
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Некоторые имплантации aarch64 также подвержены.
Но это требует привилегий для управления кэшом (чтобы вытащить прочитанные данные). А имея такие привилегии и без того можно делов натворить (как минимум DoS). Поэтому уязвимость менее критична — в правильных окружениях она не выполнима.
Можно попытаться косвенно определить значение данных (через спекулятивное исполнение), но это получается долго и нужно, чтобы процесс не прерывался планировщиком.
чтобы вытащить прочитанные данные
Чтение происходит из своего адресного пространства.
Чтение происходит из своего адресного пространства.
К своему адресному пространства мы и так имеем доступ.
И того, что я понял, в случае Spectre в документах идёт отсылка к Berkeley Packet Filter (BPF) — это виртуальная машина, позволяющая в режиме ядра выполнять пользовательский код. Meltdown здесь неприменим, т.к. исключение бросить просто невозможно. А вот выйти за границы массива с помощью Spectre вполне можно.
Но при этом в Windows BPF, насколько я понимаю, нет, поэтому Windows не должна быть подвержена этой атаке.
Spectre — отравление или обман предсказателя переходов. Чтение происходит из своего адресного пространства.
Вот только почему изоляция страниц спасает от Meltdown, а от Spectre — нет?
Да и откуда нам знать, что этот другой процесс вообще исполнит избранный код?
Spectre же заставляет чужой нам процесс спекулятивно читать данные из своего адресного пространства, которые мы потом подхватим через тайминг атаку на кеш.
Ну вот я прочитал оригинал и все равно не понимаю, как можно заставить чужой процесс что-либо прочитать по определённому адресу.
Да, за счёт шаринга DLL, мы можем обмануть branch prediction так, чтобы при определённом системном вызове спекулятивно выполнился кусок кода из адресного пространства процесса-жертвы.
Но для этого нужно, чтобы мы могли управлять регистрами процесса-жертвы перед вызовом системных функций, чтобы читать проивзольные адреса. То есть просто взять и прочитать память чужого процесса не получится.
То есть, если мы знаем, что нужная нам инструкция в атакуемой программе лежит по адресу 123456, а также в этой программе есть регулярно исполняемый косвенный переход. В атакующей программе мы пишем конструкцию, максимально похожую на переход в атакуемой, но при этом всегда выполняющую переход по адресу 123456. В нашем адресном пространстве, конечно, абсолютно валидный и легальный переход. Что именно у нас лежит по адресу 123456, никакого значения не имеет.
Через некоторое время блок предсказания переходов абсолютно уверен, что все переходы такого вида ведут на адрес 123456, поэтому, когда атакуемая программа — с нашей подачи или по своей инициативе — доходит до аналогичного перехода, процессор радостно начинает спекулятивное исполнение инструкций с адреса 123456. Уже в адресном пространстве атакуемой программы.
Через некоторое время настоящий адрес перехода будет вычислен, процессор осознает ошибку и отбросит результаты спекулятивного выполнения, однако, как и во всех прочих случаях применения Meltdown и Spectre, от него останутся следы в кэше.
Я читал много объяснений того, как это работает. Похоже, половина переводов сделаны один-в-один, и разобраться, что происходит можно только в том случае, когда человек постарался добавить ясности "от себя" или начинает расшифровывать всякие термины, без знания которых сложно разобраться.
Я постараюсь описать то, как я это понял, а вы меня поправьте, если я ошибаюсь.
На основе вышеизложенного, мы можем реализовать следующую схему:
Вот я тоже подумал про «сбрасывать кэш при отмене», но не получится ли при этом тогда действовать от противного? Прочитать весь наш массив в кэш, и потом замерять, какая часть была сброшена? 256*4096 = 1 Мб, влезет куда угодно, ну в L3 точно.
В идеале надо не сбрасывать, а восстанавливать состояние, но это, похоже, настолько дорого будет, что все преимущества кэша сойдут на нет. По сути, надо будет держать какой-то теневой кэш для кэша, в общем, не стоит оно того.
Прочитать весь наш массив в кэш, и потом замерять, какая часть была сброшена?
Можете подробнее объяснить? Как мы сможем различить эти случаи?
Как из одного потока в другой передать этот счетчик?
У потоков общая память.
Время переключения потоков (которые потоки операционки) — десятки микросекунд. Это гораздо больше времени чтения, пускай даже и из кэша, и само по себе связано с уходом исполнения в ядро.
