у продакта всегда очень много планов на ближайшее будущее. Важно понимать, справится ли с этими планами команда, или нужно выкинуть половину задач. Или, может быть, стоит нанять еще нескольких человек, чтобы реализовать все задачи.

Третий вопрос — сколько технического долга мы с собой везем? Это критичный вопрос, потому что если его количество перевалит за предельное значение, то в конце концов наш поезд вообще никуда не сможет ехать. Придется команду уволить, проект начать с начала, а мы не хотим этого допустить.

Напоследок — как нам сделать, чтобы все команды были Сапсанами, а не поездами?
1. Определяем, насколько у нас классные команды
Конечно, первым делом приходит в голову — измерить какие-нибудь метрики! Сейчас я расскажу про наш опыт и то, как мы раз за разом ошибались.

В первую очередь мы попробовали следить за velocity — сколько задач мы выкатываем за спринт. Но выяснили, что у половины наших команд вообще нет спринтов, у них Канбан. А там, где есть спринты, задачи оцениваются в часах или в story points. Еще есть ещё пара команд, которые просто делают задачи — у них нет Канбана, они не знают, что такое Scrum.
Это неконсистентность данных. Мы пытаемся посчитать одно число на абсолютно разных данных. При этом, везде сделать спринты, чтобы все команды были идентичными, будет очень дорого. Ради того, чтобы посчитать одну метрику, пришлось бы менять процессы.
Мы подумали, попробовали еще несколько вариантов и пришли к простой метрике — выполнение планов. Это тоже дорого, но нужно сделать идентичным, консистентным всего лишь планы продактов. Кто-то ведет их в Jira, кто-то в Google Spreadsheets, кто-то строит диаграммы — привести к одному формату гораздо дешевле, чем менять процессы в командах.
Каждый квартал мы смотрим, выполняет ли команда требования бизнеса, сколько запланированных задач выполнено.

Считать количество инцидентов тоже не получилось.
Мы логируем каждую неудачную выкатку или баг, которые принесли ущерб компании, и проводим post-mortem. Ко мне как тимлиду пришел Сергей и сказал: «Твоя команда допускает больше всего падений. Почему так?» Мы подумали, посмотрели и оказалось, что наша команда самая ответственная и единственная логирует все падения. Остальные действуют по принципу быстро поднятое, не считается упавшим.
Проблема опять в неконсистентности данных и недостаточности выборки. У нас есть команды, у которых просто лэндинг — он вообще никогда не падает. Мы же не можем сказать, что эта команда лучше, потому что у нее стабильнее проект.
Второе — моя любимая тема — это когнитивные искажения. Когнитивная легкость — это когда мы делаем какой-то вывод, который нам кажется простым, и сразу начинаем в него верить. Мы не включаем критическое мышление: раз много падений — значит, плохая команда.
Мы пришли к точно такой же метрике количества инцидентов, но только пересмотрели ее внедрение. Мы сделали такой процесс, при котором все падения логируются. В конце каждого месяца мы спрашиваем людей, которые не заинтересованы скрывать инциденты — это QA и продакты, полный ли это список проблем, произошедших по вине команды. Они вспоминают, когда мы роняли что-нибудь, и дополняют этот список.

С опросами тоже есть проблемы. Казалось бы, суперуниверсальное средство — всех опросим (продактов, тимлидов, заказчиков), какие у нас проблемы в командах. По их ответам мы построим графики, и все узнаем. Но проблем много.
Во-первых, если задавать закрытые вопросы, то из этих данных не сделать никаких выводов. Например, спрашиваем: «Есть ли в команде проблема с планированием?» и 34% отвечают, что есть — и что с этим делать? Если делать открытые вопросы: «Какие проблемы в команде с инфраструктурой?» — то получишь пустые ответы, потому что всем лень что-либо писать. Из этих данных невозможно сделать никакие выводы.
Мы развили эту идею — сначала проводим опросы как скрининг, а потом интервью, чтобы понять, в чем именно проблема. Об интервью поговорим чуть позже.
Я привел три примера, на самом деле мы пробовали десятки метрик.
Сейчас мы используем только:
Я слукавлю, если скажу, что мы даже эти простые вещи измеряем во всех командах, потому что самое дорогое — это внедрение. Особенно когда есть 15 разных команд, когда продакт говорит: «Да нам вообще это не надо! Нам бы выкатить свою задачу, сейчас не до того!». Очень тяжело сделать так, чтобы измерять одно число во всех командах.
Интервью
Сделаем краткое отступление об интервью с разработчиками. Я прочитал несколько статей, прошел продуктовый курс. Там есть очень много про user research и про customer development. Я взял оттуда несколько практик, и они очень хорошо легли на общение с разработчиками.
Если ваша цель — узнать, какие проблемы есть в команде, то в первую очередь вы должны написать целевые вопросы, на которые станете искать ответ. То есть не просто накидываете 30 каких-то вопросов, вы выбираете 2–3 вопроса, на которые ищете ответ. Например: есть ли в команде проблемы с инфраструктурой; как налажены коммуникации между бизнесом и командой.
При этом вопросы должны быть:
Еще очень хороший подход — это приоритизация. У вас есть разные аспекты жизни команды. Вы спрашиваете сотрудника, какие, по его мнению, самые классные и должны остаться такими же, а какие, возможно, стоит улучшить.
Есть еще один подход, который я взял из главы про собеседования в книге «Кто. Решите вашу проблему номер один» — задавать вопросы так: «Если бы я спросил продакта, как ты думаешь, какие бы он проблемы назвал?» Это заставляет разработчика взглянуть на картину в целом, а не со своей позиции, увидеть все проблемы.
2. Оцениваем ресурсы
Теперь поговорим про оценку ресурсов.
Начнем с подхода продакта — как он обычно оценивает ресурсы своей команды. Есть 3 человека, 20 рабочих дней в месяце — перемножаем людей на дни, получаем 60 задач.

