
Прим. перев.: Автор этого материала — Cindy Sridharan, инженер из компании imgix, занимающаяся вопросами разработки API и, в частности, тестирования микросервисов. В этом материале она делится своим развёрнутым видением актуальных проблем в области распределённой трассировки, где, по её мнению, наблюдается недостаток по-настоящему эффективных инструментов для решения насущных задач.
[Иллюстрация заимствована из другого материала про распределенную трассировку.]
Считается, что распределенную трассировку сложно внедрять, да и отдача от нее в лучшем случае сомнительная. «Проблемность» трассировки объясняют множеством причин, при этом часто ссылаются на трудоемкость настройки каждого компонента системы для передачи соответствующих заголовков вместе с каждым запросом. Хотя эта проблема действительно имеет место, ее вовсе нельзя назвать непреодолимой. Она, кстати, не объясняет, почему разработчики не очень любят трассировку (даже уже функционирующую).
Главная трудность с распределенной трассировкой — это не сбор данных, не стандартизация форматов распространения и представления результатов и не определение того, когда, где и как производить выборку. Я вовсе не пытаюсь представить тривиальными эти «проблемы с усвояемостью» — в самом деле, существуют довольно значимые технические и (если мы рассматриваем по-настоящему Open Source'ные стандарты и протоколы) политические вызовы, которые необходимо преодолеть, чтобы данные проблемы можно было считать решенными.
Однако, если представить, что все эти проблемы решены, высока вероятность, что ничто существенно не изменится с точки зрения опыта конечного пользователя. Трассировка по-прежнему может не приносить практическую пользу в самых распространенных сценариях отладки — даже после того, как она развернута.
Распределенная трассировка включает в себя несколько разрозненных компонентов:
Множество разговоров о распределенной трассировке сводятся к тому, чтобы рассматривать ее как некую унарную операцию, единственной целью которой является помощь в полной диагностике системы. Во многом это связано с тем, как исторически формировались представления о распределенной трассировке. В записи в блоге, сделанной, когда открывались исходники Zipkin, упоминалось, что он [Zipkin] делает Twitter быстрее. Первые коммерческие предложения для трассировки также продвигались как инструменты APM.
Прим. перев.: Дабы дальнейший текст воспринимался лучше, определим два базовых термина согласно документации проекта OpenTracing:
Trace'ы содержат невероятно ценные данные, способные помочь в таких задачах, как: тестирование в production, проведение тестов аварийного восстановления, тестирование с внедрением ошибок и т.д. На самом деле некоторые компании уже используют трассировку для подобных целей. Начнем с того, что универсальная передача контекста имеет и другие применения помимо простого переноса span'ов в систему хранения:
Ни один из перечисленных выше вариантов не относится целиком к сценарию отладки, в ходе которого инженер пытается решить проблему, глядя на trace.
Когда дело все же доходит до сценария отладки, первичным интерфейсом остается диаграмма traceview (хотя некоторые также называют ее «диаграммой Ганта» или «каскадной диаграммой»). Под traceview я подразумеваю все span'ы и сопутствующие метаданные, которые вместе составляют trace. Каждая система трассировки с открытым исходным кодом, а также каждое коммерческое решение для трассировки предлагает основанный на traceview пользовательский интерфейс для визуализации, детализации и фильтрации trace'ов.
Проблема со всеми системами трассировки, с которыми мне довелось ознакомиться на данный момент, состоит в том, что итоговая визуализация (traceview) практически полностью отражает особенности процесса генерации trace'а. Даже когда предлагаются альтернативные визуализации: карты интенсивности (heatmap), топологии сервисов, гистограммы задержек (latency), — в конечном итоге они все равно сводятся к traceview.
В прошлом я сетовала на то, что большинство «инноваций» в области трассировки в отношении UI/UX, кажется, ограничиваются включением дополнительных метаданных в trace, вложением в них информации с высокой кардинальностью (high-cardinality) или предоставлением возможности детализировать конкретные span'ы или выполнять запросы меж- и внутри-trace. При этом traceview остается основным средством визуализации. Пока будет сохраняться подобное положение вещей, распределенная трассировка будет (в лучшем случае) занимать 4-е место в качестве отладочного инструмента, вслед за метриками, логами и stack trace'ами, а в худшем — окажется пустой потерей денег и времени.
Предназначение traceview — предоставлять полную картину передвижения отдельного запроса по всем компонентам распределенной системы, к которым он имеет отношение. Некоторые более продвинутые системы трассировки позволяют детализировать отдельные span'ы и просматривать разбивку по времени внутри одного процесса (когда span'ы имеют функциональные границы).
Базовой предпосылкой архитектуры микросервисов является идея о том, что организационная структура растет вместе с потребностями компании. Сторонники микросервисов утверждают, что распределение различных бизнес-задач по отдельным сервисам позволяет небольшим, автономным командам разработчиков контролировать весь жизненный цикл таких сервисов, давая им возможность независимым образом создавать, тестировать и развертывать эти сервисы. Однако недостатком подобного распределения является потеря информации о том, как каждый сервис взаимодействует с другими. В таких условиях распределенная трассировка претендует на роль незаменимого инструмента для отладки сложных взаимодействий между сервисами.
