Нагрузочное тестирование в Skyforge, или Боты – санитары сервера. Часть 2
И снова привет, хабраюзер!
Это вторая статья, посвященная тестированию сервера Skyforge. На всякий случай напоминаю, что Skyforge – это MMORPG, сервер которой рассчитан на сотни тысяч игроков и написан на Java.
В отличие от первой части, где речь идет о роли ботов, эта статья рассказывает о нагрузочном тестировании и метриках.
{kind=link}
Нагрузочное тестирование
Читатели Хабра знают, что нагрузочное тестирование – это сбор показателей производительности программного обеспечения с целью проверки соответствия требованиям.
Наши требования к подобным тестам достаточно просты: нагрузка на сервере в «боевых» условиях должна быть в пределах нормы, а user experience не должен страдать. Поэтому при организации нагрузочного тестирования нужно в первую очередь определить, какие условия считать «боевыми». Например, для нас это означает следующее: на двух серверах игровой механики, одном сервере баз данных и одном сервере с разными вспомогательными сервисами резвятся 5000 игроков одновременно. Во вторую очередь нужно определить, какая нагрузка считается нормальной. Мы считаем, что сервер справляется с нагрузкой, если он проводит в обработке меньше 20 миллисекунд за серверный «тик».
У нас сервисно-ориентированная архитектура — это значит, что топология сервисов во время теста должна совпадать с топологией в «боевых» условиях. Объем контента тоже должен быть приближен к объему, который будет на «боевых». В общем, нагрузочное тестирование – это production в миниатюре, где вместо реальных пользователей – боты.
Организация тестирования
Все тесты, в том числе и с использованием ботов, на нашем проекте запускаются в системе непрерывной интеграции. В начале теста билд-агент обновляет и запускает сервер, запускает ботов и ждет заданное время, по истечении которого останавливает сервер, анализирует результаты и переходит к следующему тесту.
В связи с тем, что мы ограничены в ресурсах (у нас только одна ботовая площадка), нужно как-то синхронизировать их использование. Поэтому все тесты, использующие ботов, запускаются на выделенном билд-агенте.
Ночной ботовый тест
Основной нагрузочный тест, во время которого проверяется весь контент, идет ночью в течение 8 часов. Почему выбрана именно такая продолжительность? Экспериментально было замечено, что самые серьезные ошибки возникают на рубеже 4,5–6 часов, и чтобы их найти, мы просто вынуждены проводить такие длительные тесты. Именно на этот интервал приходится FullGC-пауза (подробнее об этом явлении), борьба с которой также является целью тестов. В наших планах реализовать постоянные тесты длительностью 56 часов в течение выходных. Но пока, к сожалению, это только планы.
Сервера
А сейчас я позволю себе дать несколько советов по организации нагрузочного тестирования, попутно рассказывая о том, как оно устроено у нас. Да, я понимаю, что кому-то эти советы покажутся заметками небезызвестного Капитана, но кому-то они все же могут быть полезны.
Важнейший этап нагрузочного тестирования – выбор и подготовка серверов для тестов. Так как у нас нет боевых серверов, мы выбирали максимально приближенные к тем, которые будут на момент релиза игры. Иначе следовало бы использовать сервера, аналогичные «боевым».
Сервера должны быть настроены именно так, как будут использоваться в «боевом» режиме. К слову, мы рассматриваем возможность использования технологии Thread Affinity, которая позволяет закрепить отдельные процессорные ядра за конкретными потоками, например за потоками игровой механики. И если эта технология «выстрелит», это будет означать, что данная настройка должна быть включена при проведении нагрузочного тестирования. Иначе поведение сервера под нагрузкой в тестовом окружении и в реальности будет значительно отличаться.
Также нужно помнить, что на современных серверах есть режимы работы «зеленая среда» или «экономия электричества». Рекомендую отключить их сразу, выставляя процессоры на полную производительность, потому что «в бою» серверам будет не до отдыха, а чинить несуществующие проблемы производительности во время теста в экорежиме – это плохая затея.
Важно, чтобы у вас был полный доступ к вашей площадке, чтобы вы могли в любой момент зайти и посмотреть, что там происходит, какие процессы запущены и т. д. Между вами и сервером не должно быть армии злых админов, которые контролируют каждый чих. Это необходимо по двум причинам. Во-первых, самостоятельно настраивая свой стенд и отвечая за его состояние, вы лучше представляете себе проблемы, которые могут возникнуть. Во-вторых, вы будете обладать полной информацией о том, что происходит с вашей тестовой площадкой. Это очень полезно при анализе аномалий в полученных данных.