А зачем потоки переключать? Они одновременно же работают на разных ядрах.
Если под понятием «поток» вы подразумевали нечто, что выполняется вторым ядром — то как передавать этот счетчик из второго ядра в первое ядро, еще и ненарушив кэш? Для таких вещей есть барьеры памяти, но они влияют на кэш. По сути передача данных между ядрами — через L3 (хотя это от архитектуры может зависеть) Думаю, там не померяешь так просто такой короткий интервал времени…
Во-первых, один атомарный инкремент занимает около 20 тактов. Впрочем, думаю, тут и без атомарщины можно обойтись, чтобы не лочить шину почём зря.
Во-вторых, ничто не мешает N раз провести атаку на одну и ту же ячейку и замерить суммарное время атаки, если точность измерения времени одиночной атаки недостаточна.
У потоков общая память.
Во-первых, один атомарный инкремент
N раз провести атаку
Атомарные операции выполняются с барьерами памяти
В архитектуре x86, насколько я помню, нет необходимости в явном использовании барьеров. И мои эксперименты с атомарными инкрементами показывают, что пересылка занимает явно меньше сотни тактов.
В том коде они это делают 999 раз
В том коде на каждой итерации делается вызов rdtsc. Я бы попробовал переписать код так, чтобы измерялось суммарное время 999 попыток, а не каждой из попыток в отдельности.
* perf stat -e L1-dcache-loads,L1-dcache-load-misses,branches,branch-misses /opt/phpstorm-171/bin/phpstorm.sh
Performance counter stats for '/opt/phpstorm-171/bin/phpstorm.sh':
73.192.922.309 L1-dcache-loads
6.005.629.782 L1-dcache-load-misses # 8,21% of all L1-dcache hits
44.366.574.238 branches
1.757.550.166 branch-misses # 3,96% of all branches
41,088747127 seconds time elapsedПри этом ущерб производительности не колоссально большой, потому что невалидные чтения в действительности выполняются нечасто.Вот же ж, блин, теоретики. Скорость доступа в кэш и в оперативку отличается на два порядка (то есть в сто раз). То есть даже если даже предсказатель будет «промахиваться» в одном случае из сотни (а этого, поверьте, не так-то просто достичь) мы получим проседание производительности на 30-50%.
Но и это, наверняка, не панацея.Не панацея — можно заметить как что-то пропало из кеша. Можно для «первого использования» завести отдельный кеш, но тогда можно будет играться с «двойным первым использованием» и т.д. и т.п.
Почему решение с аннулированием соответствующих строк кэша не закрывает данную уязвимость — мне непонятно.Потому что вам недостаточно просто убрать эту строку из кеша. Нужно ещё вернуть ту, которую вы убрали, чтобы эту положить. Иначе её исчезновение тоже можно заметить. А ещё — всю эту деятельность наблюдает другое ядро, не забывайте, так что наблюдать за всем этим процессом мы можем достаточно пристально.
Мне тут подумалось, для memory mapped io бывает ли такое, чтобы при чтении из ячейки памяти происходили побочные эффекты (типа считали содержимое ячейки — получили значение счетчика и он сбросился в ноль).Бывает. В лёгкую. И это настолько плохо, что уже во времена Pentium Pro появились MTRR, отключающие спекулятивные чтения для определённых диапазонов памяти.
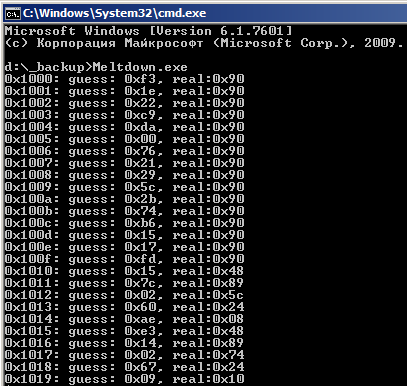
Зачем goto 2? В самом начале сбрасываем кэш специальной командой. Массив userspace[256x4096] в кэше отсутствует. После обработки исключения один из блоков длиной 4096 в этом массиве должен быть загружен в кэш. Измеряем время доступа к элементам с номерами ix4096 для i от 0 до 255. Определяем, при каком i время доступа было минимальным. Найденное i будет равно значению из защищенной области памяти. Массив time для этого не нужен, достаточно помнить минимальное время и значение индекса, в котором оно было получено.
Массив time для этого не нужен
Естественно, просто так проще объясняется алгоритм.