Если у вас действительно ошеломляюще сложная распределенная система, то ни один человек не способен удержать в голове ее полную картину. На самом деле разработка инструмента исходя из предположения, что это вообще возможно, является чем-то вроде антипаттерна (неэффективным и непродуктивным подходом). В идеале для отладки требуется инструмент, помогающий сузить зону поиска, чтобы инженеры могли сосредоточится на подмножестве измерений (сервисах/пользователях/хостах и т. п.), имеющих отношение к рассматриваемому сценарию проблемы. При выяснении причины сбоя инженеры не обязаны разбираться в том, что происходило во всех сервисах сразу, поскольку такое требование противоречило бы самой идее микросервисной архитектуры.
Однако traceview представляет собой именно это. Да, некоторые системы трассировки предлагают сжатые traceview, когда число span'ов в trace настолько велико, что их невозможно отобразить в рамках одной визуализации. Однако из-за большого объема информации, содержащейся даже в такой урезанной визуализации, инженеры все равно вынуждены «просеивать» ее, вручную сужая выборку до набора сервисов-источников проблем. Увы, на этом поприще машины значительно быстрее человека, менее подвержены ошибкам, а их результаты более повторяемы.
Еще одна причина, по которой я считаю метод traceview неправильным, связана с тем, что он плохо подходит для отладки на основе гипотез. В своей основе отладка — это итеративный процесс, начинающийся с гипотезы, за которой следуют проверка различных наблюдений и фактов, полученных от системы по разным векторам, выводы/обобщения и дальнейшая оценка истинности гипотезы.
Возможность быстро и дешево тестировать гипотезы и соответствующим образом улучшать ментальную модель является краеугольным камнем отладки. Любой отладочный инструмент должен быть интерактивным и сужать пространство поиска или, в случае ложного следа, позволять пользователю вернуться назад и сфокусироваться на другой области системы. Идеальный инструмент будет делать это с упреждением, сразу привлекая внимание пользователя к потенциально проблемным областям.
Увы, traceview нельзя назвать инструментом с интерактивным интерфейсом. Лучшее, на что можно надеяться при его использовании, — это обнаружить некий источник повышенных задержек и просмотреть всевозможные теги и логи, связанные с ним. Это не помогает инженеру выявить закономерности в трафике, такие как специфика распределения задержек, или обнаружить корреляции между различными измерениями. Обобщенный анализ trace'ов может помочь обойти некоторые из этих проблем. Действительно, имеются примеры успешного анализа с использованием машинного обучения по выявлению аномальных span'ов и идентификации подмножества тегов, которые могут быть связаны с аномальным поведением. Тем не менее, мне пока не встречались убедительные визуализации находок, сделанных с помощью машинного обучения или анализа данных, примененных к span'ам, которые бы значительно отличались от traceview или DAG (направленного ациклического графа).
Фундаментальная проблема с traceview в том, что span'ы являются слишком низкоуровневыми примитивами как для анализа задержек (latency), так и для анализа исходных причин. Это все равно что анализировать отдельные команды процессора в попытке устранить исключение, зная, что существуют гораздо более высокоуровневые инструменты вроде backtrace, работать с которыми значительно удобнее.
Более того, я возьму на себя смелость утверждать следующее: в идеале нам вовсе не нужна полная картина произошедшего во время жизненного цикла запроса, которую представляют современные инструменты для трассировки. Вместо этого требуется некая форма абстракции более высокого уровня, содержащая сведения о том, что пошло не так (по аналогии с backtrace), вместе с некоторым контекстом. Вместо того, чтобы наблюдать весь trace, я предпочитаю видеть его часть, где происходит что-то интересное или необычное. В настоящее время поиск осуществляется вручную: инженер получает trace и самостоятельно анализирует span'ы в поисках чего-нибудь интересного. Подход, когда люди таращатся на span'ы в отдельных trace'ах в надежде обнаружить подозрительную активность, абсолютно не масштабируется (особенно когда им приходится осмысливать все метаданные, закодированные в различных span'ах, такие как span ID, имя метода RPC, продолжительность span'а, логи, теги и т.д.).
Результаты трассировки наиболее полезны, когда их можно визуализировать таким образом, чтобы получить нетривиальное представление о том, что происходит во взаимосвязанных частях системы. До тех пор, пока этого нет, процесс отладки во многом остается инертным и зависит от способности пользователя подмечать верные корреляции, проверять правильные части системы или собирать кусочки мозаики воедино — в отличие от инструмента, помогающего пользователю формулировать эти гипотезы.
Я не визуальный дизайнер и не специалист в области UX, однако в следующем разделе хочу поделиться несколькими идеями о том, как могут выглядеть подобные визуализации.
В условиях, когда отрасль консолидируется вокруг идей SLO (service level objectives) и SLI (service level indicators), кажется разумным, что отдельные команды должны в первую очередь следить за соответствием их сервисов этим целям. Из этого следует, что ориентированная на сервис визуализация лучше всего подходит для таких команд.
