
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Слышал шутку, что яндекс вообще на любую позицию по алгоритмам гоняет
Бедные курьеры...
Не курьеры, а коммивояжеры.
Я не настоящий сварщик, я маску нашёл, но насколько я понимаю, под словами "задача коммивояжёра" и "задача о рюкзаке" могут подразумеваться несколько разные вещи, в том числе NP-полные задачи, так что сведение одной к другой неочевидно в таком простом заявлении, как ваше :)
Лично я дипломированный трубочист (серьёзно), так что давайте поговорим :)
Руку на отсечение не дам, но вроде бы, в обоих случаях задачи разрешимости NP-полны, и не всегда ясно, когда говорят просто про рюкзак (коммивояжёра), имеются ли в виду оптимизационные задачи или речь про разрешимость.
Насколько я вижу по вики (да и всегда думал) — задачи имеют разное название потому что это разные задачи. Там где задачи явно сводятся к другим обычно это пишут, например тут
The knapsack problem is a generalization of subset-sum.
Если не пишут значится что не сводится одно к другому
Не согласен с такой формулировкой. Если на си можно написать компилятор идриса а а на идрисе компилятор си это не означает что между ними нет разницы.
Лично я дипломированный трубочист (серьёзно), так что давайте поговорим :)
Если вы чистите трубы только тем, кто не может прочистить их сам, у меня к вам есть один вопрос. :)
Я не настоящий курьер, я рюкзак нашёл! У подъезда, вместе с велосипедом
Сколько теннисных мячей поместится в сумку
В голос, спасибо! :)
Это ещё что... Когда проходил собеседование на менеджера продукта, для какой-то важной оптимизированной операции решил использовать бинарный поиск по постоянно поддерживаемому сортированному набор строк (вполне умещались в RAM). А собеседовавший меня менеджер проекта (хотя там ещё был аналитик, не считая HR) завернул мой вариант, обосновав, что тогда потребуется индекс, а операции над ним дорогие при таких объёмах данных и требованиях к производительности. И что характерно, аналитик его не поправил. После этого я уже не стремился в их команду, потому что либо каждый должен заниматься своим делом, либо должен хотя бы знать то, о чём говорит, и понимать, что говорят другие, либо не участвовать в решении при недостатке компетенции. А уж с чем-то минимально сложным с максимальным приближением к реальному практическому решению тот товарищ вообще не совладал (это уже из опыта их приёма выполненного мною тестового задания для самостоятельной работы).
бинарный поиск по постоянно поддерживаемому сортированному набор строк
какая по вашему будет сложность вставки в такой список? и устроит ли она вас? мне кажется, что вас хоть и не поняли, но вариант вы предложили так себе. хотя и возможно, что если уточнить задачу и ваше предложение, то окажется, что всё хорошо
Да, только вот толку от всего этого мало. И подход найма такой весьма спорный, а точнее далеко не всегда оправдан, даже в таких конторах как Яндекс. Понты и глупость.
Ищут крепких середнячков. А настоящие таланты проявляются если даже и в процессе стресса, но стресса свободного, творческого, уже в работе, а не в рамках экзамена под страхом его провалить-) Экзамены подобного типа раскрывают несколько иные навыки, но мало когда именно таланты. Многие таланты от воздействия стресса наоборот теряют эффективность и работодатель теряет многих реально крутых людей. Не все к сожалению это осознают. Но это факт. Чистый совок, и не только в российских реалиях, в том же гугле примерно то же самое, нужны крепкие и послушные рабы, конвеер. Почему сейчас еще модны так называемые гибкие технологии, внедряемые везде где ни попадя, загубливая на корню многое полезное.
И ЗП меньше среднего, прям как в Яндекс доставке!
А они так и делают всегда, но в конце будет меньше всё-равно.
Ну и тем более, зачем они тогда нужны, такие красивые. Да еще и с нарочито похабным отношением к кандидатам и людям в целом. Было бы еще оправдано рвать задницу за хотя-бы полляма деревянных по нынешнему курсу в месяц. А если еще и ниже рынка-идут лесом однозначно. Экзамены можно и в других местах пройти-)
После прочтения предыдущих комментов и поста, а потом вашего коммента, в голове само всплыло название следующего сервиса: Яндекс.Девопс. Ну, знаете, сдача админов, которые почти прошли собеседование, в аренду клиентам Я.Облака.
Ну, чтобы просто результаты собеседований хоть как-то применить, даром, что они по алгоритмам!
В большинстве случае требуемые ими знания и даже формат мышления в реальной работе не нужен, а иногда даже вредит. Так как помимо алгоритмов есть ряд других навыков, которые в процессе муштрования кандидатов по алгоритмам, которые безусловно важна как часть основы, просто упускаются из виду, например в части просто логического мышления в других прикладных областях. По алгоритмам достаточно задать не более двух вопросов, остальное-явный перебор.
Меня не взяли водителем беспелоднега хотя я идеально соответствую требованиям вакансии. Про алгоритмы, с.ка, даже не спросили...
для того чтобы уметь и быстро выучить все эти смешные ci/cd, при хорошем понимании основ работы вычислительных систем-нужно немного времени. и наоборот, если вы будете знать ci/cd примочки, но не будете знать основ, основы вы освоить быстро не сможете, да и знания этих примочек будут почти бесполезны. вот в чем ошибка всех этих новомодных собеседований по ci/cd.
и еще, справедливости ради, те кто знает алгоритмы, пусть даже интуитивно, те пишут всегда еще лучше. но конечно не до абсурда как делают порой в Яндексе, по признанию очевидцев разумеется.
для того чтобы уметь и быстро выучить все эти смешные ci/cd, при хорошем понимании основ работы вычислительных систем-нужно немного времени
ну да ну да
и наоборот, если вы будете знать ci/cd примочки, но не будете знать основ, основы вы освоить быстро не сможете, да и знания этих примочек будут почти бесполезны.
примеры основ в студию, без которых практически невозможно освоить ci/cd
и еще, справедливости ради, те кто знает алгоритмы, пусть даже интуитивно, те пишут всегда еще лучше
какая вообще взаимосвязь между алгоритмами и ci/cd ? Правильный ответ - около нулевая. Видел я как девелоперы написали ci/cd на nodejs, обнять и плакать
если это учиться за неделю-две и в Яндексе свои велосипеды?
так и хочется посмотреть как ты за неделю освоишь gitlab/github actions c тераформом, поверх которого argocd. Удачи )))
как обычное собеседование на сисадмина, ничуть не больше. остальное-легко догоняется в процессе. тем более что процессы везде различные.
главное знание и понимание базовых вещей, а умение выстраивать и сопровждать ci/cd - это все равно что слесарю-сантехнику выбирать гаечный ключ нужного размера и крутить гайку в нужном направлении. но суть работы самой сантехники от этого понятна не будет.
В моем случае это правда: соискал позицию тестера. Правда, отшили после двух и "зошто" не случилось.
Они проверяют не эрудицию (знания) а ум - умение думать
Задачки нормальные, но зачем столько? Трёх-четырёх достаточно. Я бы уже на втором таком интервью вежливо распрощался, если я захочу порешать задачки, я пойду на hackerrank или leetcode.
В свое время я не успел решить одни задачки на время, честно сказал интервьюеру, что если им так нравится, они могут сами решать олимпиадные. В ответ получил оффер.
Если это так, столько собеседуют потому что якобы не доверяют-то это уже кризис управления и в конторе бардак, следовательно делать там нечего. Но скорее что это чушь и байка(про собеседования из-за недоверия внутри конторы), все там четко выверено в плане механизма собеседований. А бардака там и так полно, это его никак не исключает кстати. По качеству их сервисов это видно.
Но там не задают задачу на написание хеш таблицы. Максимум на использование. И полностью рабочее бинарное само-балансирующееся дерево — тоже не задают. Максимум тривиальное дерево. Просто для проверки, что кандидат может представить структуру и хоть чуть-чуть понимает, как работают указатели.
давать относительно несложные (не примитивные, но и не настолько сложные, чтобы отсеять вообще всех, кроме гениев и тех, кто подобное решал) задачи, где надо не алгоритмы помнить
Ну посмотрите же задачи из статьи. Где там хоть одна, где надо алгоритмы помнить? Максимум, знать, что есть такая структура данных — хеш-таблица.
А примерчик ещё проще чем в статье можно? Там все еще проще вырождается в однострочник или физзбазз.
IDE или не IDE дискуссионно.
Самое плохое в этом всем — то, что в подобных конторах собеседуемому код надо писать не в IDE, а на доске или в условном notepad-е. Это вообще бессмысленное занятие — примерно как проверять, умеет ли оператор экскаватора копать лопатой. Что вы, блин, так проверяете, знание синтаксиса языка? В вакансии на миддла-сеньора, бгг? Еще проверьте, знает ли он алфавит тогда.
Ну так в отличие от ИДЕ от вас не требуется написать компилируемый код, а иногда не требуется и брать существубщий ЯП — достаточно просто набросать алгоритм, чтобы было понятно что куда и как. Вангую что никто не будет докапываться если в каком-нибудь SelectMany букву забудете или порядок аргументов какой-нибудь функции перепутаете. Главное как вы будете рассуждать и какие уточняющие вопросы задавать.
Если от вас требуют написать без ИДЕ на бумажке идеально компилирующийся код без ошибок — то это вполне хороший фактор чтобы туда не идти. Так что не вижу ничего плохого в том чтобы получить на такое отказ.
пишет алгоритмы а не программы
Что? По определению, любая программа — алгоритм. Если вы придираетесь к тому, что там на интервью спрашивают заумные алгоритмы, которые в реальной работе не пригодятся — то вы не правы.
Вам так сложно представить, что в яндексе может возникнуть задача взять общие элементы из двух списков (задача из статьи с интервью)?
Я за свою недолгую пока карьеру в гугле много раз использовал и математику и писал хитрую структуру данных, и динамическое программирование. Не каждый день конечно, но эти вещи реально пригождаются. И самое печальное, что если этого всего не знать, то даже мысль не возникнет о том, что вот тут можно было "алгоритм" впендюрить и получить более быстрый и простой код. До этого немного поработал в яндексе, и там пришлось, например, использовать trie для ускорения процесса в несколько раз. Этой структуры нет в stl. Про нее надо хотябы знать, иначе как вообще ее нагуглить?
Сколько конкретно разработчиков в Яндекс будут решать задачи с новой реализацией хеш-тейбла?
Такая крупная компания, могли бы сесть, подумать с менеджерами и выдать идеальный ответ — организовать специальный отдел девелоперов-математиков, найти подходящих людей и ставить им задачи.
А не задавать это ВСЕМ подряд, учитывая что такие вопросы задают даже менеджерам (вот они точно будут писать новые реализации хеш-тейблов?)
— это действительно нужно (только тогда нужно давать не только самые элементарные вопросы),
это результат того, что в компании — корпоративный культ карго, выросший из того, что раньше это было действительно распространено и на этом Яндекс что-то выигрывал у конкурентов.
Вы налили тонну воды, но ответ все же дали — две задачи должно быть достаточно для общего случая.
сколько нужно — не знаю.
Вы меня поразили прям в мозг. Ну добавьте тогда в ваш зоопарк интервьюеров, которые выдают результат в зависимости от дня недели, и интервьюера, который убивает кандидатов с шансом 50%… В моём понимании интервьюер — это функция, которая принимает на вход знания кандидата и выдаёт 0 или 1. Если этот интервьюер выдаёт много FP или FN, значит это паршивый интервьюер и нафига он нужен. Если есть шанс ошибки, то поставьте 3-4 интервьюера рядом и пусть они исправляют друг друга. Добавьте ещё штуки 4 теста для быстрого вылета кандидатов, типа если напишут O(n^2) или если ник начинается с k, то сразу отлуп. Всё.
Судя по тому, что я видел, Яндекс не парится и берёт пулл кандидатов, пулл сотрудников, и как на той картинке с игрушечными собачками скрещивает их. А ведь эту кучу часов, которые рекрутеры тратят на кандидатов, можно было потратить, чтобы — внезапно — улучшить рекрутеров самих и весь процесс в целом.
Я как кандидат — в печали. Я хочу максимально быстрый ответ и, желательно, фидбек. Тут ни того, ни другого. Ну хоть посмеялись всем хабром.
раз недостатка в кандидатах нет
Я провёл больше сотни собеседований и почти половина кандидатов не смогли решить даже элементарной задачи типа «эффективно удалить нули из массива».
Если инплейс то можете подсказать как? Потому что так-то ничего сильно лучше arr.Where(x => x != 0).ToArray() и не придумывается.
Ну Яндекс большой и наверняка в каких-то его уголках есть культ карго. Но в целом — вряд ли. Тут ведь ещё какое-то дело — если не использовать текущую систему найма, то какую использовать? Система с «давайте пообщаемся о прошлом опыте» — полный отстой, т.к. пролезает очень много буллшиттеров (которых потом ещё хрен уволишь).
Можно тоже пример? По опыту в маленьких компаниях это отлично работает, не очень понятно что именно должно сломаться в случае большой. Или у вас в маленьких тоже не работает? Тогда тем более хотелось бы услышать ответ.
Если инплейс то можете подсказать как?
Примерно так:
function remZero(arr) {
var p = 0;
for (var i = 0; i < arr.length; ++i) {
if (arr[i] !== 0) {
arr[p++] = arr[i];
}
}
arr.length = p;
}А ну да, логично, даже странно что я про это не подумал. Мне почму-то показалось что мы можем элементы местами менять и нарушить относительный порядок. Немного не в ту сторону подумал.
В целом это и есть arr.Where(x => x != 0).ToArray() только копируем прям на месте вместо свободных нулей. Да, спасибо, тупанул чет
По прошлому опыту это ведь не просто "наврите нам покрасивее" а вопросы по этому опыту. Почему сделали так, а не иначе. А вот зачем этот компонент. И так далее.
Плюс можно гитхаб посмотреть если есть, если нет — то все же какую-нибудь задачку разминочную на 10 минут тоже можно. Это не дрючить 10 алгоритмическими задачками на 5 раундах собеседований, но какое-то видение дает. Вкупе с вопросами по арихектуре можно делать выводы.
Уже сейчас есть в интернете куча платных и бесплатных курсов, задрачивающих людей решать задачи. Т.е. человек без опыта может научится решать задачки и пройти интервью.
Если FAANG будет спрашивать массово про опыт и профиль на гитхабе, то будут курсы, которые будут учить людей складно рассказывать про "прошлый опыт" и объяснять по этому чужому профилю на гитхабе, почему сделали так, а не иначе.
В текущей ситуации имеем людей, возможно вайтишников, которые научились решать алгоритмические задачи. Значит перекладывать json они точно смогут, ибо это проще. В гипотетической ситуации будем иметь кучу вайтишников, очень слабо программирующих, но складно говорящих.
Вторая проблема: поговорить про опыт и посмотреть гитхаб — слишком субъективные оценки. Такое не годится для крупных компаний, которых пытаются засудить за дискриминацию, потому что интервьювер посмел спросить про размер байта в битах.
А еще это на порядок сложнее для интервьюверов. Сходу вот так глядя на неизвестный вам проект понять, что вот такое решение было лучшим, невероятно сложно. Это потребует невероятно много времени подготовки у интервьювера. Когда как задачки можно спрашивать одни и те же, пока они не утекут в сеть.
Вот и получается, что спрашивать задачки — единственно подходящее решение для интервью в FAANG/Яндексе. Оно скейлится, более менее объективно, просто в оценке, проверяет что-то вполне релевантное работе.
Если FAANG будет спрашивать массово про опыт и профиль на гитхабе, то будут курсы, которые будут учить людей складно рассказывать про "прошлый опыт" и объяснять по этому чужому профилю на гитхабе, почему сделали так, а не иначе.
Складно рассказать про прошлый опыт по-моему невозможно не прожив этот самый опыт. Шаг влево-вправо от "рассказывали на курсах" и провал. По крайней мере мне слабо представляется как можно составить решебник на все возможные вопросы.
Вторая проблема: поговорить про опыт и посмотреть гитхаб — слишком субъективные оценки. Такое не годится для крупных компаний, которых пытаются засудить за дискриминацию, потому что интервьювер посмел спросить про размер байта в битах.
Ну это да, но мне показалось выше сказали что и для маленьких такой способ не подходит.
А еще это на порядок сложнее для интервьюверов. Сходу вот так глядя на неизвестный вам проект понять, что вот такое решение было лучшим, невероятно сложно. Это потребует невероятно много времени подготовки у интервьювера. Когда как задачки можно спрашивать одни и те же, пока они не утекут в сеть.
Так что сложного? Все непонятные места адресуются кандидату — по его ответам будет понятно, думал он про это или нет, какие варианты отбросил и т.п. Не надо додумывать — надо спрашивать (если конечно есть у кого), наверное одна из первых вещей которые я понял когда начал работать: быстрый фидбек с короткими циклами — залог успеха.
Вот и получается, что спрашивать задачки — единственно подходящее решение для интервью в FAANG/Яндексе. Оно скейлится, более менее объективно, просто в оценке, проверяет что-то вполне релевантное работе.
Ну задачки отбирают либо студентов которые недавно их проходили либо сверхмотивированных людей которые в свободное время прорешивают литкод чисто ради фаанга. Пробовал так сделать в прошлом году — после пары десятков задач задолбался и забил.
Я не предлагаю никаких альтернатив, просто рассматриваю минусы текущего подхода. Вполне вероятно это лучшее из худшего.
лучшее из худшего.
Тоже так считаю. Да, у студентов приемущество возникает и нужно тратить время на подготовку. Ужасный метод. Но лучшего, на мой взгляд, нет.
Ужасный метод. Но лучшего, на мой взгляд, нет.
Тут в соседнем треде мне другой товарищ доказывал, что эти алгоритмические интервью — ужасны, потому что их проходят легко "профессора" знающие наизусть О-большое всех-всех алгоритмов и умеющие доказывать заумные абстрактные утверждения, но вообще нисколько не умеющие писать код.
В отличии от текущих интервью, ваш вариант как раз подвержен такой проблеме.
Он никак не проверят, что кадидат может писать код. Он никак не проверят, что кандидат умеет решать задачи, а не выбирать из нескольких предложенных вариантов.
Нет. Вам не даны несколько вариантов. В реальной жизни у вас есть только задача. Вам надо эти варианты еще найти. Как понять, что вот этот вот ответ на стекоферфлоу — хороший? Надо ли искать дальше? Или подобно задаче о привередливой невесте, ищем 4 ответа и берем лучший, надеясь, что среди этих 4-х есть нужный?
Теперь про стандартные библиотеки: 99% всего что вы делаете — нет в библиотеках! Вы можете прикрутить стандартную структуру данных, или найти какой-то фреймворк, который надо как-то потыкать, и часть вашей задачи будет решена. Но практически все, что вы делаете — это решение одной частной ВАШЕЙ задачи. Магической функции "сделать хорошо" нет ни в одной библиотеке.
Это нормально понимать, что вам тут нужно сбалансированное дерево поиска, и взять готовую реализацию из библиотеки. Но если вы не знаете, что вам тут нужно именно дерево, то что вообще искать?
пусть интервьюируемый посмотрит их и скажет какое лучше и почему
ну или алгоритмиста.
Ну нет смысла нанимать выделенного алгоритмиста. Весь абсолютно программный код по определению — алгоритмы. Большая часть — тривиальные, типа пройтись по списку и выбрать минимум или сложить 2 числа.
Без знания о том, какие бывают алгоритмы, без умения решать задачи и алгоритмического мышления часто сложно даже понять, что вот эта задача — она решается тупо (прошлись по списку и выбрали минимум), а вот та — совсем нет.
Потому что почти всегда есть простой, понятный и очень не эффективный наивный метод.
Потому что эта самая алгоритмическая задача ничем принципиально не отличается от всех других задач, которые программисты постоянно решают.
В итоге получается, что выделенный алгоритмист должен ревьювить вообще весь код в компании. С потоком кандидатов FAANG/Яндекса эффективнее, дешевле и удобнее сразу нанимать только "алгоритмистов".
с которым больше поговорить
С "поговорить" большая проблема — это очень субъективно. Мелкой компании, где условный CTO сам проводит интервью и решает: кого брать, кого нет — это работает. В крупной типа яндекса и FAANG — уже нет. Плюс, если язык хорошо подвешен, можно тупо заболтать интервьюера в процессе этого "поговорить".
Плюс, если язык хорошо подвешен, можно тупо заболтать интервьюера в процессе этого «поговорить».Без знаний особо не заболтаешь, если человек подходит ответственно к интервью: можно же спросить технические детали/особенности, да и github человека можно посмотреть.
Нет, выделенный алгоритмист должен вместе с архитекторами решать как будет работать самые высоконагруженные компоненты.
Или у пользователей по всему миру отвалиться условный ютуб на пару часов, потому что упал какой-то служебный сервис из-за возросшей внезапно нагрузки. Или несколько часов не будет показываться вся реклама от яндекса. Огромная денежная потеря.
Отвечу словами здесь https://youtu.be/NwEuRO_w8HE?t=2180 (там всего на 40 секунд вопрос и ответ). Если вас парит о-сложность до того, как вы запустили код, прогнали бенчмарки и обозначили SLA пользователям, вы занимаетесь преждевременной оптимизацией. В конце концов, насрать, что в формочке на фронте O(n^2), браузер клиента всё стерпит. Не мучайте фронта булщитом про пузырьковую сортировку, пусть об этом парятся люди, которые контрибьютят в ядро линукса или пишут низкоуровневые системные библиотеки.
А как проверить, что человек сможет исправить найденную после запуска плохую часть?
В конце концов, насрать, что в формочке на фронте O(n^2), браузер клиента всё стерпит.
А потом такие "вот сайт тормозит, пользоваться невозможно!!!". Или у людей игра грузится по 10 минут на пустом месте. При чем там наверняка такая же мысль была: Ну насрать, что там в чтении одного мелкого конфига O(n^2), клиент все стерпит. А потом n, внезапно, выросло и все стало плохо.
А потом такие "вот сайт тормозит, пользоваться невозможно!!!". Или у людей игра грузится по 10 минут на пустом месте. При чем там наверняка такая же мысль была: Ну насрать, что там в чтении одного мелкого конфига O(n^2), клиент все стерпит. А потом n, внезапно, выросло и все стало плохо.
Нет, "потом" такого не будет. Вы просто взяли и пропустили фразы про бенчмарки, SLA и так далее. Если в SLA не было оговорено условное время загрузки сайта, то что там оговорено было вообще?
Просто обычно программный код имеет столько внутренних нюансов, что замена алгоритма с O(n^2) на более оптимальный может замедлить скорость работы, если это делать в слепую.
Вы игнорируете константу, вы игнорируете наиболее полулярные N и так далее.