Конечно, я утрирую, нормальный продакт перемножит это как 60 дней разработки. Но это тоже неправильно, никто никогда не выкатит задач, оцененных на 60 дней, за 60 дней. Даже в Scrum советуют считать фокус-фактор и умножать на некое магическое число, например, 0,2. На самом деле от итерации к итерации мы будем выкатывать то 12, то 17, то 10 задач. Я считаю, что это очень грубая оценка.
У меня есть свой подход к оценке ресурсов. Для начала считаем общий ресурс команды в рабочих часах. Умножаем часы на разработчиков, отнимаем отпуска и отгулы. Предположим, получилось 750. Но не вся разработка — это непосредственно разработка.
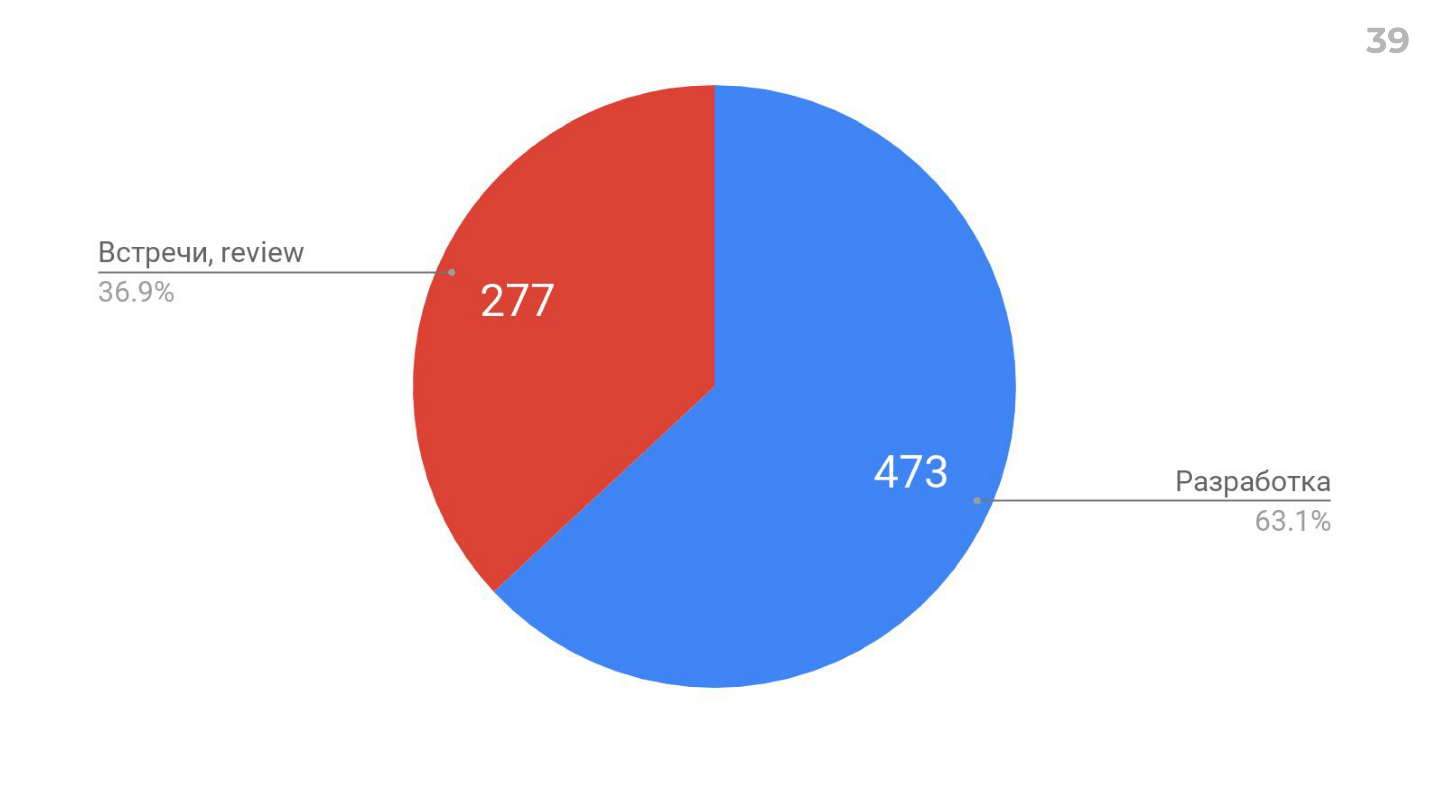
Выше реальные данные на примере одной из команд:
Может ли продакт рассчитывать на эти 63,1%? Нет, не может, потому что продуктовые задачи — это только часть. Еще есть квота (около 20%) на исправление багов и рефакторинг. Это то, что распределяет тимлид, и продакт уже не рассчитывает на это время.

Из продуктовых задач тоже не все задачи — это те, которые продакт запланировал. Есть продуктовые задачи других команд, которые просят срочно помочь, потому что релиз. Мы оцениваем примерно в 8–10% задачи, которые поступают от других команд.

И вот у нас есть 287 часов! Всё было бы классно, если бы мы всегда укладывались в свои оценки. Но в этой команде средний оверспент был посчитан — 1,51, то есть в среднем на задачу уходило в полтора раза больше времени, чем ее оценили.

Итого из 750 остается 189 часов на выполнение основных задач. Конечно, это приближение, но у этой формулы есть переменные, которые можно менять. Например, если вы посвящаете месяц рефакторингу, то можете подставить это значение и узнать, на что можете рассчитывать.
Я посвятил этому целый день — брал задачки, в Excel считал среднее время, анализировал — потратил кучу времени и решил, что никогда больше не буду этого делать. Мне нужен для этого какой-то быстрый подход, чтобы не делать это каждый раз руками.
Мне посоветовали плагин для Jira и EazyBI. Это суперсложный инструмент, или у меня не хватило способностей, но я на середине сдался.
Я нашел способ, который позволяет быстро строить любые отчеты.
Выгружаете данные из вашего таск-трекера в любую знакомую вам СУБД (для нас это PostgreSQL), а потом просите аналитика все посчитать. У нас это Дима, и он посчитал все за 2 часа.
При этом он выдал кучу дополнительных данных — овертайм по разработчикам, овертайм по типам задач, какие-то коэффициенты, рассказал нам про свои инсайты и новые гипотезы — прикольно и масштабируемо: вы можете использовать это сразу во всех командах.
Как увеличить ресурс
Теперь о том, как можно ускорить команду — увеличить ее ресурс, не увеличивая количество разработчиков.
В первую очередь, чтобы что-то ускорить, нужно сначала это измерить. Обычно мы считаем две метрики:
Не устану рассказывать бота Арсения, которого я написал за выходные. Он каждую неделю постит дайджест — сколько задач мы выкатили.

Здесь есть две интересных вещи:
Скорость — это запаздывающая метрика, мы не можем напрямую на нее влиять. Она показывает что-то, но есть метрики, влияя на которые, мы можем влиять на скорость. На мой взгляд, есть две основных:
1. Точность оценки задач.
Здесь нам опять помог наш заряженный аналитик Дима, который посчитал фактическое время выполнения задачи в зависимости от первоначальной оценки.
Это реальные данные. Сверху график фактического времени на выполнение задачи, а внизу — наша оценка.
Joel Spolsky утверждает, что 16 часов на задачу — это предел. Для нас видно, что после 12 часов оценка не имеет смысла, там слишком велика дисперсия. Мы действительно ввели soft-limit и стараемся не оценивать задачи, больше, чем в 12 часов. После этого либо декомпозиция, либо дополнительный research.
2. Расход времени, то есть когда разработчики тратят время на что-то, на что могли бы его не тратить.
В одной из наших команд на коммуникацию тратилось до 50% времени. Мы стали анализировать и разбираться, в чем причина. Оказалось, что проблема в процессах: все заказчики писали напрямую разработчикам, задавали вопросы. Мы немного поменяли процессы, сократили это время и улучшили показатели скорости.
В вашем случае это не обязательно будут коммуникации, это, например, может быть время на деплой или на инфраструктуру. Но пререквизитом для этого является то, что все ваши разработчики должны логировать время. Если у вас никто не логирует время в Jira, то, очевидно, будет очень дорого это внедрить.
3. Разбираемся с техническим долгом
Когда я говорю «технический долг», я его визуализирую как нечто размытое — непонятно, как его можно измерить?

