
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
А потом новости будут про коррупцию среди ИИ-чиновников, которые брали взятки процессорным временем и оперативкой.
upd.
Блин, промахнулся мимо нужной ветки.
А где-нибудь в США народ возмущаться будет в такой ситуации
коммунизм это отрицание всякой частной собственности
«При значительной разнице в финансировании проектов, отечественные разработки не уступают, а где-то даже превосходят зарубежные аналоги»и десять и двадцать лет назад. Могу ошибаться, но вот так на вскидку кроме Яндекса не могу вспомнить проектов вышедших на мировой рынок.
Что это было?
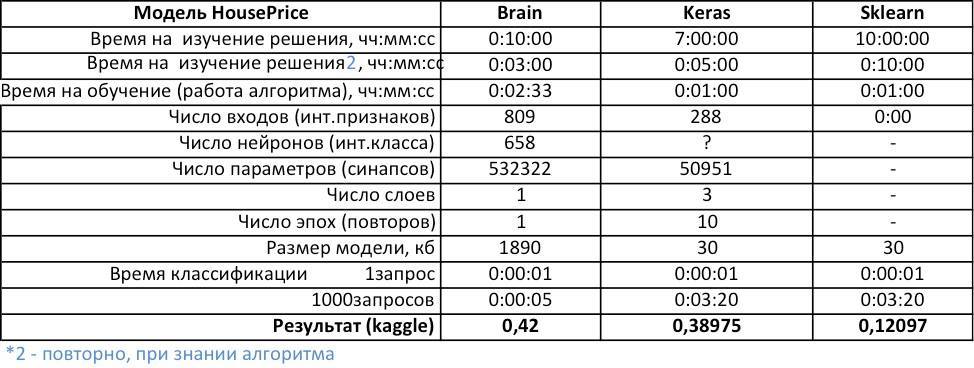
Другая российская разработка — платформа Brain2 компании “Когнитивные системы” — концентрируется на быстрой обработке bigdata в нейромодели знаний для систем ИИ. К примеру, нейромодель для оценки стоимости недвижимости (House Prices), обученная по 79 параметрам 1461 объектов недвижимости, способна предсказать стоимость объекта с незначительной ошибкой (RMSE=0,42), что равнозначно оценке опытного эксперта по недвижимости. При этом на обучение модели ушло всего 20 минут. Для сравнения, у опытного программиста-математика на решение подобной задачи с применением лучшей бесплатной библиотеки для машинного обучения Keras (TensorFlow) уйдет не менее 30 часов, а результат будет незначительно лучше (RMSE ≈ 0,32).
Почему автор сравнивает облачный сервис и фреймворк?
1) Сравнивайте тогда уж Brain2 с Google ML Cloud или MS Azure ML.
2) В рекламной презентации показывать результаты на MNIST'е в районе 81% точности и c местом во 2-й тысяче лидерборда
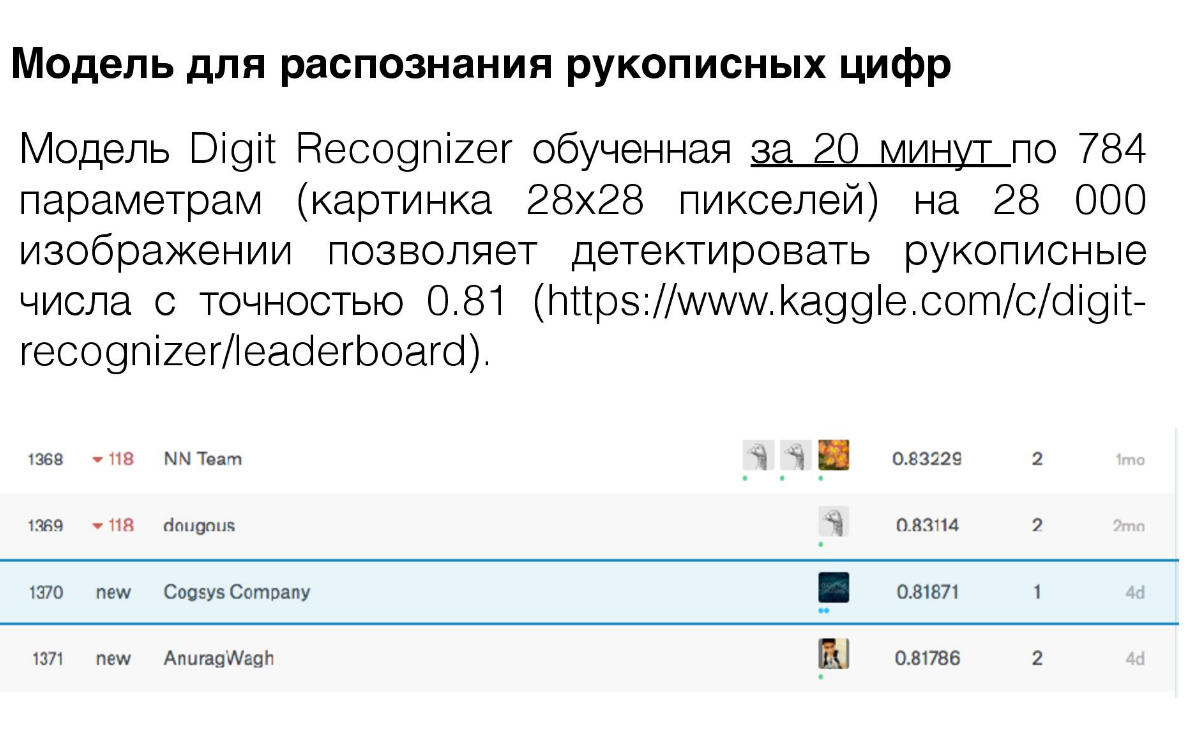

Им не стыдно за свой сервис?