Trace'ы, особенно без выборки, являются кладезем информации о каждом компоненте распределенной системы. Эту информацию можно скормить хитрому обработчику, который будет поставлять пользователям ориентированные на сервис находки.Они могут быть выявлены заранее — еще до того, как пользователь взглянул на trace'ы:
На некоторые из этих вопросов встроенные метрики просто не могут ответить, заставляя пользователей тщательно изучать span'ы. В итоге мы имеем чрезвычайно враждебный к пользователю механизм.
В связи с этим возникает вопрос: как насчет комплексных взаимодействий между разнообразными сервисами, контролируемыми разными командами? Разве traceview не считается наиболее подходящим инструментом для освещения подобной ситуации?
Мобильные разработчики, владельцы stateless-сервисов, владельцы управляемых stateful-сервисов (вроде баз данных) и владельцы платформ могут быть заинтересованы в другом представлении распределенной системы; traceview — это слишком универсальное решение для этих в корне отличных нужд. Даже в очень сложной микросервисной архитектуре владельцам сервиса не нужны глубокие знания более чем двух-трех upstream- и downstream-сервисов. В сущности, в большинстве сценариев пользователям достаточно отвечать на вопросы, касающиеся ограниченного набора сервисов.
Это похоже на разглядывание небольшого подмножества сервисов через увеличительное стекло ради скрупулезного изучения. Это позволит пользователю задавать более насущные вопросы, касающиеся комплексного взаимодействия между этими сервисами и их непосредственными зависимостями. Это аналогично backtrace'у в мире сервисов, где инженер знает, что не так, а также имеет некоторое представление о происходящем в окружающих сервисах, чтобы понять, почему.
Продвигаемый мною подход — это полная противоположность к подходу «сверху вниз», основанному на traceview, когда анализ начинается со всего trace'а, а затем постепенно спускается до отдельных span'ов. Напротив, подход «снизу вверх» начинается с анализа небольшого участка, близкого к потенциальной причине инцидента, а затем пространство поиска расширяется при необходимости (с возможным привлечением других команд для анализа более широкого спектра сервисов). Второй подход лучше приспособлен для быстрой проверки начальных гипотез. После получения конкретных результатов можно будет переходить к более целенаправленному и подробному анализу.
Привязанные к конкретному сервису представления могут быть невероятно полезны, если пользователь знает, какой сервис или группа сервисов повинна в увеличении задержек или является источником ошибок. Однако в сложной системе определение сервиса-нарушителя может оказаться нетривиальной задачей во время сбоя, особенно если сообщения об ошибках от сервисов не поступали.
Построение топологии сервисов может сильно помочь при выяснении, какой сервис демонстрирует всплеск частоты ошибок или увеличение задержки, приводящих к заметному ухудшению работы сервиса. Говоря о построении топологии, я имею в виду не карту сервисов, отображающую каждый имеющийся в системе сервис и известную своими картами архитектур в форме звезды смерти. Такое представление ничем не лучше, чем traceview на основе направленного ациклического графа. Вместо этого мне хотелось бы видеть динамически генерируемую топологию сервисов, основанную на определенных атрибутах, таких как частота ошибок, время отклика или на любом заданном пользователем параметре, который помогает прояснить ситуацию с конкретными подозрительными сервисами.
Давайте обратимся к примеру. Представим себе некий гипотетический новостной сайт. Сервис главной страницы (front page) обменивается данными с Redis, с сервисом рекомендаций, с рекламным сервисом и видеосервисом. Видеосервис берет видеоролики с S3, а метаданные — из DynamoDB. Сервис рекомендаций получает метаданные из DynamoDB, загружает данные из Redis и MySQL, пишет сообщения в Kafka. Рекламный сервис получает данные из MySQL и пишет сообщения в Kafka.
Ниже приведено схематическое изображение этой топологии (топологию строят многие коммерческие программы для трассировки). Оно может пригодиться, если нужно разобраться в зависимостях сервисов. Однако во время отладки, когда некий сервис (скажем, видеосервис) демонстрирует увеличенное время отклика, подобная топология не слишком полезна.