Если я вам скажу, что у нас в одной из команд технический долг ровно 648 часов — вы мне не поверите. Но я расскажу алгоритм, благодаря которому мы измеряем его.

Мы собираемся раз в квартал всей командой (называем это refactoring meetup) и придумываем карточки: какие костыли (свои и чужие) люди видели в коде, сомнительные решения и прочие плохие штуки, например, старые версии библиотек — все, что угодно. После того, как мы сгенерировали кучу этих карточек, для каждой пишем resolution — что с этим делать. Может быть, ничего не делать, потому что это вообще не технический долг, либо нужно обновить версию библиотеки, рефакторить и т.д. Дальше мы создаем тикеты в Jira, где записываем: «Вот проблема — вот ее решение».
И вот у нас 150 тикетов в Jira — что с ними делать?
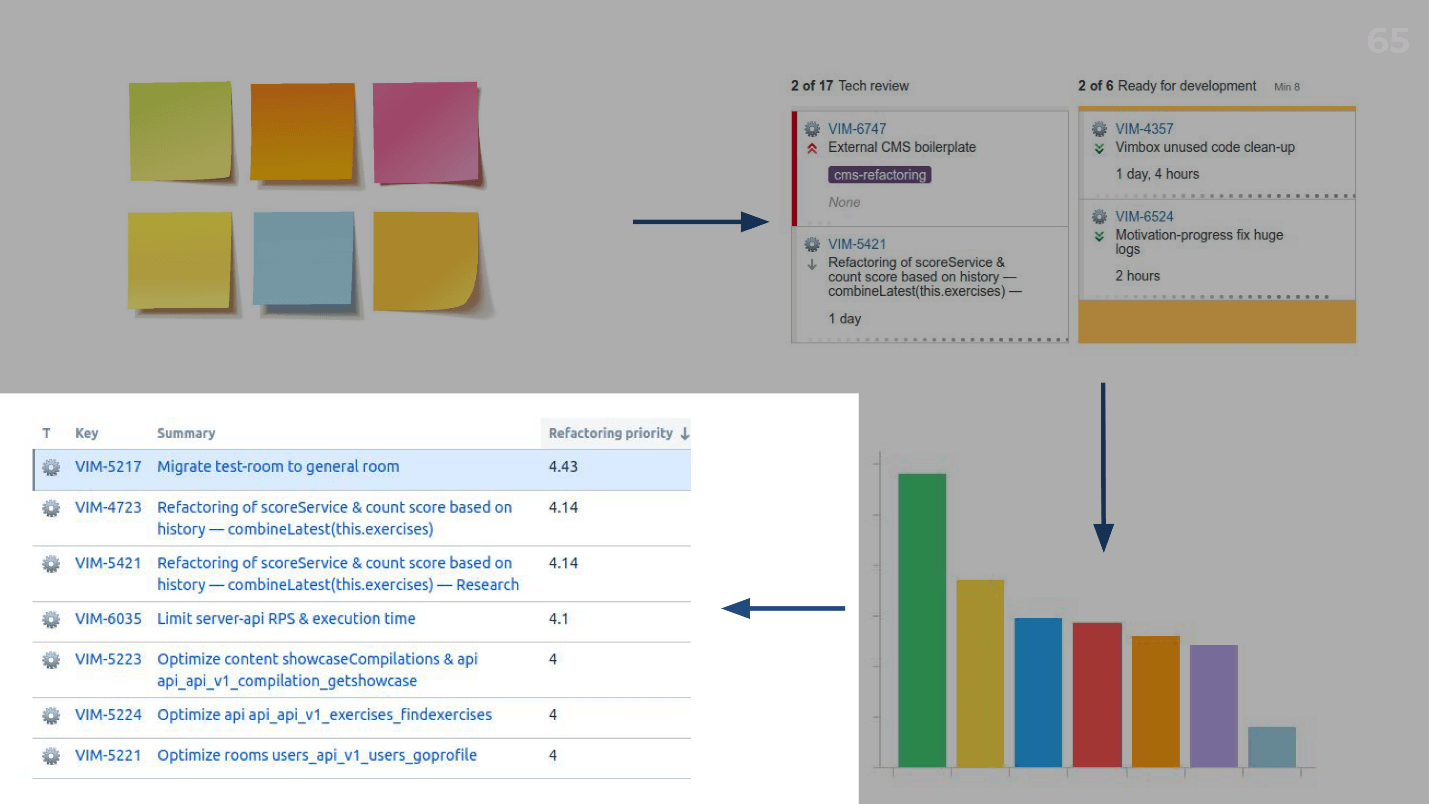
После этого мы проводим опрос, который занимает 10 минут для одного разработчика. Каждый разработчик ставит оценку от 1 до 5, где 1 — «Когда-нибудь сделаем в следующей жизни», и 5 — «Прямо сейчас нужно делать, это сильно нас замедляет». Эту оценку мы вносим прямо в тикет в Jira. Мы сделали кастомное поле, назвали его «Приоритет рефакторинга», и по нему получаем приоритезированный список нашего технического долга, проблем. Оценив первые 10–20, и потом умножив хвост на среднюю оценку (нам же лень оценивать все 150 тикетов), мы получаем технический долг в часах.
Зачем это нам нужно? Мы проводим эту оценку раз в квартал. Если у нас в первом квартале было 700 часов, а потом стало, например, 800, то все в порядке. А если стало 1400, это значит, что есть угроза и нужно увеличить квоту на рефакторинг — договориться с бизнесом, что мы сейчас будем рефакторить целый месяц или 40% всего времени.
Хорошо, мы решили проблему с техническим долгом, он под замком.

Но давайте еще поговорим о причинах, которые приводят к его возникновению. Чаще всего это плохой code review.
Плохой code review
Одна из главных причин плохого code review — это bus-factor. Мы научились формализовывать bus-factor. Мы берем команду, выписываем список областей релевантных для этой команды, например, для платформенной команды это: видеосвязь, синхронизация упражнений, инструменты. Каждый разработчик ставит оценку от 1 до 3:
Интересно, что для некоторых областей в команде не было ни одного эксперта, никто не знал, как это работает.
Как мы решали проблему с bus-factor’ом?
Далее мы посчитали медианное значение для каждой области, и провели серию докладов на регулярных командных встречах, в которых эксперты рассказали всей команде про те самые области. Конечно, этот способ не очень хорошо масштабируется, но, во-первых, есть видео этих докладов, а во-вторых, это очень быстрый способ. Вся команда теперь более-менее знает, как работает видеосвязь. Для каких-то областей мы еще не написали документацию, но сделали задачу написать документацию. Когда-нибудь напишем.

