
В Java с незапямятных времён есть замечательный интерфейс Map и его имплементации, в частности, HashMap. А начиная с Java 5 есть ещё и ConcurrentHashMap. Рассмотрим эти две реализации, их эволюцию и то, к чему эта эволюция может привести невнимательных разработчиков.
Warning: в статье использованы цитаты исходного кода OpenJDK 8, распространяемого под лицензией GNU General Public License version 2.
Времена до Java 8
Те, кто застал времена долгого-долгого ожидания сначала Java 7, а потом и Java 8 (не то что сейчас, каждые полгода новая версия), помнят, какие операции с Map были самыми востребованными. Это:
Если нужно положить значение в коллекцию, используем первый метод, а для получения имеющегося значения — второй.
Но что делать, если требуется «ленивая» инициализация? Тогда появлялся код такого вида:
String getOrPut(String key) {
String result = map.get(key); //(1)
if (result == null) { //(2)
result = createValue(key); //(3)
map.put(key, result); //(4)
}
return result;
}
- получаем значение по ключу
- проверяем, найдено ли искомое значение
- если значения не обнаружено, то создаём его
- добавляем значение в коллекцию по ключу
Немного громоздко получается, не находите? Причём в случае, когда используется простой HashMap, то это просто код, который неудобно читать, т.к. он немногопоточен. Зато в случае с ConcurrentHashMap всплывает дополнительная особенность: метод createValue (2) может быть вызван несколько раз, если несколько потоков успеют проверить условие (1) до того, как один из них запишет значение в коллекцию (3). Такое поведение зачастую может привести к нежелательным последствиям.
До прихода Java 8 элегантных вариантов просто не было. Если требовалось увернуться от нескольких созданий значений, то приходилось использовать дополнительные блокировки.
С Java 8 всё стало проще. Казалось бы…
Java 8 к нам приходит…
Какая самая долгожданная фича пришла к нам с Java 8? Правильно, лямбды. И не просто лямбды, а их поддержка во всём разнообразии API стандартной библиотеки. Не обошли вниманием и структуры данных Map. В частности, там появились такие методы, как:
За счёт этих методов можно переписать приведённый ранее код гораздо проще:
String getOrPut(String key) {
return map.computeIfAbsent(key, this::createValue);
}
Понятно, что никто не откажется от возможности упростить свой код. Более того, в случае с ConcurrentHashMap метод computeIfAbsent ещё и выполняется атомарно. Т.е. createValue будет вызвано ровно один раз и только в том случае, если искомое значение будет отсутствовать.
IDE тоже не прошли мимо. Так IntelliJ IDEA предлагает автозамену старого варианта на новый:

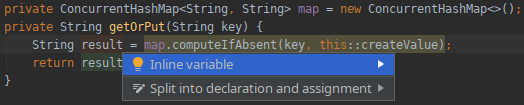

Понятно, что и упрощение кода и подсказки от IDE стимулируют разработчиков использовать этот новый API. Как следствие тот же computeIfAbsent начал появляться в очень многих местах кода.
Пока…
Внезапно!
Пока не настала пора очередного нагрузочного тестирования. И тут обнаружилось страшное:

Приложение работало на следующей версии Java:
openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-8u222-b10-1ubuntu1~18.04.1-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
Для тех, кто не знаком с таким замечательным инструментом, как YourKit.
На скриншоте горизонтальными широкими линиями отображается работа потоков приложения во времени. В зависимости от состояния потока в конкретный момент времени полоса раскрашивается в соответствующий цвет:
- жёлтый — поток бездействует, ожидая работы;
- зелёный — поток работает, выполняя програмный код;
- красный — данный поток заблокирован другим потоком.
То есть получается, что практически все потоки (а их на самом деле было гораздо больше, чем отображено на скриншоте) почти всё время находятся в заблокированном состоянии. И у всех блокировка находится в том самом computeIfAbsent у ConcurrentHashMap! И это при том, что в связи со спецификой данного конкретного нагрузочного теста в этой коллекции может храниться не более 6-8 значений. Т.е. практически все операции в данном месте — исключительно чтение уже имеющихся значений.
Но постойте, как так? Ведь даже в документации к методу про блокировки говорится только в приложении к обновлению:
«If the specified key is not already associated with a value, attempts to compute its value using the given mapping function and enters it into this map unless null. The entire method invocation is performed atomically, so the function is applied at most once per key. Some attempted update operations on this map by other threads may be blocked while computation is in progress, so the computation should be short and simple, and must not attempt to update any other mappings of this map.»
На деле же получается всё не совсем так. Если заглянуть в исходный код этого метода, то получается, что он содержит два весьма толстых синхронизирующих блока:
Реализация ConcurrentHashMap.computeIfAbsent
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction) {
if (key == null || mappingFunction == null)
throw new NullPointerException();
int h = spread(key.hashCode());
V val = null;
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
Node<K,V> r = new ReservationNode<K,V>();
synchronized (r) {
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K,V> node = null;
try {
if ((val = mappingFunction.apply(key)) != null)
node = new Node<K,V>(h, key, val, null);
} finally {
setTabAt(tab, i, node);
}
}
}
if (binCount != 0)
break;
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
boolean added = false;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek; V ev;
if (e.hash == h &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
val = e.val;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
if ((val = mappingFunction.apply(key)) != null) {
added = true;
pred.next = new Node<K,V>(h, key, val, null);
}
break;
}
}
}
else if (f instanceof TreeBin) {
binCount = 2;
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(h, key, null)) != null)
val = p.val;
else if ((val = mappingFunction.apply(key)) != null) {
added = true;
t.putTreeVal(h, key, val);
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (!added)
return val;
break;
}
}
}
if (val != null)
addCount(1L, binCount);
return val;
}
Из приведённого примера видно, что результат может быть сформирован только в шести точках, и почти все эти места находятся внутри синхронизирующих блоков. Весьма неожиданно. Тем более, что простой get вообще не содержит синхронизации:
Реализация ConcurrentHashMap.get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
Так что же делать? По сути, есть только два варианта: или возвращаться к первоначальному коду, или использовать его же, но в чуть модифицированном варианте:
String getOrPut(String key) {
String result = map.get(key);
return (result != null) ? result : map.computeIfAbsent(key, this::createValue);
}
Заключение
Вообще такие фатальные последствия от, казалось бы, банального рефакторинга оказались весьма неожиданными. Ситуацию спасло только наличие нагрузочного теста, который удачно выявил деградацию.
К счастью в более новых версиях Java эту проблему поправили: JDK-8161372.
Так что будьте бдительны, не доверяйте заманчивым подсказкам и пишите тесты. Особенно нагрузочные.
Всем Java!
UPD1: как правильно заметили coldwind, проблема известна: JDK-8161372. И, вроде как, исправлялась для Java 9. Но при этом на момент публикации статьи и в Java 8, и в Java 11, и даже в Java 13 этот метод остался без изменений.
UPD2: vkovalchuk подловил меня на невнимательности. Действительно для Java 9 и более новых проблема исправлена добавлением ещё одного условия с возвращением результата без блокировки:
else if (fh == h // check first node without acquiring lock
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
Изначально я напаролся на ситуацию в следующей версии Java:
openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-8u222-b10-1ubuntu1~18.04.1-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)
А когда смотрел на исходники более поздних версий, то честно проморгал эти строки, что ввело меня в заблуждение.
Так что ради справедливости подправил основной текст статьи.