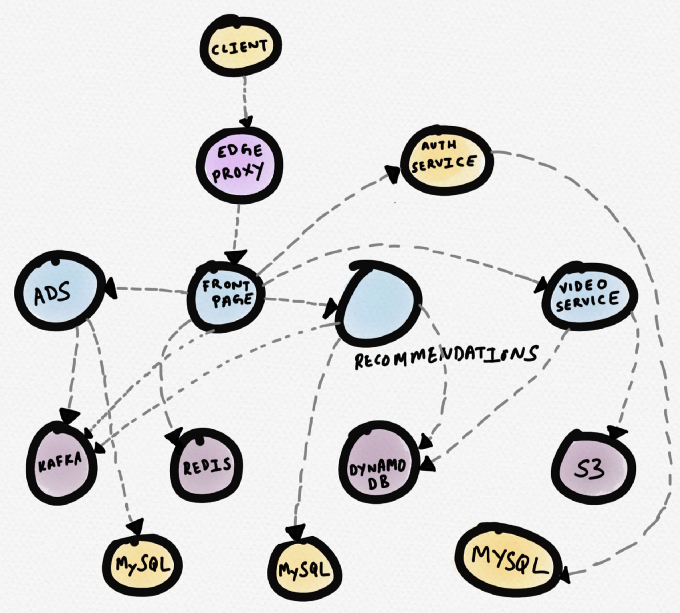
Схема сервисов гипотетического новостного сайта
Лучше подошла бы диаграмма, изображенная ниже. На ней проблемный сервис (video) изображен прямо в центре. Пользователь сразу его замечает. Из данной визуализации становится понятно, что видео-сервис работает аномально из-за увеличения времени отклика S3, что влияет на скорость загрузки части главной страницы.
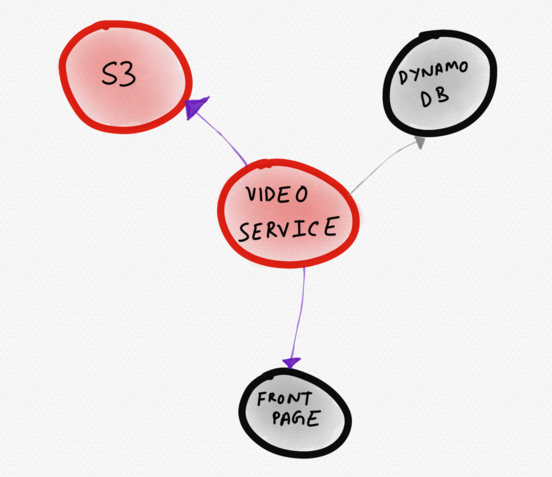
Динамическая топология, отображающая только «интересные» сервисы
Динамически генерируемые топологические схемы могут оказаться более эффективными, нежели статические карты сервисов, особенно в эластичных, автомасштабируемых инфраструктурах. Возможность сравнивать и сопоставлять топологии сервисов позволяет пользователю задавать более актуальные вопросы. Более точные вопросы о системе с большей вероятностью приводят к лучшему пониманию того, как система работает.
Еще одной полезной визуализацией будет сравнительное отображение. В настоящее время trace'ы не слишком хорошо подходят для сравнения бок о бок, поэтому обычно сравниваются span'ы. А основная идея этой статьи как раз и состоит в том, что span'ы слишком низкоуровневые, чтобы извлекать наиболее ценную информацию из результатов трассировки.
Сравнение двух trace'ов не требует принципиально новых визуализаций. На самом деле достаточно чего-то вроде гистограммы, представляющей ту же информацию, что и traceview. Удивительно, но даже этот простой метод может принести гораздо больше плодов, чем простое изучение двух trace'ов по отдельности. Еще более мощной стала бы возможность визуализировать сравнение trace'ов в совокупности. Было бы крайне полезно увидеть, как недавно развернутое изменение конфигурации базы данных с включением GC (сборки мусора) влияет на время отклика downstream-сервиса в масштабе нескольких часов. Если то, что я описываю здесь, кажется похожим на А/В-анализ влияния инфраструктурных изменений во множестве сервисов с помощью результатов трассировки, то вы не слишком далеки от истины.
Я не подвергаю сомнению полезность самой трассировки. Искренне верю, что нет другого метода собирать настолько же богатые, казуальные и контекстуальные данные, как те, что содержатся в trace'е. Однако я также считаю, что все решения для трассировки используют эти данные чрезвычайно неэффективно. До тех пор, пока инструменты для трассировки будут зациклены на traceview-представлении, они будут ограничены в возможности по максимуму использовать ценную информацию, которую можно извлечь из данных, содержащихся в trace'ах. Кроме того, существует риск дальнейшего развития совершенно недружественного и неинтуитивного визуального интерфейса, который сильно ограничит способность пользователя устранять ошибки в приложении.
Отладка сложных систем, даже с использованием новейших инструментов, невероятно сложна. Инструменты должны помогать разработчику формулировать и проверять гипотезу, активно предоставляя релевантную информацию, выявляя выбросы и подмечая особенности в распределении задержек. Для того, чтобы трассировка стала предпочтительным инструментом разработчиков при устранении сбоев в production или решении проблем, охватывающих различные сервисы, необходимы оригинальные пользовательские интерфейсы и визуализации, в большей степени соответствующие ментальной модели разработчиков, создающих и эксплуатирующих эти сервисы.
Потребуются серьезные умственные усилия, чтобы спроектировать систему, которая будет представлять различные сигналы, доступные в результатах трассировки, способом, оптимизированным для облегчения анализа и умозаключений. Необходимо продумать, как абстрагировать топологию системы во время отладки таким образом, чтобы помогать пользователю преодолевать слепые зоны, не заглядывая в отдельные trace'ы или span'ы.