Теперь о code review, когда не хватает времени. У нас сейчас проходит эксперимент, где мы делаем review code review. В конце каждого месяца мы выбираем случайные pull requests, просим разработчиков еще раз сделать code review и найти как можно больше проблем. Таким образом, когда ты знаешь, что кто-то за тобой перепроверит, то ты уже более ответственно относишься к review. Еще мы добавили чек-листы — посмотрел ли ты на это, это и это — в общем, стараемся сделать code review более качественным.
На этом все про технический долг. У нас остался последний вопрос — это как сделать, чтобы все команды были Сапсанами.
4. Превращаем все команды в Сапсаны
Проще всего это делать на старте. Когда образуется новая команда, особенно когда приходит новый тимлид и набирает людей, мы делаем то же самое cross review всех процессов. То есть мы берем эксперта-тимлида, который проверяет всё: планирование, первые технические решения, стек технологий, все процессы. Таким образом мы задаем правильный вектор команде, которая начинает работу. Это очень дорого за счет потраченного времени, но это окупается.
Здесь тоже есть некий пререквизит, через Google Suite мы записываем на видео все встречи: все митинги, все планирования, все ретроспективы, их всегда можно пересмотреть.
Вторая дешевая метрика — это конечно чек-листы.

Выше пример чек-листа, но на самом деле он гораздо длиннее. Для каждой команды мы в огромной таблице отмечаем, есть ли в команде автотесты, Continuous Integration и т.д.
Но с этими чек-листами есть проблема — они устаревают на следующий день после того, как вы его сделали. Решить ее нам помогают административные ассистенты — это люди, которым вы можете ставить любые рутинные задачи. Мы ставим задачу, и они обновляют сами то, что могут обновить, а там, где не могут, добиваются, чтобы тимлид обновил. Таким образом мы поддерживаем актуальность чек-листов.
Подведем итоги
Мы поговорили о том:
В доклад не вошли некоторые материалы, которыми Алексей готов поделиться по запросу.
Напишите Алексею в Telegram (@ax8080) или facebook, чтобы получить эти списки и узнать больше об оценке эффективности команд.
Посмотрите или прочитайте доклад Алексея Катаева на Saint TeamLead Conf, если не знаете, по каким формальным признакам определить классная ли у вас команда. Если хотите уметь измерять технический долг в часах, а не оперировать категориями «совсем чуть-чуть», «сколько-то», «ужасно много». Если ваш продакт-менеджер считает, что команда из трех человек за месяц сделает 60 задач — покажите ему эту статью. Если ваш руководитель обвешал разработку метриками и предлагает вам принимать меры на основе результатов вроде: «34% считают, что в команде есть проблема с планированием», этот доклад для вас.
О спикере: Алексей Катаев (deusdeorum) 15 лет занимается веб-разработкой. Успел поработать backend, frontend, fullstack-разработчиком и тимлидом. Сейчас занимается оптимизацией процессов разработки в Skyeng. Может быть знаком тимлидам по выступлению о работе распределенной команды.
Теперь наконец передаем слово спикеру. Начнем с контекста и постепенно перейдем к основной проблеме.
Я пришел в Skyeng в 2015 году и был одним из пяти разработчиков — это были все разработчики в компании.
Прошло чуть больше трех лет, и сейчас нас 15 команд — это 68 разработчиков.
Все разработчики работают удаленно, они разбросаны по всему миру.
Посмотрим на проблемы, которые неизбежно возникают при масштабировании компании от 5 до 68 сотрудников.
На картинке Сергей — руководитель разработки.
Когда-то у нас была одна команда, и это был Сапсан, который несся в будущее и вез за собой кучу задач в продакшн. Но не только задач, а еще чуть-чуть технического долга. Потом в какой-то момент, неожиданно для нас, команд стало гораздо больше.
Первый вопрос, который стоит перед Сергеем, это все ли наши команды — это Сапсаны, или среди нас есть паровозы, где нужно подкидывать дрова в топку.
Этот вопрос важен потому, что может возникнуть такая ситуация: к Сергею придет продакт-менеджер или представитель бизнеса и скажет, что мы ничего не успеваем, команда работает плохо. Но на самом деле проблема может быть не только в команде. Проблема может быть во взаимоотношениях команды и бизнеса или в самом бизнесе — он может плохо ставить задачи или иметь слишком оптимистичные планы.
Необходимо понимать — классная ли команда.