Измеряем время доступа к элементам с номерами ix4096 для i от 0 до 255
А разве кэш-промах и вытаскивание новых данных не испортят нам состояние кэша?
Мне кажется метод атаки имеет академический интерес, но вот попроси любого из нас провести реальную атаку даже в лабораторных условиях — иВы не сможете, а авторы соотвествующих статей смогли. Пароли из менеджера паролей вороются на раз. Просто потому что они не могут жить на стеке (они ж глобальные и должны там храниться годами) и менять их каждые 5 секунд тоже вроде как незачем.мы не сможеми я не смогу.
3. Найдите в дампе свои пароли.Кто вам сказал, что они там «открытым текстом» будут храниться? Там где-то будет мастер-пароль и зашифрованная база со всеми остальными.
в память они попадают временно в момент когда их запрашивают (GUI/API)
Пароли в нормальных менеджерах лежат в базе данных вЕсли у вас менеджер спрашивает мастер-пароль каждый раз при необходимости показать какой-либо другой пароль — то да. Но большинство пользователей такого уровня параноидальности не выдерживают.
зашифрованном виде и в память они попадают временно в момент когда их запрашивают (GUI/API)
А мне может кажется или ваш цикл на шаге 2 нужно поставить после 4-го пункта? Ведь смысл от цикла — измерить время доступа к данным массива, чтобы получить значение байта по "невалидному адресу", а измеряем время доступа мы только после того, как поймаем исключение. На шаге 2 нужен другой цикл, ИМХО. Цикл, который будет читать последовательно байты из памяти ядра, чтобы, собственно, и получить интересующий нас пароль к почте Клинтон.
P.S. А так за объяснение плюс. Стало намного понятнее все.
В пункте 5 у меня опечатка:
Ловим исключение и измеряем время доступа к элементуaddressuserspace[i * 4096], записывая в массив time[i]
Цикл стоит в правильном месте, поскольку сложно гарантировать, что за 256 итераций наша искомая кэш-линия не вытеснится из кэша. Например, ОС решит выделить квант времени другому процессу, который испортит весь кэш. В данном случае, приведен медленный, но более стабильный вариант.
происходит переход на адрес который должен находится в памяти.
Проецируют память только по одной причине — чтобы часть кода ядра попала в кэш и была там по возможности как можно дольше, а лучше — всегда, но все это на усмотрение процессора
CR3 сбрасывается каждый рад при переключении задачи
Верификатор загружаемого кода может проверять, что все обращения в память происходят либо к статически выделенной памяти, либо к стеку, либо к тому, что вернул new/malloc.πздец, извините за выражение. Выходят статьи, диссертации, разные инструменты и прочее, которые нужны для того, чтобы это свойство, с некоторой вероятностью, можно было обеспечить.
А там, где есть сомнения, ставить breakpoint, который сломает конвейер (а лучше вообще не давать запускать).Нечто подобное, примерно, и предлагается. Но там приходится почти везде это делать, так как магического валидатора у нас нету…
Теория алгоритмов утверждает, что создание подобного верификатора попросту невозможно.
Верификатор загружаемого кода может проверять, что все обращения в память происходят либо к статически выделенной памяти, либо к стеку, либо к тому, что вернул new/mallocЭто не защищает от Spectre.
Вот такой кусок кода даст примерно такой же ассемблерный код:
struct foo {
char flags;
char padding[4095];
};
struct foo array[256];
unsugned char* index_ptr;
do {
char flags = array[*index_ptr];
} while (flags == 0);И этот код вполне себе обычный.
Ну Интел сказал же, что это не RCE.
Но запуск и не требуется — просто прочитать из памяти что-нибудь вкусненькое тоже хорошо.
Меня вот лично очень пугают сообщения, что чуть ли не через JS можно будет содержимое оперативной памяти читать. Зашёл на сайт с нехорошим скриптом — и пароли из KeePass утекли. Вот где ужас-то.
читать можем что угодно.
3. Читать можно файловый кэш к примеру.
Нельзя просто взять и считать данные отдельного процесса.Почему нельзя-то? В структурах данных ядра написано — где чего хранится. У нас есть доступ ко всей памяти. Заходим и читаем.
Из кеша ничего не читается, но можно сделать полный дамп памяти ядра. А потом применить volatility.