3) Что за бред про 30 часов работы опытного программиста-математика?
Еще забавляет, что на их сайте, русская версия от английской отличается только языком меню, весь контент не зависимо от выбранного языка будет на русском языке.
Имхо, как-то подозрительно выглядят эти "Когнитивные технологии" — убийцы tensorflow...
Спасибо за ответы:-)
Хотя объем бреда, по моему, только увеличился:
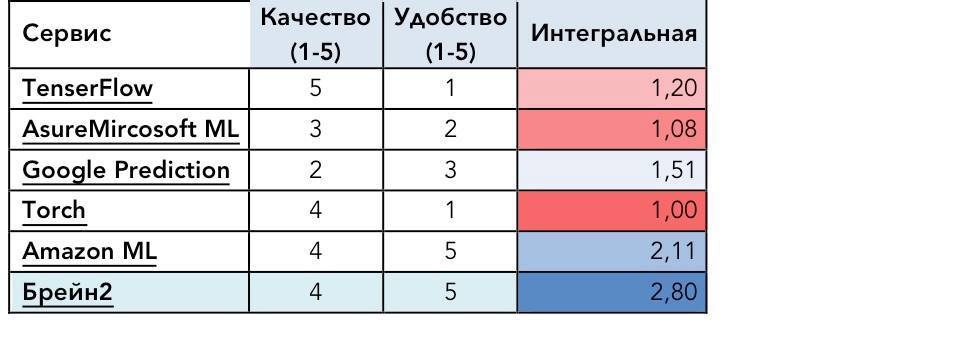
Сравнивать надо сравнимое. Для оценки надо взять как минимум 2 параметра – удобство и результат (пока отбросим стоимость).
Совершенно не понятно, какой смысл вкладывается в критерий "Результат"… вроде как на любом из представленых фреймворков можно любую модель реализовать...
Задачу MINST как представленная в виде демо в сервисе он решает хорошо – 0,92 точность, но вот другие, которые мы пытались решить увы не может.
92% — это очень плохо. Тупая сетка из пары сверточных и полносвязных слоев натренируется до 97%… а 92 — это даже хуже, чем описаный мной пару лет назад unsupervised метод, дайющий 96%.
Оценка должна быть справедливой, наш результат — за 2 минуты во 2-ой тысячи лидеров.
2 минуты тренировки? Лень проверять, но LeNet на моей не самой топовой GPU тренируется 1-2 минуты до тех 97%.
Другую задачку с House Prices, решили решать с использованием Кeras(theano) (for TensorFlow), на то чтобы разобраться с возможными решениями часов и выбрать лучшие по данным публикаций ушло примерно 13, подготовить данные (номализовать) обучить и протестировать ушло примерно 17 часов. А результат (0,32) полученный не многим лучше чем у Brain2 (0,42) где все создание моделей автоматизированно и заняло 30 минут!
Даже не знаю что сказать:) Может стоит сначала изучать инструмент, а потом им пользоваться...
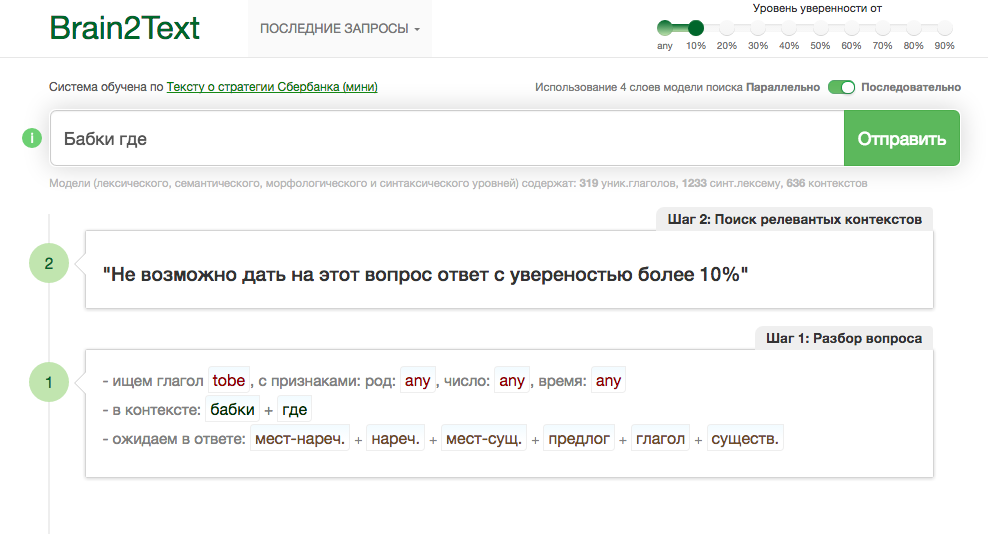
Отчего, Вы не обратили внимание, на то решение, над которым мы очень много работали Brain2Text. И то, что решения для синтеза предложения из слов пока ни у кого из лидеров рынка не представлено, не говоря об синтезе ответа?