Нам нужны хорошие возможности по абстрагированию и разбиению на уровни (особенно в UI). Такие, которые хорошо впишутся в процесс отладки на основе гипотез, где можно итерационно задавать вопросы и проверять гипотезы. Они не решат все проблемы с наблюдаемостью автоматически, однако будут помогать пользователям оттачивать интуицию и формулировать более взвешенные вопросы. Я призываю к более вдумчивому и инновационному подходу в области визуализации. Здесь есть реальная перспектива расширить горизонты.
Читайте также в нашем блоге:
[Иллюстрация заимствована из другого материала про распределенную трассировку.]
Считается, что распределенную трассировку сложно внедрять, да и отдача от нее в лучшем случае сомнительная. «Проблемность» трассировки объясняют множеством причин, при этом часто ссылаются на трудоемкость настройки каждого компонента системы для передачи соответствующих заголовков вместе с каждым запросом. Хотя эта проблема действительно имеет место, ее вовсе нельзя назвать непреодолимой. Она, кстати, не объясняет, почему разработчики не очень любят трассировку (даже уже функционирующую).
Главная трудность с распределенной трассировкой — это не сбор данных, не стандартизация форматов распространения и представления результатов и не определение того, когда, где и как производить выборку. Я вовсе не пытаюсь представить тривиальными эти «проблемы с усвояемостью» — в самом деле, существуют довольно значимые технические и (если мы рассматриваем по-настоящему Open Source'ные стандарты и протоколы) политические вызовы, которые необходимо преодолеть, чтобы данные проблемы можно было считать решенными.
Однако, если представить, что все эти проблемы решены, высока вероятность, что ничто существенно не изменится с точки зрения опыта конечного пользователя. Трассировка по-прежнему может не приносить практическую пользу в самых распространенных сценариях отладки — даже после того, как она развернута.
Такая непохожая трассировка
Распределенная трассировка включает в себя несколько разрозненных компонентов:
- оснащение приложений и middleware средствами контроля;
- передача распределенного контекста;
- сбор трассировок;
- хранение трассировок;
- их извлечение и визуализация.
Множество разговоров о распределенной трассировке сводятся к тому, чтобы рассматривать ее как некую унарную операцию, единственной целью которой является помощь в полной диагностике системы. Во многом это связано с тем, как исторически формировались представления о распределенной трассировке. В записи в блоге, сделанной, когда открывались исходники Zipkin, упоминалось, что он [Zipkin] делает Twitter быстрее. Первые коммерческие предложения для трассировки также продвигались как инструменты APM.
Прим. перев.: Дабы дальнейший текст воспринимался лучше, определим два базовых термина согласно документации проекта OpenTracing:
- Span — базовый элемент распределенной трассировки. Представляет собой описание некоего рабочего процесса (например, запроса к базе данных) с названием, временем начала и окончания, тегами, логами и контекстом.
- Span'ы обычно содержат ссылки на другие span'ы, что позволяет объединять множество span'ов в Trace — визуализацию жизни запроса в процессе его перемещения по распределенной системе.
Trace'ы содержат невероятно ценные данные, способные помочь в таких задачах, как: тестирование в production, проведение тестов аварийного восстановления, тестирование с внедрением ошибок и т.д. На самом деле некоторые компании уже используют трассировку для подобных целей. Начнем с того, что универсальная передача контекста имеет и другие применения помимо простого переноса span'ов в систему хранения:
- Например, Uber использует результаты трассировки для разграничения тестового трафика и production-трафика.
- Facebook использует данные trace'ов для анализа критического пути и для переключения трафика во время регулярных тестов аварийного восстановления.
- Также соцсеть применяет блокноты Jupyter, позволяющие разработчикам выполнять произвольные запросы на результатах трассировки.
- Приверженцы LDFI (Lineage Driven Failure Injection) используют распределенные trace'ы для тестирования с внедрением ошибок.
Ни один из перечисленных выше вариантов не относится целиком к сценарию отладки, в ходе которого инженер пытается решить проблему, глядя на trace.
Когда дело все же доходит до сценария отладки, первичным интерфейсом остается диаграмма traceview (хотя некоторые также называют ее «диаграммой Ганта» или «каскадной диаграммой»). Под traceview я подразумеваю все span'ы и сопутствующие метаданные, которые вместе составляют trace. Каждая система трассировки с открытым исходным кодом, а также каждое коммерческое решение для трассировки предлагает основанный на traceview пользовательский интерфейс для визуализации, детализации и фильтрации trace'ов.
Проблема со всеми системами трассировки, с которыми мне довелось ознакомиться на данный момент, состоит в том, что итоговая визуализация (traceview) практически полностью отражает особенности процесса генерации trace'а. Даже когда предлагаются альтернативные визуализации: карты интенсивности (heatmap), топологии сервисов, гистограммы задержек (latency), — в конечном итоге они все равно сводятся к traceview.