Честно говоря, я не особо понял, зачем так делать — я бы просто к rax прибавил единичку сразу после чтения, да и всё
Читаем интересную нам переменную из адресного пространства ядра, это вызовет исключение, но оно обработается не сразу.
Кстати, тут должно стать понятно, как работает гипертрединг
Сходить в оперативную память стоит больше 100 процессорных тактов
Это все еще так? Вроде последнее поколение оперативной памяти всего лишь
раза в 1.5 уступает в частоте написанной на упаковке?

try{}catch или выставить предварительно signal(SIGSEGV)), но как это эксплойтить из ЯВУ наподобие JS, мне непонятно.[X86] Disable Memory Protection Keys CPU feature found in some Intel CPUs.
char tmp = *kernel_space_ptr ;char tmp = (*kernel_space_ptr >> k) & 1;tmp и… всё. Почему мы не используем непосредственно его, а ищем косвенными путями? Через некоторое время после чтения ядра произойдёт исключение, но процесс всё равно продолжает работать после этого, так почему бы не использовать tmp напрямую?Потому что процессор "случайно" выполнил это, ведь на самом то деле исключение уже произошло и весь результат работы надо выкинуть. И он выкидывает.
Вы же, когда на код смотрите, сами видите, что исключение будет выкинуто на строке
char tmp = *kernel_space_ptr;и, с точки зрения даже ассемблерного кода, не говоря уж про С, никакой результат в tmp не попадёт.
tmp.А если прибивать процесс сразу после попытки чтения памяти ядра, эксплойта уже не будет?Будет. Там не обязательно спекулятивно исполнять после обращения к несуществующей памяти — это просто, чтобы пример упростить. Можно через предсказатель ветвлений сделать то же самое.
bool read_memory;
void* read_from;
if (read_memory) {
tmp = *read_from;
...
}
read_from, процессор запоминает и начинает исполнять ветку спекулятивно. Потом перекулючаем read_from на адрес ядра, а read_memory — на false. Ветка всё равно исполняется спекулятивно и данные адра спекулятивно же читаются — но «реального» исключения не происходит.Кое-где используются эти прерывания для нормальной работы. Я такое видел в интерпретаторе Java.

Для javascript проблема решается с помощью отключения SharedArrayBufferНеизвестно, сколько сайтов сломается.
В JVM например по стандарту языка, любая выделенная память заполняется нулямиЭто защищает от чтения данных, оставшихся от предыдущего владельца. Для Spectre/Meltdown какая разница?
Что делать с этим массивом данных с кучей рандомных байт?Если бы там были «рандомные данные», то процесс ничего путного сделать бы не смог. А так — там определённые структуры, списки… фактически всё, что может и «умеет» программа — там сидит.
for (i = 0; i < 256; i++) {
if (is_in_cache(userspace_array[i*4096])) {
// Got it! *kernel_space_ptr == i
}
}
char not_used = userspace_array[tmp * 4096];KeePass вряд ли будет хранить пароли в чистом виде — они будут зашифрованы мастер-паролем.Однако при этом или мастер-пароль или какий-нибудь хеш от него будут лежать в памяти рядышком. Иначе бы двойной щелчок мышью по имени сайта не мог бы скопировать в буфер клавиатуры пароль без повторного запроса мастер-пароля.
Flush+Reload attacks work on
a single cache line granularity. These attacks exploit the
shared, inclusive last-level cache. An attacker frequently
flushes a targeted memory location using the clflush
instruction. By measuring the time it takes to reload the
data, the attacker determines whether data was loaded
into the cache by another process in the meantime.
As already discussed, we utilize cache attacks that allow
to build fast and low-noise covert channel using the
CPU’s cache. Thus, the transient instruction sequence
has to encode the secret into the microarchitectural cache
state, similarly to the toy example in Section 3.
We allocate a probe array in memory and ensure that
no part of this array is cached. To transmit the secret, the
transient instruction sequence contains an indirect memory
access to an address which is calculated based on the
secret (inaccessible) value. In line 5 of Listing 2 the secret
value from step 1 is multiplied by the page size, i.e.,
4 KB. The multiplication of the secret ensures that accesses
to the array have a large spatial distance to each
other. This prevents the hardware prefetcher from loading
adjacent memory locations into the cache as well.
Here, we read a single byte at once, hence our probe array
is 256×4096 bytes, assuming 4 KB pages.