Что лучше, что бы у большинства пользователей корзина покупок грузилось секунду, а у кого-то 5 или что бы у всех грузилась по 3 секунды?
Только и константы там одинаковые.
Обычно сделать более быстрый (асимптотически) код ничего не стоит. Классический пример который вижу в дотнете: foos.OrderBy(x => x.Something).First().Bar. Если это на старте приложения 1 раз делается или там в какой-нибудь режкой ручке — то как бы и плевать. А когда элементов достаточно много да и код выполняется довольно часто — то как бы не очень.
При том что решение — загуглить за 5 секунд любую из библиотек-расширений LINQ (либо написать свой хелпер за 5 секунд), и заменить это на foos.MinBy(x=>x.Something).Bar — почти те же буквы и те же константы, только уже за линию.
Только и константы там одинаковые.
Зависит от контекста. Всегда люблю приводить в пример перемножение матриц)
Обычно сделать более быстрый (асимптотически) код ничего не стоит.
Зависит от контекста. В вашем примере — не стоит. В каком-то случае это ухудшение читаемости и поддерживаемости кода. В каком-то случае это написание своего более оптимального велосипеда, который потом надо поддерживать.
Я не спорю, что в каких-то случаях вы просто улучшаете точность и все работает, но это явно не 100% и, скорее всего, даже не 50% случаев.
Сколько не работал с кодом, обычно существует одно место, которое тормозит больше всего, и это место отвечает за какую-то io работу в духе "сходи забери из базы что-то с кривым запросом". Переписываешь запрос и все работает :)
Даже во всяких cpu-bound задачах довольно часто спасает кеширование или исправление конкретного места.
Буквально на днях столкнулся с "возросшей нагрузкой" — есть корпоративный портальчик, ничего супер-пупер нагруженного, состряпали, запустили, пользуемся… через пару лет начинаются жалобы — тормозит. Автор портальчика к тому моменту уже потерялся, полез смотреть сам (я не программист) — оказывается, при каждом действии, ajax шерстит историю сообщений, чтобы в случае чего новенького отрисовать "колокольчик", а сообщений накопилось уже немало, а в алгоритме почему-то был линейный перебор с "ручным" анализом "новое/прочитанное" (таблица ID прочитанных сообщений была у каждого пользователя своя, а таблицы сообщений шли сплошной простынёй)… казалось бы — сделай запрос к базе по JOIN с "объединением по NULL", чтобы отобрать только непрочитанные, но автор решил несколько иначе — выбирал все сообщения, а потом искал их ID в "личной" таблице, и если не находил — высвечивал оповещение.
Вроде рабочий алгоритм, но вот с масштабированием совсем боль.
Ну так тут же дело не в каких-то неправильных алгоритмах, а в нарушение принципов работы с БД, что все выборки и расчеты максимально должны выносится в БД.
Ну так это ровно то же, что вы пишите. Выборка данных + расчет производных данных на их основе (преобразование функциями, сумма, вот этот весь треш).
Если вы фильтруете или преобразовываете данные потом на бекенде, то тут что-то немного не так. Иногда это ваша вина, иногда бд.
Я на самом деле очень люблю оптимизировать. Я несколько лет работал научным сотрудником в сфере, где широко использовалась wolfram mathematica. Я очень заморачивался над вещами типа сведения интеграла к сумме по элементам массива, над вставками на C, которые работали быстрее, итд. Но я это делал уже сильно после того, как написал первый прототип программы, который работал нормально, а потом захотелось больше отзывчивого UI. Я не считаю, что рядового кодера в стрессовых условиях собеса нужно мучать на оптимальные алгоритмы. Для этого давно есть библиотеки и только в редких случаях возникнет реально проблемный боттлнек, где придётся оптимизировать код. Если такое случится — ну, ок, сядет разраб и в спокойной обстановке поищет, в чём там проблема.
При строитенльстве домов теже проблемы, только в меньшем масштабе. Возьмите типичную квартиру и посмотрите как расположены там розетки, используются ли вские тройники и удлинители. А ведь это все можно было решить на этапе ремонта. Вот только для этого нужно точно знать где какая мебель будет стоять, какие у неё будут размеры, какие электроприборы и где будут стоять и использоваться. Точно это предугадать невозможно, поэтому и возникают все эти удлинители или абсурдно огромные группы розеток "на всякий случай".
Так же и в разработке софта. Мы зачастую не знаем сколько у нас будет пользователей конкретной фичи, не знаем какие фичи будут добавлены завтра, а какие убраны. Мы даже не знаем кто будет завтра с этим кодом работать. То что мы знаем точно — так это то что проект точно будет меняться или умрет. Но что именно будет меняться — можно лишь гадать. И правильно угадывать мы будем далеко не всегда. Поэтому намного выгоднее писать код таким, чтобы его было легко менять в будущем, пытаться предсказать что может поменяться, а что нет. А еще, чтобы его могли понять другие разработчики, желательно без необходимости вникания во всю историю проекта. Хороше же оптимизированный код зачастую сложно читать, сложно расширять. В итоге приходится балансировать между расширяемостью, читаемостью и оптимизацией. Хороший разработчик — не тот кто упарывается в одну из этих крайностей, а тот, кто умеет находить баланс в каждом конкретном случае. Когда надо — писать хорошо оптимизированный write only код, а когда надо — медленный, но легкочитаемый и/или легкомодифицируемый, а в большинсте случаев — что-то среднее.
Хороше же оптимизированный код зачастую сложно читать, сложно расширять.
Это только если упарываться микрооптимизациями. Если просто использовать нормальный алгоритм или структуру данных — то код часто даже проще и понятнее. Что легче — полный перебор через рекурсивную функцию с откатами и неочевидными отсечениями, или динамическое программирование, которое все — 2 вложенных цикла и тривиальная формула для пересчета одной ячейки массива через соседние?
Поэтому намного выгоднее писать код таким, чтобы его было легко менять в будущем,
Спасибо, вы меня поняли. Заморочиться и написать fast inverse square root всегда можно потом.
заходишь такой в интернет-магазин… и обычный обывательский мобильник вешается.Зашёл я как-то на один технический новостной сайт с обычного пользовательского мобильника…
В конце концов, насрать, что в формочке на фронте O(n^2), браузер клиента всё стерпит. Не мучайте фронта булщитом про пузырьковую сортировку
Браузер стерпит. Пользователь может и не стерпеть.

А конкуренты куда делись?
И как вам тут алгоритмы помогут? Отказоустойчивость проверяется нагрузочным тестированием. Даже идеальный алгоритм захлебнётся, если элементарно не хватит нужных ресурсов.
А потом систему в проде уронит случайный метод. Потому что на него внезапно пришла нагрузка, а он сделан так жутко что роняет всю БД.Я ведь верно понимаю, что любой алгоритмист, при устройстве на работу, гарантирует своему работодателю некий аналог sla с несколькими девятками, и полной компенсацией в случае падения прода? Или алгоритмисты только говорить могут, а на деле роняют прод примерно так же часто, как и обычные инженеры?
А потом систему в проде уронит случайный метод. Потому что на него внезапно пришла нагрузка, а он сделан так жутко что роняет всю БД.
Ну нет смысла нанимать выделенного алгоритмиста. Весь абсолютно программный код по определению — алгоритмы. Большая часть — тривиальные, типа пройтись по списку и выбрать минимум или сложить 2 числа.
Под "алгоритмистами" чаще всего понимают рисерч-инженеров… давайте расскажите, как компаниям не нужен R&D и все можно порешать на уровне понимания "сейчас пройдемся по списку и сложим два числа"...
ну или алгоритмиста
А что не так? В Яндексе нет настолько умных людей как в FAANG? Или они не делают нормальные сервисы?
В Яндексе нет настолько умных людей как в FAANG?Вполне вероятно, что в FAANG средний уровень выше банально за счёт того, что и конкуренция, и ареал поиска кандидатов куда больше.
Или они не делают нормальные сервисы?Ну, не знаю, огромная доля сервисов Яндекса со стороны кажется банальным симптомом болезни «а во. такая штука появилась на рынке, значит, надо делать свой клон». Редкое исключение — божественный Яндекс.Маркет, но и его загаживают последнее время жутчайше.
негативных отзывов на поведение контор из избранного списка
Вот здесь столько спецов из яндекса рассказывают про крутые алгоритмы, и ведь никто не ответит, почему на жалобу, что в яндексе галочка «искать как в запросе» банально ничего не делала и выдача оставалась такой же, решение было принято по удалению данной галочки.
Ну, так сказать, вот они — крутые олимпиадники в действии…
Вполне вероятно, что в FAANG средний уровень выше банально за счёт того, что и конкуренция, и ареал поиска кандидатов куда больше.
Вполне вероятно, что в FAANG средний уровень выше банально за счёт того, что и конкуренция, и ареал поиска кандидатов куда больше.
пройдёт лет 10 и слоупоки-подражатели типа Яндекса тоже сменят пластинку и начнут подражать новым веяниям из Кремниевой Долины
TaskId enque(Task task, Time time);
void cancel(TaskId taskId);
Вообще, стандартное решение этой задачи — с использованием priority_queue.
В очереди хранится пара {время, TaskId}, упорядоченная по минимуму времени. Еще нужен map TaskId->время. При enqueue создается новая задача и помещается в очередь. При cancel соответствующая запись из очереди удаляется.
Не надо даже писать очередь, можно использовать stl-овскую, например. Правда, могут спросить, а представляете ли вы как эта структура данных работает.
Другой поток просыпается при любом enqueue или по таймеру. При просыпании он смотрит, пора ли выполнять следующую задачу и выполняет ее. Если рано — ставит таймер до следующей задачи.
По-моему, при написании от кандидата не требуют знаний системных вызовов для таймеров, событий и потоков. Обертки над всем этим и так есть в любой большой компании. Достаточно сказать: ну пусть у нас есть Event, у которого есть метод Wait(timeout), который усыпляет поток, пока не выйдет таймаут или кто-то не вызовет у этого объекта метод signal. Тут интервьюер может даже подсказать, если только кандидат скажет, что надо усыплять потоки. Если кандидат знает про select — это плюс.
Потом могут быть дополнительные вопросы, а что делать, если какая-то задача выполняется дольше, чем дедлайн до следующей? (запускать следующую сразу и не засыпать). Можно ли выполнять задачи в несколько потоков? (можно. Один поток все так же спит, отсчитывает таймеры и работает с очередью, а другие спят пока не получат задание на выполнение).
Еще надо помнить про всякие крайние случаи — типа enque задачи в прошлом времени.
Колеса времени
В очереди хранится пара {время, TaskId}, упорядоченная по минимуму времени. Еще нужен map TaskId->время. При enqueue создается новая задача и помещается в очередь. При cancel соответствующая запись из очереди удаляется.
Тогда уж нужно TaskId -> Node, чтобы можно было из очереди за О(1) удалить, иначе для удаление задачи с конца нужно долго и упорно пёхать по всей очереди (если она в виде связного списка реализована).
Из priority_queue за время О(1) удалить не получится. По крайней мере, если это priority_queue на основе "пирамиды".
Хотя если брать "в среднем", то да, О(1) и выходит… Но в любом случае для нужно время, а не Node.
Впрочем, если есть Node, то его можно не удалить, а "задизаблить".
Еще можно std::set использовать в качестве очереди.
Нет, они довели до абсурда худшие практики, которые в FAANG постепенно уходят из повестки собеседований.
Несколько лет назад, когда я проходил свои 4 собеседования в Яндекс, они всё же были другими. Там про архитектуру и проектирование систем спрашивали, про устройство Linux, распределённые системы и т.п. интересные вещи. А то, о чём написал автор — это квинтэссенция идиотизма. Бессмысленная трата времени и очень плохой алгоритм фильтрации и проверки кандидатов.
В начале собеседования с Гуглом, вас потребуют подписать NDA, что ни какие подробности интервью вы не можете разглашать. Какие последствия? Наверное через суд, заставят оплатить издержки, например, потратили время на 1000 кандидатов, которые уже знали заранее ответы, или оплатить 100 часов на переделку всех контрольных билетов. :-)
common = set(a).intersection(set(b)) # найдём общие элементы
for el in common:
occurs = min(a.count(el), b.count(el)) # и посчитаем, сколько они встречаются
Ага, сам знаю. Но именно так я и написал бы в проде. Это легко читается, достаточно быстро на небольшом количестве элементов (а сколько их обычно будет в реале, 10-20?), легко пофиксить, если станет боттленеком. Preliminary optimization — зло, как по мне.
list((Counter([1, 2, 3, 2, 0]) & Counter([5, 1, 2, 7, 3, 2])).elements())На интервью не требуют писать стандартные структуры данных. Сойдет и использование встроенной хеш таблицы. Запрещают пользоваться стандартной библиотекой там, где есть встроенное решение всей задачи. Иначе проверять нечего.
Ну, на худой конец, можно отсортировать и слить 2 списка. Будет O(n log n) вместо O(n). Если сказать, что можно и хештаблицей, но я боюсь, что не напишу ее за интервью.
))\n — скобки закрывать надо!
Dawson’s first law of computing: O(n^2) is the sweet spot of badly scaling algorithms: fast enough to make it into production, but slow enough to make things fall down once it gets there.
https://randomascii.wordpress.com/2021/02/16/arranging-invisible-icons-in-quadratic-time
а сколько их обычно будет в реале, 10-20?
20 уже много. Вот если 3-5. Причём нужно очень хорошо понимать, какие реальные объёмы могут встретиться на проекте. Не только самые типовые. А то потом получится как на gitlab-е, или ikea. На gitlab-е открываешь большой MR и оно едва ворочается. Или вот в ikea видимо тоже примерно так подумали — сколько человек товаров может заказать? 5? 10? Нормааально. Заказываем 14 и страница зависает на любое действие на секунды.
Не шутите с квадратами. Мы, программисты, очень часто далеки в своих оценках от реальности.
P.S. а ещё всякие катастрофические regexp-ы, убивающие поток на минуты попадись им строка чуть длиннее обычного.
Или вот в ikea видимо тоже примерно так подумали — сколько человек товаров может заказать? 5? 10? Нормааально. Заказываем 14 и страница зависает на любое действие на секунды.
Ситуации вида "ваш сайт дико тормозит" в коде вполне могут быть выражены ситуацией "наш код прекрасен и работает за O(1). Тормозит что-то? Ну, это проблема не на нашей стороне, а какой-нибудь там реакт редакс браузер виноват, но не мы (с)". Это, опять же — тоже реальный личный опыт из разгребания не вполне рабочих фронтовых проектов, созданных руками чудо-алгоритмистов.
Скажем, уже больше 10 лет назад меня попросили "оживить" проект-презенташку очень важных данных в виде таблички, где у чудо-алгоритмистов, написавших чудо-бэкэнд, вдруг возникли сложности с презентованием результатов. Я пришел, увидел код, который на примерно любое действие пользователя собирал огромнейшую строку (всю страницу вместе с большой-пребольшой таблицей в основе) и фигачил её в корневой элемент презенташки через innerHTML. Когда я немного пришел в себя и поинтересовался, как такое вообще могло появиться — мне было сказано, что тут всё реализовано через минимальную алгоритмическую сложность O(n), и это всё так и надо и правильно. А что тормозит (браузеры немного выпадали в осадок и потребление памяти дико скакало, с ожидаемыми тормозами в моменты, когда она вся выжиралась) — так это просто браузеры плохие. И вообще этот ваш веб новомодный отстой.
Я ни разу не спорю с тем, что базовые алгоритмы это только один из многих необходимых навыков :)
собирал огромнейшую строку (всю страницу вместе с большой-пребольшой таблицей в основе) и фигачил её в корневой элемент презенташки через innerHTMLТак дело именно в том, что это были не алгоритмисты, а ровно наоборот — люди, не имеющие представления об алгоритмической сложности. Уж алгоритмисты-то обязательно для начала поинтересовались бы, каково это — добавить здоровенное поддерево в dom. Сделали это как раз те, кто говорит и пишет в каждой подобной теме, как же это тупо — проверять кандидата на понимание алгоритмической сложности. Самому регулярно приходилось и приходится ликвидировать последствия подобного кода. А все потому, что люди даже не видят, не замечают, не понимают, что они на самом деле постоянно сталкиваются с оценкой сложности в повседневных задачах, вот о чем важно говорить.
Всё же механика часть физики.
И я такой не один, нас таких достаточно много.
В абсолютных цифрах — возможно. А в потоке людей — очень и очень мало. Ну представьте себе что человек проходит какие-нибудь 3-недельные курсы на ютубе, его научили правильно отвечать на "что такое солид" и какие-нибудь киты ООП, но он реально не программист, а какой-нибудь дворник который попал на таргетированную рекламу "заработай 100500 на ~~джойказино ~~яндексе".
И вот на одного такого вас 19 вот таких фот "типа программистов".
Если в маленькой компании с вами могут нормально поговорить по душам и распознать одно от другого (это не трудно, если уделить достаточно времени) — то в компании "на потоке" кроме как собсвтенно попросить кодить это не проверить.
Увы, тоже пример личный. Один человек вообще себя искренне называл "Аватар тестирования" (я иногда принимаю участие в собеседовании QA, рассказываю про архитектуру и прочие вопросы по компании с точки зрения разработки).
Есть и другие истории, но их пожалуй приберегу, не все из них хочется в паблик писать, мало ли увидят и обидятся.
Если числа не очень большие по модулю — то динамическое программирование, как в задаче о рюкзаке. Будет решение за O(n*M), где M — сумма всех чисел по модулю.
Если числа — любые инты, то только перебор.
А вообще, я невнимательно прочитал задачу. Там надо не подмножество чисел взять, а отрезок из массива. Решается за линию. Идем по массиву считая частичную сумму (до начала). Поддерживаем хешмап уже известных сумм. Смотрим, есть ли там target-<текушая сумма>. Если есть — мы нашли отрезок. Потом кладем текущую сумму в мап.
Нет, просто частичные суммы. От начала до текущего элемента.
Основная идея решения: сумма на отрезке — это разность двух частичных сумм. Поэтому если для каждой частичной суммы достаточно проверить, что левее есть нужная частичная сумма.
Вот набросок кода:
pair<int, int> FindRange(const vector<int>& v, int target) {
std::unordered_map<int, int> sums;
int current_sum = 0;
for (size_t i = 0; i < v.size(); ++i) {
current_sum += v[i];
if (current_sum == target) return std::make_pair(0, i+1);
auto it = sums.find(current_sum - target);
if (it != sums.end()) {
return std::make_pair(it->second+1, i+1);
}
sums[current_sum] = i;
}
return std::make_pair(-1, -1);
}Можно избавиться от одного случая, если изначально впихнуть в map {0, -1}, но понятнее без этого, мне кажется.
Памятка сотрудникам техподдержки:
Это письмо составлено не потому что проблему у Автора, а потому, что проблема у Вас
Это письмо составлено потому, что Автор уважает труд разработчиков и считает что фидбек лишним не бывает.
Автор сам может справиться любой проблемой или прекратить использование продукта.
Если вас устраивает, что ваши пользователи будут сталкиваться с вышеописанной проблемой, просьба проигнорировать это письмо или в ясной форме озвучить свою позицию в ответе.
Такие же наблюдения. Не понимаю где они берут специалистов с таким подходом?
Создалось мнение, что хорошие спецы попадают в большие компании будучи купленными в стартапах, а там где стартапов нет, там одни задроты-алгоритмены.
Но может это тоже работает? Нанимаешь абстрактного алгоритмена в вакууме и расширяешь необходимыми методами
Хотя, глядя на современный софт, и, даже фреймворки, разрабатываемые корпорациями, (привет гуглу и фейсбуку), которые, вообще, должны быть эталоном кода, понимаешь, что и там квалификация вайтишников на донышке.
ЗЫ опыт работы с пхп чуть больше года, уже три тикета на гитхабе aws php sdk создавал, и объяснял как им надо их баги исправлять… Мир катится в ад
Ну возьмите одного такого на 50 человек в качестве консультанта, чего ж в этом плохого? Конечно, иногда и список развернуть надо, но с чего бы такое внимание именно на этом аспекте?
Ну тут сразу два перебора получается: 1) спрашиваем три раза про одно и то же; 2) не спрашиваем больше ни о чём.
В некотором смысле каждый кулик своё болото хвалит — неудивительно, что люди, которые сильны в алгоритмах, считают, что это и есть самый важный и незаменимый навык. Но человек хорошо разбирающийся в железе или в особенностях того или иного языка/фреймворка /архитектуры тоже может доказать, что его навык самый главный. Тем более, что требования к алгоритмической задаче хорошо формализуются, и всегда можно найти если не своего, так внешнего консультанта, который это решит за лайки или за пиво.
Алгоритмы безусловно один из главных необходимых навыков, но далеко не достаточный, особенно когда он полностью оторван от прикладной области.
А собесы в Яндексе, по примерам очевидцев, создают впечатление, что с прикладной частью не сильно дружат. И для понимания и решения 90% прикладных задач среднего ИТ специалиста-программиста достаточно просто знания и понимания трех основных алгоритмов на пальцах. И основных структур данных. Что кстати не менее важно. И главное-их отображения и отработки системами. Остальное - доучивается в процессе работы и по мере необходимости, на опыте.
оно опирается на субъективность восприятия
(ну и чтобы киты в итоге побольше донатили, куда без этого
провал заточки 10 раз подряд, при шансе 75%
для опыта игрока должно получаться 3.
Не для "опыта", а для "эмоциональных ожиданий". Игрок, имевший опыт бросания монетки или изучения теорвера, как раз имеет опыт что серии — это ожидаемое поведение. И если их нет — значит рандом "накручен", и ещё вопрос в какую конкретно сторону.
А вот эмоционально можно ожидать и что "5% шанс сломать не выпадет никогда, а 75% сработает точно".
как раз имеет опыт что серии — это ожидаемое поведение.
в это ожидание не вписывается от слова никак
Да, это популярное заблуждение. С точки зрения эмоций — не вписывается. С точки зрения теорвера — это поведение рано или поздно обязано случиться. С точки зрения псевдорандомного генератора(а других не завезли) — оно случиться может.
Остаётся только делать не "честный рандом"(как того требуют эмоционирующие игрока) — а накручивать специальные "сбросы серий" и прочий мухлёж(да) чтоб эмоциональное ощущение не страдало.
А я бы сказал, что как раз апологеты подкручиваний в итоге привели ситуацию к тому, что публика начинает жаловаться на нейтральный ГПСЧ без подкручиваний.
В играх Blizzard нейтральный ГПСЧ остался только в серии Diablo, а остальные игры крутили его так дико, что особо умные игроки даже эксплуатировали это. Или вон при создании пользовательских карт в Warcraft 3, надо было использовать формулу пересчета вероятностей, чтоб обеспечить реальное статистическое соответствие между заданным значением, например, срабатывания абилки, и шансом появления этого в реальности. Задавать значение в 50% и ожидать срабатывания в половине случаев — было крайне наивно.
