
В чем проблема рекуррентных нейронок?
Задачи машинного перевода, языкового конструирования или распознавания голоса — когда-то все они решались при помощи RNN, так называемых, рекуррентных нейронных сетей, которые упрощали, сводили огромное число параметров к конечному результату и условному прогнозу.
Отличие RNN от обычной нейронки со скрытыми слоями и output/input — наличие временной компоненты и памяти.

Принцип работы рекуррентных нейронных сетей основан на идее обратной связи, где выход одного шага сети используется как часть входа на следующем шаге. Информация из предыдущих шагов последовательности сохраняется и передается на следующие шаги для анализа и прогнозирования. Именно поэтому RNN доминировали в решении задач, связанных с языком.
В этом смысл названия. Рекурсия. Мы постепенно переходим от временного шага t и входных данных к новому скрытому состоянию и так постепенно накапливаем данные. Так и учитывается контекст. Читая книгу, мы запоминаем детали с предыдущих страниц, а в конце неожиданно начинаем сами дописывать прочитанный нами "детектив"...
Создатели RNN-щики попросту учли наш способ чтения — он последовательный. Слово за словом, состояния за состояниями, данные за данными. Обрабатывая токен или слово, ИИ запоминает "информацию" с токена и передает ее дальше для использования при обработке следующего слова/токена. У каждого слоя нейронки появляется своеобразная "память".
Помимо связей между слоями, элемент получает связь с самим с собой, возвращается к себе, передавая информацию с текущего момента времени t1 в следующий момент времени t2.
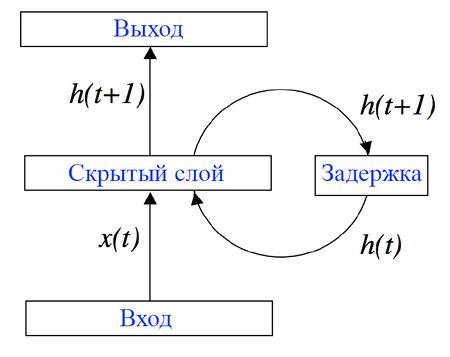
Возьмем за пример предложение: “I love dogs”. Сначала рекуррентная нейронка пронесет через себя I, которую можно представить в виде вектора, запомнит некоторые данные и использует их при последующей последовательной обработке love.
Формулы рекуррентной сети немного сложнее:
Обучаемая матрица в конкретный момент времени t умножается на входные данные. Все это суммируется с умноженной обучаемой матрицей и скрытым вектором на предыдущем шаге (t-1). Все это безусловно прогоняется через функцию активации.
Новое скрытое состояние умножается на обучаемую матрицу и готово. Наш выход yt!
Вектор скрытого состояния — это и есть "память" слоя.
Мы получили новое скрытое состояние, приправив обработанное старое дополнительными входными данными. Всем понятно, что такие рекуррентные нейросети из-за своего принципа постепенного накопления данных работают дольше. Представьте себе нейросеть, которая прогоняется через тысячи слов и предложений…

Так как нам учитывать все эти злосчастные скрытые состояния, а не только одно последнее? Вот для этого в 2017 году энтузиасты и разработали механизм "Attention".
Механизм внимания: RNN + attention
В нужные моменты мы обращаем внимания на нужные слова. А не распределяем токены один к одному. Очевидно, что, например, последовательность слов в разных языках разная. А одни слова чаще употребляются с другими. Принцип Attention, который был разработан ученым-энтузиастами, призван как раз распределять веса или значимость токенов/слов и создавать эффект “контекста”.
Принцип максимально приближен к имитации семантических цепочек.
Например, плитку мы упоминаем в архитектурном, строительном или интерьерном контексте. Для любого слова в языке есть набор постоянно употребляемых в контексте слов. Говорим "выстрели", скорее, из ружья или пистолета... Говорим “включи” чаще ПК, телефон или "в розетку".
Млекопитающее-кит-планктон-вода...
Стул-стол-гарнитур-мебель-вилка...
Мы можем распределить "значимость" одних слов для других. Стулья бывают разные: на улице, на кухне, в банкетном зале, в офисе... Необязательно стул как-то должен быть связан с гарнитуром или вилкой. А вот со столом...
Именно поэтому предпочтительнее в тексте раскидывать значимость слов контекстуально.
Легче понятие "attention" описать концепцией сущности вещей. Вот есть у нас автомобиль, что прежде всего делает автомобиль автомобилем? Безусловно — колеса. Колеса важнее всех остальных элементов.

Attention (внимание) в машинном обучении — это механизм, который позволяет модели динамически выбирать, на какие части входных данных сосредоточить своё внимание при выполнении задачи.
Механизм Attention используется для вычисления весового коэффициента для каждого слова во входной последовательности на основе его важности в контексте текущего запроса или задачи. Эти весовые коэффициенты затем используются для взвешенного суммирования представлений всех слов, чтобы получить контекстуализированное представление.
Матрица должна обучаться при тренировке. Для каждого токена она будет считать вектор и распределять места по месту в предложении. Выглядит это примерно так:

Механизм Attention задает матрицу весов или тех самых семантические цепей, где определяется важность одних слов для других. Если открыть обычный google-переводчик, мы увидим целый список переводов одного слова по степени их популярности или важности.
При работе типичных кодеров/декодеров, например, вариационного автокодировщика результаты с применением дополнительного слоя Attention повышаются, значительно. “Внимание” раскрывает вероятностный подход нейросети.
Какая вероятность, что перевод слова sex – любовь, а не пол человека? Но полноценно вся мощь этого механизма разработана в трансформерах.
Attention заменяет каждый эмбеддинг токена/слова на эмбеддинг, содержащий информацию о соседних токенах, вместо использования одинакового эмбеддинга для каждого токена вне зависимости от контекста. Если бы мы кодировали слова по принципу словаря, получили бы просто “мешок слов”, который никак с друг другом не связан.
Трансформеры или сдвиг парадигмы в NLP
Теперь вместо рекуррентных нейронок пришло время трансформеров. Они учитывали контекст избирательно и формировали своеобразные матрицы весов для слов. Теперь процесс обработки естественного языка предполагал не последовательной накопления нагромождения данных, а получения избирательного контекста отдельных слов и их употреблений…
Архитектура трансформера состоит из энкодера и декодера.
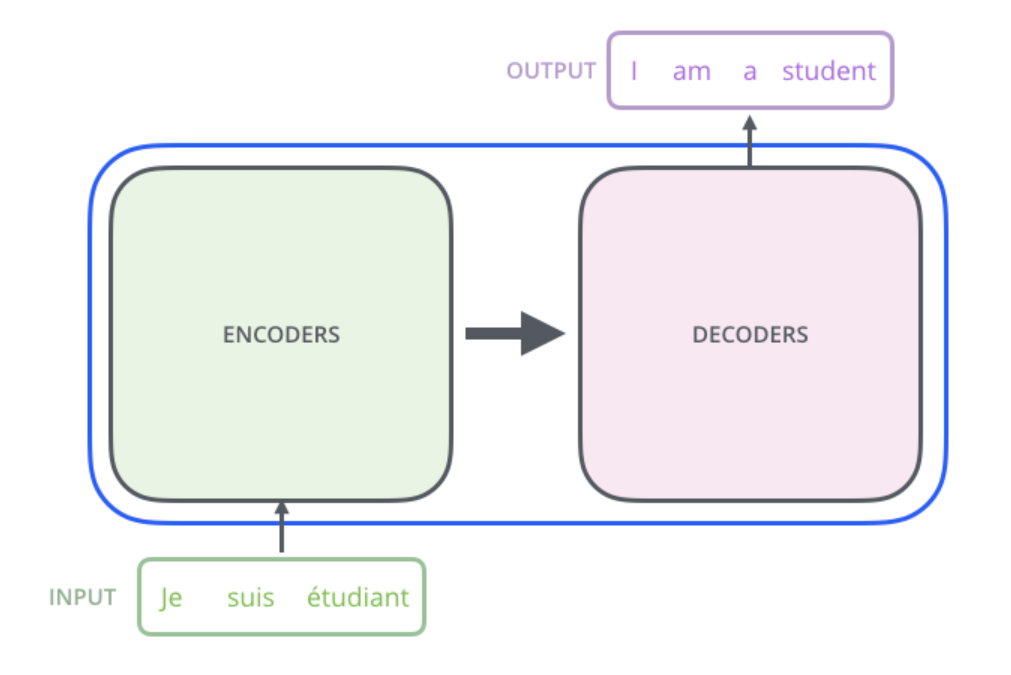
Энкодер состоит из слоев, как и декодер.
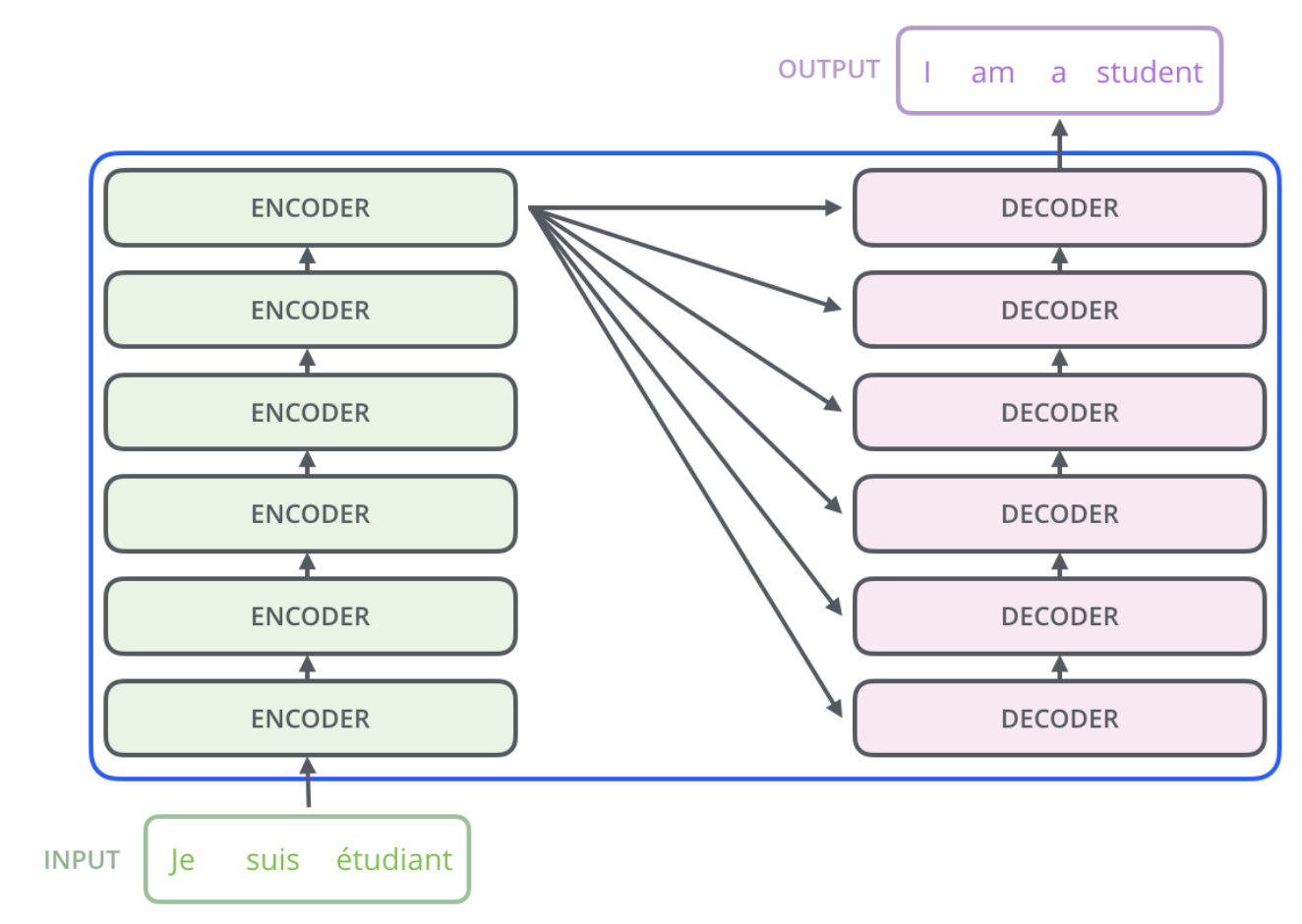
Каждый из слоев состоит из блоков: self-attention и полносвязной нейронной сети (обычная нейронка, где одни слои связаны со всеми последующими слоями).

Self-attention — главный костяк работы трансформера. Давайте представим, что у нас есть предложение "Кот ловит мышь". Каждое слово в этом предложении (кот, ловит, мышь) представлено вектором. Self-Attention — это механизм, который позволяет модели фокусироваться на важных словах в предложении и определять, какие слова имеют большее значение для понимания смысла всего предложения.
Для каждого слова в предложении мы создаем три вектора: запрос (Query), ключ (Key) и значение (Value). Затем мы используем эти векторы, чтобы определить, насколько каждое слово важно для каждого другого слова в предложении. Естественно, что подобное перемножение не работает простым образом.
Главная цель self-attention затащить в нейронную сеть максимальное число векторных представлений, которые бы обрисовывали значимость отдельных слов в разных контекстах.
Когда мы говорим "Кот ловит мышь", модель может сосредоточиться на слове "Кот", чтобы понять, о ком идет речь. Для этого модель вычисляет, насколько слово "Кот" важно для каждого другого слова в предложении. Если важно, она больше обращает на него внимание.

Таким образом, благодаря механизму Self-Attention, модель может динамически определять, какие слова в предложении наиболее значимы, учитывая их контекст и взаимосвязь друг с другом. В результате работы механизма мы получаем attention-score.
Если провести такую операцию своеобразного эмбендинга кода, а именно восемь раз и получить на выходе новые матрицы с весами мы получим целый набор весов для разных контекстов, а это еще больше информации! Чем больше информации – тем лучше.

ChatGPT обучается на больших наборах текстовых данных, где модель пытается минимизировать потери (например, перекрестную энтропию) между сгенерированным текстом и правильными ответами. В процессе обучения модель настраивает веса внутри блоков трансформера, чтобы улучшить качество генерации текста. И вот мы получаем мощнейшую нейронку с миллиардами параметров и вполне приемлемым текстом для пользователей.
Какие трансформеры сегодня есть помимо GPT?
BERT (Bidirectional Encoder Representations from Transformers): Разработанный в Google, BERT - это модель трансформера, обученная на огромном корпусе текстовых данных для выполнения различных задач NLP, таких, как классификация текста, извлечение информации и вопросно-ответные системы.
T5 (Text-to-Text Transfer Transformer): Разработанный Google, T5 – универсальная модель трансформера, которая может решать широкий спектр задач NLP, представленных в формате текст-к-тексту. Такой формат позволяет использовать единый обученный трансформер для различных задач, таких как перевод, классификация, генерация текста и многое другое.
XLNet. Этот подход, также разработанный Google, представляет собой расширение и улучшение модели трансформера BERT. XLNet использует перестановочный механизм предложений и предлагает улучшенное моделирование контекста и лучшее качество на различных задачах NLP.
RoBERTa (Robustly optimized BERT approach). Разработанный Facebook, RoBERTa – это улучшенная версия модели BERT, которая была обучена с использованием различных стратегий обучения, таких как динамическое маскирование и обучение на длинных последовательностях, что привело к улучшению качества на различных задачах NLP.