Полный доступ подразумевает также, что вы там один. Если вы проводите нагрузочное тестирование, нужно убедиться, что на сервере нет вашего коллеги, занятого тем же самым, а также выяснить, не происходит ли backup базы данных. Нужно быть на 100% уверенным, что вы там один.
Снимаемая статистика
Самый простой и самый наглядный способ проанализировать данные по нагрузке – это визуализировать их. Мы используем для построения графиков библиотеку Highcharts, которая уверенно вытеснила jqPlot. Давайте посмотрим на примеры.
График нагрузки
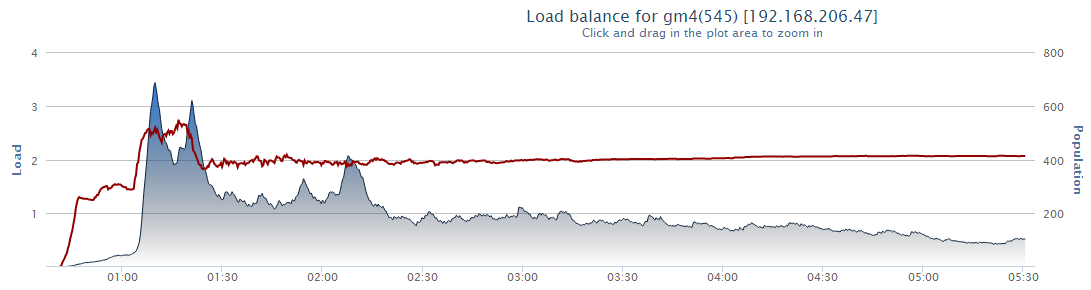{kind=link}
Подобный график я вижу каждое утро. Он позволяет отслеживать нагрузку. Нагрузка на сервере – это величина, равная отношению времени в миллисекундах, проведенному в обработке данных за 1 «тик» сервера, к 20 миллисекундам. Если на графике показатель больше единицы (больше нормы), значит, все плохо, если меньше – все хорошо.
График использования памяти
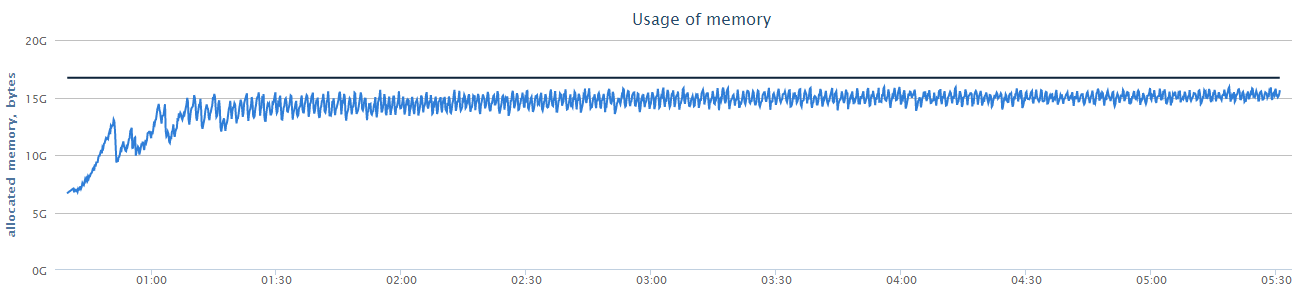{kind=link}
Это общий график использования памяти. Он позволяет приблизительно оценить работу «сборщика мусора».
График работы GC
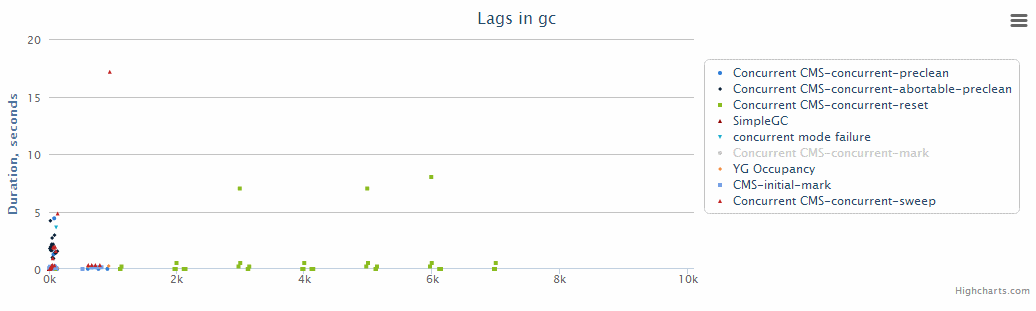{kind=link}
Наверное, это один из наиболее важных графиков для Java-серверов. Вряд ли игроки не заметят паузы во время полной сборки мусора. На нем по оси Y отмечена продолжительность той или иной фазы работы сборщика мусора.