В прошлом я сетовала на то, что большинство «инноваций» в области трассировки в отношении UI/UX, кажется, ограничиваются включением дополнительных метаданных в trace, вложением в них информации с высокой кардинальностью (high-cardinality) или предоставлением возможности детализировать конкретные span'ы или выполнять запросы меж- и внутри-trace. При этом traceview остается основным средством визуализации. Пока будет сохраняться подобное положение вещей, распределенная трассировка будет (в лучшем случае) занимать 4-е место в качестве отладочного инструмента, вслед за метриками, логами и stack trace'ами, а в худшем — окажется пустой потерей денег и времени.
Проблема с traceview
Предназначение traceview — предоставлять полную картину передвижения отдельного запроса по всем компонентам распределенной системы, к которым он имеет отношение. Некоторые более продвинутые системы трассировки позволяют детализировать отдельные span'ы и просматривать разбивку по времени внутри одного процесса (когда span'ы имеют функциональные границы).
Базовой предпосылкой архитектуры микросервисов является идея о том, что организационная структура растет вместе с потребностями компании. Сторонники микросервисов утверждают, что распределение различных бизнес-задач по отдельным сервисам позволяет небольшим, автономным командам разработчиков контролировать весь жизненный цикл таких сервисов, давая им возможность независимым образом создавать, тестировать и развертывать эти сервисы. Однако недостатком подобного распределения является потеря информации о том, как каждый сервис взаимодействует с другими. В таких условиях распределенная трассировка претендует на роль незаменимого инструмента для отладки сложных взаимодействий между сервисами.
Если у вас действительно ошеломляюще сложная распределенная система, то ни один человек не способен удержать в голове ее полную картину. На самом деле разработка инструмента исходя из предположения, что это вообще возможно, является чем-то вроде антипаттерна (неэффективным и непродуктивным подходом). В идеале для отладки требуется инструмент, помогающий сузить зону поиска, чтобы инженеры могли сосредоточится на подмножестве измерений (сервисах/пользователях/хостах и т. п.), имеющих отношение к рассматриваемому сценарию проблемы. При выяснении причины сбоя инженеры не обязаны разбираться в том, что происходило во всех сервисах сразу, поскольку такое требование противоречило бы самой идее микросервисной архитектуры.
Однако traceview представляет собой именно это. Да, некоторые системы трассировки предлагают сжатые traceview, когда число span'ов в trace настолько велико, что их невозможно отобразить в рамках одной визуализации. Однако из-за большого объема информации, содержащейся даже в такой урезанной визуализации, инженеры все равно вынуждены «просеивать» ее, вручную сужая выборку до набора сервисов-источников проблем. Увы, на этом поприще машины значительно быстрее человека, менее подвержены ошибкам, а их результаты более повторяемы.
Еще одна причина, по которой я считаю метод traceview неправильным, связана с тем, что он плохо подходит для отладки на основе гипотез. В своей основе отладка — это итеративный процесс, начинающийся с гипотезы, за которой следуют проверка различных наблюдений и фактов, полученных от системы по разным векторам, выводы/обобщения и дальнейшая оценка истинности гипотезы.
Возможность быстро и дешево тестировать гипотезы и соответствующим образом улучшать ментальную модель является краеугольным камнем отладки. Любой отладочный инструмент должен быть интерактивным и сужать пространство поиска или, в случае ложного следа, позволять пользователю вернуться назад и сфокусироваться на другой области системы. Идеальный инструмент будет делать это с упреждением, сразу привлекая внимание пользователя к потенциально проблемным областям.
Увы, traceview нельзя назвать инструментом с интерактивным интерфейсом. Лучшее, на что можно надеяться при его использовании, — это обнаружить некий источник повышенных задержек и просмотреть всевозможные теги и логи, связанные с ним. Это не помогает инженеру выявить закономерности в трафике, такие как специфика распределения задержек, или обнаружить корреляции между различными измерениями. Обобщенный анализ trace'ов может помочь обойти некоторые из этих проблем. Действительно, имеются примеры успешного анализа с использованием машинного обучения по выявлению аномальных span'ов и идентификации подмножества тегов, которые могут быть связаны с аномальным поведением. Тем не менее, мне пока не встречались убедительные визуализации находок, сделанных с помощью машинного обучения или анализа данных, примененных к span'ам, которые бы значительно отличались от traceview или DAG (направленного ациклического графа).
Span'ы слишком низкоуровневые
Фундаментальная проблема с traceview в том, что span'ы являются слишком низкоуровневыми примитивами как для анализа задержек (latency), так и для анализа исходных причин. Это все равно что анализировать отдельные команды процессора в попытке устранить исключение, зная, что существуют гораздо более высокоуровневые инструменты вроде backtrace, работать с которыми значительно удобнее.