А нынче при столкновениях с нейтральным ГПСЧ в играх а-ля XCOM — у солидной части публики вдруг начинает пригорать. Ну как так, промах с 99% шансом попадания? Быть такого не может (с).
А я бы сказал, что как раз апологеты подкручиваний в итоге привели ситуацию к тому, что публика начинает жаловаться на нейтральный ГПСЧ без подкручиваний.
В играх Blizzard нейтральный ГПСЧ остался только в серии Diablo
статистическое соответствие
А нынче при столкновениях с нейтральным ГПСЧ в играх а-ля XCOM — у солидной части публики вдруг начинает пригорать. Ну как так, промах с 99% шансом попадания? Быть такого не может (с).
Не было его там никогда. У D2 лут строго привязан к локациям/боссам, а у д3 при инициализации игровой сессии усекалась лут таблица, выше описывал.
Тем не менее, сам ГСПЧ нейтральный. В том же варкрафте3 именно ГСПЧ постоянно "подкручивает" свои шансы в зависимости от предыдущих результатов.
Тем не менее, сам ГСПЧ нейтральный.
О господи, ну я вам даже дал в пример другую игру, погуглите что ли, прежде чем рассуждать.
Включите JA2 в какой-нибудь «режим железной руки» и сыграйте там.
После чего включите xcom современный с их постоянными промахами при 95% чуть ли не в упор и расскажите мне, что это игроки играть не умеют и проценты не понимают.
Я играл. И я по прежнему нахожу ваш confirmation bias невероятно забавным. Вполне возможно, что вы просто относитесь к "не могущим в статистику" людям.
В JA2 при использовании того оружия, которое стреляет по разу за действие — всё то же самое. Более того, движок JA2 оперирует (как и XCOM) именно процентами успеха, а не "физической моделью", из-за чего криворукий наёмник вполне мог не попасть большей частью очереди из автомата в упор.
Но именно обилие стрельбы делает JA2 на вид "более честным", чем XCOM: когда ты в ход можешь выстрелить раза 2-3 даже из снайперки, один промах тебя не особо будет беспокоить. И уж тем более тебя не будет волновать промах пары выстрелов из очереди.
В XCOM же выстрелы — это очень ценные действия, и неудивительно, что каждая ситуация с промахом 5% поджигает определенные чувствительные части тебя некоторых людей.
Дааа. Именно. Криворукий.
Ну вот, а в XCOM меткий оперативник, достигающий шансов попадания в 100% — не мажет. Вообще никогда.
Другое дело, что у продвинутых элиенов есть всякие свойства, минусующие шансы попадания по ним.
Только берём спеца, то даже очередями промахи снижаются весьма сильно.
Ну так и в XCOM нуб со базовым шансом попасть в 65% и профи — с 110% — это очень разные вещи.
Там и одиночные промахи бывают, при высокой вероятности попасть. Но это именно что несистемные случаи.
Ну то есть в JA2 "несистемные", а в XCOM "системные". Понятно. Так и запишем.
Только в искоме очередь вся улетает в молоко.
Потому что очереди не моделируются. "Выстрел" в терминах механики XCOM всегда один, а как он там анимируется — дело десятое.
Но претензии к условностям механики пошагового боя меня очень забавляют. Это пошаговый бой, уже дикая условность, которая абсолютно никак не натягивается на реальность. И при этом вас беспокоит отсутствие честной симуляции очередей? Ну-ну.
Это как придти жаловаться шахматистам, что ладья как-то нереалистично ходит.
патчи таки были, но 100% — это обратный идиотизм.
разговор про 95%, хватит пытаться уводить в сторону.
Эм. В XCOM:EU и XCOM2 шансы попадания не ограничены сверху. Там нет потолка в 95%.
Вот стоит группа и стреляет по одному. Все имеют большие шансы попасть, все промахиваются.
Пруфы? Давайте начнем хотя бы с 4 5% промахов в ряд — это целых 0.000625% шансов, вполне вероятно, что среди всех сыграных партиий в XCOM за всё время такая ситуация возникала, и кто-то выложил её в интернет, а то и может быть даже и не одну. Если же у вас "всё реализовано неправильно", то таких ситуаций должно быть по-вашему — сколько? Тысячи? Десятки тысяч? Короче, выложить сюда хотя бы пару дюжин не должно составить для вас никакого труда.
О, люблю предметный разговор!
Итак:
Видео №1: нубы или около того (средняя базовая меткость: 65%) стреляют в овервотче (x0.7 от финального шанса попасть) по солдату в half-cover (-20%, многие думают, что в overwatch бонусы от укрытия не применяются, но это не так) в упор из винтовок (+19-20%). Это если конечно там модами что-нибудь из этого не переделано.
Итого у каждого шанс попасть — около 45%. Три раза подряд промахнуться — ~16%.
Видео №2:
Ну да, это full cover. В ванильке нет никаких бонусов за "частичный" фланг. Плюс, судя по времени видео, это совсем ванилька, с её приятной механикой критов (это когда при, допустим 15% шансах попасть и 15% крита любое попадание становилось критом). Потом эту механику переделали в WoTC, кстати.
Видео №3:
В XCOM:EU отображаемые шансы попадания псионикой всегда жили своей жизнью. Это баг, который долго и мучительно устраняли из Long War, я c этой историей лично сталкивался. А в ванильке его никто не чинил, по-моему.
Видео №4:
Ну и что такого? Это вероятности в районе 0.1% (а не 0.000625%, как я вам предложил найти), с учётом объемов сыграных игр таких видосиков легко могут быть сотни.
Видео №5:
Ничего необычного, классическая нубоошибка на гейткрашере — сидеть в half-cover, которое дает всего лишь -20% и надеяться на овервотч, который х0.7 к финальному шансу попадания и в силу этого даже с крыши работает так себе. И да, я нахожу панику в ванилле XCOM2 реализованной невероятно тупо, это про дальнейшее.
Ну а уж мемасики «xcom симулятор промахов»
Люди в среднем не могут в статистику, ага.
Было бы наоборот удивительно, если б при популярности XCOM таких мемасиков бы не было.
И да, я тоже нахожу симуляцию тактического боя в джаге — гораздо более цельной и приятной, чем в XCOM:EU и особенно в XCOM2.
(AI там нисколько не лучше, но именно с точки зрения отсутствия странных правил и формул всё намного лучше)
Просто это всё ортогонально честности ГПСЧ. Рандом абсолютно честный и там и здесь. Вернее, в XCOM он нечестен (на легких сложностях) как максимум в пользу игрока, и никогда наоборот.
При этом так же есть ксенонавты, где такого убожества нет.
Так что это не «люди не запоминают», это просто отмазки, что раз типа теория вероятности позволяет делать серии из промахов при 90%, то это нормально такие серии получать постоянно. Неа, тервер говорит, что если у вас 99 постоянных решек, то скорей всего проблема в монете.
Нет, тервер говорит что монета не имеет памяти, а 90% попадание означает что каждый 10й будет промах. Но если люди попадали с 90% вероятность 100 раз подряд а 101-110 промахивались — они побегут доказывать что игра сломана и подставляет их чтобы они не могли выиграть. Хотя зачем разработчикам это делать — непонятно. Видимо чтобы всех побесить побольше
вероятность серии из нескольких промахов подряд подсчитайте при 95%? а теперь вероятность такую серию получать периодически? Ну, когда у вас отряд из 5-8 человек выстрелили и при хороших шансах все промахнулись
Она не ноль — вот и все.
Тем, что у них AI врагов отсутствует как класс. В JA2
Для этого можно было бы ограничить абсолютную точность для людей в 70% например а не врать что она 95.
Пока что все "пруфы" что я видел — от непонимания теорвера. У людей если монетка 10 раз орлом падает — это невозможно и монетка кривая. Все же знают забавную задачку на подбросить монетку и потом записать результаты бросков на бумажку — хороший профессор теорвера всегда знает какой студент правда бросал, а какой просто от балды написал "типа случайные броски".
При заточке предмет ломается. Так что когда 10 раз подряд фейлится 75% шанс — ломается 10 разных (одного типа) предметов.
Интересно было бы почитать про рандом из мира CS. Такое ощущение, что там коэффициент удачливости устанавливался на запуске игры, потому что было проще перезапустить CS, чем мучиться с не попадающими никуда пулями))
Это да, но мне сложно иначе объяснить, что я проигрываю раунд за раундом — перезапускаю CS и начинаю выигрывать так же стабильно. Возможно, какой-то сетевой лаг меняется, но больше похоже, что именно "удачливость" меняется.
Где-то слышал/читал, что опционы получает небольшая часть сотрудников ~17%, возможно самые выдающиеся, например здесь https://www.vedomosti.ru/technology/articles/2015/04/02/yandeks-predlagaet-sotrudnikam-otvyazat-optsioni-ot-kapitalizatsii-kompanii
Или есть другая инфа?
И что, этот один будет весь код в компании ревьювить и искать, где разработчик не заметил алгоритмическую задачу?
Если же этих алгоритмистов нанимать несколько, то дешевле всех остальных уволить и пусть алгоритм-мены все сами и пишут.
Ну "алгоритмическая" задача ничем особо не отличается от обычной! Вот надо вам, допустим, найти одинаковые элементы в двух наборах данных. И тут человек не натасканный на эти задачки с интервью вполне может использовать 2 списка и проверять на вхождение через стандартную библиотечную операцию, получая O(n^2). Возникнет ли у него тут позыв послать эту часть алгоритм-мену? Казалось бы все тупо. Надо взять элементы из первого набора, которые есть во втором. Так и сделано.
Ну хорошо, допустим эти звоночки происходят практически во всех нужных случаях. Тогда неизбежно false positive. Все равно наличие выделенных алгоритм-менов сильно усложняет работу. Они будут завалены заявками. Имея гугловую поток кандидатов гораздо легче тупо нанимать только алгоритм-менов.
С тем же успехом тогда надо представлять себе карикатурного «алгоритмена», который ни в зуб ногой в архитектуре, и потом надо ещё иметь специально обученного человека на него
И… такой человек как раз есть практически везде. Называется архитектор, technical lead, или еще как-то.
Разность в том, что задачки, "алгоритмические" или нет, постоянно решает любой, кто пишет код. Любой код — это алгоритм. Любые данные — это структура данных. Очень часто тривиальные, да.
Когда надо составить SQL запрос — тут, очевидно, нужен специалист по SQL, можно спросить его. Когда надо придумать, как организовать новый модуль, то очевидно, что это архитектура проекта — надо спросить архитектора.
А когда надо писать код, очевидно, надо спросить алгоритм-мена в команде. s/
Конечно, в идеале все в команде специалисты во всех областях. Но это слишком дорого держать такую команду, да и тогда надо 100500 собеседований проводить и не наберешь столько работников, даже с гугловым потоком кандидатов.
Вообще-то SQL обычно пишут все. И никаких отдельных специалистов по нему нет. В том же Я у меня была секция с вопросами про SQL, когда я устраивался.
Эмм, вы тут поосторожнее с такими заявлениями. Если человек работает с ORM, то лучше бы ему знать во что запрос превратится.
Включая фронтов?
Ну давайте еще до уборщиков дойдем с примерами. Статья вообще про бэкенд и Django. Да и фронтенд сейчас тоже может запросы делать иногда — graphQL и тп.
Если человек работает с ORM, то лучше бы ему знать во что запрос превратится.
Отлично. Я согласен 100% с этим. Но вы мне возразили или согласились?
С тем же Django постоянно приходится залезать внутрь и смотреть как он там это все делает. Каждый запрос надо знать как выполняется, не забывать про транзакции и тп.
Прошу прощения. Конечно, я имел в виду "все бэкендеры". А писать SQL, HQL или Criteria собирать — это уже дело десятое. Один фиг, если тормозить будет, то придётся посмотреть, какой SQL генерируется и какой у него план выполнения.
А потом frontend девелопер генерит себе backend JHipster-ом и захреначивает динамический lazy scrolling (тот который SELECT по rownum) и один юзер с мышкой вешает и backend и базу простым движением руки.
Ситуация в Яндексе, кстати местами именно такое впечатление и производит. Все умеют проходить алгоритмические секции, а практически любое решение переделывают каждые несколько лет, т.к. оказалось, что архитектура достаточно жёсткая, чтобы проще было с нуля переписать. Или под конец моей там работы был случай, когда ради оптимизации в одном из компонентов решили кардинально поменять его АПИ, чем вынудили всех клиентов этого компонента переписывать довольно много кода. И ни у кого ничего не "звякнуло" ведь. Хотя теоретически, если есть сомнения по архитектуре, то можно сходить на специальный "Архитектурный комитет" и там её обсудить. Просто сомнений обычно нет, да и "зачем время тратить?" — лучше потом два раза переделать)
Вот на чем такие утверждения основаны интересно. Типа я вот щас пошел, посидел три месяца на leetcode и вуаля я готовый сеньор-помидор и знания об архитектуре, базам данных
А что, с ним рождаются? Что за уникальный навык такой, которому нельзя научить?
Ну тут есть важный нюанс: «алгоритм-мен» всегда может решить практическую задачу. [...]Разумеется нет.
А вот обратное — уже проблема. Если человек владеет инструментами, но алгоритмы сочинять не умеет [...]
А опыту за пределами алгоритмов откуда взяться?
Если инженеру нужно отсортировать список,
Для решения вашей повседневной задачи не нужны алгоритмы, нужно как раз умение решать повседневные задачи, те поговорить с менеджером, выяснить, что достаточно взять последний звонок клиенту и посмотреть дату следующего прозвона для этого звонка. Какие тут алгоритмы?
те поговорить с менеджером, выяснить
достаточно взять последний звонок клиенту и посмотреть дату следующего прозвона для этого звонка
В смысле, менеджер должен рассказать программисту, как ему данные выбирать?
Да, менеджер расскажет что искать, ибо даже в такой постановке задачи есть два варианта что искать — просто максимальную дату прозвона для каждого клиента или все же дату прозвона у последнего звонка. Эти даты могут отличаться. Те это формулирование начальных и граничных (не у всех звонков может быть дата прозвона) условий. Это как раз умение решать практические задачи, а не алгоритмические.
А после формулирования условий остается написать нужный SQL запрос, что во-первых, тоже не алгоритмическая, а практическая задача, а во-вторых при определенном навыке решения практических задач уже ищется в гугле.
Любой код можно назвать алгоритмом, конечно. Только вот под "алгоритм-меном" подразумеваются совсем другие алгоритмы и люди. И вот "алгорим-мен" может не догадаться, что пришедшую задачу нужно обсудить с постановщиком, а так же с тем, кто пользоваться будет. Ему вообще прикольнее задачки на сайтах решать, а не с менеджерами общаться. А практик сделать может не оптимально, зато формочку удобную нарисовать в итоге и больше профита компании доставить.
не буду лезть в ваш спор про то, что лучше, лишь уточню, что на собеседовании помимо правильного решения смотрят на то, какие вопросы задаёт кандидат. Решение может быть неидеальным и иногда даже не до конца правильным, но если кандидат задаёт толковые вопросы по граничным условиям и т.д. — это идёт ему в плюс и может помочь пройти на след этап
Действительно. Нафига нужны архитекторы, нафига нужен опыт? Берем студента, дрочим его пару месяцев на сортировку список и отправляем какую-нибудь распределенную систему писать, со сложной, меняющейся бизнес-логикой и большой нагрузкой. Главное, что он деревья вращать умеет, а остальное на SO найдет.А опыту за пределами алгоритмов откуда взяться?Хм. На SO, например. Какой там опыт нужен?
Назовите задачку не на алгоритмы, которую нельзя взять и нагуглить.Хорошая шутка, но я тоже так умею. Назовите задачку на алгоритмы, которую нельзя взять и нагуглить.
Я же прям в моём посте указал пример совершенно обыденной повседневной задачи, решения которой нет в справочнике объемов зелёных резиновых мячей, и на которой запнулся реальный чувак, который не умел писать алгоритмы.Вы стебетесь надо мной сейчас?
Хорошая шутка, но я тоже так умею. Назовите задачку на алгоритмы, которую нельзя взять и нагуглить.
1) Нагугливаем вычисление, где расположится точка [x, y, z] на проекции 120120120 (это вроде бы изометрическая проекция?)
2) Нагугливаем алгоритм Брезенхэма для окружности.
3) ???
4) PROFIT!
И?
Пожалуйста, задачка из моей практики. Сжатие одной картинки JPEG на одном ядре арма занимает 0.08 секунд. Требуется получить поток фреймов минимум 30 fps. Есть несколько ядер. Как будете решать?Начну с изучения бизнес-требований. Именно бизнес, а не технических — чтобы понять какой результат ожидается, а не как его достичь. Продолжу изучением предметной области — раньше как-то не доводилось работать с изображениями и видео. Изучу, какие алгоритмы для сжатия существуют, их характеристики. Найду нужный — использую его. Если не найду — попробую изменить условие задачи, найти компромисс между требованиями и возможностями.
Почему вы вообще противопоставляете алгоритмы реальному программированию? Программирование — оно целиком про алгоритмы, сюрприз. Если вы берете инженера, а не кодо-макаку, у него не возникнет проблемы увидеть необходимость разработки алгоритма.Это главное условие специальной олимпиады — сравнивать вырожденные случаи. На одной стороне суперопытный инженер, который при этом не написал самостоятельно ни одного алгоритма сортировки, на другой — суперопытный олимпиадник, который годами только сортировку и пишет, ни на что более не отвлекаясь :)
В смысле, нельзя распараллелить? Как раз поток jpeg параллелится элементарно: один кадр — один поток.
Учитывая указанные ранее ограничения, конечно:
Сжатие одной картинки JPEG на одном ядре арма занимает 0.08 секунд
с задержкой не более 200ms и максимальным fps
Но, если вам, по каким-то пропущенным мною ограничениям, это решение не подходит, то сжатие jpeg все-равно можно параллелить: косинусные преобразования, квантование и RLE происходят в блоках независимо. Потом уж и не помню, хаффман применяется ко всем блокам сразу или независимо. Но в любом случае, можно после одной непараллельной части для построения таблицы хаффмана, кодировать все параллельно.
Сжатие одной картинки JPEG на одном ядре арма занимает 0.08 секунд. Требуется получить поток фреймов минимум 30 fps. Есть несколько ядер. Как будете решать?
Выкинуть армы, оставить один для управления.
Сверху напаять плисину (плюс покупная библа) или дсп-шку.
Профитттт! :)
«Алгоритм-мен» никогда не сможет решить практическую задачу
И чем эта практическая задача принципиально отличается от алгоритмической? Типа горе от ума? Отсортировать списки он сможет, а сложить 2 числа — уже нет, слишком просто?
А если базы данных c SQL не используется? В гуглах и яндексах всякие свои распределенные системы хранения со своими интерфейсами.
Как человеку помогут знания алгоритмов в написании эффективного запроса
Вы всё с ног на голову перевернули. Человек умеющий оптимизировать запросы
тем более если он вообще о субд ничего не знает.
… является человеком, который в той или иной мере изучал алгоритмы. Ну нельзя хорошо уметь оптимизировать запросы, не имея бэкграунда. СУБД — это как раз та редкая область в ИТ, которая буквально напичкана алгоритмикой.
Ну очевидно же, что если мы берём человека, который ничего о СУБД не знает, то наверное не на должность DBA или DB Performance Engineer? ;)
100 раз "да". Ситуация абсолютно уникальная — одна хорошо прорисованная "ментальная модель базы данных" (ну там парсер, кэш запросов, оптимизатор, эвристики, память, буфер сортировки, redo, диск, ...) превращает способного слушать литкодера в достаточно полезного специалиста по отладке запросов СУБД. А гуглить — просто умрешь, сумасшедшее количество деталей и ручек/кнопок (особенно Oracle какой-нибудь).
понять, почему он неэффективно работает
Зная алгоритмы, по крайней мере, отдаешь себе отчёт, чем там занимается СУБД, выполняя твой запрос, а не воспринимаешь её как чёрный ящик.
Нечеткостью критериев.
Я вам в другой ветке писал про различия между "смогут" и "сделают" — вот лично наблюдаемый случай у меня был как раз такой: х2 времени на разработку и очень сложно поддерживаемый код от двух олимпиадников-снежинок там, где вместо всех примененных наворотов можно было взять чужую либу (работающую медленнее, чего уж там, только это не играло никакой роли).
Могли они сами взять чужую либу? Да конечно же могли. Взяли? Нет, не взяли. Лишние пара недель разработки (и потом еще пара недель на то, чтоб после них подтереть) — это та самая нерешенная практическая задача.
"Взять либу" — это вы только до предпоследнего уровня дошли. На последнем смотришь сколько у этой либы активных авторов, какая лицензия, как быстро они баги закрывают и на что живут при этом, зачем им эта либа вообще. Потом читаешь код, чтобы убедиться, что и сам бы также написал. В общем если надо написать 20 строк я бы не стал тащить либу, слишком много надо сделать, чтобы притащить ее правильно.
«Алгоритм-мен» никогда не сможет решить практическую задачу. Потому что он наловчился только списки сортировать. А опыту за пределами алгоритмов откуда взяться?Оттуда же, откуда и у тех, кто ни в алгоритмы, ни в сложность, очевидно. Только у него будут дополнительно важные знания и навыки.
ттуда же, откуда и у тех, кто ни в алгоритмы, ни в сложность, очевидно. Только у него будут дополнительно важные знания и навыки.Угу. А еще он на скрипке играть умеет — это тоже очевидно.
Что более вероятно: (а) Вася хорошо умеет в алгоритмы или (б) Вася хорошо умеет и в алгоритмы, и в архитектуру?Если Вася успешно потратил при изучении алгоритмов мозговых усилий кратно больше ленивого Пети, то статистически и в любой другой области, в которой он профессионально позиционируется, очевидно, будет разбираться не хуже Пети. Потому что может укладывать в голове сложные объекты и действия над ними, а Петя — ну так, со скрипом. И потому что Вася умеет упорно добираться до недр изучаемого предмета, а Петя — ну как уж получилось.
статистически и в любой другой области, в которой он профессионально позиционируется, очевидно, будет разбираться не хуже Пети.
Ни откуда это не следует, это вы придумали двух каких-то персонажей.Вы же точно тред сверху прочли?
