Использование Trino для построения ETL‑процессов

1. Введение. Trino: ключевые задачи и главные преимущества
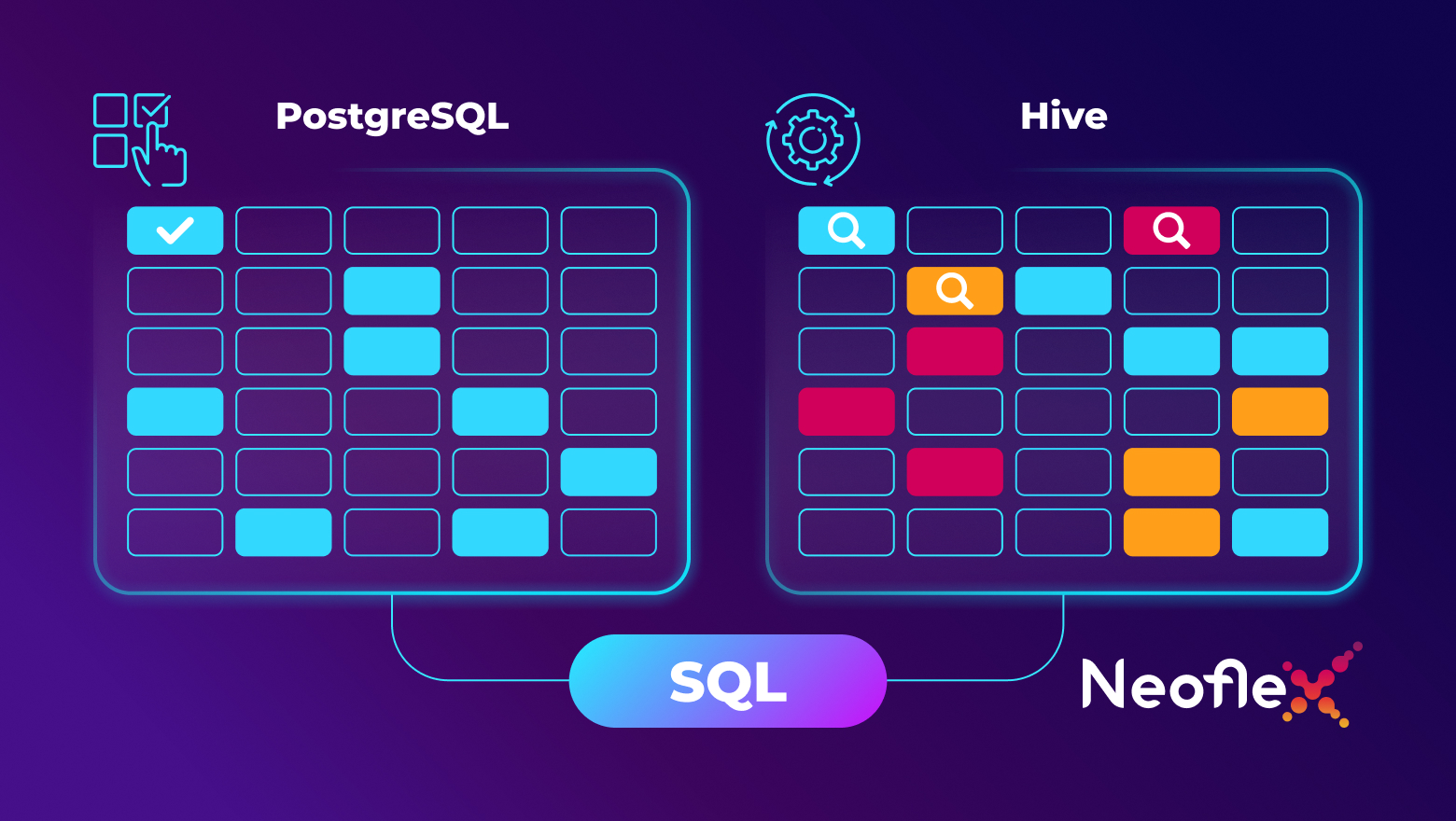
В современной архитектуре управления данными ETL‑процессы рассматриваются не как вспомогательный инструмент, а как базовый механизм интеграции, трансформации и подготовки данных, поступающих из множества гетерогенных источников. Ключевая цель этих процессов — избавиться от хаоса и разрозненности данных, которые почти всегда появляются в больших распределенных компаниях [1].
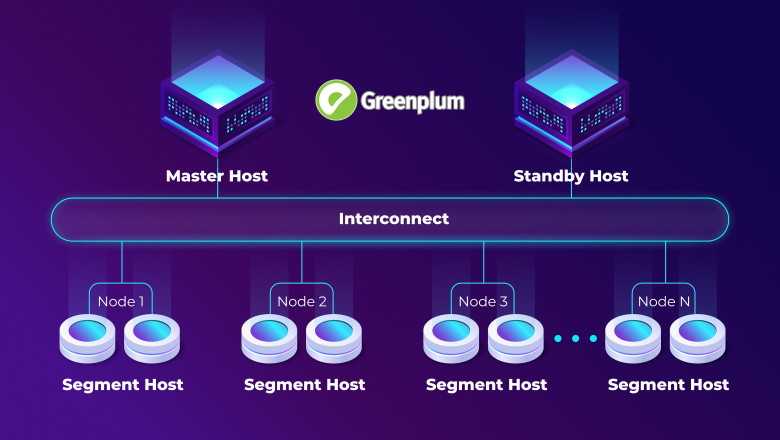
В рамках ETL‑конвейера выполняется автоматизированное извлечение данных из различных источников, их очистка, нормализация и приведение к единой модели, после чего подготовленные данные загружаются в централизованное аналитическое хранилище. Это даёт три главных преимущества: обеспечивает высокое качество и согласованность данных, структурирует информацию под нужды бизнес‑отчетности, а также отделяет аналитическую нагрузку от операционных систем, повышая таким образом производительность системы в целом.
ETL возник как вынужденная мера, так как во время его появления (1970–1990-е) не было ни высокоскоростных сетей, ни мощных распределенных движков аналитики, ни концепции Data Lake. Единственным надёжным способом построить аналитическую отчетность было физически извлекать данные из операционных систем и копировать их в отдельную специализированную базу. Именно поэтому ETL закрепился как основной архитектурный паттерн аналитических систем на долгие десятилетия.
Увы, такой подход породил и массу проблем: это дублирование данных, долгие пайплайны, сложные зависимости, задержки обновления и огромные затраты на поддержку. Традиционным ETL‑процессам становится всё труднее справляться с постоянно растущим объемом поступающих данных. Более того, большие сложности возникают при работе с уже накопленной информацией, ведь её требуется хранить на протяжении многих лет, а значит — сохранять возможность глубокого анализа по всей доступной истории.