
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Интроинспекция объектов параметров поддерживается ли IDE?
А то вот тут ничерта не понятно
// Удаление пользователя с `id = 2`
await User.destroy({
where: {
userId: 2,
},
})
// Удаление всех пользователей
await User.destroy({
truncate: true,
})Почему метод удаления принимает два объекта разной структуры?
Может ли разработчик понять какие вообще структуры примет метод не перечитывая мануалы?
Большинство DML запросов принимает параметр where. Чтобы это использовать достаточно раз прочитать мануал.
Второй пример показывает как можно очистить всю таблицу не операцией DELETE FROM а операцией TRUNCATE. Для этого в операции destroy есть параметр truncate.
Почему же разной?
Одной, с примерно таким типом: Partial<DestroyOptions>
Спасибо за уточнение.
Т.е интроинспекция будет работать и правильно мне подскажет варианты.
Но возник вопрос, уже скорее не относящийся к самому sequelize.
Я правильно понимаю, что в качестве параметра подобного метода подойдёт объект любого типа, при наличии у него хотя бы одного совпадающего с типом свойства?
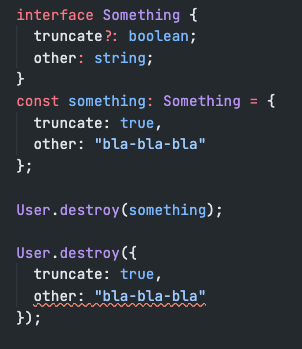
Т.е в качестве параметра зайдёт и такое?
interface Something {
truncate?: boolean;
other: string;
}
const something: Something = {
truncate: true,
other: "bla-bla-bla"
};
await User.destroy(something) Если писать именно так, то да, зайдёт. Но обычно передают сразу объект и там всё правильно отработает
$criteria = new Criteria(['x' => 1]);
$criteria2 = new Criteria(['y' => 'bla-bla']);
$newCriteria = $criteria->and($criteria2);
$result = $db->find($newCriteria);
Вот скажите. Зачем весь этот огород?! Ведь в итоге разрабоичику в любом случае надо изучать sql чтобы, даже, сделать простую выборку в этом вашем колхозе. И когда разработчик его освоит то выкинет этот orm куда нибудь.
Ничего, кроме потерянного времени и кучи костылей..интересно, какая уже по счету попытка скрестить ежа и ужа..
Большинство апи запросов это простые выборки. Плюс вокруг этого можно построить что то типо генерации роутов. Или имплементация json-api ( https://github.com/ringcentral/nestjs-json-api) с валидацией и опирировать только сущностями.
У меня возник аналогичный вопрос. Намного проще и куда более полезно просто подучить SQL.
Желаю вам удачи при попытке например переименовать поле в случае использования чистого sql)
За такое надо по рукам бить линейкой. Понаплодилось неучей. По этому все так и работает. Проектировка семантической модели и ее реализация в физический уровень это не типрвая рутина. Это знание и понимание как устроена на физическом и логическом уровне целевая субд, знание разработанной архитектуры модели данных бд, знание бизнес процессов и их взаимосвязей, интеграционных правил и их взаимосвязей. Понимание теории реляционной бд, как работаеи, почему так, а не иначе, что такое домены, ограничения целостности и потенциальные ключи, индексы, хранимые процедуры, триггеры, сиквенсы и как они могут и дрлжны быть связаны в рамках реализации модели данных. Как ращгрвничить права на данные для групп пользователей. Как их изменения будут влиять на логику и производительность. Этими вещами должны заниматься не условные Васи Пупкины, а арзитекторы (грамотные, опытные, испольующие мозг и совершенно другой инструментарий люди) Но зачем?! Зачем все это учить и знать? Зачем изучить опыт попыток "программировать без программтрования", "создавать бд без знаний"... Ведь это старые, глупости. Вот же! Новая, модная "фишка".. Го говнокодить и писать поделки.
Не бывает "чистоно" или "грязного" sql. Это - стандарт. Все это (и очень многое другое) делается алминистратором БД с помощью DDL. А вот как в этой вашей поделке запросом сделать иераохический вывод? Или использовать оконные функции или хинты?
А где-то шла речь что sql знать не надо? Надо конечно, но в большинстве приложений, руками sql запрос нужно писать только в очень редких случаях, ибо там обычно простая выборка данных, либо простой апдейт, или джойн двух таблиц. Тут не нужны ни знания рокет саенса, ни сырой sql, с этом вполне справился orm.
Всему своё место и время. Если джуну в его коде надо что то из базы прочитать, то зачем отвлекать на написание этого кусочка программиста СУБД ?
Разработка это прежде всего производство и чем ниже требования к квалификации тем больше сотрудников можно привлеч к этому производству. Любые библиотеки снижающие требования к квалификации помогаю производству.
Ни кто не запрещает пользоваться сырыми запросами через эту библиотеку или любую другую.
Вы свободны в своём выборе. Вам дают инструмент, а вы можете им не пользоваться, кто то другойосвоиться с ним и ему это будет полезным.
Вы на столько погрузились в свой выдуманный мир с джунами, миддлами, и прочими драконами блэкджеками и прочим, что начали распределять, кому и какие знания нужны в каждый момент вреиени. Это полный бред. Себя вы считаете кем в этой иерархии? Что значит джуну надо выбрать? Вот как вы представляете, например, начинающего водителя? Ему надо сразу знать все правила и обладвть всеми навыками вождения или, например, осуществлять только поворот направо и ездить только по двухполосной проезжей части? Учить и учиться надо всему. Если человека допускают до проекта в котором участвует БД он должен понимать как с ней работать. Как сделать запрос, как хранятся данные и т.д и т.п иначе, получать будем мы то, что вокруг нас. И никогда не выберемся их текущкго положения вещей, когда куча неспециалистов (исполнителей и подчиненнвх) пытается решить инженерную задачу
Нет, не надо понимать, надо уметь работать с чёрными ящиками, какая разница из СУБД получаем данные или данные нам вернёт метод какого то класса ?
Если нам надо что то спроектировать, тогда, да, в таком случае надо понимать в вопросе, а если уже спроектирована БД ? нам просто надо настроить работу приложения с ней, зачем нам вникать ?
Сделали описание структуры для ОРМ, и пользуемся ОРМом, возможно это описание уже кто то сделал.
Это называется специализация, кто то СУБД проектирует, кто то АПИ пишет, кто то формочки рисует..
Имхо после использования typeorm, Sequelize кажется каким то громоздким с точки срезения кода. Использовать Sequelize без обвертки в тайпскрипт достаточно неудобно, а последний раз когда пытался использовать Sequelize и тайпскрипт вылезали ошибки типов, возможно сейчас этого уже нет.
Раньше типизация была выполнена сообществом в виде отдельного пакета, и было всё печально, но начиная с 5 версии sequelize поддерживает ts из коробки. Из неудобств, желательно при описании модели описывать типы два раза, и потом ещё описывать саму таблицу. Что выглядит как-то так:
interface IRantypeAttributes {
id: number;
title: string;
alias: string;
}
class Rantype extends Model<IRantypeAttributes, IRantypeAttributes> {
id!: number;
title!: string;
alias!: string;
}
Rantype.init(
{
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true,
},
title: {
type: DataTypes.STRING,
allowNull: false,
},
alias: {
type: DataTypes.STRING,
allowNull: false,
},
},
{
tableName: "rantype",
sequelize,
},
);Но есть например sequelizejs-decorators который решает и эту проблему
Хороший инструмент. Сила sequelize в scopes, без них составление запросов становится очень громоздким и порядком раздражает. Но есть и более существенные минусы такие как в первую очередь невозможность получить строку запроса без его выполнения, этом связано с тем что для некоторых условий sequelize сам дорезает выборку, что в свою очередь приводит к проблемам если запрос содержит subquery. Так же в силу той же причины sequelize не может отдать stream. На стандартных проэктах это не критично. Но если надо сделать что то действительно сложное приходится искать обходные пути. Но это везде так, ни один инструмент полностью не может удовлетворить запросы разработчика. Но для этих проблем уже давно существуют issue и PRы для из решения но разработчики упорно их игнорируют.
Post.findAll({
where: {
[Op.or]: [
sequelize.where(sequelize.fn('char_length', sequelize.col('content')), 7),
{
content: {
[Op.like]: 'Hello%'
}
},
{
[Op.and]: [
{ status: 'draft' },
sequelize.where(sequelize.fn('char_length', sequelize.col('content')), {
[Op.gt]: 10
})
]
}
]
}
});
SELECT *
FROM "posts" AS "post"
WHERE (
char_length("content") = 7
OR
"post"."content" LIKE 'Hello%'
OR (
"post"."status" = 'draft'
AND
char_length("content") > 10
)
)
{
[Op.or]: [
{
title: {
[Op.like]: 'Boat%'
}
},
{
description: {
[Op.like]: '%boat%'
}
}
]
}
// title LIKE 'Boat%' OR description LIKE '%boat%'
особо хочу отметить кривой интерфейс операторов, когда сначала идёт оператор, а потом значения, мозг сломать можно при чтении


Идеальный инструмент для работы с СУБД без SQL для Node.js или Все, что вы хотели знать о Sequelize. Часть 1