Второй вопрос — это ресурсы команды: сколько задач мы можем увести в прод. Этот вопрос важен потому, что у продакта всегда очень много планов на ближайшее будущее. Важно понимать, справится ли с этими планами команда, или нужно выкинуть половину задач. Или, может быть, стоит нанять еще нескольких человек, чтобы реализовать все задачи.
Третий вопрос — сколько технического долга мы с собой везем? Это критичный вопрос, потому что если его количество перевалит за предельное значение, то в конце концов наш поезд вообще никуда не сможет ехать. Придется команду уволить, проект начать с начала, а мы не хотим этого допустить.
Напоследок — как нам сделать, чтобы все команды были Сапсанами, а не поездами?
1. Определяем, насколько у нас классные команды
Конечно, первым делом приходит в голову — измерить какие-нибудь метрики! Сейчас я расскажу про наш опыт и то, как мы раз за разом ошибались.
В первую очередь мы попробовали следить за velocity — сколько задач мы выкатываем за спринт. Но выяснили, что у половины наших команд вообще нет спринтов, у них Канбан. А там, где есть спринты, задачи оцениваются в часах или в story points. Еще есть ещё пара команд, которые просто делают задачи — у них нет Канбана, они не знают, что такое Scrum.
Это неконсистентность данных. Мы пытаемся посчитать одно число на абсолютно разных данных. При этом, везде сделать спринты, чтобы все команды были идентичными, будет очень дорого. Ради того, чтобы посчитать одну метрику, пришлось бы менять процессы.
Мы подумали, попробовали еще несколько вариантов и пришли к простой метрике — выполнение планов. Это тоже дорого, но нужно сделать идентичным, консистентным всего лишь планы продактов. Кто-то ведет их в Jira, кто-то в Google Spreadsheets, кто-то строит диаграммы — привести к одному формату гораздо дешевле, чем менять процессы в командах.
Каждый квартал мы смотрим, выполняет ли команда требования бизнеса, сколько запланированных задач выполнено.
Считать количество инцидентов тоже не получилось.
Мы логируем каждую неудачную выкатку или баг, которые принесли ущерб компании, и проводим post-mortem. Ко мне как тимлиду пришел Сергей и сказал: «Твоя команда допускает больше всего падений. Почему так?» Мы подумали, посмотрели и оказалось, что наша команда самая ответственная и единственная логирует все падения. Остальные действуют по принципу быстро поднятое, не считается упавшим.
Проблема опять в неконсистентности данных и недостаточности выборки. У нас есть команды, у которых просто лэндинг — он вообще никогда не падает. Мы же не можем сказать, что эта команда лучше, потому что у нее стабильнее проект.
Второе — моя любимая тема — это когнитивные искажения. Когнитивная легкость — это когда мы делаем какой-то вывод, который нам кажется простым, и сразу начинаем в него верить. Мы не включаем критическое мышление: раз много падений — значит, плохая команда.
Мы пришли к точно такой же метрике количества инцидентов, но только пересмотрели ее внедрение. Мы сделали такой процесс, при котором все падения логируются. В конце каждого месяца мы спрашиваем людей, которые не заинтересованы скрывать инциденты — это QA и продакты, полный ли это список проблем, произошедших по вине команды. Они вспоминают, когда мы роняли что-нибудь, и дополняют этот список.
С опросами тоже есть проблемы. Казалось бы, суперуниверсальное средство — всех опросим (продактов, тимлидов, заказчиков), какие у нас проблемы в командах. По их ответам мы построим графики, и все узнаем. Но проблем много.
Во-первых, если задавать закрытые вопросы, то из этих данных не сделать никаких выводов. Например, спрашиваем: «Есть ли в команде проблема с планированием?» и 34% отвечают, что есть — и что с этим делать? Если делать открытые вопросы: «Какие проблемы в команде с инфраструктурой?» — то получишь пустые ответы, потому что всем лень что-либо писать. Из этих данных невозможно сделать никакие выводы.
Мы развили эту идею — сначала проводим опросы как скрининг, а потом интервью, чтобы понять, в чем именно проблема. Об интервью поговорим чуть позже.
Я привел три примера, на самом деле мы пробовали десятки метрик.
Сейчас мы используем только:
- Выполнение планов.
- Количество инцидентов.
- Опросы + интервью.
Я слукавлю, если скажу, что мы даже эти простые вещи измеряем во всех командах, потому что самое дорогое — это внедрение. Особенно когда есть 15 разных команд, когда продакт говорит: «Да нам вообще это не надо! Нам бы выкатить свою задачу, сейчас не до того!». Очень тяжело сделать так, чтобы измерять одно число во всех командах.
Интервью