А Siri то как работает?) Ну и там всякие цепочки LSTM'ов и все такое проче...
Никого не хочу обидеть, или оскорбить, но чет какой-то фэйспалм это всё :(
Чтобы не быть голословным, забенчмаркал MNIST.
Вот такая сетка:
def LeNet5(x):
net = tf.reshape(x, [-1, 28, 28, 1])
with tf.variable_scope("conv1"):
net = layers.conv2d_relu(net, [5, 5, 1, 20], [20])
net = layers.maxpool2d(net)
net = tf.contrib.layers.batch_norm(net)
with tf.variable_scope("conv2"):
net = layers.conv2d_relu(net, [5, 5, 20, 50], [50])
net = layers.maxpool2d(net)
net = tf.contrib.layers.batch_norm(net)
fc_size = int(net.get_shape()[1] * net.get_shape()[2] * net.get_shape()[3])
net = tf.reshape(net, [-1, fc_size])
with tf.variable_scope("fc1"):
net = layers.inner_product(net, [fc_size, 500])
net = tf.contrib.layers.batch_norm(net)
net = tf.nn.relu(net)
with tf.variable_scope("fc2"):
net = layers.inner_product(net, [500, 10])
return netЗа 500 итераций сходится к 99% точности. Время тренировки: 50 секунд на GTX980Ti...
А при размере батча в 2048, за 20 секунд сошлось к тем-же цифрам...

1) Были уже всякие RapidMiner'ы и прочие тулы для автоматического построения моделей… у всех есть один главный недостаток: когда мы получили какую-то модель, а результат не можем объяснить, то смысла от этой модели никакого:
И вот тут мы приходим к тому, что человек, который как умная обезьянка тычет по кнопкам, не понимая происходящего, может получить какой-то результат, но что с ним делать дальше — он не знает. Т.е. результат вроде бы есть, но на самом деле его нет.
Ну а в случае этого Barin2, даже результат странный — 81% на MNIST'е говорит о том, что даже на простейших модельных задачах автоматически как-то все не очень круто работает. Как правильно пишут выше: а давайте возьмем cifar10 и попробуем на нем запустить ту-же задачу… скорей всего там все рассыпется.
А если инструмент позиционируется как продвинутый калькулятор, то его корректней сравнивать с Excel, а не tensorflow или torch.
2) Обработкой текста на практике я не занимался почти, т.ч. тут могу ошибаться и, возможно, решение Brain2Text — это что-то прорывное, хотя результаты работы не впечатляют от слова совсем. Но всякие чат-боты — это вроде-бы довольно горячая тема последних пары лет и их лепят все кому не лень. Гугл выдает десятки репозиториев с различными решениями на рекурентных сетях.
Кстати, в табличках не правильно указаны названия TensorFlow и Azure… там разработчики — это точно не пара студентов первого курса?)
Просто как-то нескучными обоями повеяло...
А что не так с Россией?
Есть, наприер, success story у авторов Prism: ребята вовремя уловили тренд, вложили денег в high load сервис, способный deep learning тянуть с минимальной задержкой и стали лидерами в области стилизации фотографий.
Ну или findface — крутые ребята, которые сначала на MegaFace победили, и продвигают свою технологию распознавания лиц.
Туда же и Yandex можно отнести, вот уж кто серьезно рисерчем занимается в России.
Ну и по мелочи есть еще куча компаний, кто по большей части на аутсорс делают решения на основе машинного обучения и прочего data science.
Имхо, были бы знания и идеи, а остальные вопросы в этой области решаемы, даже в России.
В экономиках Казахстана и Турции преобладают позитивные тенденции. ВВП Казахстана в 2012
году увеличился на 5,1%, в ближайшие годы ожидается сохранение достигнутых темпов роста.
Замедление ВВП Турции в 2012 году до 2,2%, вероятнее всего, является временным, в
последующие годы можно прогнозировать повышение темпов роста до 4%.
ВВП Казахстана
темпы ВВП Казахстана
есть замедление ввп турции в 2012 году до 2.2 проц вероятнее всего
Есть ли у России шансы на лидерство в «марафоне искусственного интеллекта»