Я тоже могу придумать Григория, который как прилежный зубрилка задрочил все алгоритмы с хакерранка, но больше ничего не умеет, и слишком задрот чтобы понять что он должен что-то еще уметьМожете придумать, ну пусть будет, почему бы нет. И, внезапно, раз Григорий ничего не умеет, то у него и не получится позиционировать себя в какой-то востребованной области. Тем более так, чтобы это было не замечено в начале первой же беседы. Еще раз подчеркну: если ваш Григорий ничего не умеет, то и проблемы его отсечения не существует. А если умеет как надо, то это не ваш Григорий, который
как прилежный зубрилка задрочил все алгоритмы с хакерранка, но больше ничего не умеет, и слишком задрот чтобы понять что он должен что-то еще уметь
Вот алгоритмист так же, считает что у него крутой «мыслительный аппарат», а на деле он дальше алгоритмов ничего не видит.Дальше алгоритмов он видит не хуже остальных. А так как сразу на автомате прикидывает сложность работы, то лучше остальных. В сложных случаях — намного лучше. Да что там в сложных — вон по тому, как ворочается эта страничка (вы же заметили?), видно, что хабр далеко не алгоритмисты писали.
Факт в том, что в «оперативной памяти» хранятся наиболее часто используемые знания и навыкиЭто не факт, это ваше допущение, особенно в части навыков. На самом деле строго наоборот: чем более мыслительный аппарат разносторонен и тренирован (ага), тем легче и успешней даются прочие действия в смежных областях.
Чем реже и меньше человек что-то использует, тем с большей вероятностью он это забудетВот только нет ни одной причины, по которой умеющие в алгоритмическое мышление вдруг в повседневной работе что-то использовали реже остальных. Вы тоже фантазируете про шарообразных алгоритмистов в вакууме, а они точно так же работают над обычными задачами, используя те же технологии, что и неспособные в алгоритмику. Только с лучшим результатом в силу более развитых способностей видеть сложность целого.
А кто может знать алгоритмы лучше других? Правильно, тот, кто совсем недавно закончил их изучать.Алгоритмы нужно не «знать и помнить наизусть», а помнить в целом, какие они есть, а главное — моментально оценивать сложность разных подходов, когда приходит время выбора. Да, архитектуры это тоже касается, если вообще не в первую очередь.
К примеру, вместо того, чтобы сравнивать скорость разных алгоритмов сортировки списков, он сравнивает разные способы организации и получения данных в какой-нибудь базе, типа постгреса.Ох… Вы знаете, я вообще-то sql'щик, и мне особенно больно видеть, какие способы организации и получения данных в какой-нибудь базе изобретают неумеющие в базовую алгоритмику/сложность. И чаще всего быстро и прозрачно пофиксить это невозможно, это фиксится через кровь и развороченные кишки. Ну просто написано вообще без мысли «а как это потом будет работать». Даже не «и так сойдет (с)», а просто люди не видят последствий, не привыкли автоматом просчитывать пути и алгоритмы наперед. Пока данных немного, оно без проблем работает. А когда/если проект вырастает, начинаются веселые старты с поминанием незлым тихим словом непонимающих, что алгоритмы и сложности — они на самом деле везде, просто они не обучены сразу видеть это на каждом шагу.
Решить может и может, но заточеность на решение сложных алгоритмических задач часто мешает ему сделать простое и поддерживаемое решение, в итоге буде плохокод
Если человек владеет инструментами, но алгоритмы сочинять не умеет, то он застрянет на вполне себе практических задачах вида «отобразить оператору клиентов, которых надо сегодня прозвонить, это клиенты, у которых есть звонки с указанной датой следующего прозвона меньше либо равной текущей дате, и нет звонков с датой следующего прозвона больше текущей даты»
«алгоритм-мен» всегда может решить практическую задачу.
Ну вот поэтому на интервью просят решать задачики, а не проводят теоретический экзамен. Чтобы отсеять в том числе таких профессоров.
Что?
Сначала вы пишите, что есть профессора, которые могут натеоретизировать заумного computer science, но не могут писать код. Я вам говорю, ну вот же, на интервью просят писать код. Не заумный — задачки простые! И тут вы каким-то непостижимым мне образом делаете вывод, что если заставлять людей писать код решающий эти простые задачки, то его пройдут исключительно профессора "не могущие написать код"? Раскройте свою логику по шагам — она мне вообще не понятна.
Задачки в посте и прочие простые задачки на интервью — они и есть задачки.
Эти задачки (или нечто очень похожее на них) постоянно возникают во время работы. Вам так сложно представить, что в Яндексе где-то программисту придется выбрать общие элементы из двух списков?
Отсюда люди, умеющие решать пазлы, но не умеющие решать практических задач, зачастую даже не могущие понять как подходить к решению практических задач.
Не могу себе это представить. Как раз алгоритмическое мышление и умение решать пазлы тренеруют построение математической модели задачи. Это очень помогает решать практические задачи.
Потому что в реальности задачи стоят не в виде условий от экзаменатора, а в виде ситуации в реальном мире
Есть еще отдельная секция про проектирование систем — вот там как раз проверяется умение решать большую, нечеткую задачу. Там не просят писать код (то, что человек код писать умеет видно по алгоритмическим секциям). Но там как раз смотрят, как человек разбивает задачу на подзадачи, как выковыривает из интервьювера недостоющую информацию.
Ее не задают на начальные позиции, потому что люди на этих позициях в основном "копают от сюда и до обеда". Им ставят вполне фиксированные задачи.
Я ищу программиста которы умеет на Java и выбивает 7+ из 10 (0-нуб, 10-бог, условно). Задаю вопрос по почте «пожалуйста прочитайте 17.4 спецификации языка, и подумайте, зачем оно». Ни один из кандидатов (многие с 20+ годами опыта) нормально не ответил, либо не могут прочитать, либо не могут нагуглить разжеванный вариант, либо начинают хамить прямо сразу и говорить, что это не надо. Так что да, профессия загибается.
Я его по-английски задаю, и всем немного по-разному, чтобы рекрутер не понял паттерн, но все с “can you please, if you have time, ...”, плюс — это тоже тест, насколько легко вас втянуть в конфликт.
А зачем, собственно, вы втягиваете программистов в конфликт?
Я спрашивал (в смысле что делать если у вас с коллегой разные предпочтения). На собеседовании все либо говорят, что они взрослые люди, что можно договориться, что надо форматирование автоматическое делать в pre-commit делать, либо (когда совсем без опыта и не понимают что будет с историей в гите) — что это пофиг и пусть каждый как хочет так и кодит. А после найма — большинство тихонько делают по-своему и меняют форматирование в каждом коммите, пока "начальник" не скажет как надо.
Я понимаю всё это. Я просто не могу придумать как делать лучше. Когда кандидат мне пишет “я 9 из 10 в Linux” честно готовлюсь сам ко встрече с мессией, как дурак трачу время на поиск интересных вопросов и тем, а потом чел не знает что такое системный вызов, и, грубо говоря, на какой порт приходит пинг.
и, грубо говоря, на какой порт приходит пинг.
На какой?
грубо говоря, на какой порт приходит пинг.
Я понимаю всё это. Я просто не могу придумать как делать лучше.
как дурак трачу время на поиск интересных вопросов и тем
Если бы я нанимал сборщика мебели, я бы еще и спросил с каким моментом надо закручивать в фанеру и с каким в ДСП и у кого их лучше покупать и какой отверткой крутить.
Те кто 9 из 10 в Linux, обычно знают с ходу и про пинг и про то, какую для пинга лучше брать сетевуху и у кого покупать, но редко клюют на вакансию "Software Engineer".
Да, вы правы, мой мастер цеха бы их научил с каким моментом крутить и какой отверткой. Нафиг их спрашивать. И проверить просто — дать один шкаф собрать.
В принципе так с контрактниками и происходит, и все довольны обычно. И контрактники сами еще приносят шкаф показать, который они делали, и иногда даже можно владельца шкафа спросить как он там.
Те кто 9 из 10 в Linux, обычно знают с ходу и про пинг и про то, какую для пинга лучше брать сетевуху и у кого покупать
Ту на которой написано "ping ready edition"?
Те кто 9 из 10 в Linux, обычно знают с ходу и про пинг и про то, какую для пинга лучше брать сетевуху и у кого покупатьWTF. Или это такой тонкий сарказм? :D
Я каждый день ковыряюсь в пачке микротиков, хобби такое, но вот сходу не вспомнил. Во первых я не в контексте, во вторых вы всегда можете загуглить любыми словами, даже не зная «icmp».
Без знания ICMP вам врядли светит профессия сетевого инженера например, т.к. поговорить как два профессионала с нанимателем не получится.
Судя по всему, в Яндексе у вас есть такой шанс. Заодно алгоритмы подтянете.
Без знания ICMP вам врядли светит профессия сетевого инженера например
Я ищу программиста которы умеет на Java и выбивает 7+ из 10 (0-нуб, 10-бог, условно).
Чел будет просить значительно больше денег, и нам было бы здорово такого заиметь и платить больше, мы сами себя сисадминим. Он же сам пишет что знает.
ЗЫЫ — про пинг сетевой инженер знает и на вопрос про порт проржется мне прямо в глаза. Зачем знать про порт — ну чтобы знать насколько хорошо можно пингом оттестировать производительность TCP.
Простой пример, 5ый знак после запятой числа пи назовете сходу?назову — я принят? :D Не знаю почему, но еще со школы врезалось — 3,14 15 926 53 58 (написал по памяти)
Видимо да, наименее затратный подход для обоих сторон. Или вообще только через знакомых искать (но это будет не совсем честно).
А ссылку даете?
Кстати, один из кандидатов был русский чел из гугла. Элегантно отвертелся от низкоуровневых деталей 17.4, затроллил offline coding task на игре слов, сделав совсем не то, что просили но настолько круто, что всем очень понравилось — совершенно другая лига, футболист с мячом, а не бурлак на Волге, условно говоря. Ощущение, что просто приходил убедиться, что в гуле ОК, несмотря на иногда скучную работу.
Не понимаю где они берут специалистов с таким подходом?
Вы уверены? Я слышал ровно наоборот от коллег, которые пробовали кого-то рекомендовать.
Наоборот, это что они (порекомендованные) сначала долго ждут, когда с ними свяжутся, и не всегда даже дожидаются, а потом их отправляют на тот же стандартный набор секций.
Собственно, это даже логично, учитывая, что рекомендовавшему за нанятого по рекомендации дают приличный бонус.
А то, что стараются нанимать по рекомендации, вовсе не противоречит необходимости решать при этом задачки.
Это у них, видимо, так, потому что наемом занимаются люди, которые никакого отношения к тому проекту не имеют. Поэтому у них подход чисто формальный: озадачить кандидата задачкой и поставить оценку, которая зависит от того, насколько его решение соответсвует тому, что они ожидают. Им так проще.
А вот насколько способность быстро решать логические/алгоритмические задачи на интервью кореллирует с практикой разработки программного обеспечения, это еще вопрос. По мне так не сильно.
Безусловно кореллирует, но не пропорционально тем масштабам, которые уделяют этому они. Причем у них вообще вопросы зачастую сильно оторванные от прикладных областей.
Очень хотелось бы прочитать историю человека, который прошел все этапы в Яндекс (или другую крупную компанию), о том, чем он занимается ежедневно. Доступным языком.
Расскажу схожую историю про одного моего знакомого))) Он смог попасть в госкомпанию (назовем это так) на три буквы первая Ф. Отбирался год примерно, куча этапов, сложнее только у космонавта отбор… Потом ходил гордый, на вопросы чем занимаешься не отвечал — тайна. В итоге через общих знакомых узнал, что он 10 лет на калитке просидел сутки-трое. Нет, тоже важная часть работы, но зачем тайну делать из этого, видимо разочарован был.
Тем же, что и везде. Работал в Маркете бэкендером на Java. Когда устраивался, описанное выше ещё задачками на сообразительность разбавляли. Писал всякие API, "перекладывал JSON'ы", добавлял в БД таблички и писал к ним запросы, иногда писал и фронт (с минимальным опытом в этом, но на внутренние проекты фронтов часто не дают), иногда что-то ковырял в местном map-reduce, настраивал местный недо-кубер, настраивал всякие графики (rps, тайминг, ошибки и пр.) и мониторинги по ним (тоже всё в основном самописное: "на наших масштабах готовые решения не тянут" ©), чинил баги и разбирался со всякими неожиданными (и иногда мистическими) проблемами с производительностью или неожиданными багами, когда при отключении одного ДЦ ложится вся, казалось бы устойчивая к этому, конструкция.
По теме могу только сказать, что писать квадратичные алгоритмы вместо линейных — это таки большое зло. И стреляет потом очень больно, и разбираться и чинить придётся в дикой спешке и, возможно, в нерабочее время, ибо прод горит, а деньги улетают в трубу тоннами в секунду.
Что конечно никак не обосновывает необходимость задротства на литкоде
Еще большее зло — не писать бенчмарки, или не уметь их писать правильно/реалистично.
Таки вот тут выше был пример с "найти общие элементы в двух списках". Вот вы как предпочитаете: написать "очевидный" для тех, кто не в курсе про асимптотическую сложность, квадратичный алгоритм, а потом ловить проблему бенчмарком, или таки воспользоваться библиотечной функцией для пересечения множеств и больше не вспоминать об этом никогда?
Нагрузочное тестирование конечно никто не отменял, но его делают далеко не так часто, а ещё реже добиваются высокого покрытия по коду, а подобная взрывная штука может спрятаться где угодно.
Ну и писать бенчмарки на любой кусочек кода — тоже странная идея. Они всё-таки обычно применяются, когда уже понятно по другим признакам, что конкретный кусочек кода работает слишком медленно, и не видно очевидных опять же проблем с асимптотикой, поэтому придётся писать что-то сложное, которое надо и протестировать досконально, и производительность с другими вариантами сравнить.
Ещё я заметил, что люди пишущие квадратичные алгоритмы абсолютно не парятся по поводу рантайма приложения. Напихать в контейнер 5гб зависимостей — легко! А что, на ноуте же запускается? Потом эти же люди решили в результат map-reduce для простоты добавить все входные данные. А что? Так же проще дебажить? Подумаешь, на мастер приезжает 1тб мусора… проще ж засыпать железом.
Спасибо, коллега. Занимаюсь примерно тем же.
Могу поделится опытом из гугла. Да, 99% времени — рутина. Как шутят в гугле — вместо алгоритмов перекладываешь данные из одного протобуфа в другой.
Но алгоритмические задачи раз в месяц, да и случаются. И тут я благодарен, что я алгоритмы умею.
Сейчас на интервью спрашиваю именно ту задачу, которую сам решал и комитил в прод (слегка упрощенную, конечно, чтобы в интервью влезло).
И считаю что такие алгоритмические интервью — полезны. Даже идиота можно научить перекладывать данные из одного протобуфа в другой. А вот с редкими, но важными алгоритмическими задачами чувак с кучей историй и с которым можно по душам поговорить про очередной фреймворк далеко не всегда справится. Более того, такой условный разработчик может даже и не поймет, что тут алгоритмическая задача. Надо как-то данные перемолотить, ну и молотим. А то, что тут можно динамическим программированием вместо 2^n получить n^3 и при этом решение в 3 раза короче по коду и сильно проще для чтения — даже мысль не придет.
Поэтому, если у вас достаточно кандидатов, то имеет смысл отсеевать по самому сложному, хоть и редко нужному навыку.
Плюс, единственный достоверный способ реально понять, умеет ли кандидат писать код — это заставить его писать код.
Самый сложный и постоянно нужный навык — задавать себе вопросы типа:
И еще «как мне не стоять на проходе когда я ничем не могу помочь», и как понять когда я могу а когда нет. Фрактальный скилл просто.
Чем я сейчас занимаюсь? Какая от этого польза? Что мы вообще делаем и для кого?
Чревато. Можно прийти к выводам "ненужное, неиспользуемое, корявое и неудобное, а ещё хлипкое".
2^n получить n^3 и при этом решение в 3 раза короче по коду и сильно проще для чтения — даже мысль не придет
. А то, что тут можно динамическим программированием вместо 2^n получить n^3 и при этом решение в 3 раза короче по коду и сильно проще для чтения — даже мысль не придет.
А про потребление памяти не забыли? Запросто может быть, что более «медленный» алгоритм более оптимален по памяти, чем более «быстрый» с каким-нибудь бектрекингом, но как только мы сваливаемся в какой-нибудь своп — усе пропало, шеф
Если там n такое, что n^3 заметно по потреблению памяти, то первоначальный алгоритм за 2^n — вообще ни в какие ворота не лезет. Кстати в динамическом программировании часто памяти надо на порядок (или даже 2) меньше, чем времени. И в итоге потребление по памяти может быть таким же, как при переборе.
Ну 2^n может по памяти быть массив на n + счетчик, а n^3 может быть "а давайте создадим массив nnn и будем его обновлять в процессе обхода."
Если n^3 уже хотя бы 100 килобайт, то 2^n — это 70 триллионов. Наивный алгоритм тут работает десятки часов, когда как этот ужасно прожорливый до памяти алгоритм — миллисекунды.
Повторю свой тезис: Если увеличенное потребление памяти нельзя тупо проигнорировать, то изначальный алгоритм работал непозволительно долго.
Это как упрекать пожарника, что вы мне компьютер залили — он сломался. Когда как вокруг дом горел и люди умирали. Несоизмеримо меньшее зло.
А то, что тут можно динамическим программированием вместо 2^n получить n^3 и при этом решение в 3 раза короче по кодуи сильно проще для чтения— даже мысль не придет.
Что вы понимаете под "постзнанием" тут? Базовые понятия из курса про алгоритмы (ДП идет оттуда). Тут даже никакой хитрой математики нет.
Если это продолжать, то тогда и всякие хитрые конструкции языка использовать не надо. switch-case, оно короче, проще и понятнее, когда представляешь, как оно работает. А вот if-else-if-else-if… это и без "постзнания" понятно. Так что ли?
А вот прям так с ходу, чтобы более быстрый алгоритм был ещё и более коротким и понятным (без постзнания)
Из моей практики. 100+ строк рекурсивной функции полного перебора (+ еще 20 комментариев) заменяется на 20 строк ДП уже с комментариями. Там всего 2 вложенных цикла и тривиальная формула внутри. Комментарии четко говорят, что тут ДП, что вот такие параметры, вот пересчет. Даже не знакомый с ДП человек сможет въехать.
Вот прям хотелось бы пример!
Я эту задачу сейчас сам на интервью использую. Поэтому не буду приводить.
Но по записи быстрого решения понятно что мы делаем на уровне бизнес логики — только в случае, если человек уже разобрался с этой задачей
Это лечится одним комментарием вроде "cur_max_sum — максимальная сумма подпоследовательности, заканчивающийся в данном элементе." Если после этого человек не может понять эту логику, то этому человеку, наверно, не место в яндексе.
Сейчас на интервью спрашиваю именно ту задачу, которую сам решал и комитил в прод (слегка упрощенную, конечно, чтобы в интервью влезло).
Интересно бы глянуть условие задачи.
Поскольку я ее все еще задаю, не хочу ее в интернет сливать.
Вот немного похожая задача: leetcode
Спасибо за ссылку, интересный паззл.
Вспомнилась другая забавная задачка, может Вы зацените. Дан массив положительных чисел, и надо собрать из них максимально возможную сумму, но при этом нельзя использовать соседние элементы (т.е. если в сумму взяли a[i], то не берем a[i-1] и a[i+1]). Вернуть значение суммы. Интересна тем, что внезапно очень компактно решается за O(N) времени и O(1) памяти.
Простейшее же ДП: F(i) — максимальная сумма, если брать i-тое число и какие-то до него (соблюдая правила).
Пресчет очевиден. Если мы берем i-ое число, то предыдущее может быть i-2 или раньше.
F(i) = max_{j<i-1}(F(j))+a[i]
Такая реализация O(N^2) по времени, но легко реализуется и за линию, если еще ввести
G(i) = max_{j<i}(F(j)).
Тогда пересчет:
F(i) = G(i-1) + a[i]
G(i) = max(G(i-1), F(i-1))Также, можно сделать O(1) по памяти, если хранить только последние значения F и G, и пересчитывать на месте по формулам выше.
Ответ: max(G(N),F(N)). База: F(0) = a[0], G(0) = 0.
4 часа.
Да, 4 часа это много когда вы и не собирались устраиваться на работу, а пришли поразвлекаться.
Реальная работа это ...
Найм на работу — это ещё не работа. Во-первых — время не оплачивается. "Во-вторых" после этого уже не требуется.
на найм дефицитных и востребованных кадров
Давайте их пожалеем?
Соответственно, не понятно в чём тут экономия времени для кандидата, если его будут больше собеседовать.
Ну, в том то и дело, что то было до ковида. Если компания оплатит перелёт и проживание, то можно и 8 часов лично собеседоваться, тут нормально всё.
они ничего не тратят кроме денег на зарплату интервьюеру.
пришли поразвлекаться
А ничего что "они первые начали"? Не автор к ним просился, а они его всяко зазывали. Значит — в данном случае им нужнее! Поэтому:
На сколько я понимаю на западе даже большие компании начали отказываться от такого подхода. Например в Амазоне уже давно не только алгоритмы и задачки а сильно лучше
Но почему на кодирование 4 собеседования?! Они были не уверены после первого? Вроде бы и кодит, но что-то тут не то, давайте ещё 3 раза повторим.
ЕМНИП, чтобы уменьшить влияние мнения одного человека. Ок, один не получил то что хотел, но трое других были в восторге.
Обычно в таком случае все четверо приходят вместе. И спрашивают из широкого спектра, а не одни и те же задачки.
Я после 11 класса, помнится, и олимпиадные задачки решал, и сортировки все помнил… Но могли бы меня с теми знаниями взять сейчас на сеньора? Да упаси Нортон!
Сейчас уже все эти сортировки забыл за 20 лет, но знаю где лучше применить RabbitMQ а где Kafka, на каком сервере расположить сервисы и как их связать. А сложность сортировки я нагуглю быстро, если надо.
RabbitMQ
Я могу ошибаться, но вроде бы нельзя шарить задачи, которые были на интервью?
В гугле, во всяком случае, было так.
Я могу ошибаться, но вроде бы нельзя шарить задачи, которые были на интервью?
Под NDA нельзя поставить что-то без полноценного заведения оной NDA, с подписями, контролем доступа и всем таким, причём строго через "И".
Поэтому всякие подписи в письмах от рекрутеров "вот это письмо, которое пришло к вам без всяких подписанных бумаг, шарить нельзя" — фикция. Во всяком случае в России.
Устно договориться "давайте Вы не будете делиться?" — это только на уровне устной договорённости. То есть можно, но не обязательно.
но вроде бы нельзя шарить задачи, которые были на интервью?
А вы сделайте им такое собеседование, к которому нельзя заранее подготовиться :)
Фреймворки - это "мета-вопрос", проясняющий несколько аспектов сразу:
- Случилось ли кандидату действительно работать с тем, что у него/нее в CV написано - или это копипаста откуда-то
- Понимает ли он/она преимущества и проблемы использования библиотек/фреймворков
- Понимает ли он/она "внутреннюю кухню" фреймворка и его API (я люблю .NET-чиков спрашивать, как Task выполняется - почти никто не знает)
- Как кандидат обьясняет свой выбор и реагирует на вопросы
Разумеется, я никогда в жизни не сталкивался и с половиной предлагаемого (например Spring или React) - но если человек действительно на этом писал или хотя бы знает принципы, это сразу видно.
Смотря что понимать под «нельзя».
Неэтично — да, конечно. А в принципе то как запретишь? Даже если в Яндексе установлен режим коммерческой тайны и они как-то умудрились притянуть к нему эти задачки, кандидат — не сотрудник, как ему доступ к коммерческой тайне оформлять?
Шарить задачки, которых нет в интернете — подло с точки зрения компании, но яндекс в этот круг компаний не входит, тк взял все задачки с литкода и ничего нового не придумал.
Ну стиль у меня такой ¯_(ツ)_/¯ Да, всё субъективно — рассказал, как это выглядело с моей стороны и что я чувствовал.
Какой смысл в сухом изложении, если большинство пойдет и получит такой же эмоциональный фон в подобной ситуации — это же не вопиющий случай, а политика компании. Наверно будь это не яндекс, было бы куча оговорок — "я не знаю как у других", "может зависит от того кто собеседует" и тд. и тогда сухое изложение может быть было бы уместно, а бурю эмоций можно было бы скрыть под спойлер
Да, и стандартная библиотека олимпиадникам не нравится, они ее сразу переписывают сами :)
на самом деле алгоритмы в реальной работе нужны не очень часто
"На самом деле огнетушитель в машине нужен не очень часто". Зачем их вообще требовать и проверять на техосмотрах?
Дело в том, что олимпиадники, в подавляющем большинстве случаев, смогут использовать готовые библиотеки, перекладывать данные отсюда туда и всякую другую рутину. Плохой стиль кода у олимпиадников лечится всего за пару недель, если в компании есть код-ревью. А вот не умеющий в алгоритмы программист даже не заметит, что вот тут эта самая алгоритмическая задача возникла. И впендюрит n^2 вместо n log n. Потом внезапно прод станет тормозить, когда нагрузка возрастет всего-то в 10 раз. И придется экстренно искать это место и переписывать.
Да-да, олимпиадник. Он как раз вместо того чтобы взять готовое решение будет сам месяц писать велосипед. Потому что его натаскивали именно на задачи "война, stdlib убит, напиши свое".
У нас в гугле такого не вижу. Да, есть всякие внутренние фреймворки и библиотеки, которые имеют распространенные аналоги, но практически все они в компании сделаны раньше, чем эти распространенные появились. Есть собственная замена почти всему из stdlib в репозитории, поддерживаемая специальными командами (и работает сильно быстрее почти всегда). Никто из моей команды каких-то велосипедов не пишет.
Мой коммент:
У нас в гугле...
Вы приводите ссылку на статью о том, что технологии применяемые в гугле не стоит бездумно перенимать, ибо они заточены под реально большие объемы, которых в большинстве других компаний почти точно нет. Что вы хотели этим сказать?
Если вы про контекст этого поста — то он о яндексе. Как конкурент гугла, хоть и на локальном рынке, Яндекс как раз одна из тех немногих компаний, где гугловые технологии тоже нужны. Опять же, я не понимаю, при чем тут ваш коммент.
Ну вообще, интернет большой. Искать по всему интернету — даже с учетом фокуса на рунете у яндекса — охренительный объем данных. Не знаю, сколько у них датацентров, но предполагаю, что далеко не один. Так что яндексу 100% нужны самопальные решения. Потому что если можно соптимизировать std::string на 1% — это огромная в абсолютных цифрах экономия, хоть и ничтожная в относительных.
«олимпиадникам» удавалось ускорить раза так в 3 а там где performance matters это довольно полезный скилл.
Нет. Не обязательно. Взяли вместо O(N^2) сделали O(N log N). Там уже от навороченности алгоритма (константы) и конкретного значения N может получиться что угодно — хоть в 3, хоть в 100 раз быстрее.
Дело в том, что олимпиадники, в подавляющем большинстве случаев, смогут использовать готовые библиотеки, перекладывать данные отсюда туда и всякую другую рутину.
И конечно же это чистое совпадение, что именно компании-средоточия-олимпиадников являются же главными центрами по производству софтверных решений, которые устраняют исключительно фатальные недостатки в самых разнообразных существующих технологиях.
Ну и уже на личном опыте: смогут использовать готовые библиотеки? Да, безусловно смогут. Будут ли использовать готовые библиотеки там, где их можно прекрасно было использовать? Скорее нет, если только не придёт признанный авторитет и не скажет таки использовать.
И конечно же это чистое совпадение, что именно компании-средоточия-олимпиадников являются же главными центрами по производству софтверных решений, которые устраняют исключительно фатальные недостатки в самых разнообразных существующих технологиях.
И еще одно забавное совпадение: большое количество этих "велосипедов" без фатального недостатка появилось раньше этих разнообразных существующих технологий.
Они, в числе прочего, умеют выбирать из готовых решений там где другие не видят особой разницы.
Не наблюдал никакой корреляции. Умеют выбирать — те, кто умеют выбирать (как правило это те люди, которые уже обжигались на плохих выборах, или те, кто были свидетелями таких случаев). Олимпиадники к этому относятся ортогонально.
И конечно же это чистое совпадение что именно компании-средоточия-олимпиадников являются лидерами рынка и «разнообразные существующие технологии» создаются зачастую именно ими.
И стали лидерами они до перехода на "строго олимпиадники" или после?
И пруф на "создано именно олимпиадниками" очень хотелось бы увидеть.
В яндексе всё свое, им нафиг не нужны Ваши знания библиотек, фреймворков и т.п. А еще они большие и хотят сделать наем более объективным. Я видел в других местах ситуации когда лид набирает людией под себя и после его ухода их всех только увольнять, другие с ними работать не хотят.
В общем причины почему так нанимают есть. Но вот платят они мало и потому только студентов олимпиадников и могут нанять..
Вспмонилось как один кандидат спросил "чтО большое?"
к интервью не готовлюсь
Есть теория, что Яндекс понимает кого ищет.
Ищет людей с хорошим знанием алгоритмов и привычкой всюду смотреть на O(?).
Как найдет, дальше всему научит сам.
Мне такой подход не близок, но я не Яндекс.
Про то, что спрашивать про джанго на собеседованиях не нужно, я как раз с Яндексом согласен. Если ты крутой, дадут методичку, выучишь.
А алгоритмы сам Яндекс форсит учить перед собеседованием. Вот как раз по ним и надо давать методичку
Выучить джанго все-таки на порядки проще, чем научится алгоритмическому мышлению и способности решать задачи.
Выучить джанго все-таки на порядки проще, чем научится алгоритмическому мышлению и способности решать задачи.
С этим не поспоришь. Но хватит и пары задач чтобы это выяснить. А вот реальный опыт очень важен.
У меня есть хороший пример — на прошлой работе был коллега, матерый программист, еще TCP-стек для какого-то микроконтроллера реализовывал 30 лет назад, писал на всем что горит… Кинули его и меня на новый проект с Джангой. Дали книжку, которую мы за неделю прочитали и уяснили суть.
Как матерые ООПшники порадовались идее ORM и кинулись в бой. Красиво реализовали все на классах, а потом как пошла нагрузка — поняли что база не совсем любит наш подход и select_related не зря придумали.
В том-то и дело, что Яндексу не нужен опыт. Нужна голова и способность принять условия игры. Несколько раз сказали — выучи, повтори алгоритмы. Если (а) согласишься (б) успешно и быстро подтянешь — то потом, когда тебе скажут разобраться с «Яндекс.Велосипедофреймворк», ты (а) не будешь спорить (б) быстро разберешься.
Система грейдов — чтобы удерживать людей со знанием «Яндекс.Велосипедофреймворк» в компании.
И да, система найма Яндекса устроена так, что сеньоров с рынка они почти не нанимают.
P.S. На всякий случай — я не из Яндекса, инсайдов нет, это мои наблюдения.
но я человек ответственный, поэтому к интервью не готовлюсь. Это кстати я не шуткую, реально: если вы ответственный человек, ты вы, когда предстаёте перед компанией, отвечаете за то, что вы заявляете как ваши умения. Можно выучить типовые вопросы и даже казаться умнее и опытнее, чем есть, но по факту это переобучение на тестовых заданиях/вопросах.
ну тут двоякое, большинство все еще любят упарываться в типовые вопросы, знание ответов на которые никак и ни разу тебе не пригодятся в будущей работе и вообще никогда не пригодятся ни на одной из будущих работ
Мне кажется, вы словили джекпот — вам подсунули все самые популярные в Яндексе задачки на собеседованиях (сам, когда работал в Яндексе, очень любил задачку про симметрию задавать).
При этом, вы их все слили в интернет, так что сейчас все будут бегать кругами и придумывать новые.
Я надеюсь, что что-то поменяется. А вообще leetcode большой. На крайний случай могу накидать 10 аналогичных по классу задач и предоставить Яндексу на безвозмездной основе.
вы их все слили в интернет, так что сейчас все будут бегать кругами и придумывать новые
Ящитаю, это очень хорошо. Человечество от этого только выиграет. Если все так и будут
всегда поступать, со временем сформируется "база знаний" автоматизирующая решение подобных задач, высвобождая время для более полезных вещей. Хотя, конечно, есть некоторая вероятность, что потеря такого фильтра навсегда лишит общество некоего жизненно важного градиента, оставив нас в локальном минимуме эффективности. Но это скорее в предельно длительной перспективе, а на наш век всё-таки — одна выгода.
Автор молодец, я хорошо посмеялся, а я просто возьму и оставлю это здесь
https://blog.ploeh.dk/2021/03/22/the-dispassionate-developer/
По моему многие просто неправильно понимают суть собеседования в яндекс.
Добавьте сюда ещё другой аспект: когда к тебе стоит очередь из желающих пособеседоваться, её надо бы как-то проредить с минимальными затратами для компании, чтобы не тратить время на тех, кто и не собирается становиться сотрудником, но хочет большую честь или там строчку в резюме ну хоть кого-нибудь.
Одного мема «в Яндексе/Гугле/Иксе гоняют по алгоритмам» достаточно, чтобы часть из этой очереди поумерила пыл — и вообще не пришла сразу, а ушла готовиться — не тратя время компании на это.
Всё ещё слишком много времени уходит на собеседования? Добавляем в ротацию домашнее задание и отсеивается ещё часть людей, которые не хотят тратить своё время — и таки образом не будут тратить время компании.
Всё ещё не помогает? Полируем раундом-двумя-тремя онсайт-интервью на четыре часа — часть людей отвалится сразу как только их об это предупредят, а с «выжившими» можно и поговорить.
Абстрактное программирование — это программирование насмерть оторванное от железа
Закусывайте.
Автор, кстати, хорошо показывает откуда берутся статьи «Винда полчаса сортирует значки рабочего стола» и «GTA V зачем-то парсит гигантский json на каждый чих». А что, «сложность алгоритма в реальном программировании нужна целых 0 раз», интерсектом бахнем да и норм :)
Гуглопочта написана на собственных технологиях гугла.
1) Так что же, их собственные офигенные решения не такие уж офигенные?
2) Куда делись все олимпиадники при написании гуглопочты?
Это, конечно, звучит как "сперва добейся"… Но попробуйте сделать гуглпочту более лучше. Я не встречал ни одного другого почтового клиента с таким набором фич, с поддержкой того же количества трафика.
Я не встречал ни одного другого почтового клиента с таким набором фич, с поддержкой того же количества трафика.
Гуглопочта, до того момента, как она стала гуглопочтой на 6.7Мб — была такой же гуглопочтой, но весьма более скромного размера.
А еще до этого она была гуглопочтой без SPA (это то, что сейчас существует как "облегченная версия"), и там с размерами и скоростью загрузки тоже было всё просто наишоколаднейше.
Так что вот "другие клиенты с фичами и траффиком" — это всё та же гуглопочта, просто не то, что сейчас предлагается по умолчанию, а исторические её варианты.
была такой же гуглопочтой, но весьма более скромного размера.
И там не было ни автодополнения, ни отмены отправленных сообщений, ни чата и кучи других функций.
Да ну нет конечно. Тот же hangouts в почте с незапамятных времен, и в прошлой он тоже был. И в новой он, подозреваю — один из самых скромных по размеру компонентов. И вообще в момент радикального утолщения почты там не было никаких прорывных фич добавлено, по крайней мере относящихся непосредственно к почте.
Фичи уже потом пошли. И самое забавное, что размер гуглопочты они особо не увеличивали.
И там тоже есть автодополнение, чат, оффлайн режим?
Тут же меня спросили, какова сложность алгоритма — ок, норм, это нужно знать, потому что в реальном программировании мне это потребовалось целых 0 раз
Да, это нужно. Тут вам повезло, что словарь в питоне работает быстро. Но если не знать что как работает, то можно, например, написать то же самое со списком. Получить квадратичный алгоритм и получить дикие тормоза, когда нагрузка на прод возрастет.
Ну тут ещё вопрос культуры языка и среды. В C++ (STL) алгоритмическая сложность каждого метода является частью спецификации и прописана в документации. Соответственно, даже если человек вообще не очень в алгоритмах смыслит, ему эти "линейное время" и "логарифмическое время" постоянно глаза мозолят. И хорошо что мозолят, везде бы так.
Как еще делать в большой компании, чтобы избежать влияния личности на результат, и чтобы можно было сравнить нескольких кандидатов между собой?
Автоматизировать? Предложить решить 100 задач на том же литкоде в удобное время?
Нет, лучше назначить в рабочее время звонок на минимум час времени и сопеть в наушники пока кандидат потеет в стрессе. Повторить через день. И потом еще неделю так же.
Где-то видел чей-то комментарий на тему "когда меня спросили есть ли у меня вопросы я сказал что есть — мне хотелось бы тоже знать уровень тех, с кем я буду работать. И тоже предложил им решить при мне задачку". Мне кажется это может немного охладить интервьюеров иногда.
По крайней мере интервьювер видит кандидата. Тупо подсказки соседа и гуглеж уже невозможны. Хитрости со скрытыми наушниками еще работают, но в интервью при живом общении такие странности видны. Если кандидат после каждого вопроса несколько минут тупит, а потом идеально отвечает — это будет отражено в отчете интервьюера.
Предложить решить 100 задач на том же литкоде в удобное время?
Та же проблема что и с предложением принимать профиль на гитхабе на интервью.
Списывание, читерство и обман.
При этом само решение тут, гм, решающей роли не играет — по большому счету, вы можете ее даже не решить или решить неправильно, но все равно набрать себе очков, если все делали правильно (и это логично, потому что кому нужны олимпиадники и литкод-ковбои в продакшене :) ).
Эта популярная отмазка Яндекса ("вы, если чё, можете решить всё неправильно, мы принимаем комплексное решение, основываясь на всех аспектах") не бьется с практикой: тем, кто на задачособеседованиях решает неправильно, тут же говорят "извините, дальше мы вас не будем собеседовать".
Когда вас гоняют по (иногда?) тупым задачкам, хотят вовсе не получить их решение, а достать т.н. «сигналы» — как кандидат себя ведет, как размышляет, как комментирует свои действия, как тестит свой код (каким бы простым он ни был)Ну вообще человек, который понимает, что его время тратят по большому счёту зря, при этом ожидая к себе какого-то уважительного отношения, раздражается, и правильно делает. А умение сохранять покерфейс при работе с неприятными людьми нужно обычно менеджеру, а не программисту (да, даже в продуктовых компаниях и внутренней разработке при общении со стейкхолдерами оно нужно очень ограниченно). Потому, ну, что проверяете, то и получаете.
При этом само решение тут, гм, решающей роли не играетКак уже сказали, это утверждение неверно.
кому нужны олимпиадники и литкод-ковбои в продакшенеЯндексу. Почему-то. Хотя зачем люди идут унижаться в Яндекс за всем этим, когда можно пойти хотя бы в Гугл с теми же предусловиями (плюс английский, окей), мне совершенно непонятно.
Почему зря?Потому что если вы спрашиваете однообразные задачи, которые даже не из разных сфер знаний алгоритмики более двух раз — а примеры выше реально однообразные и практически друг друга не дополняют — вы тратите время зря, притом и своё, и кандидата. Это не добавляет новой информации, это проверяет терпение кандидата, а для программиста ангельское терпение не является ключевой компетенцией. Возможно, потому что процессы поганые, возможно, потому что конкретные интервьюеры/рекрутёры не справляются с задачей (в этот конкретный раз или систематически — другой вопрос).
к сожалению, программисты — зачастую, очень неприятные людиЛюди вообще зачастую очень неприятные, чивоуштам. А если чуть серьёзнее — так задача менеджмента и отдела по работе с персоналом выстроить процессы так, чтобы очень неприятные люди как минимум не собеседовали кандидатов за исключением крайней необходимости, а в полном идеале так вообще не попадали в компанию (но это уже сложнее, и ещё и платить надо деньгами, и вообще шевелиться много), или, если попали, исправлялись по мере возможностей.
В гугле 3-4 алгоритмических интервью. Но это не 10 задач. Обычно дают 1 задачу с дополнительными вопросами. Вроде: сначала напишите совсем простой случай. Потом а что если у вас данные вот такие придут?
Middle от 130к до 200к; Senior от 200к до 300к + полугодовые премии
Middle 2500 — 3500 USD; Senior 5000 — 6000 USD
Ну опять вот это всё. Смиритесь уже, что никого не волнует знание Django или SqlAlchrmy. Это всё наживное, если мозги есть, человек разберётся. А вот закодить эффективный алгоритм для хай лоада — это уметь надо.
И как на интервью проверить, что мозги есть? Понятно, что лучший способ — взять человека на испытательный строк в пол года, чтобы уж наверняка. Но это непозволительно дорого.
Вроде уже несколько раз прозвучало выше что яндекс таким образом нанимает людей, которым можно внушить корпоративные ценности и которые не будут задавть лишних вопросов. Как показывает эта статья — со своей задачей они справляются, автор отсеился, а если бы прошел то сам бы свалил в течение пары месяцев "задачи мусор и инициативы вообще не дают".
Это раз, второе — когда у вас гигантский поток заявок то нужно отсеивать хоть по каким-то признакам. Хоть по цвету кожи, хоть по гороскопу, хоть по байке "зачем нам нужны неудачники". Если вы физически не можете проводить единолично 100 собеседований в день и на первый взгляд все резюме +- одинаковые — все прекрасные крутые спецы с кучей опыта и интересными проектами — то приходится фильтровать хоть как-то. Например разделить 100 кандидатов на 20 подчиненных и попросить их пройти какой-нибудь бессмысленный формальный критерий. Ну и дальше от них уже отсекать какой-то процент.
Это раз, второе — когда у вас гигантский поток заявок то нужно отсеивать хоть по каким-то признакам.А зачем кого-то вообще отсеивать? Нужно набрать условно сотню человек по разным позициям — обрабатываешь входящие заявки до тех пор, пока не наберешь, после чего закрываешь вакансию. Вряд ли кто-то всерьез надеется на таких объемах брать лучших из лучших. Подходят под требования — и ладно.
А зачем? если можно улучшить корреляцию и вместо 0.1% шанса найти кого нужно сделать 0.2% шанса назойливыми вопросами — то это в целом удвоение качества поискав 2 раза, хотя 99.9% и 99.8% отказов со стороны кажутся примерно одним и тем же.
Ну то есть не факт, что человек знающий алгоритмы — молодец, а не знающий — лохопед. Но зачастую хороший разработчик шарит и за базовые алгоритмы, а если нет — то придумает на ходу. У меня недавно собес был, спросили про MESI (алгоритм когерентности кеша в цпу), а я ни в зуб ногой. Помню что лет 5 нзад в википедии читал про него, в памяти осталось только что там 4 режима работы. Ну и как бы ничего, с подсказками от интервьювера минут за 20 переизобрел режимы и зачем они используются. Просто исходя из простой логики разработчика с опытом работы с многопотоком.
Точно так же изобретал каналы — для меня это всегда была штука куда ты пихаешь данные и они с другого конца видны — без мьютексов и каких-то других дорогостоящих синхронизаций. И тоже — не интересовался никогда, но после предложения "давайте вы попробуете придумать такую структуру данных, думаю у вас получится" и некоторых подсказок тоже смог придумать и spsc и mpsc каналы. ИСЧХ теперь я думаю я это навсегда запомню — вымученное таким трудом запоминается.
В итоге да, вместо часа интервью заняло почти два, и незнание каких-то вещей в целом не помешало успешно пройти (позвали на второй и третий этап) собеседование. Задачка это бусидо — не цель, но путь. Важно не решить задачу, а продемонстрировать свои навыки в процессе. Например вот так.
def common_elements(a, b):
b_dict = defaultdict(int) # defaultdict выжил :)
for el in b:
b_dict[el] += 1 # я считаю все элементы из b, т.е. типа collections.Counter
result = []
for el in a:
count = b_dict[el]
if count > 0: # если какой-то элемент из a встречается в b
result.append(el) # то это успех
b_dict[el] -= 1 # и я "вынимаю" его из b, т.е. уменьшаю его количество на 1
return result
Сделал для себя такие выводы.
Дана строка (возможно, пустая), состоящая из букв A-Z: AAAABBBCCXYZDDDDEEEFFFAAAAAABBBBBBBBBBBBBBBBBBBBBBBBBBBB
Нужно написать функцию RLE, которая на выходе даст строку вида: A4B3C2XYZD4E3F3A6B28
В JS она тривиально решается однострочником с регуляркой.
Плохая идея. Почти наверняка будет на порядки медленнее. Регулярки — сильный инструмент, но им очень легко выстрелить себе в ногу.
В JS она тривиально решается однострочником с регуляркой.
А можете показать этот тривиальный однострочник? не троллинга ради, просто интересно.
Могу, эти сведения не содержат гостайну. Выражение вернёт новую строку, можно проверить в консольке браузера.
str.replace(/(.)\1*/g, (s, c) => s.length > 1 ? c + s.length : c)Вряд ли это будет на порядки медленнее, как предположил wataru. Регулярка тут простая, линейная, забирает подстроку и тут же заменяет. Вручную ничего не выиграем, по крайней мере в js.
* имеет преимущество перед + или это просто на скорую руку так получилось?str.replace(/(.)\1+/g, (s, c) => c + s.length)Извиняюсь за некропост, не смог пройти мимо и не попробовать измерить. Я не знаток js, так что не смог бы угадать результат измерения:
> 'a'.repeat(1e7).replace(/(.)\1*/g, (s, c) => s.length > 1 ? c + s.length : c);
Thrown:
RangeError: Maximum call stack size exceeded
at String.replace (<anonymous>)по сути Яндекс не могут проверить ТС на реальных задачах (потому что не знают или потому что секурность или потому что хрен знает что надо делать завтра) и гоняют его на простых задачах, как проверяют выпускников вуза/курсов
Чтобы понять, как у него мозг работает, вынослив ли :)
ну как если бы грузчика нанимали, дал ему мешок и пусть туда-сюда 100-метровку бегает
самого выносливого (и терпеливого) берешь :)
Разделяю мысли автора. Сам завалил собес в Яндексе на первом этапе на вопросах вроде:
UPD. Ребзя, я тут понял, что фраза "интервью шли один за другим" может быть неправильно понята. Сорри, я имел в виду, что 2 и 3 интервью были одно за другим, а вообще между 1, (2и3) и 4 собеседованиями проходило несколько дней а то и неделя. Так что тут я не в претензии, время я выбирал удобное мне. так что за это яндексу плюс.
Статью отредактировать не могу, у меня зависает UI хабра, даже в разных браузерах.
Знаешь, кто такой зануда? Это человек, с которым легче переспать, чем объяснять, почему ты этого не хочешь!
(с) Ностальгия
Эм… Вы все еще ждете ответа после фразы "мы вам перезвоним"?
После моего супер-провального собеседования в 2019 (были две задачи: про отель и нули с единицами, обе решил частично) мне через две недели прислали письмо, сказали что не подхожу, надо решать задачи на литкоде и попробовать ещё раз через полгода.
Я бегло посмотрел ваши решения и хочу сказать что вам надо подтянуть базовые знания о LIFO/FIFO и рекурсии. Многие представленные здесь задачки имеют лаконичные решения через стек или рекурсивный обход. Удачи!
Насчёт рекурсии — они ж обязательно спросят, а что будет если на вход подадут 10k элементов?
Ну вот тут LIFO и понадобится. Любую рекурсию можно переписать в цикл+стек. Зачастую и стек не нужен, как в каноничном примере с факториалом.
не бьется с практикой: тем, кто на задачособеседованиях решает неправильно, тут же говорят «извините, дальше мы вас не будем собеседовать».
Простите, вы про наем кого сейчас говорите? Студентов на джуниорские позиции? Тогда ок, обучайте сколько угодно.
Смысл брать опытного разработчика в том, чтобы он принес свой, возможно новый, опыт в компанию/проект.
Какого именно опытного, из тех 30 опытных, что претендуют на 1 место в команде?
А вот нет у меня формулы универсальной, простите. Я всегда предпочитал чтобы человек сам рассказал о своем опыте. Заодно видно насколько он общительный или конфликтный.
Если человек собеседуется на вакансию senior Django developer и рассказывает как он, к примеру, писал API (и какие библиотеки использовал), какие были проблемы и как решались (не обязательно им самим, а командой) — то я не буду его заставлять писать сортировку если он адекватный. И уж точно я не буду давать ему 10 разных задачек на алгоритмы.
Ну, вот представьте, что у вас 30 таких адекватных, которые писали API, а выбрать надо одного.
А вот нет у меня формулы универсальной, простите.
А вот в этом и основная проблема. Многие ругают алгоритмические собеседования, но не предлагают альтернативы. Альтернативы для компаний уровня ФААНГА, когда на одно место претендуют десятки человек.
Алгоритмические интервью (если они проводятся правильно) — это не интервью на знание алгоритмов, это проверка того, как кандидат может думать. Потом, кстати, обычно следуют интервью на системный дизайн и поведенческие, не нужно думать, что все ограничивается одними задачками.
Ну, вот представьте, что у вас 30 таких адекватных, которые писали API, а выбрать надо одного.
Очень просто — если их 30 человек и все адекватные (и прямо все подходят), то до последнего просто не дойдет очередь. Уже после 5 собеседований я перестану тратить время и выберу из пяти. Субъективно, конечно же.
У вас собеседования идут параллельно, вы не можете себе позволить год собеседовать. И, естественно, эти 30 адекватных идут вместе со 170 неадекватными. А еще будет печально, если последний окажется самым талантливым с самым ценным для вас опытом.
Вы мыслите категорями маленькой компании. В гуглах и амазонах мыслят по-другому.
Я вот недавно собеседовал человека, который говорил, что он писал апи, казался адекватным, владел теорией и т.д. А как попросил его написать код, даже не алгоритмичускую задачку решить а написать банальный кусок, похожий на то, что каждый программист пишет каждый день, понял, что код писать человек не умеет. Он ключевые слова языка неправильно писал.
У вас собеседования идут параллельно, вы не можете себе позволить год собеседовать
Ога, зато по 4 часа (как минимум) собеседовать каждого по одной только теме вы можете себе позволить..
А когда вы, наконец, прошли все эти 200 собеседований и выбрали самого-самого, наняли его… И через неделю вам попадается самый-самый-самый! Вы будете увольнять предыдущего?
Давайте не будем углубляться в какие-то непонятные споры. Тут все приводят уже совсем странные примеры.
Суть статьи — на собеседовании на позицию "Senior Django developer" компания провела 4 собеседования для одного кандидата и еще ни разу не зашел вопрос о Django и чем-то хотя бы смежном. Вы считаете это нормальным? Сколько еще будет считаться допустимым?
Ога, зато по 4 часа (как минимум) собеседовать каждого по одной только теме вы можете себе позволить..
Вы правда думаете, что гугл, амазон, фейсбук и прочие не умеют считать деньги?
И через неделю вам попадается
Не попадается, вакансия закрыта, набора на нее больше нет.
Суть статьи — на собеседовании на позицию "Senior Django developer"
Я пишу про ФААНГ, там обычно собеседуют на позицию software developer engineer, а не django developer или jquery developer.
Не вижу проблемы взять на позицию синьора человека, который джанги в глаза не видел. Это не принципиально. Если он действительно синьор, разберется. Если это, конечно, не набор на временный проект, который через пол года завершится. Пока вы ищите и умного и красивого, конкуренты возьмут умного, а красоту наводить его потом научат.
Ох и представьте себе, сколько же ненависти по поводу собеседований вы будете читать от людей, которые вошли в "калибровачную" стадию, если такой подход использовать.
Но даже без этого, тут есть большая разница. В задаче о невесте нет никакого знания о качестве вариантов. Там могут приходить числа любой размерности. При найме же предел отлично известен (все знающий и умеющий сеньер). Еще, особенно в больших компаниях типа яндекса-FAANG, нужно нанять не одного кандидата, а многих и поток кандидатов можно считать неограниченным. Вот и получается, что идеальное решение — установить нижнюю планку требования кандидата и при прохождении ее сразу нанимать.
Нет, не думаю. Все ваши предположения перечеркиваются одним простым фактом: в фаанге полно адекватных разработчиков и очередь тех, кто туда готовится очень велика. Я раньше тоже думал, как многие тут. А когда стал решать литкод и глубже изучать алгоритмы изменил свое мнение на прямо противоположное. Имхо, это нужно любому синьору, оно, в итоге, помогает в работе и приводит мысли в порядок. Особенно сисдиз.
Это как-бы стандарт интервью в фаанг. Если вы не Линус Торвальдс, у вас будет такое же интервью, как и у всех.
А зачем стали решать литкод и изучать алгоритмы, что за область применения?
Хочу в фаанг. Но потом просто интересно стало. Более глубокое понимание алгоритмов, их сложности, применимости и т.д. помогает в работе. Я это с удивлением заметил. И не только я.
Просто для себя решил пока не тратить время на Кнута, вроде оно в вебе не ценится.
Я фуллстек. Начните не с Кнута, а с лекций Седжвика на курсере. Начните решать литкод, там есть челлендж, когда в день нужно решать 1 задачку. Вот апрельский. Это правда интересно само по себе.
В телеге есть группы единомышленников.
Бывает и такое, да. Почему вы решили, что в случае с Яндексом это так? У вас есть какой-то инсайд, вы работали в компании на найме не линейным специалистом?
Это не отвечает на поставленные вопросы. Линейным специалистам часто некоторые вещи кажутся глупостью, потому что они не видят всей картины.
В задачке 4 subranges не нужен, там достаточно помнить текущий максимум, длину предыдущего ренжа (либо 0, когда справа от него него более чем на один нолик) и накапливать текущий. Вот вам и O(N) памяти на пустом месте…
Ну и в 10 задачке картина похожая. Накапливаем текущий ренж, пока он меньше суммы. Если превысил, сдвигаем начало вправо. Тоже всё линейно и без доп. памяти.
Автору спасбо за крутой слог и лёгкий стиль изложения. Браво!
Давно так не смеялся. Автор, с меня пиво если пересечёмся!
Помните, тут нельзя ничего запускать, вместо этого тут принято запускать интервьюера, который интерпретирует ваш код прям в голове и говорит какие случаи не работают, чтобы вы могли пропатчить код.

В фейсбуке такие же интервью предлагают. И причем их надо рожать в моем случае на свифте, ны котором в силу специфики работы обычно не держишь в голове всякие там строковые сдвиги и вещи как из Char получить String и обратно плюс всякие там copy-on-write и даже если помнишь какое то решение из универа для свифта его надо модифицировать. И это при точ что я в итоге родил им за 5 часов собеседования все алгоритмы. В итоге они остались чем то недовольны. На что я им сказал что они уже на этих алгоритмах наняли 2х моих бывших коллег которых я нахожу одними из самых паршивых программистов и я переписывал за ними то что они наархитектили, и раз они еще чем то не довольны, значит наверное мне не место в этой компании. А самое забавное что эту же моду взяли самые захудалые мелкие конторы.
Я не минусовал.
В целом, да — интервью прошло не так как ожидал человек. Но по вашему комментарию можно понять будто вы думаете что это что-то плохое.
У человека же есть какое-то самоуважение. Вы 10 лет работали над довольно сложными задачами, у вас опыт на реальных проектах, вы идете общаться с людьми, которые вроде бы даже должны быть выше вас по уровню… Но вас спрашивают то же самое что и студента 4 курса, а об опыте, который нужен по описанию вакансии — ни слова.
Это обидно, в первую очередь. Конечно, 1-2 задачи — без проблем, но 4 часа! А остальное будут спрашивать? Еще 8 часов?
суть поста в том, что человека отинтервьюировали не так, как он хотел?
while True:
passed = check_candidate(task_type="algo",task_level="easy")
if not passed:
break
А почему он не может написать свое мнение? Обязательно только позитив писать?
Где, укажите мне, прописаны каноны, по которым надо проводить собеседования?
Если нанимаемого не устраивает, он волен покинуть «театр абсурда», а не писать потом негатив в сторону нанимателя.Почему-то вы сами своим же советом не воспользовались, и, вместо того, чтобы молча покинуть эту статью, начали комментировать её. Так стоит ли требовать от других людей того, чего сами же не выполняете?
Болтовня ничего не стоит. Покажите мне код.
— Linus Torvalds
Даже когда были вопросы на собеседованиях про круглые люки (да, я сам их тогда задавал тоже, прошу прощения у всех!), то тоже всегда были люди которые говорили что без них нельзя, почти дословно, простите на сарказм:
Когда ты раз сходил на такой собес — кажется, ой, ну какие-то дураки там сидят, фигню спрашивают. А по ту стороны сидят ребята, у которых уже глаз наметан на эти задачи, на типичные ошибки, на понимание того, как кандидат мыслит.
Если человек не может быстро взять какой-то инструмент и начать им пользоваться
Ну да, быстро нагуглил трендовые инструменты и понеслась! Помним mongoDB в каждом сайте 10 лет назад?
то тоже всегда были люди которые говорили что без них нельзя
Ну да, быстро нагуглил трендовые инструменты и понеслась
Чтобы поправить строчку в Го сервисе, мне не надо изучать Го.
Могу поспорить, что Вы не скажете в чем тут ошибка:
Чтобы поправить строчку в Го сервисе, мне не надо изучать Го.
найти автора кода и спросить у него
найти группу, которая ментейнит код, и спросить у них
не пропускать код на ревью, который никто не понимает
использовать языки, где не будет проблем с пониманием
Вы же не предлагаете это все спрашивать у кандидата? Или вы ищете жестко под одну задачу заточенного человека?
И привел пример того, что не зная языка, Вы просто не увидите ошибку
Уволился пять лет назад.
А зачем тогда Вы там нужны?
Те, кто пишут на этом языке, прекрасно его понимают.
Я как раз предлагаю не гонять кандидата по олимпиадным задачам.
Почему вы так считаете?
Например, в соревнованиях CTF приходится и в brainfuck уязвимости искать, и ничего, люди находят.
В вашей компании, я так понимаю, не 300+ разработчиков, которые ежедневно коммитят в один проект под сотню ПРов?
Ну, вы же нанимаете людей на языке, на котором пишете, да?
В силу ряда особенностей, мы нанимаем разработчиков и готовим их (первые три месяца) на язык и платформу под которую пишем.
Те, кто пишут на этом языке, прекрасно его понимают. Тут проще не допускать до ревью того, кто не знает этого языка.
У меня с опытом все сильнее складывается ощущение, что с ростом экспертизы разработчик перестает быть С++ или там Java девелопером а становится просто Software developer, который баг на любом языке от питона до хаскелля может пофиксить за разумное время, а выбор языка для сервиса будет основывать на "готовые либы чтобы сделать Х и иметь поменьше юзеркода/что знает команда/что со спецами на рынке/...", а не по принципу "ну я С++ дев буду на С++ писать".
У меня с опытом все сильнее складывается ощущение, что с ростом экспертизы разработчик перестает быть С++ или там Java девелопером а становится просто Software developer
который баг на любом языке от питона до хаскелля может пофиксить за разумное время
выбор языка для сервиса будет основывать на «готовые либы чтобы сделать Х и иметь поменьше юзеркода/что знает команда/что со спецами на рынке/...», а не по принципу «ну я С++ дев буду на С++ писать»
дальше можно не читать
с длинным хвостом опционовДа куда угодно, где этот хвост компенсируют пропорциональным сайнапом (в деньгах, акциях или опционах), что вообще-то совсем не нонсенс.
Что так всех бомбит — не пойму.То, что человека просят делать одни и те же довольно тривиальные вещи по кругу 10 раз на нескольких собесах, притом иногда ставя откровенно абсурдные ограничения (и да, невозможность использовать стандартную библиотеку языка — абсурдное ограничение, куда полезнее, если зачем-то очень хочется, обсудить, как она работает, и в каких случаях используемые алгоритмы неприменимы/неудачны — по скорости, памяти или чему-то ещё).
Можете объяснить, что такое "хвост опционов" в Яндексе? У каких-то старых сотрудников эти опционы уже должны были конвертироваться в акции которые можно продать и уйти куда угодно?
А оклады по грейдам это какая-то тайна или нет? Можете примерную табличку с грейдами (и всеми "хвостами" переведенными в условные тугрики) привести? Ну типа мидл — 200к на руки, сениор — 300к на руки, лид — 400к на руки, архитектор 500к на руки? Ну, просто чтобы как-то предметно было.
А то слов сказано много, а понимания что к чему — непонятно. По идее грейды на весь яндекс скорее всего одни и те же и условно в общем доступе, поэтому хотя бы примерно обозначить на что могут рассчитывать разработчики определенного уровня было бы неплохо. Тот же фаанг на levels.fyi эти цифры например показывает
Хм, никогда бы не подумал.
Ну оттуда следует что средненький сениор получает 50к на руки за год
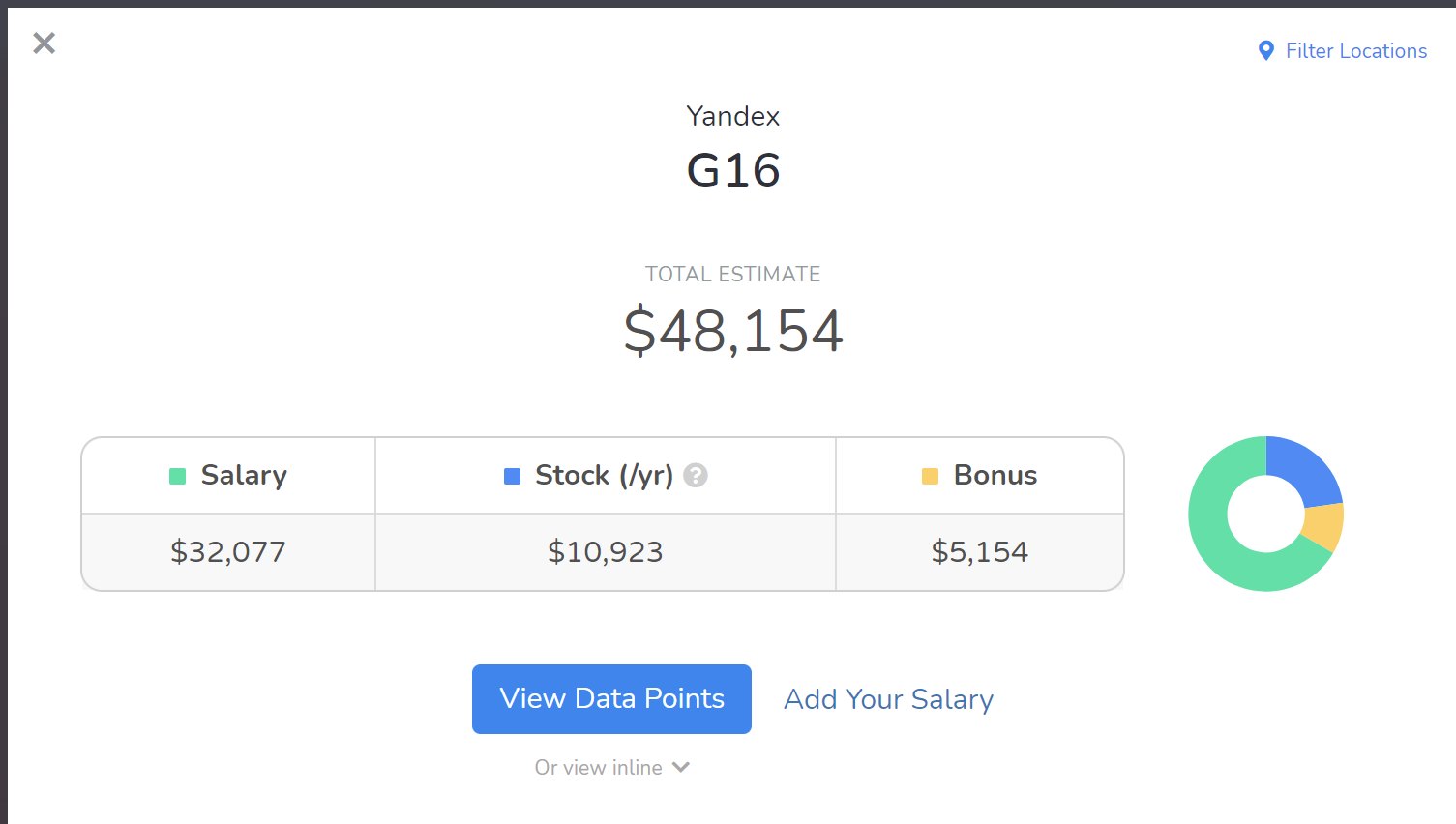
Что кажется вполне неплохо. G18 получает уже 110к на руки, т.е. 8.5 миллионов за год.
Не похоже на "ниже рынка"
Это не сениор, это миддл. По крайней мере приставки "старший" в названии должности у такого нет. Сениор — это 17.
Ну окей, то есть получается 50000 мидл (321000 рублей в месяц), сениор 75000 (474000 рублей в месяц).
Не знаю в каком мире это "ниже рынка". Если посмотреть отчеты "Моего Круга" тут же на хабре то там в средних красуются смешные по сравнению с этим цифры в 100-150к для мидла. Конечно там регионы вносят лепту и тд итп но все же. Можно на хх поискать мидл вакансии на 300к ради интереса — нет ни одной. А в тех что есть скромненько через слеш пишется senior. Да и вакансий 6 из 1735.
Это не к вам лично вопрос, а скорее в воздух про людей у котороых яндекс — это выжималка, в которой ни денег не заработать ни задач нормальных. И если второе возможно верно (как и для любой крупной компании впрочем), то первое видимо далеко от истины
я знаю некоторое количество таких
просто платить хорошие бонусы, которые в некоторых компаниях тоже бывают.
что на 17 грейде в Яндексе оценка С на ревью даёт примерно +250 баксов
Надо только понимать, что по большей части эти крутые коллеги пришли еще до того, как начался этот театр абсурда с собеседованиями.
Вот, кстати, еще один комментарий в похожем треде: " Как проходят алгоритмические секции на собеседованиях в Яндекс" в блоге самого Яндекса.
Прошло два года, ничего не поменялось.
А вот скажите, как часто в работе попадаются задачи из тех, что предлагаются на собесе?
но буквально за полгода раскрывались в достаточно перспективного разработчика. Алгоритмические задачки таких отсеивают сходу
Приходит такой Линус Торвальдс на собес в Яндекс.Лавку, говорит — "я Linux напи..."
А ему — "нам наплевать что вы там написали, давайте посчитайте сколько тут символов в строке"
Оффтоп: я биллингом раньше занимался, и там почти вся финансовая часть была на коболе. У вас был и вы его выжгли напалмом, или не было? Или вообще до сих пор живёт с вами?
Насколько знаю бизнес-логика пишется на Java и прочих Haskell-ах, а тут ассемблер среднего уровня (если C++ есть ассемблер высокого уровня).
CRTCPPMOD MODULE(QTEMP/DTAQ) SRCFILE(&ASRC/&SRCF) SRCMBR(DTAQ) OUTPUT(*PRINT)-
DBGVIEW(*SOURCE)
CRTCPPMOD MODULE(QTEMP/BATCHM) SRCFILE(&ASRC/&SRCF) SRCMBR(BATCHM) OUTPUT(*PRINT)-
DBGVIEW(*SOURCE)
CRTCPPMOD MODULE(QTEMP/BATCHMWRP) SRCFILE(&ASRC/&SRCF) SRCMBR(BATCHMWRP)-
OUTPUT(*PRINT) DBGVIEW(*SOURCE)
CRTSQLRPGI OBJ(QTEMP/ELB03S) SRCFILE(&ASRC/&SRCF) SRCMBR(ELB03S) DBGVIEW(*SOURCE)-
COMMIT(*NONE) OBJTYPE(*MODULE) RPGPPOPT(*LVL2) SRTSEQ(*HEX) OUTPUT(*PRINT)-
LANGID(RUS)
CRTRPGMOD MODULE(QTEMP/ELB07PROC) SRCFILE(&ASRC/&SRCF) SRCMBR(ELB07PROC)-
DBGVIEW(*COPY)
CRTPGM PGM(&ALIB/ELB03S) MODULE((QTEMP/BATCHM) (QTEMP/BATCHMWRP) (QTEMP/DTAQ)-
(QTEMP/ELB03S) (QTEMP/ELB07PROC) ) BNDDIR((*LIBL/LESBNDDIR) ) ACTGRP(*CALLER)-
TGTRLS(*CURRENT) STGMDL(*SNGLVL) ALWUPD(*YES) ALWLIBUPD(*NO) ENTMOD(QTEMP/ELB03S)
extern "C" int WordsCount(char *pBuffer, int nBuffLen)
// количество слов в строке
dcl-pr WordsCount int(10) extproc(*CWIDEN : 'WordsCount');
pBuffer char(65535) const options(*varsize);
nBuffLen int(10) value;
end-pr;
// Создаем многопочку
Master = Batch_CreateMaster('*LIBL' : 'ELB07S' : '' : 'ETLPROC' :
DtaQLib : 'DQELBMAST' : 'DQELBWORK' :
WorkersCount :
(%size(t_qdsClient) * SendBlockSize) :
(%size(t_qdsClient) * SendBlockSize) :
PingTime : ResendCount : RecieveTimeout :
strError);
Batch_MasterSendData(Master : pData : DataLen : ErrStr)При закрытии дня работа не останавливалась, тут к сожалению деталей реализации не знаю, работал все-таки аудитором, а не разрабом.