Сделаем краткое отступление об интервью с разработчиками. Я прочитал несколько статей, прошел продуктовый курс. Там есть очень много про user research и про customer development. Я взял оттуда несколько практик, и они очень хорошо легли на общение с разработчиками.
Если ваша цель — узнать, какие проблемы есть в команде, то в первую очередь вы должны написать целевые вопросы, на которые станете искать ответ. То есть не просто накидываете 30 каких-то вопросов, вы выбираете 2–3 вопроса, на которые ищете ответ. Например: есть ли в команде проблемы с инфраструктурой; как налажены коммуникации между бизнесом и командой.
При этом вопросы должны быть:
- Открытые. Ответ на вопрос: «Есть ли проблема?» — «Да!» — вам ни о чем не скажет.
- Нейтральные. Вопрос про проблему — плохой вопрос. Лучше спросить: «Расскажи про процесс планирования в вашей команде». Человек рассказывает про процесс, а вы уже начинаете ему задавать более глубокие вопросы.
Еще очень хороший подход — это приоритизация. У вас есть разные аспекты жизни команды. Вы спрашиваете сотрудника, какие, по его мнению, самые классные и должны остаться такими же, а какие, возможно, стоит улучшить.
Есть еще один подход, который я взял из главы про собеседования в книге «Кто. Решите вашу проблему номер один» — задавать вопросы так: «Если бы я спросил продакта, как ты думаешь, какие бы он проблемы назвал?» Это заставляет разработчика взглянуть на картину в целом, а не со своей позиции, увидеть все проблемы.
2. Оцениваем ресурсы
Теперь поговорим про оценку ресурсов.
Начнем с подхода продакта — как он обычно оценивает ресурсы своей команды. Есть 3 человека, 20 рабочих дней в месяце — перемножаем людей на дни, получаем 60 задач.
Конечно, я утрирую, нормальный продакт перемножит это как 60 дней разработки. Но это тоже неправильно, никто никогда не выкатит задач, оцененных на 60 дней, за 60 дней. Даже в Scrum советуют считать фокус-фактор и умножать на некое магическое число, например, 0,2. На самом деле от итерации к итерации мы будем выкатывать то 12, то 17, то 10 задач. Я считаю, что это очень грубая оценка.
У меня есть свой подход к оценке ресурсов. Для начала считаем общий ресурс команды в рабочих часах. Умножаем часы на разработчиков, отнимаем отпуска и отгулы. Предположим, получилось 750. Но не вся разработка — это непосредственно разработка.
Выше реальные данные на примере одной из команд:
- 36,9% времени тратится на коммуникацию — это митинги, обсуждения, технические review, code review и пр.
- 63,1% — непосредственно на решение задач.
Может ли продакт рассчитывать на эти 63,1%? Нет, не может, потому что продуктовые задачи — это только часть. Еще есть квота (около 20%) на исправление багов и рефакторинг. Это то, что распределяет тимлид, и продакт уже не рассчитывает на это время.
Из продуктовых задач тоже не все задачи — это те, которые продакт запланировал. Есть продуктовые задачи других команд, которые просят срочно помочь, потому что релиз. Мы оцениваем примерно в 8–10% задачи, которые поступают от других команд.
И вот у нас есть 287 часов! Всё было бы классно, если бы мы всегда укладывались в свои оценки. Но в этой команде средний оверспент был посчитан — 1,51, то есть в среднем на задачу уходило в полтора раза больше времени, чем ее оценили.
Итого из 750 остается 189 часов на выполнение основных задач. Конечно, это приближение, но у этой формулы есть переменные, которые можно менять. Например, если вы посвящаете месяц рефакторингу, то можете подставить это значение и узнать, на что можете рассчитывать.
Я посвятил этому целый день — брал задачки, в Excel считал среднее время, анализировал — потратил кучу времени и решил, что никогда больше не буду этого делать. Мне нужен для этого какой-то быстрый подход, чтобы не делать это каждый раз руками.
Мне посоветовали плагин для Jira и EazyBI. Это суперсложный инструмент, или у меня не хватило способностей, но я на середине сдался.
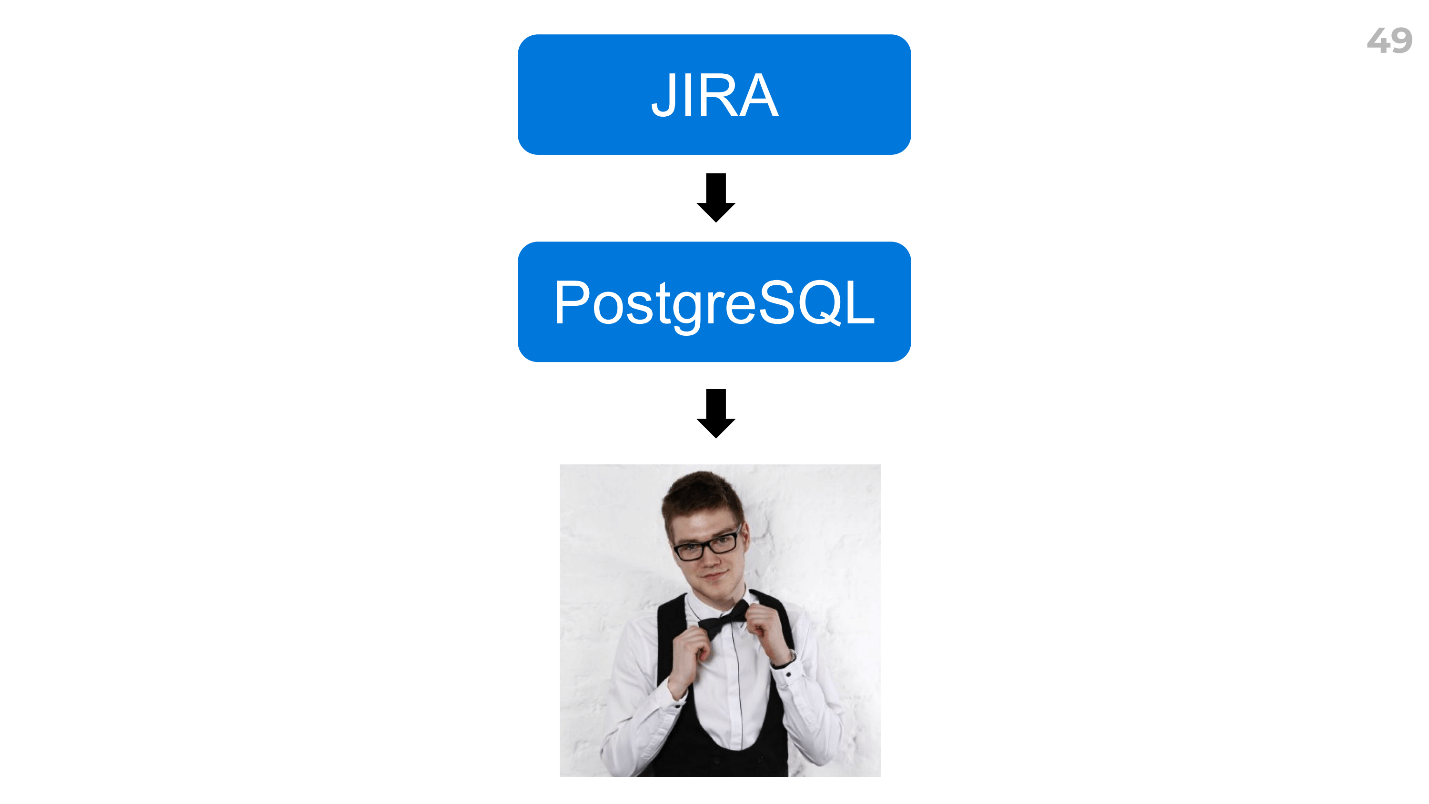
Я нашел способ, который позволяет быстро строить любые отчеты.
Выгружаете данные из вашего таск-трекера в любую знакомую вам СУБД (для нас это PostgreSQL), а потом просите аналитика все посчитать. У нас это Дима, и он посчитал все за 2 часа.
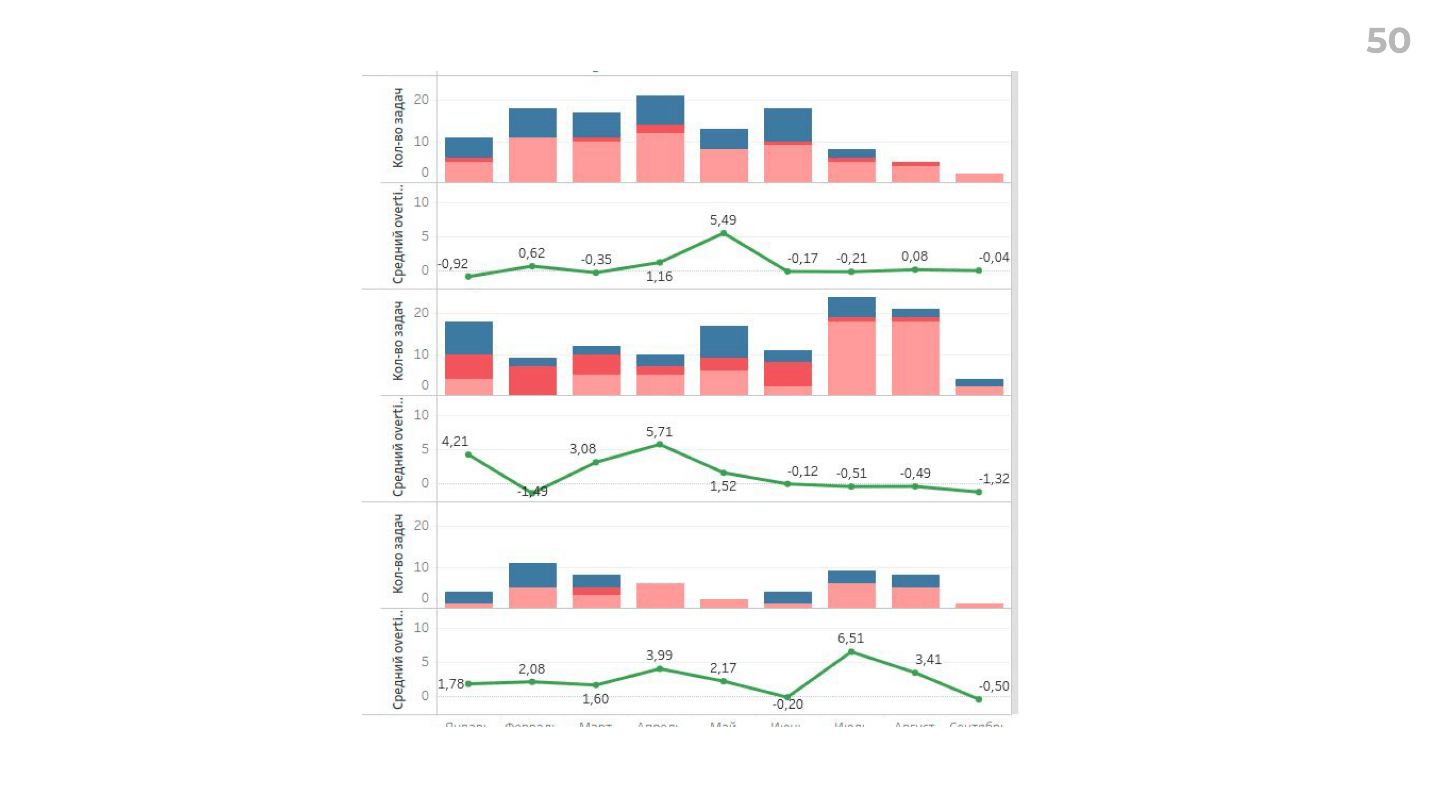
При этом он выдал кучу дополнительных данных — овертайм по разработчикам, овертайм по типам задач, какие-то коэффициенты, рассказал нам про свои инсайты и новые гипотезы — прикольно и масштабируемо: вы можете использовать это сразу во всех командах.
Как увеличить ресурс
Теперь о том, как можно ускорить команду — увеличить ее ресурс, не увеличивая количество разработчиков.
В первую очередь, чтобы что-то ускорить, нужно сначала это измерить. Обычно мы считаем две метрики:
- Первоначальная суммарная оценка задач за итерацию в часах. Например, мы выкатили за неделю задач на 100 часов.
- И иногда average rolling time — время от момента, когда задача пришла в разработку, до того, как она оказывается на продакшне. Это более бизнесовая метрика и интересна продакту, а не разработчику.
Не устану рассказывать бота Арсения, которого я написал за выходные. Он каждую неделю постит дайджест — сколько задач мы выкатили.
Здесь есть две интересных вещи:
- То, что я называю эффектом наблюдателя — оценивая какой-то показатель мы, тем самым уже его меняем. Как только мы стали пользоваться этим ботом, у нас увеличилось количество задач, которые мы делаем за итерацию.
- Метрика должна быть мотивирующая. Я начал с того, что показывал, насколько мы не успеваем сделать спринт. Выходило, что не успеваем на 10%, на 20%. Это не мотивирует вообще, никакого эффекта наблюдателя не будет.
Скорость — это запаздывающая метрика, мы не можем напрямую на нее влиять. Она показывает что-то, но есть метрики, влияя на которые, мы можем влиять на скорость. На мой взгляд, есть две основных:
1. Точность оценки задач.
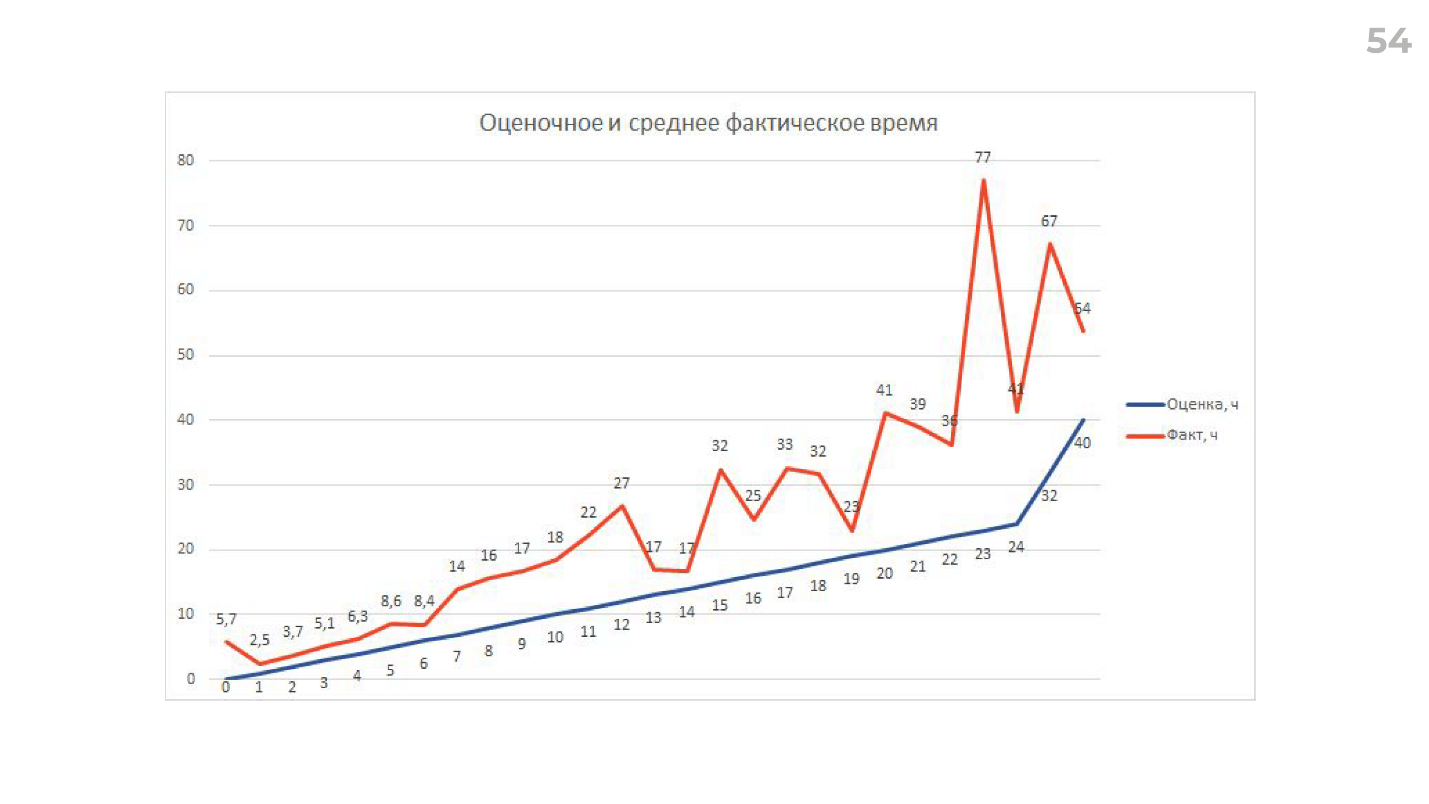
Здесь нам опять помог наш заряженный аналитик Дима, который посчитал фактическое время выполнения задачи в зависимости от первоначальной оценки.
Это реальные данные. Сверху график фактического времени на выполнение задачи, а внизу — наша оценка.
Joel Spolsky утверждает, что 16 часов на задачу — это предел. Для нас видно, что после 12 часов оценка не имеет смысла, там слишком велика дисперсия. Мы действительно ввели soft-limit и стараемся не оценивать задачи, больше, чем в 12 часов. После этого либо декомпозиция, либо дополнительный research.
2. Расход времени, то есть когда разработчики тратят время на что-то, на что могли бы его не тратить.
В одной из наших команд на коммуникацию тратилось до 50% времени. Мы стали анализировать и разбираться, в чем причина. Оказалось, что проблема в процессах: все заказчики писали напрямую разработчикам, задавали вопросы. Мы немного поменяли процессы, сократили это время и улучшили показатели скорости.
В вашем случае это не обязательно будут коммуникации, это, например, может быть время на деплой или на инфраструктуру. Но пререквизитом для этого является то, что все ваши разработчики должны логировать время. Если у вас никто не логирует время в Jira, то, очевидно, будет очень дорого это внедрить.
3. Разбираемся с техническим долгом
Когда я говорю «технический долг», я его визуализирую как нечто размытое — непонятно, как его можно измерить?
Если я вам скажу, что у нас в одной из команд технический долг ровно 648 часов — вы мне не поверите. Но я расскажу алгоритм, благодаря которому мы измеряем его.
Мы собираемся раз в квартал всей командой (называем это refactoring meetup) и придумываем карточки: какие костыли (свои и чужие) люди видели в коде, сомнительные решения и прочие плохие штуки, например, старые версии библиотек — все, что угодно. После того, как мы сгенерировали кучу этих карточек, для каждой пишем resolution — что с этим делать. Может быть, ничего не делать, потому что это вообще не технический долг, либо нужно обновить версию библиотеки, рефакторить и т.д. Дальше мы создаем тикеты в Jira, где записываем: «Вот проблема — вот ее решение».
И вот у нас 150 тикетов в Jira — что с ними делать?
После этого мы проводим опрос, который занимает 10 минут для одного разработчика. Каждый разработчик ставит оценку от 1 до 5, где 1 — «Когда-нибудь сделаем в следующей жизни», и 5 — «Прямо сейчас нужно делать, это сильно нас замедляет». Эту оценку мы вносим прямо в тикет в Jira. Мы сделали кастомное поле, назвали его «Приоритет рефакторинга», и по нему получаем приоритезированный список нашего технического долга, проблем. Оценив первые 10–20, и потом умножив хвост на среднюю оценку (нам же лень оценивать все 150 тикетов), мы получаем технический долг в часах.
Зачем это нам нужно? Мы проводим эту оценку раз в квартал. Если у нас в первом квартале было 700 часов, а потом стало, например, 800, то все в порядке. А если стало 1400, это значит, что есть угроза и нужно увеличить квоту на рефакторинг — договориться с бизнесом, что мы сейчас будем рефакторить целый месяц или 40% всего времени.
Хорошо, мы решили проблему с техническим долгом, он под замком.
Но давайте еще поговорим о причинах, которые приводят к его возникновению. Чаще всего это плохой code review.
Плохой code review
Одна из главных причин плохого code review — это bus-factor. Мы научились формализовывать bus-factor. Мы берем команду, выписываем список областей релевантных для этой команды, например, для платформенной команды это: видеосвязь, синхронизация упражнений, инструменты. Каждый разработчик ставит оценку от 1 до 3:
- 1 — «Я вообще не понимаю, что это такое, слышал пару раз».
- 2 — «Могу делать задачи из этой области».
- 3 — «Я суперэксперт в этой области».
Интересно, что для некоторых областей в команде не было ни одного эксперта, никто не знал, как это работает.
Как мы решали проблему с bus-factor’ом?
Далее мы посчитали медианное значение для каждой области, и провели серию докладов на регулярных командных встречах, в которых эксперты рассказали всей команде про те самые области. Конечно, этот способ не очень хорошо масштабируется, но, во-первых, есть видео этих докладов, а во-вторых, это очень быстрый способ. Вся команда теперь более-менее знает, как работает видеосвязь. Для каких-то областей мы еще не написали документацию, но сделали задачу написать документацию. Когда-нибудь напишем.
Теперь о code review, когда не хватает времени. У нас сейчас проходит эксперимент, где мы делаем review code review. В конце каждого месяца мы выбираем случайные pull requests, просим разработчиков еще раз сделать code review и найти как можно больше проблем. Таким образом, когда ты знаешь, что кто-то за тобой перепроверит, то ты уже более ответственно относишься к review. Еще мы добавили чек-листы — посмотрел ли ты на это, это и это — в общем, стараемся сделать code review более качественным.
На этом все про технический долг. У нас остался последний вопрос — это как сделать, чтобы все команды были Сапсанами.
4. Превращаем все команды в Сапсаны
Проще всего это делать на старте. Когда образуется новая команда, особенно когда приходит новый тимлид и набирает людей, мы делаем то же самое cross review всех процессов. То есть мы берем эксперта-тимлида, который проверяет всё: планирование, первые технические решения, стек технологий, все процессы. Таким образом мы задаем правильный вектор команде, которая начинает работу. Это очень дорого за счет потраченного времени, но это окупается.
Здесь тоже есть некий пререквизит, через Google Suite мы записываем на видео все встречи: все митинги, все планирования, все ретроспективы, их всегда можно пересмотреть.
Вторая дешевая метрика — это конечно чек-листы.
Выше пример чек-листа, но на самом деле он гораздо длиннее. Для каждой команды мы в огромной таблице отмечаем, есть ли в команде автотесты, Continuous Integration и т.д.
Но с этими чек-листами есть проблема — они устаревают на следующий день после того, как вы его сделали. Решить ее нам помогают административные ассистенты — это люди, которым вы можете ставить любые рутинные задачи. Мы ставим задачу, и они обновляют сами то, что могут обновить, а там, где не могут, добиваются, чтобы тимлид обновил. Таким образом мы поддерживаем актуальность чек-листов.
Подведем итоги
Мы поговорили о том:
- Как определить, какие команды работают хорошо, какие плохо.
- Как оценить ресурсы команды и иногда даже ускорить какую-то из команд.
- Как оценить технический долг, который эти команды везут с собой.
- Как сделать все новые команды Сапсанами.
Бонус
В доклад не вошли некоторые материалы, которыми Алексей готов поделиться по запросу.
- QA-метрики — это больше 10 разных метрик в тестировании, чтобы сделать все команды классными.
- Список всех метрик, которые кто-либо из Skyeng когда-либо пробовал. Это не просто список — это список с опытом и комментариями, плюс, с некоторой категоризацией этих метрик.
- Бот Арсений скоро будет выложен в open source, вы можете узнать об этом, как только произойдет.
Напишите Алексею в Telegram (@ax8080) или facebook, чтобы получить эти списки и узнать больше об оценке эффективности команд.
Напоминаю, что Call for Papers на конференцию для тимлидов TeamLead Conf 2019, которая пройдет 25–26 февраля в Москве, уже открыт. Здесь кратко о том, как подать доклад, и условиях участия, это ссылка на заявочную форму.
И оставайтесь с нами! Мы продолжим выкладывать статьи и видео по управлению командами разработки, а в рассылке будем собирать подборки полезных материалов за несколько недель и писать о новостях конференции.