We observe that the clflush instruction evicts the
memory line from all the cache levels, including from
the shared Last-Level-Cache (LLC). Based on this observation
we design the FLUSH+RELOAD attack—an extension
of the Gullasch et al. attack. Unlike the original
attack, FLUSH+RELOAD is a cross-core attack, allowing
the spy and the victim to execute in parallel on different
execution cores. FLUSH+RELOAD further extends
the Gullasch et al. attack by adapting it to a virtualised
environment, allowing cross-VM attacks.
Two properties of the FLUSH+RELOAD attack make
it more powerful, and hence more dangerous, than prior
micro-architectural side-channel attacks. The first is that
the attack identifies access to specific memory lines,
whereas most prior attacks identify access to larger
classes of locations, such as specific cache sets. Consequently,
FLUSH+RELOAD has a high fidelity, does not
suffer from false positives and does not require additional
processing for detecting access. While the Gullasch et al.
attack also identifies access to specific memory lines, the
attack frequently interrupts the victim process and as a
result also suffers from false positives.
The second advantage of the FLUSH+RELOAD attack
is that it focuses on the LLC, which is the cache level
furthest from the processors cores (i.e., L2 in processors
with two cache levels and L3 in processors with
three). The LLC is shared by multiple cores on the
same processor die. While some prior attacks do use the
LLC [47, 60], all of these attacks have a very low resolution
and cannot, therefore, attain the fine granularity
required, for example, for cryptanalysis.
retry и jz retry нужны из-за того, что обращение к началу массива даёт слишком много шума и, таким образом, извлечение нулевых байтов достаточно проблематично. Честно говоря, я не особо понял, зачем так делать — я бы просто к rax прибавил единичку сразу после чтения, да и всё.
Судя по всему в некоторых случаях "подсмотренный" байт может занулиться до выполния shl.
jz retry нужен для того чтобы ингорировать неудачные для нас исходы race condition
сбрасывать/перезаписывать линии кэша, имеющие отношение к запрошенному адресуКоторый не имеет отношения к тому адресу, на который производится атака.
вставлять задержкиКоторые никого не волнуют.
включать на какое-то время режимы искусственного торможения потенциально опасного процессаКоторый, в этот момент, уже «всё сделал» и готовится умереть.
Который не имеет отношения к тому адресу, на который производится атака.
Которые никого не волнуют.
Который, в этот момент, уже «всё сделал» и готовится умереть.
Да, им нужно быть связанными неким буфером — но это может быть, например, кусок кода libc или что-нибудь подобное…
Что значит «не имеет»? Атака производится именно на тот адрес, по которому впоследствии генерируется исключение.Сейчас — да. Но если вы видели как Spectre реализуется, то могли бы понять, что можно вообще без исключений обойтись. А уж сделать два обращения в память так, чтобы первое «било» в молоко — так и вообще не проблема.
Им в любом случае не обойтись без ядерных средств межпроцессного взаимодействия.Нет. Им нужен кусок разделяемой памяти — и всё. Все обращения в память ядра можно сделать спекулятивными. Хоть это и несколько усложнит логику.
Статья прежде всего про Meltdown, и я говорю прежде всего о нем.Так и я о нём же.
Куда какое обращение «бьет», для Meltdown разницы нет — исключение возникает всегда.Исключение вызывается только для «реальных» обращений. Сделайте обращения к «ядрёной» памяти спекулятивными — всё. Скорость упадёт, но никаких исключений не будет.
Если у процессов есть разделяемая память, доступная для записи — это и означает наличие межпроцессного взаимодействия.Зачем вам память, доступная для записи? Двухмегабайтный массив, через которые данные передаются Meltdown только читает.
У независимых процессов такой памяти никогда нет.Зависит от операционки, но этого и не нужно. Почти все процессы разделяют, как минимум, libc. А можно и что-нибудь более редкое загрузить.
Так и я о нём же.
Исключение вызывается только для «реальных» обращений. Сделайте обращения к «ядрёной» памяти спекулятивными — всё. Скорость упадёт, но никаких исключений не будет.
Зачем вам память, доступная для записи?
Почти все процессы разделяют, как минимум, libc
Ваш подход — это подход антивирусников
; rcx = kernel address
; rbx = probe array
retry:
mov al, byte [rcx]
shl rax, 0xc
jz retry
mov rbx, qword [rbx + rax]
The PAT allows any memory type to be specified in the page tables, and therefore it is possible to have a single physical page mapped to two or more different linear addresses, each with different memory types.
Как именно работает Meltdown