При этом была высока доля ручных операций
По скулю — если отключить оптимизацию запросов нельзя обойтись без построения плана запроса?
вам-то, наверное, в работе нужно знание алгоритмов
Нет. План запроса все равно строится. Хотя бы для того, чтобы понять какие индексы подцепить.Тогда понятно почему для скорости используется MongoDB, хотя в основном mongoose используется, чтобы привлечь к работе тех, кто не знает SQL.
На следующий день (иногда через день, все это сводится воедино и на счете получается технический овердрафт в -10тр. Так работает АБС.Жесть какая-то. Так не работает нормальная АБС. Не из нашего времени. Устриц ел, если что.
В результате на серверах одновременно крутятся тысячи фоновых процессовЕдиницы сотен — могу понять. Какая-то жуть в архитектуре.
И любое изменение требования регулятора приводит к необходимости доработки той или иной функцииВезде так. У у всех. Да и по-другому быть не может. В-общем, наверно, не понял примера и к чему он.
А вот если запрос динамический и формируется на лету… И при этом вызывается десятки тысяч раз в секунду… Получается очень дорого.
Была у меня задача — запрос содержал конструкцию where… in (...) где список in(...) формировался каждый раз заново из входных данных
Да, больше кода. Но стало быстрее работать и меньше грузить процессор. А функция была критичная — как раз поиск совпадений по наименованию со списком злодеевО боги… еще тысяча и один пример из серии таких же «возьмите уже грамотного sql-разработчика один раз и не мучайте железо и весь отдел дикой самопальщиной».
Из PEX статистики работы XXXXXXX видно, что 33% времени и 36% ресурсов CPU тратится на выполнение QSQRPARS в программе YYYYYYY, т.е. парсинг статических выражений при подготовке SQL запроса
А функция была критичная — как раз поиск совпадений по наименованию со списком злодеев. Т.е. вызываться она могла в определенных ситуациях десятки миллионов раз подряд.
И будет у вас один фулл скан таблицы на каждое обновление кеша раз в N минут.
Я не знаю баз для которых раз в несколько минут один раз прочитать одну табличку полностью дорого. Естественно у таблички должен буть приемлимые размер, в вашем описании он как раз такой.
Если у вас можно производительность закручивать хинтами или ещё как вниз то надо закручивать. В этом месте можно работать дольше.
Для всех у которых большая нагрузка по kv паттерну. А что тут такого? Так примерно все и делают. Чтобы нагрузку держать и sql базу не грузить.
Просто читать не из sql, а из общего кеша. Порефактрить код придётся, но опять же ничего страшного. Вы и так рефакторили чтобы читать как-то по другому.
У вас есть табличка в которую летит большой rps по kv паттерну. Проверить наличие по ключу или по строке это именно он и есть.
40 миллионов с формами это ну пусть миллионов 400 без оптимизации даже.
Инмемори влазит без проблем.
Берёте и кладёте эту табличку в любой инмемори кеш. Любой стандартный подойдёт. Настраиваете периодическое обновление. Прочитать раз в 5 минут табличку на 40 миллионов записей вообще не проблема для БД.
Дальше переводите всех клиентов на обращения к этому кешу вместо sql таблички.
Для каждой следующей таблички с аналогичным паттерном нагрузки повторяете.
Получаете маштабируемое решение. Вам становится просто все равно на нагрузку в этом месте. Типовые вещи на небольшом железе вытягивают вообще любой rps. Sql база перестаёт испытывать нагрузку.
Прочитать раз в 5 минут табличку на 40 миллионов записей вообще не проблема для БД.
Вы так уверены? Пробовали читать 40 миллионов записей в каждой из которых лежит мегабайтный jsonb?
Там в условиях фамилии.
Делать kv поиск по полю с мегабайтом данных как-то неразумно. Класть такое поле в табличку вместе с обычными данными тем более неразумно, если у вас не колоночная БД.
27 тыс. программных объектов
15 тыс. таблиц и индексов базы данных
Более 150 программных комплексов
Занимает более 30 Терабайт дискового пространства
В день изменяется более 1,5 Терабайт информации в БД
За день выполняется более 100 млн. бизнес операций
Одновременно обслуживается более 10 тыс. процессов
При чем тут вообще масштаб всей системы? Явно же не во все таблички идёт большой rps по kv схеме. Ну и значит и не надо все так делать.
Делается мониторинг, собирается статистика. Находятся больные места. И именно они обвешиваются кешами.
Альтернативный — это читать с других железок. Читать все всегда с одной железки рано или поздно упирается в эту самую железку.
в особо тяжких случаях до отзыва лицензииесли мне не изменяет память, самое быстрое событие для отзыва лицензии — это неотправка рейсов в Банк России в течение 4 дней.
Я описал стандартную архитектуру всех яндексогуглов. Это работает. Стандартным образом. Стабильнее Сбера уж точно.
Все типовое, взаимозаменяемое и быстронакатываемое. Ну вылетела железка и ладно. Просто берётся запасная. Автоматика сама на неё накатит софт и подключит слейвом к двум оставшимся.
Ну вылетела железка и ладно. Просто берётся запасная.
Час простоя АБС может стоить банку до 24 миллионов рублей
прямых финансовых потерь при кратковременной недоступности.
Это не учитывая репутационных потерь, которые могут привести
к прекращению банковской деятельности в целом.
АБС – это сердце банковской системы.
От него зависит жизнеспособность подавляющего
большинства банковских сервисов.
Его остановка приведет к почти полному прекращению
предоставления автоматизированных банковских услуг.
К АБС подключено более 60 банковских систем,
обеспечивающих работу различных бизнес направлений.
Большинство фронт приложений используют АБС,
как основной источник информации и функциональности.
можно сделать АБС параллельной
Фактически, там многое что работает параллельно.наверное, я не очень точно выразился — имел ввиду каждый бизнес процесс седлать разделяемым на множество и разнести все это по разным машина.
Но все это крутится на одном сервере
это теоретические рассуждения, а практического опыта в таком у меня нет.
Ну вылетела железка и ладно. Просто берётся запасная.
Даже комментировать это не буду.
Для быстрой реакции (переключения) нужен, конечно, резерв, причём горячий. И мощности закладываются так, чтобы фактор репликации учитывался в запасе мощности. Иначе, как вы и привели пример, при отказе и временном росте нагрузки, все может стать ещё хуже.
В случае использования стандартного железа (без подходов вертикального масштабирования), это стоит адекватных денег и окупается примерно после первого сбоя, если сервис критично важен. Но тут, конечно, не могу сказать за всех, проекты бывают разные.
Через час-два готов ко включению слейвом в любую БД или принимать нагрузку если там данных локальных не нужно.
Вы специально пропустили все кроме этой фразы про час?
Зачем М-Видео? Сервера много кто делает. 2к это нормальная цена. Даже недорого ещё. Я думал там под 5к уже.
А вот 817к это неразумно.
За такие деньги можно огромное резервирование обеспечить и еще на огромный запас производительности останется.
2к это нормальная цена
Как раз столько и стоят. Ну может 5к.
Смысла нет платить больше. Проще взять побольше и организовать резервирование. И в прод лишний сервер добавить и в запас поставить. Так и дешевле и надежнее.
Вы все время пытаетесь принизить все остальные проекты, не надо так делать. Мы тут тоже большие вещи делаем. И даунтайм тоже много денег стоит.
А теперь представьте что вы пытаетесь расплатиться картой в магазине, а вам говорят «извините, ваша карта не работает потому что ваш банк не отвечает».у нас такое постоянно с самым крупным банком — приват. Примерно пару раз в год их терминалы не работают и расплачиваться в магазинах можно только наличкой.
Те же карты — два часа не работают — это ЧП для банка.приватбанк смотрит на вас с недоумением )))
Т.е. тут надо не просто иметь резервную железку, тут надо еще чтобы эта железка в реальном времени зеркалилась с рабочей. И так для всех железок в системе…
Но ядро АБС неделимо. Там все данные очень тесно связаны между собой (практически все таблицы имеют перекрестные связи так или иначе) и падение любой из них в той или иной степени затронет всю систему целиком.
Напомню что началось все с того что я предложил вместо магии использовать типовой кеш. Для kv нагрузки на одну из таблиц. И сразу нагрузка упадет.
Кажется там много таких мест. Которые можно безболезненно вынести.
Повторюсь — я не думаю, что в банке не умеют считать деньги. И была бы возможность обойтись сервером за 5к — обошлись бы.очень сомневаюсь, думаю там действуют по принципу — «работает — не трогай» )) Ну и да, экспериментировать там себе дороже будет. Поэтому и сидят на таких монстрах с ораклом за 100500$. Ынтерпрайз он такой — суровый и беспощадный
умаю там действуют по принципу — «работает — не трогай» )) Ну и да, экспериментировать там себе дороже будет.
Сколько денег вы потеряете за эти 15 минут простоя?
Повторюсь — я не думаю, что в банке не умеют считать деньги. И была бы возможность обойтись сервером за 5к — обошлись бы.
Вас вполне могут нанимать на перекладывание джейсонов, а не на оптимизацию работы с БДТогда организаторов интервью-процесса надо уволить за профнепригодность, потому как они не проверяют ключевые компетенции кандидата.
лучше не нанять хорошего разработчика, чем нанять плохогоВы-таки не поверите, но можно хорошо задрочить литкод и в целом алгоритмическую базу и всё равно быть плохим, даже отвратительным разработчиком, просто не в тех же аспектах, что и Senior Spring/Django/Symfony Developer, который не умеет сортировать массив быстрее, чем за O(n^2 log n) (да, я утрирую, я знаю, что это медленнее пузырьков и прочих сортировок вставками)
Тогда организаторов интервью-процесса надо уволить за профнепригодность, потому как они не проверяют ключевые компетенции кандидата.
Вы-таки не поверите, но можно хорошо задрочить литкод
Senior Spring/Django/Symfony Developer
«олимпиадники не умеют писать код»
Порой действительно не умеют, но быстро учатся.
Интересно мнение бывшего яндексоида. Почему Я проводит так много алго-раундов? 10 задач выглядит как перебор, почему не разбавить system design раундом?
Большие компании спрашивают меньше: не считая первого скрининга, на Senior Амазон тратит 3 алго раунда, из них половина времени на leadership principles, в итоге 3 задачи всего. Гугл 3 раунда, 3-6 задач, Фейсбук 2 раунда, 2-4 задачи. При этом всегда есть system design раунд.
По пункту 2 и 3 — почему не почитать фидбек с предыдущих раундов, которые твои коллеги проводили, код посмотреть? Нужно чтобы кто-то обязательно подсказал со стороны? Выглядит странно.
Вопрос не только по конкретной ситуации, знаю людей которые тоже по 10 задач решали с 8+ лет опыта и без раундов по систем-дизайну (или их нет в Яндексе?).
Для "старших грейдов" — это надо подаваться на вакансии с уровня Старший специалист чтобы у тебя провели System Design?
Дальше, чтобы там не говорили про собесы в Яндекс, коллеги там реально крутые, то есть система отбора все-таки работает.а можно неудобный вопрос — раз там такие крутые «коллеги», то почему 90% их творений такие
Это кстати я не шуткую, реально: если вы ответственный человек, ты вы, когда предстаёте перед компанией, отвечаете за то, что вы заявляете как ваши умения. Можно выучить типовые вопросы и даже казаться умнее и опытнее, чем есть, но по факту это переобучение на тестовых заданиях/вопросах.
Нет. Суть в том, что это работает как proof-of-work. Теория такая: если ты способен выучить алгоритмы, то ты, вероятно, толковый специалист. У этого есть две стороны:
Не угадал, конечно — "а можно быстрее?". Но тут, к счастью, время вышло, и мой мозг не успел придумать ничего лучше.
"А можно быстрее?" — это всегда хороший вопрос. Потому что даже если решение "правильное", сделать его быстрее почти всегда можно. И даже если нельзя быстрее, можно показать, что ты в целом знаешь, как подходить к этому вопросу. Или показать, что не знаешь.
lst = [0, 0, 1, 1, 0, 1, 1, 0]
#lst = [0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0]
#lst = [1, 1] # частный случай, когда все единицы
length = 0
max_length = 0
if 0 in lst:
for i in map(len, ''.join(map(str, lst)).split('0')):
if length + i > max_length:
max_length = length + i
length = i
else:
max_length = max(0, len(lst) - 1)
print(max_length)lst = [0, 0, 1, 1, 0, 1, 1, 0]
length = 0
last_length = 0
max_length = 0
if 0 in lst:
for el in lst + [0]:
if el == 0:
if length + last_length > max_length:
max_length = length + last_length
last_length = length
length = 0
else:
length += 1
else:
max_length = max(0, len(lst) - 1)
print(max_length)Не минусовал. Ваше решение похоже работает. Но минусуют, наверно, потому что у кого-то возникла мысль "хвастается, зачем-то. Никто же не спрашивал, как решать задачу, зачем это писать?"
Или кому-то не понравилось, что вы обрабатываете отдельно случай всех единиц в массиве. Плюс код работает очень неявно. Непонятно, чем именно является last_length, почему они суммируются именно при 0. Еще, возможно из-за двух подряд идущих комментариев от вас с решением.
Есть, например, вот такое решение. Оно мне кажется проще и понятнее:
def FindOnesSequence (lst):
print(lst)
# Max sequence of 1s at the end of processed list.
current_ones = 0
# Max sequence of 1s at the end of processed list,
# if exactly one element is removed.
current_result = -1
result = 0
for e in lst:
if e == 1:
current_result = max(current_result + 1, current_ones)
current_ones += 1
else:
current_result = current_ones
current_ones = 0
if current_result > result:
result = current_result
return result Это, фактически, динамическое программирование. Но можно о нем рассуждать и не зная ДП. F(i,k) — максимальная длина из '1' в конце списка из первых i элементов, если оттуда удалить k элементов. Для k=0, оно считается в current_ones. При k=1, оно считается в current_result и там выбираются 2 варианта — или элемент удален раньше или удаляется последний элемент.
Писал статью про найм людей на питоне прошлым летом (в ML-стартап) но подход диаметрально противоположный, зацените, тогда вроде всем зашло.
Причем что важно — выбрали в итоге людей, которые бы наверное не прошли бы 4 раунда таких "испытаний", но у них все в порядке с головой и они всегда решают именно "реальную" задачу и стремятся найти креативные и творческие решения нетривиальных задач.
И да, если вы ищете работу на питоне — залетайте к нам. У нас не Яндекс.
Не стал ее постить напрямую на Хабр, т.к. побоялся, что за такую нативную "рекламу" словлю пермабан на Хабре. Но автор молодец, вроде не боится =)
Ну забанят — буду ещё где-нибудь писать. Тем более это так себе реклама, никто не пишет почти.
Без шуток, это хорошее собеседование для студента без опыта работы, т.е. если работодатель уверен в том что соискатель ничего не умеет и "пороха не нюхал", то вариант отличный, но у готового специалиста спрашивать такое — бесполезная трата времени, причем для абсолютно всех.
Собеседовался 3 раза в общей сложности. Все три завалил, лучший результат — 4ый собес, 5/6 решённых задач. Последний раз собеседовался в сервис, который использую как минимум раз в неделю. И который был практически неюзабельным несколько недель из-за глупой ошибки бизнес-логики: цена фиксировалась на интервал меньший, чем нужно человеку на подтверждение действия. Очень хотелось уже устроиться и делать человеческий сервис, с человеческим качеством пользовательского опыта. (Да, я наивен до степени уверенности, что могу что-то изменить в корпорации). Но не получится.
Ну может кто-то считает, что Яндекс — полезная строчка в резюме.
Возможно про ниже рынка это миф. По крайней мере у меня противоречивая информация насчет доходов. Если считать не оклад, а вообще все доходные статьи
Думаю, у Яндекса и подобных компаний сильная специфика, которая приводит к такому процессу.
Лично знаю людей, не прошедших отбор в Яндекс, которые на порядок круче тех, кто прошел.
Вот список задач на leetcode или полностью совпадающих с приведенными в статье или близких к ним (некоторые залочены):
1) Intersection of two arrays
2) String compression
3) Summary ranges
4) Longest subarray of 1s after deleting one element
5) Number of students doing homework at a given time
6) Group anagrams
7) Merge intervals
8) Line reflection
9) One edit distance
10) Subarray sum equals k
del
count += 1 нужно добавить last_sym = sym. Иначе основное условие никогда не выполнится.Теперь понятно почему такого качества их решения)
Зачем тратить время на компанию, которая не может в течении 45 минут решить стоит брать спеца на испытательный срок или нет?
Более 1-го собеседования прводят на руководящие должности, а 3+ собеседования-на техдира или около того.
Зачем тратить свое время? Они тратят по часу каждый, а Вы — сумму от каждого такого собеседования. И если бы оно что-то давало, так кроме основ ничего ценного.
Плюс процессы далеко не самые нормальные и оптимальные, о чем и говорит сам процесс найма, да и условия работы в лучшем случае средние или чуть выше средних по рынку.
Ищите нормальные, а лучше хорошие компании с человеческим лицом.
Тем более если Вам хорошо на текущем месте, то зачем тратить энергию в пустоту? Сделайте что-нибудь полезное для своей работы сверхположенного и получите за это премию и/или повышение. Не ведитесь на распиаренные компании. Отличным компаниям пиар не нужен. А лучший вариант, когда к Вам сами придут, поговорят по-человечески и предложат. Остальных отсеивайте. Первые лет 5-6 стоит искать, а потом наоборот-делайте по душе и отлично, и за Вами потянутся. К тому же у Вас замечательная компания)
Статья класс! Спасибо)
Зачем тратить время на компанию, которая не может в течении 45 минут решить стоит брать спеца на испытательный срок или нет?
Ну, мало ли. Может, кто-то себя на помойке нашел чтобы так задрачиваться...
Суть в том, что вакансий и компаний много и на всех тратить много времени-слишком затратно, равно как и компании тратить много времени на каждого кандидата.
Нужно уметь ценить свое и чужое время и оптимально выстраивать процессы.
45 минут вполне достаточно при диалоге, чтобы решить допускать кандидата на испытательный срок или нет. Далее все определяется в течении 2-6 недель на испытательном сроке. Не стоит пытаться определить все сразу-это просто невозможно, для этого и есть исп срок.
Уже давно пушечным мясом не являюсь.
Если ищут кого-то-то пусть они и проходят все этапы.
Если кого-то конкретного, и я им подхожу, то пообщаемся, а там обоюдно определим стоит начать сотрудничество или нет.
И никаких трат времени ни моего, ни компании на многоэтапные и длинные собесы. Просто предложение и диалог. Все.
На все остальное немало желающих, лично в этом я не участвую.
Мое время дорого.
def solve1(A, B):
A = Counter(A)
B = Counter(B)
return [a for a in A if a in B for _ in range(min(A[a], B[a]))]
def solve2(S):
ans = []
start = 0
for end in range(1, len(S) + 1):
if end == len(S) or S[end] != S[start]:
ans.append(S[start])
if end - start > 1:
ans.append(str(end - start))
start = end
return ''.join(ans)
def solve3(A):
S = set(A)
ans = []
while S:
x = next(iter(S))
while x - 1 in S:
x -= 1
y = x
while y in S:
S.remove(y)
y += 1
if y - x == 1:
ans.append(str(x))
else:
ans.append(f"{x}-{y-1}")
return ','.join(ans)
def solve4(A):
ans, curr, prev = 0, 0, 0
for a in A:
if a == 1:
curr += 1
else:
curr, prev = 0, curr
ans = max(ans, curr + prev)
return ans
def solve5(A):
B = []
for a, b in A:
B.append((a, 1))
B.append((b, -1))
ans, c = 0, 0
for x, d in sorted(B):
c += d
ans = max(ans, c)
return ans
def solve6(A):
B = defaultdict(list)
for a in A:
B[''.join(sorted(a))].append(a)
return list(B.values())
def solve7(A):
A.sort()
B = []
for a, b in A:
if B and B[-1][1] >= a:
B[-1][1] = max(B[-1][1], b)
else:
B.append([a, b])
return B
def solve8(A):
I = defaultdict(list)
for x,y in A:
I[x].append(y)
X = list(sorted(I))
cx = (X[-1] + X[0]) / 2
ai, bi = 0, len(X) - 1
while ai < bi:
if cx - X[ai] != X[bi] - cx:
return False
A, B = I[X[ai]], I[X[bi]]
if Counter(A) != Counter(B):
return False
ai += 1
bi -= 1
return True
def solve9(A, B):
if len(A) == len(B):
return sum(a != b for a, b in zip(A, B)) <= 1
if len(A) > len(B):
A, B = B, A
if len(A) + 1 != len(B):
return False
d = 0
for i, a in enumerate(A):
if a != B[i + d]:
if d == 1:
return False
d += 1
return True
def solve10(A, target):
S = {0: -1}
c = 0
for i, a in enumerate(A):
c += a
if c - target in S:
return (S[c - target] + 1, i + 1)
S[c] = i
481 комментарий выше моего, на момент написания сего комментария.
Я Солидарен с автором, ибо в у меня был подобный опыт. Рекрутер Яндекса 2 недели ежедневно зомбировала меня пройти их Интервью (с большой буквы), и я сдался, решил попробовать, хотя все друзья убеждали не делать этого. Ска, ШЕСТЬ, ДА ШЕСТЬ разных интервьюеров, почти 10 часов потраченного времени…
И сам подход один а один как у автороа. А его интервью 4… Мне кажется у нас был один и тот же интервьювер.
Как итог, 4 из шести пройдены (исходя из фидбека рекрутера). Но мне всё же рекомендовано пройти половину задачь из letcode ))) И попробовать к ним снова — ХАХАХАХА (Яндекс, напишите алгоритм, какая буква тут лишня)
Да закикайте меня шпалами! Но я солидарен с автором.
Представители Яндекса, скажите, что реально вы получаете от такого процесса? Это просто попытка повторить Гугл? Фейсбук? Так там ещё и про отношение к меньшинствам спрашивают ), а вы нет!
Ни Гугл, ни FB не задал мне на собеседовании ни одного вопроса про меньшинства, так что если такое и есть, то это выброс.
А вы пробовали… Сказать, что уже решали эти задачу? Я тоже сталкивалась с тем, что первый собеседователь спросил то, что должен был второй. Я сказала второму, что это уже спрашивали, и меня просто начали спрашивать обо мне (оффер мне в итоге сделали, но там была другая странная/туппя история, но это же яндекс)
Хочу заметить по поводу "каждый следующий интервью не знал моего контекста". Немного не так. По результатам каждого этапа интервью пишет отчёт, в котором указывает, что спрашивал, что по его мнению сильно, что слабо. Следующий интервьюер это видит. Ну или должен видеть, по крайней мере. Возможно ваши решения не удовлетворил первого, второй решил перепроверить. Ответ на вопрос, на который на предыдущем этапе ответа не было, это однозначно плюс, значит человек заморочился и узнал для себя что-то новое.
P.S. Был в, привлекался, не разраб, уже нет :)
Я бы лучше предложил интервьюеру партейку в шахматы
Я как бы и не писал, что умею в алгоритмы. Субъективно оцениваю себя как алгоритмэна на 3 из 5, вон все решения привёл как есть, с ошибками, чтобы не думали, будто я гений какой. Но мне кажется, 1-2 интервью достаточно, чтобы это понять, да и вообще я немного другие скиллы планировал демонстрировать.
Это как устраиваться шеф-поваром: если попросят нарезать хлеб пару раз, я в принципе не против (хотя хлеб всегда уже нарезанный приезжает), но когда меня просят это сделать раз 10, я открываю хабр.
Много интервью делаются для объективности. У нас в гугле проходят 3-4 алгоритмических интервью, отчеты интервьюверы посылают комитету, который все взвешивает и принимает, по задумке, наиболее объективное решение. Комитет не видел кандидата и не знает ни имени, ни пола, ни возраста. Если какой-то отчет содержит намеки на пристрастность интервьювера, то он выбрасывается из рассмотрения.
Вот и получается, что проводят так много интервью.
[1, 2, 3]
[4, 2, 1]
[1, 2]
res = list(set(n).intersection(set(m)))
# set(n) + set(m) +
O(n) + O(m) + O(m) = O(n) + 2 * O(m)
[1, 2, 3, 2, 0]
[5, 1, 2, 7, 3, 2]
[1, 2, 2, 3]
from collections import defaultdict
d1 = defaultdict(int)
d2 = defaultdict(int)
for elem in a1:
d1[elem] += 1
for elem in a2:
d2[elem] += 1
result = []
for v2, count2 in d2.items():
count1 = d1.get(v2)
if count1 is None:
continue
for _ in range(min(count1, count2)):
result.append(v2)
####
n = 15
"""
1 0 1 0 1 0 1 0 # 3 || 8 = 2 ^ 3
1 0 1 0 # 2 || 4 = 2 ^ 2
1 0 # 1 || 2 = 2 ^ 1
1 # 0
"""
elements_in_top_row = (n + 1) // 2
2 ** 3 = elements_in_top_row
2 ** y == elements_in_top_row
y == log2(elements_in_top_row)
#################
O(log n) 
А какой смысл был бы в специальной структуре для поиска, если бы поиск в ней занимал столько же времени, что и поиск в массиве. Ну и построить дерево поиска, даже сбалансированное, довольно просто без всякого интернета. Вот оставлять его сбалансированным при вставке/удалении — это да, уже надо знать.
я человек ответственный, поэтому к интервью не готовлюсь. Это кстати я не шуткую, реально: если вы ответственный человек, ты вы, когда предстаёте перед компанией, отвечаете за то, что вы заявляете как ваши умения. Можно выучить типовые вопросы и даже казаться умнее и опытнее, чем есть, но по факту это переобучение на тестовых заданиях/вопросах.
слёту без гугления я его построить не могу, в работе это пригодилось мне примерно никогда
если бы поиск в ней занимал столько же времени, что и поиск в массиве
O(log(n)) — тот ответ, который я в итоге дал интервьюеру, и который он не принял.Вы выше в комментарии написали, что интервьюеру сказали, что O(n) в худшем случае, т.к. придётся пройтись по всем элементам, а для сбалансированного дерева это неправильно. Про O(log n) вы написали, что посмотрели в Википедии, и это уже правильно.
Я выдал что-то типа «ну в лучшем случае это O(1) потому что элемент попадётся первым, в худшем мы пройдёмся по всем элементам, поэтому это O(n), а в среднем там какой-то логарифм, сам не помню, как правильно считается». На что последовал ответ «ну вообще-то нет»
В худшем случае при поиске в бинарном дереве поиска надо проверить всего O(log n) элементов. Логарифм двоичный.
Собственно, в этом и смысл двоичного дерева поиска — худший случай поиска O(log n). А основная проблема — поддержание инварианта при вставках и удалениях.
Кстати, как вы наверно догадываетесь, есть большая разница между решением, написанным в обычной рабочей атмосфере, и решением, написанным на собеседовании в яндекс.блокнотике с интервьюером на связи и ограничением по времени.
Найс оправдания)
Самое забавное что сам месяц назад проходил в Яндекс собеседование на позицию middle c++. Ни одного вопроса по c++, все алгоритмы и задачи с которыми я справился. На самом последнем собеседовании джавист из Яндекса вообще учил меня shared_ptr писать) в общем я прошел все кейсы, а после общения с тим лидом получил через пару минут отказ. Оказалось что со мной общается внешний рекрутер, которая по цепочке из n людей общается с Яндекс рекрутером и перепутала результаты. В итоге Яндекс звонил мне и извинялся, однако потом сказали что кейсы я все равно провалил из за пары мелких багов в задачах, а мой вопрос "как я дошел до беседы с лидом" так и остался без ответа)
Это какие-то алгодрочеры ))
У меня знакомый работал в яндексе на позиции js разработчика… на собеседование он решал кучу алгоритмических задач… а на работе… рисовал кнопочки…
Спрашивается… яндекс, ну нафига ?)
В моём случае… эта длинная цепочка HR… калапснула… и в результате почти месяц не могли назначить собеседование… Когда наконец-то назначили… собеседующмй меня человек опоздал на 20 минут !
Ну, какбы, пишу я, bin и count. Никакой стандартной библиотеки, никаких импортов, в питоне это считай О(1).Первая ссылка в гугле утверждает, что bin — это конвертация числа в строку с его двоичным представлением. Итого Ваше решение переводит число в строку (под которую надо еще память выделить), и в ней считает количество символов '0'. Надеюсь, не нужно объяснять почему это решение не является ни лучшим, ни эталонным, ни вообще адекватным.
Это все что бы ты ценил что тебе дали работу в яндэксе и потом не ныл что тебе мало платят и много переработок, а думал что попал в святое место где решаешь уникальные задачи и вообще теперь ты особенный и это самое главное. :)
p.s.
"после того как компания решила нанять сеньор питон разраба за 200к" — это что сейчас такие рейты в РФ, расскажите кто в курсе?
Процесс ради процесса, наверное, тоже интересно…
Но почему после статьи захотелось уменьшить свой портфель с акциями Yndx
Я в прошлом месяце на js в маркет до финала дошел, но в конце туннеля вдруг выяснилось, что я реактом не владею в бою. Все, две недели "коту под хвост". Но кодинга/алгоритмов было всего 2 "собеседования", плюс одно на софт-скиллы (как я понял), плюс одно с командами (было похоже на ярмарку вакансий, где я больше слушал).
Именно… но вот после написала рекрутер, что "бизнес развивается настолько быстро, что меня без практического реакта никто не готов взять". Я, в принципе, не против, что не подошёл или не понравился, но за две недели мог бы уже лобать что-то, при том, что одна команда вообще внутреннюю срм пишет, в которой "ближайшая важная задача" сделать удобный календарик для выбора дат)
Я очень хотел попасть, чтобы бустануть карьеру. Это при том, что я не js-ник, но много читаю, практического опыта не так много. Я был немного удивлён, что вообще дошёл до финала, но конец все же расстроил.
"Испарился" типа совсем не ответили или что сказали?
Я, кстати, аж прошлым летом (или даже весной в кинопоиск сначала) прошёл самый первый этап, но тогда отказался продолжать, потому что удаленки ещё не было.
Что-то Яндекс отстаёт. Сейчас модно как Амазон — 70 процентов про leadership вопросов задавать. Бомбить от этого можно сколько угодно, но если хочешь работать то приходится учить как проходить собесы
Мне казалось, что зашквар с тестами, задачами, кодингом уже динозавры юзают. Ан, нет. Был повергнут в шок про 5 часов собеседований. Конечно, понимаю, что лучше потратить 5 часов рекрутёра, чем 3 месяца испытательного срока и искать заново. Но камон-хамон! 5 часов Карл! Час, ну край два! Испыталка покажет! Гоу ко мне, ребята! Пишите в личку. Ищу.
Согласен с тем, что много собеседований на алгоритмы — это неправильно.
Не согласен с тем, что сложность в реальной жизни не пригождается. Мне не раз приходилось переделывать места, где кто-то написал квадратичный алгоритм, а потом в специфических условиях всё тормозило и пользователи жаловались. Если бы человек сразу думал, какие максимальные реальные входные данные бывают и какая сложность у того, что он написал, пользователь бы не страдал. Встречается и такое, что n log(n) — медленно, и надо n, но редко.
И отсутствие знания сложности сортировки для меня означает, что подпускать человека к написанию кода, который будет работать на больших данных, рановато.
Я удивлён тому, что для приведённых решений вас не спросили, можно ли быстрее, т.к. есть куда улучшать.
Ну наверно таки да, знать полезно, особенно если в планах большими данными ворочать (хотя для этого я использовал бы какой-нибудь numpy или что-нибудь ещё, написанное на сях, раз уж на то пошло, а меня тут просят оптимизировать на голом питоне). Но в реале я никогда не ловил себя за подсчитываением O(n) после написания функции :) Там скорее чуйка какая-то: я примерно представляю, какие вызовы функций дорогие, я напрягаюсь, если вижу вложенные циклы, ну и прикидываю, как сильно будет грустить БД после моих запросов.
Согласен с тем, что много собеседований на алгоритмы — это неправильно.
Много интервью — это не потому что FAANG так важны алгоритмы, а для объективности.
Несколько разных интервьюверов пишут отчеты, потом (по крайней мере в гугле точно так) целый отдельный комитет по найму рассматривает отчеты и решает. Если кандидат затупил на одном интервью, волновался, а все остальные прошел на отлично — с большой вероятностью его наймут. Если один интервьювер явно офигел от внешнего вида кандидата и предвзято писал отчет, это еще не приговор.
В яндексе явно читали кривой перевод про собесы какогонить фейсбука. Половину не поняли, половину выкинули от лени, а образовавшиеся пустоты заполнили чем умеет их персонал — абстрактными задачами из местного репозитория. И правда, абсурд. В общем, и правда не зря игнорирую рекрутеров якитории ))
вы забыли галочку снять "установить дополнительные вопросы"
Полный провал разведки. Каждый раз сюрприз от несовпадение ожидания с реальностью. Зачем же так? Это же не рога и копыта, о том что ожидать можно узнать заранее из многих источников.
Про то зачем нужны алгоритмические задачки и почему у некоторых компания это работает Гэйл Лакманн Макдауэлл написала целую главу в книге. Посмотрите на досуге.
В это плане Яндекс играет в открытую, по своим правилам. Тут либо соглашаться, либо жаловаться.
Позволю себе добавить и свой вывод из вашей истории.
c = [elem for elem in a if elem in b]Хуже на данный момент только Озон особенно для Golang разработчиков.А можно подробнее?
Вопрос к Яндексоидам: на вскидку, как много людей устраивается в Яндекс как трамплин на запад?
По LinkedIn тысячи бывших сотрудников Яндекса переехало заграницу. С учетом что большинство людей не может переехать — не могут бросить родителей/друзья тут/патриоты в хорошем смысле слова/не знают английский (самый популярный вариант) — для относительно небольшой компании цифры огромные.
Возможно, компания что-то делает для удержания, есть ли какая-то статегия?
Как потенциальному кандидату такая огромная текучка сотрудников (в том числе ключевых — серьезный red flag.
У Mail.ru Group разработчиков поменьше, но зарубеж укатило в разы меньше % (по linkedin). Про "не самых глупых" — пройти собес на западе это 90% про подготовку: английский, софт-скилы, дизайн, алгоритмы. Если рекрутер фаанга напишет условному senior staff software engineer в Я, то 99% последний откажется по причинам выше (не может бросить родителей/друзья тут/патриот в хорошем смысле слова/не знает английский/...). А скорей всего и не напишет, потому что наш разработчик еще аккаунт не завел на LinkedIn. А зачем? Дачу в подмосковье построил, ипотеку выплатил, дети в школе устроены.
Вопрос именно что Яндекс многие специально используют как трамплин. Кроме опытных ребят, на LinkedIn сотни людей с 1-2 года работы в Яндексе и потом, внезапно, Facebook/Google/etc
У Mail.ru Group разработчиков поменьше, но зарубеж укатило в разы меньше % (по linkedin). Про "не самых глупых" — пройти собес на западе это 90% про подготовку: английский, софт-скилы, дизайн, алгоритмы
Как нас учили на курсе АОД в универе — корреляция не всегда означает казуацию. Например, может быть объясненеи что разрабочтики мейлру на западе просто неинтересны, а вот яндексоидов хантят с удовольствием. Или что мейлрушники все в москве живут (оттуда уезжать меньше причин), а яндекс больше рассеян по стране, и из условной воркуты они с куда большим удовольствием уезжают… Или ещё десятки возможных объяснений, это первые что в голову пришли
Согласен, но я немного про другое. Вы видимо не в курсе как это работает сейчас.
"На западе просто неинтересны" — заведите аккаунт в linkedin, заполните профиль и если у вас есть несколько лет опыта и ключевые слова — вам напишут из всех крупных компаний. При этом вы можете работать в неизвестном стратапе из 10 человек. Яндекс, как и Меил, отстуствуют на западе, о них никто не знает (почти).
Устроиться в крупную компанию — это не про опыт (опыт нужен только чтобы попасть на собеседование), это про подготовку к интервью. Яндекс выглядит как идеальное место для подготовки. Прошаренные рекрутеры по идее знают про это и работа в Я теоретически может упростить попадание на собеседование.
Ну я вот заполнил на линкедине резюме, опыт 8 лет, только автоматический спам на 99% из российских компаний. И нвидия которые кажде 3 дня предлагает мне пойти к ним го или питон разработчиком, при том что у меня раст/C# описаны.
Ну такое.
Устроиться в крупную компанию — это не про опыт (опыт нужен только чтобы попасть на собеседование), это про подготовку к интервью. Яндекс выглядит как идеальное место для подготовки. Прошаренные рекрутеры по идее знают про это и работа в Я теоретически может упростить попадание на собеседование.
Для этого необязательно устраиваться в яндекс — можно порешать задачки на литкоде и пойти внезапно не в яндекс, а в какой-нибудь амазон
А как это тормознет умников? В лямбде пишется просто после прочтения FileInfo Progress.Report(p => p+1) и все
А тут такие простыни кода, что меня прямо в дрожь бросает. Прекрасный способ дать кандидату почувствовать себя ничтожеством.
Уже хочу у вас работать
Ну если умника не тормознёт настолько тонкий намёк, то баллов за тестовое задание он не получит.
Перед заданием я предупреждаю, что нежелателен уход метода в нирвану на неопределённое время без репорта.
Ну окей, если файлов много можно заменить на Directory.EnumerateFiles — оно работает лениво, на 100к файлах отработало без каких-либо проблем, первый файл был зарепорчен через 8мс после выполнения кода.
А это мы ещё не трогали потенциально возможное зацикливание папок через хардлинки (реальный кейс из продакшена) и другие прелести.
Ну это уже будет сложнее, да, но там в принципе сложности с тем "что есть файл". Ну и тут наверное стандартный обходник не подойдет. Но на изначальных условиях да даже с миллионами файлов — проблем нет.
Кроме того, если я чему и научился на текущем проекте (мы бэкапами занимаемся), так это правилу «ищешь перерасход памяти — ищи подвисший список путей». 9 из 10 OutOfMemoryException — это неудачно сохранённая в памяти коллекция абсолютных путей.
Какая-то ваша специфика. У меня например оомов не так много, но почти все из них были вызваны "накапливали логи быстрее чем успевали их записывать". В другой раз в экспрешн случайно попала ссылка на репозиторий хранящий DataContext — в итоге кэши ормки пухли и никогда не очищались. Ну и всякие такие приколы.
Если много файлов то просто не надо получать их все — рецепт в общем-то простой. Если же там хардлинки и все остальное — то тут просто видимо пишется своя библиотечная функция для того же самого, которая работает так как нам нужно, ну и код остается тем же, просто вместо Directory вызываем MySuperDuperHelper.
Ящитаю, что статья закончилась именно там, где должна была закончиться. Она ведь не про то, как какой-то чувак прошёл/не прошёл в Яндекс и что с ним стало потом, а про доширак (и прочее). Но если вам так интересно, то вот апдейт:
1) Меня завернули после 4 собеседования. Никаких особых комментов, почему, не было — ну типа решал алгоритмы не очень. Даже если фидбек был, он же проходит через тор, и я не знаю, сколько инфы там теряется. Я не верю в теорию заговора и считаю, что действительно решал алгоритмы так себе (да вы и сами всё видели) — особенно после того, как посмотрел ради любопытства видео Яндекса про собеседования и какие критерии там смотрят. Я со своей логикой там вообще не в кассу.
2) После выхода статьи со мной связался Яндекс и предложил стать СЕО и сообщил вот что:
Да ладно, вы правда поверили, что Яндексу не плевать? Никто мне не писал, рекрутер вообще не в теме.
3) Яндекс.Музыка, Почта и другие сервисы у меня ещё работают
Возможно сениоры сами виноваты что идут зачем-то на собес, хотя на каждом заборе написано "здесь вам не рады, мы нанимаем джунов-мидлов" :shrug:
В больших ИТ-компаниях нет столько задач: у Амазона всего 3-4 за весь день, у других больше, но не 10+ точно. Так же если есть хотя бы пара лет опыта всегда будет раунд на дизайн систем.
Эластик и любые другие похожие системы нужны для больших данных. Добавьте в любую задачку условие что данных пара терабайт и они не влазят в память. И сразу мапредьюсы с разнообразными базами полезут везде.
a = [1,2,3,2,0]
b = [5,1,2,7,3,2]
res = [r[0] for r in [[y for y in b if y == x] for x in a] if len(r) > 0]
print(res)
O(n^2). Слишком медленно.
У автора там тоже
И автор не прошел интервью
Просто хотел более выразительный
Более выразительный? Это больше похоже на попытку в code golf — где надо решить задачу наименьшим количеством символов. Как этот однострочник более выразителен, чем 2 вложенных цикла — я не понимаю.
Этот код менее читаем, да еще и работает медленнее даже тупого решения с 2 циклами. Потому что выделяет память под копии и не останавливается при нахождении вхождения.
За алгоритмами будущее. Тот кто быстрее будет предоставлять информацию пользователю, тот будет выигрывать всегда
Ask forgiveness not permission
В рамках кода, что в статье, на больших входных данных эксепшнов ожидается гораздо меньше, чем было бы проверок на наличие предыдущих элеменов. Так что выгоднее с ними, но, вообще говоря, решение само по себе не очень :)
Крутая статья, увидел себя со стороны. У меня последняя, 5-я встреча, тоже состояла из решения алогритмических задач. Дело было до пандемии, этапы с 2 по 5 шли оффлайн. Но все время было ощущение, что собеседование != реальные задачи на работе и такой упор на алогритмы сделан, чтобы как-то можно было отсеять нескольких из большого количества соискателей.
Если честно, после этого думал натренировать алогритмы и ехать, но после прочтения статьи как у них происходит повышение (не помню ссылку) подумал, что мы с Яндексом можем хорошо сосуществовать раздельно.
чувак! то есть я не один такой? два года назад я прошёл через вот это же вот, потом мне сказали что я плохой, негодный сеньор-программист. и я впал в такую депрессию из которой не могу выйти до сих пор. мне почти 40 лет и это первый раз, после экзамена по термодинамике на втором семестре физкультурного техникума, когда я ощутил себя тупым ничтожеством.
Я вам больше скажу. Не редки ситуации, когда уже сотрудники Яндекса уходят из надоевшего проекта наружу, а не ротируются в другую команду внутри, из-за того, что при ротации (по крайней мере при смене бизнес-юнита) тоже надо пройти почти такой же набор собесов, а они не хотят тратить на это столько сил и/или не уверены, что смогут их успешно пройти.
А что именно является интеллектуальной собственностью? Если формулировка задания, то не достаточно ли переформулировать задачу своими словами? И можно ли эту собственность оспорить, если найти соответствующую задачу в каком-нибудь задачнике, откуда её скорее всего взяли?
Ужас, яндекс боиться, что их суппер ситема найма сломается если кто-то прочитает ГДЗ и узнает ответы.
Чем закончилась в итоге история с Яндексом? Сделали офер, отказали, отказался?
Да... Есть у HR яндекса некоторые странности...
У меня сложилось впечатление, если честно, что тестовые задачи не на алгоритмы и языки, а на "знание внутренних корпоративных стандартов яндекса методом телепатии".
В принципе - это частая болезнь. Но видел пару раз забавные результаты.
Сегодня проходил собес. Первую задачу решил с грехом пополам, на вторую не осталось времени. Автор статьи в чём-то прав, конечно, но перегибает. Своими алгоритмическими собесами Яндекс отфильтровывает людей умеющих думать, а не только действовать по шаблону. Другое дело, что в реальной жизни это требуется редко. Но, как бы это сформулировать корректно, решать алгоритмические задачи требуется редко, а вот думать - часто. :) У нас в школе висел плакатик - "Математика - это гимнастика ума". Кажется Лобачевский автор, но могу спутать. Тут что-то типа этого. Сейчас нагуглить можно всё. Но, чтобы это правильно применить надо уметь думать. Так что формат собесов Яндекса вполне оправдан ИМХО. Хоть я и, кажется, не прошёл :)

Собеседование в Яндекс: театр абсурда :/