Более того, я возьму на себя смелость утверждать следующее: в идеале нам вовсе не нужна полная картина произошедшего во время жизненного цикла запроса, которую представляют современные инструменты для трассировки. Вместо этого требуется некая форма абстракции более высокого уровня, содержащая сведения о том, что пошло не так (по аналогии с backtrace), вместе с некоторым контекстом. Вместо того, чтобы наблюдать весь trace, я предпочитаю видеть его часть, где происходит что-то интересное или необычное. В настоящее время поиск осуществляется вручную: инженер получает trace и самостоятельно анализирует span'ы в поисках чего-нибудь интересного. Подход, когда люди таращатся на span'ы в отдельных trace'ах в надежде обнаружить подозрительную активность, абсолютно не масштабируется (особенно когда им приходится осмысливать все метаданные, закодированные в различных span'ах, такие как span ID, имя метода RPC, продолжительность span'а, логи, теги и т.д.).
Альтернативы traceview
Результаты трассировки наиболее полезны, когда их можно визуализировать таким образом, чтобы получить нетривиальное представление о том, что происходит во взаимосвязанных частях системы. До тех пор, пока этого нет, процесс отладки во многом остается инертным и зависит от способности пользователя подмечать верные корреляции, проверять правильные части системы или собирать кусочки мозаики воедино — в отличие от инструмента, помогающего пользователю формулировать эти гипотезы.
Я не визуальный дизайнер и не специалист в области UX, однако в следующем разделе хочу поделиться несколькими идеями о том, как могут выглядеть подобные визуализации.
Фокус на конкретных сервисах
В условиях, когда отрасль консолидируется вокруг идей SLO (service level objectives) и SLI (service level indicators), кажется разумным, что отдельные команды должны в первую очередь следить за соответствием их сервисов этим целям. Из этого следует, что ориентированная на сервис визуализация лучше всего подходит для таких команд.
Trace'ы, особенно без выборки, являются кладезем информации о каждом компоненте распределенной системы. Эту информацию можно скормить хитрому обработчику, который будет поставлять пользователям ориентированные на сервис находки.Они могут быть выявлены заранее — еще до того, как пользователь взглянул на trace'ы:
- Диаграммы распределения задержек только для сильно выделяющихся запросов (outlier requests);
- Диаграммы распределения задержек для случаев, когда SLO-цели сервиса не достигаются;
- Самые «общие», «интересные» и «странные» теги в запросах, которые чаще всего повторяются;
- Разбивка задержек для случаев, когда зависимости сервиса не достигают поставленных SLO-целей;
- Разбивка задержек по различным нижестоящим (downstream) сервисам.
На некоторые из этих вопросов встроенные метрики просто не могут ответить, заставляя пользователей тщательно изучать span'ы. В итоге мы имеем чрезвычайно враждебный к пользователю механизм.
В связи с этим возникает вопрос: как насчет комплексных взаимодействий между разнообразными сервисами, контролируемыми разными командами? Разве traceview не считается наиболее подходящим инструментом для освещения подобной ситуации?
Мобильные разработчики, владельцы stateless-сервисов, владельцы управляемых stateful-сервисов (вроде баз данных) и владельцы платформ могут быть заинтересованы в другом представлении распределенной системы; traceview — это слишком универсальное решение для этих в корне отличных нужд. Даже в очень сложной микросервисной архитектуре владельцам сервиса не нужны глубокие знания более чем двух-трех upstream- и downstream-сервисов. В сущности, в большинстве сценариев пользователям достаточно отвечать на вопросы, касающиеся ограниченного набора сервисов.
Это похоже на разглядывание небольшого подмножества сервисов через увеличительное стекло ради скрупулезного изучения. Это позволит пользователю задавать более насущные вопросы, касающиеся комплексного взаимодействия между этими сервисами и их непосредственными зависимостями. Это аналогично backtrace'у в мире сервисов, где инженер знает, что не так, а также имеет некоторое представление о происходящем в окружающих сервисах, чтобы понять, почему.
Продвигаемый мною подход — это полная противоположность к подходу «сверху вниз», основанному на traceview, когда анализ начинается со всего trace'а, а затем постепенно спускается до отдельных span'ов. Напротив, подход «снизу вверх» начинается с анализа небольшого участка, близкого к потенциальной причине инцидента, а затем пространство поиска расширяется при необходимости (с возможным привлечением других команд для анализа более широкого спектра сервисов). Второй подход лучше приспособлен для быстрой проверки начальных гипотез. После получения конкретных результатов можно будет переходить к более целенаправленному и подробному анализу.
Построение топологии
Привязанные к конкретному сервису представления могут быть невероятно полезны, если пользователь знает, какой сервис или группа сервисов повинна в увеличении задержек или является источником ошибок. Однако в сложной системе определение сервиса-нарушителя может оказаться нетривиальной задачей во время сбоя, особенно если сообщения об ошибках от сервисов не поступали.
Построение топологии сервисов может сильно помочь при выяснении, какой сервис демонстрирует всплеск частоты ошибок или увеличение задержки, приводящих к заметному ухудшению работы сервиса. Говоря о построении топологии, я имею в виду не карту сервисов, отображающую каждый имеющийся в системе сервис и известную своими картами архитектур в форме звезды смерти. Такое представление ничем не лучше, чем traceview на основе направленного ациклического графа. Вместо этого мне хотелось бы видеть динамически генерируемую топологию сервисов, основанную на определенных атрибутах, таких как частота ошибок, время отклика или на любом заданном пользователем параметре, который помогает прояснить ситуацию с конкретными подозрительными сервисами.