Ключи, которые мы используем для сбора данных о работе GC
-verbose:gc
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintTenuringDistribution
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintPromotionFailure
-XX:+PrintClassHistogramBeforeFullGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCTimeStamps
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintTenuringDistribution
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintPromotionFailure
-XX:+PrintClassHistogramBeforeFullGC
-XX:+PrintClassHistogramAfterFullGC
-XX:+PrintGCApplicationConcurrentTime
График остановок в Safepoint
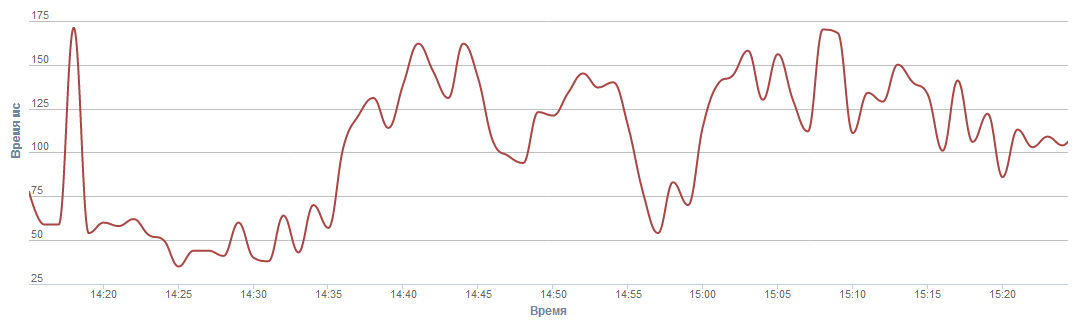{kind=link}
Safepoint – это точка в Java Virtual Machine, где происходит остановка каждый раз, когда нужно собрать stack trace или провести сборку мусора. Подробнее о safepoints можно почитать здесь. На данном графике изображено, сколько миллисекунд за 1 минуту сервер проводит в этих точках.
График датабазных операций
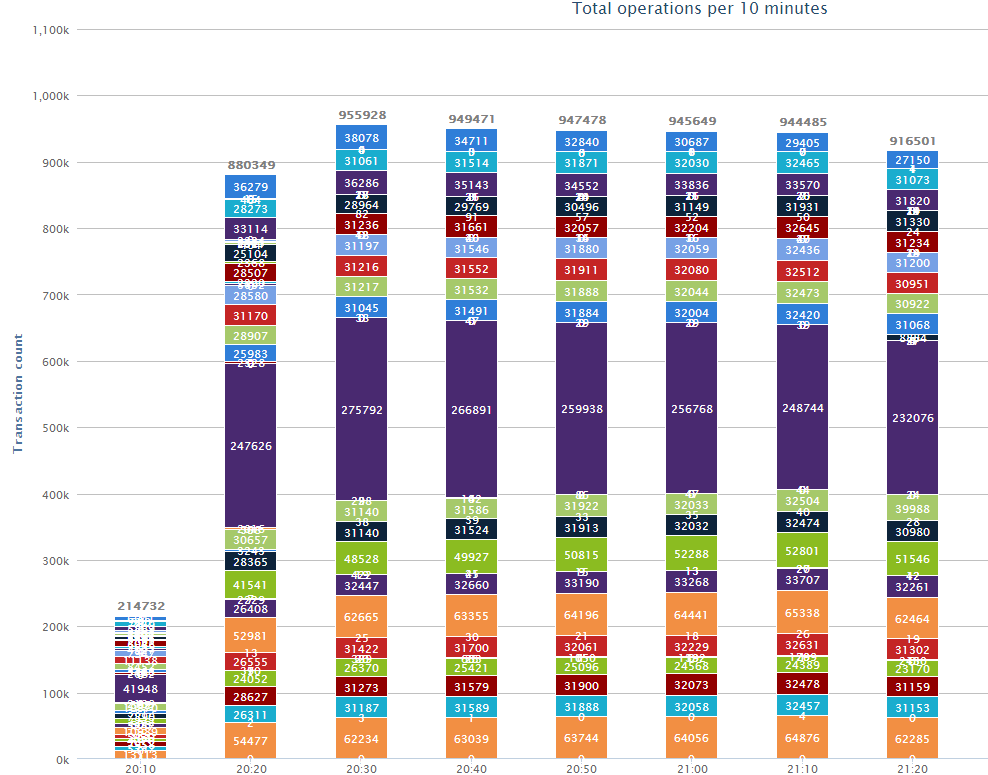{kind=link}
А вот прекрасные «шарфики», которые были сделаны по заказу Randll, чей доклад о базах данных вы могли прочесть ранее. Эти «шарфики» позволяют оценивать, какие database-операции и в каком количестве у нас выполняются.
Кроме этого так же логируется еще несколько десятков статистик, способных рассказать как о высокоуровневых показателях (количество мобов в бою с одним игроком), так и о низкоуровневых (количество переданных пакетов). Большинство этих статистик были заведены в ходе расследований относительно роста нагрузки.
Для этих же целей с помощью API Yourkit'a мы сделали автоматическое снятие дампа памяти и профиля нагрузки в конце теста. Сейчас они анализируются только в ручном режиме, но планируется автоматизировать и этот процесс.
Вишенка
В конце теста запускается так называемый анализатор ошибок. Мы берем все ошибки – а их за ночь иногда набегает до 100 гигабайт – и раскладываем по полочкам. Сравниваем, какие ошибки повторяются наиболее часто, а какие — редко, и разбиваем их по группам. Сортируем по типу – ошибка, предупреждение либо информационное сообщение – и выясняем, является ли это ошибкой контента. Ошибки контента мы передаем QA-специалистам по контенту, а ошибки в серверном коде исследуем сами.
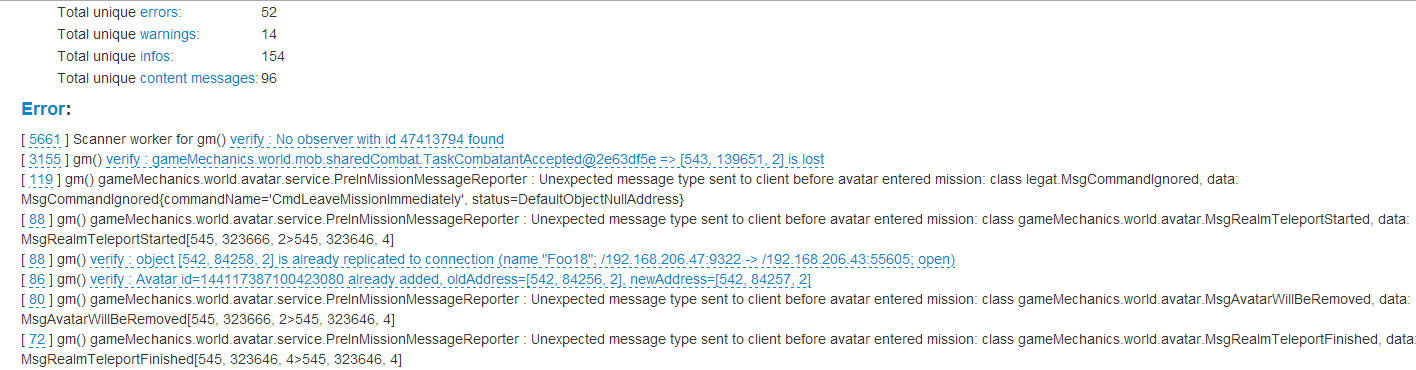{kind=link}
В отчете указано, сколько раз и в какие временные промежутки ошибка повторялась. Количество косвенно характеризует сложность повторения данной ошибки, ее стоимость для сервера (не забываем, что при сборе каждого коллстека на сервере умирает котенок) и приоритет в баг-трекере.
Время появления позволяет оценивать распределение ошибок по времени теста. Одно дело, если ошибки размазаны равномерно, и совсем другое, если они начинаются и заканчиваются в некоторый временной промежуток.
В дальнейшем мы планируем развивать эту систему, чтобы можно было связывать ошибки с тасками в JIRA и находить ревизию, в которой ошибка была замечена в первый раз.
Проблемы
У нагрузочных ночных тестов очень дорогие итерации. Стоимость каждого теста – день. Конечно, мы прикладываем все усилия, чтобы тест проходил каждую ночь, но в реальности успешно он проходит реже, а итерации становятся еще дороже. Любая поломка в любом узле инфраструктуры способна сорвать проведение теста.
Заключение
Регулярное нагрузочное тестирование с применением всевозможных статистик – это лучшее средство для здорового сна разработчиков. Сейчас я не представляю, как можно жить без такого рода тестирования, потому что благодаря ему каждое утро я вижу, где у нас
Другие материалы можно посмотреть на сайте разработчиков Skyforge и в нашем сообществе Вконтакте.
Спасибо за помощь в создании доклада и написании статьи всей команде сервера Skyforge.