Давайте обратимся к примеру. Представим себе некий гипотетический новостной сайт. Сервис главной страницы (front page) обменивается данными с Redis, с сервисом рекомендаций, с рекламным сервисом и видеосервисом. Видеосервис берет видеоролики с S3, а метаданные — из DynamoDB. Сервис рекомендаций получает метаданные из DynamoDB, загружает данные из Redis и MySQL, пишет сообщения в Kafka. Рекламный сервис получает данные из MySQL и пишет сообщения в Kafka.
Ниже приведено схематическое изображение этой топологии (топологию строят многие коммерческие программы для трассировки). Оно может пригодиться, если нужно разобраться в зависимостях сервисов. Однако во время отладки, когда некий сервис (скажем, видеосервис) демонстрирует увеличенное время отклика, подобная топология не слишком полезна.
Схема сервисов гипотетического новостного сайта
Лучше подошла бы диаграмма, изображенная ниже. На ней проблемный сервис (video) изображен прямо в центре. Пользователь сразу его замечает. Из данной визуализации становится понятно, что видео-сервис работает аномально из-за увеличения времени отклика S3, что влияет на скорость загрузки части главной страницы.
Динамическая топология, отображающая только «интересные» сервисы
Динамически генерируемые топологические схемы могут оказаться более эффективными, нежели статические карты сервисов, особенно в эластичных, автомасштабируемых инфраструктурах. Возможность сравнивать и сопоставлять топологии сервисов позволяет пользователю задавать более актуальные вопросы. Более точные вопросы о системе с большей вероятностью приводят к лучшему пониманию того, как система работает.
Сравнительное отображение
Еще одной полезной визуализацией будет сравнительное отображение. В настоящее время trace'ы не слишком хорошо подходят для сравнения бок о бок, поэтому обычно сравниваются span'ы. А основная идея этой статьи как раз и состоит в том, что span'ы слишком низкоуровневые, чтобы извлекать наиболее ценную информацию из результатов трассировки.
Сравнение двух trace'ов не требует принципиально новых визуализаций. На самом деле достаточно чего-то вроде гистограммы, представляющей ту же информацию, что и traceview. Удивительно, но даже этот простой метод может принести гораздо больше плодов, чем простое изучение двух trace'ов по отдельности. Еще более мощной стала бы возможность визуализировать сравнение trace'ов в совокупности. Было бы крайне полезно увидеть, как недавно развернутое изменение конфигурации базы данных с включением GC (сборки мусора) влияет на время отклика downstream-сервиса в масштабе нескольких часов. Если то, что я описываю здесь, кажется похожим на А/В-анализ влияния инфраструктурных изменений во множестве сервисов с помощью результатов трассировки, то вы не слишком далеки от истины.
Заключение
Я не подвергаю сомнению полезность самой трассировки. Искренне верю, что нет другого метода собирать настолько же богатые, казуальные и контекстуальные данные, как те, что содержатся в trace'е. Однако я также считаю, что все решения для трассировки используют эти данные чрезвычайно неэффективно. До тех пор, пока инструменты для трассировки будут зациклены на traceview-представлении, они будут ограничены в возможности по максимуму использовать ценную информацию, которую можно извлечь из данных, содержащихся в trace'ах. Кроме того, существует риск дальнейшего развития совершенно недружественного и неинтуитивного визуального интерфейса, который сильно ограничит способность пользователя устранять ошибки в приложении.
Отладка сложных систем, даже с использованием новейших инструментов, невероятно сложна. Инструменты должны помогать разработчику формулировать и проверять гипотезу, активно предоставляя релевантную информацию, выявляя выбросы и подмечая особенности в распределении задержек. Для того, чтобы трассировка стала предпочтительным инструментом разработчиков при устранении сбоев в production или решении проблем, охватывающих различные сервисы, необходимы оригинальные пользовательские интерфейсы и визуализации, в большей степени соответствующие ментальной модели разработчиков, создающих и эксплуатирующих эти сервисы.
Потребуются серьезные умственные усилия, чтобы спроектировать систему, которая будет представлять различные сигналы, доступные в результатах трассировки, способом, оптимизированным для облегчения анализа и умозаключений. Необходимо продумать, как абстрагировать топологию системы во время отладки таким образом, чтобы помогать пользователю преодолевать слепые зоны, не заглядывая в отдельные trace'ы или span'ы.
Нам нужны хорошие возможности по абстрагированию и разбиению на уровни (особенно в UI). Такие, которые хорошо впишутся в процесс отладки на основе гипотез, где можно итерационно задавать вопросы и проверять гипотезы. Они не решат все проблемы с наблюдаемостью автоматически, однако будут помогать пользователям оттачивать интуицию и формулировать более взвешенные вопросы. Я призываю к более вдумчивому и инновационному подходу в области визуализации. Здесь есть реальная перспектива расширить горизонты.
P.S. от переводчика
Читайте также в нашем блоге:
