
Прошли те дни, когда не надо было беспокоиться об оптимизации производительности баз данных. Время не стоит на месте. Каждый новый бизнесмен из сферы высоких технологий хочет создать очередной Facebook, стремясь при этом собирать все данные, до которых может дотянуться. Эти данные нужны бизнесу для более качественного обучения моделей, которые помогают зарабатывать. В таких условиях программистам необходимо создавать такие API, которые позволяют быстро и надёжно работать с огромными объёмами информации.

Если вы уже некоторое время занимаетесь проектированием серверных частей приложений или баз данных, то вы, вероятно, писали код для выполнения запросов с разбиением на страницы. Например — такой:
Так оно и есть?
Но если разбиение на страницы вы выполняли именно так, я с сожалением могу отметить, что вы делали это далеко не самым эффективным образом.
Хотите мне возразить? Можете не тратить время. Slack, Shopify и Mixmax уже применяют приёмы, о которых я хочу сегодня рассказать.
Назовите хотя бы одного разработчика бэкендов, который никогда не пользовался
Но если нужно с нуля создавать надёжные и эффективные системы, стоит заблаговременно позаботиться об эффективности выполнения запросов к базам данных, используемых в таких системах.
Сегодня мы поговорим о проблемах, сопутствующих широко используемым (жаль, что это так) реализациям механизмов выполнения запросов с разбиением на страницы, и о том, как добиться высокой производительности при выполнении подобных запросов.
Как уже было сказано,
Проблема возникает в том случае, если база данных разрастается до таких размеров, что перестаёт помещаться в памяти сервера. Но при этом в ходе работы с этой базой данных нужно использовать запросы с разбиением на страницы.
Для того чтобы эта проблема себя проявила, нужно, чтобы возникла ситуация, в которой СУБД прибегает к неэффективной операции полного сканирования таблицы (Full Table Scan) при выполнении каждого запроса с разбиением на страницы (в то же время могут происходить операции по вставке и удалению данных, и устаревшие данные нам при этом не нужны!).
Что такое «полное сканирование таблицы» (или «последовательный просмотр таблицы», Sequential Scan)? Это — операция, в ходе которой СУБД последовательно считывает каждую строку таблицы, то есть — содержащиеся в ней данные, и проверяет их на соответствие заданному условию. Известно, что этот тип сканирования таблиц является самым медленным. Дело в том, что при его выполнении выполняется много операций ввода/вывода, задействующих дисковую подсистему сервера. Ситуацию ухудшают задержки, сопутствующие работе с данными, хранящимися на дисках, и то, что передача данных с диска в память — это ресурсоёмкая операция.
Например, у вас есть записи о 100000000 пользователях, и вы выполняете запрос с конструкцией
Скажем, это может выглядеть так: «выбрать строки от 50000 до 50020 из 100000». То есть, системе для выполнения запроса нужно будет сначала загрузить 50000 строк. Видите, как много ненужной работы ей придётся выполнить?
Если не верите — взгляните на пример, который я создал, пользуясь возможностями db-fiddle.com.
Пример на db-fiddle.com
Там, слева, в поле
А второй, который представляет собой эффективное решение той же задачи, так:
Для того чтобы выполнить эти запросы, достаточно нажать на кнопку
А если данных будет больше, то всё будет выглядеть ещё хуже (для того чтобы в этом убедиться — взгляните на мой пример с 10 миллионами строк).
То, что мы только что обсудили, должно дать вам некоторое понимание того, как, на самом деле, обрабатываются запросы к базам данных.
Учитывайте, что чем больше значение
Вместо комбинации
Это — выполнение запроса с разбиением на страницы, основанное на курсоре (Cursor based pagination).
Вместо того, чтобы локально хранить текущие
Почему? Дело в том, что в явном виде указывая идентификатор последней прочитанной строки, вы сообщаете своей СУБД о том, где ей нужно начинать поиск нужных данных. Причём, поиск, благодаря использованию ключа, будет осуществляться эффективно, системе не придётся отвлекаться на строки, находящиеся за пределами указанного диапазона.
Давайте взглянем на следующее сравнение производительности различных запросов. Вот неэффективный запрос.
Медленный запрос
А вот — оптимизированная версия этого запроса.

Быстрый запрос
Оба запроса возвращают в точности один и тот же объём данных. Но на выполнение первого уходит 12,80 секунд, а на второй — 0,01 секунда. Чувствуете разницу?
Для обеспечения эффективной работы предложенного метода выполнения запросов нужно, чтобы в таблице присутствовал бы столбец (или столбцы), содержащий уникальные, последовательно расположенные индексы, вроде целочисленного идентификатора. В некоторых специфических случаях это может определять успех применения подобных запросов ради повышения скорости работы с базой данных.
Естественно, конструируя запросы, нужно учитывать особенности архитектуры таблиц, и выбирать те механизмы, которые наилучшим образом покажут себя на имеющихся таблицах. Например, если нужно работать в запросах с большими объёмами связанных данных, вам может показаться интересной эта статья.
Если перед нами стоит проблема отсутствия первичного ключа, например, если имеется таблица с отношением «многие-ко-многим», то традиционный подход, предусматривающий применение
Если вам интересна эта тема — вот, вот и вот — несколько полезных материалов.
Главный вывод, который мы можем сделать, заключаются в том, что всегда, о каких бы размерах баз данных ни шла речь, нужно анализировать скорость выполнения запросов. В наше время крайне важна масштабируемость решений, и если с самого начала работы над некоей системой спроектировать всё правильно, это, в будущем, способно избавить разработчика от множества проблем.
Как вы анализируете и оптимизируете запросы к базам данных?

Если вы уже некоторое время занимаетесь проектированием серверных частей приложений или баз данных, то вы, вероятно, писали код для выполнения запросов с разбиением на страницы. Например — такой:
SELECT * FROM table_name LIMIT 10 OFFSET 40
Так оно и есть?
Но если разбиение на страницы вы выполняли именно так, я с сожалением могу отметить, что вы делали это далеко не самым эффективным образом.
Хотите мне возразить? Можете не тратить время. Slack, Shopify и Mixmax уже применяют приёмы, о которых я хочу сегодня рассказать.
Назовите хотя бы одного разработчика бэкендов, который никогда не пользовался
OFFSET и LIMIT для выполнения запросов с разбиением на страницы. В MVP (Minimum Viable Product, минимальный жизнеспособный продукт) и в проектах, где используются небольшие объёмы данных, этот подход вполне применим. Он, так сказать, «просто работает».Но если нужно с нуля создавать надёжные и эффективные системы, стоит заблаговременно позаботиться об эффективности выполнения запросов к базам данных, используемых в таких системах.
Сегодня мы поговорим о проблемах, сопутствующих широко используемым (жаль, что это так) реализациям механизмов выполнения запросов с разбиением на страницы, и о том, как добиться высокой производительности при выполнении подобных запросов.
Что не так с OFFSET и LIMIT?
Как уже было сказано,
OFFSET и LIMIT отлично показывают себя в проектах, в которых не нужно работать с большими объёмами данных.Проблема возникает в том случае, если база данных разрастается до таких размеров, что перестаёт помещаться в памяти сервера. Но при этом в ходе работы с этой базой данных нужно использовать запросы с разбиением на страницы.
Для того чтобы эта проблема себя проявила, нужно, чтобы возникла ситуация, в которой СУБД прибегает к неэффективной операции полного сканирования таблицы (Full Table Scan) при выполнении каждого запроса с разбиением на страницы (в то же время могут происходить операции по вставке и удалению данных, и устаревшие данные нам при этом не нужны!).
Что такое «полное сканирование таблицы» (или «последовательный просмотр таблицы», Sequential Scan)? Это — операция, в ходе которой СУБД последовательно считывает каждую строку таблицы, то есть — содержащиеся в ней данные, и проверяет их на соответствие заданному условию. Известно, что этот тип сканирования таблиц является самым медленным. Дело в том, что при его выполнении выполняется много операций ввода/вывода, задействующих дисковую подсистему сервера. Ситуацию ухудшают задержки, сопутствующие работе с данными, хранящимися на дисках, и то, что передача данных с диска в память — это ресурсоёмкая операция.
Например, у вас есть записи о 100000000 пользователях, и вы выполняете запрос с конструкцией
OFFSET 50000000. Это значит, что СУБД придётся загрузить все эти записи (а ведь они нам даже не нужны!), поместить их в память, а уже после этого взять, предположим, 20 результатов, о которых сообщено в LIMIT.Скажем, это может выглядеть так: «выбрать строки от 50000 до 50020 из 100000». То есть, системе для выполнения запроса нужно будет сначала загрузить 50000 строк. Видите, как много ненужной работы ей придётся выполнить?
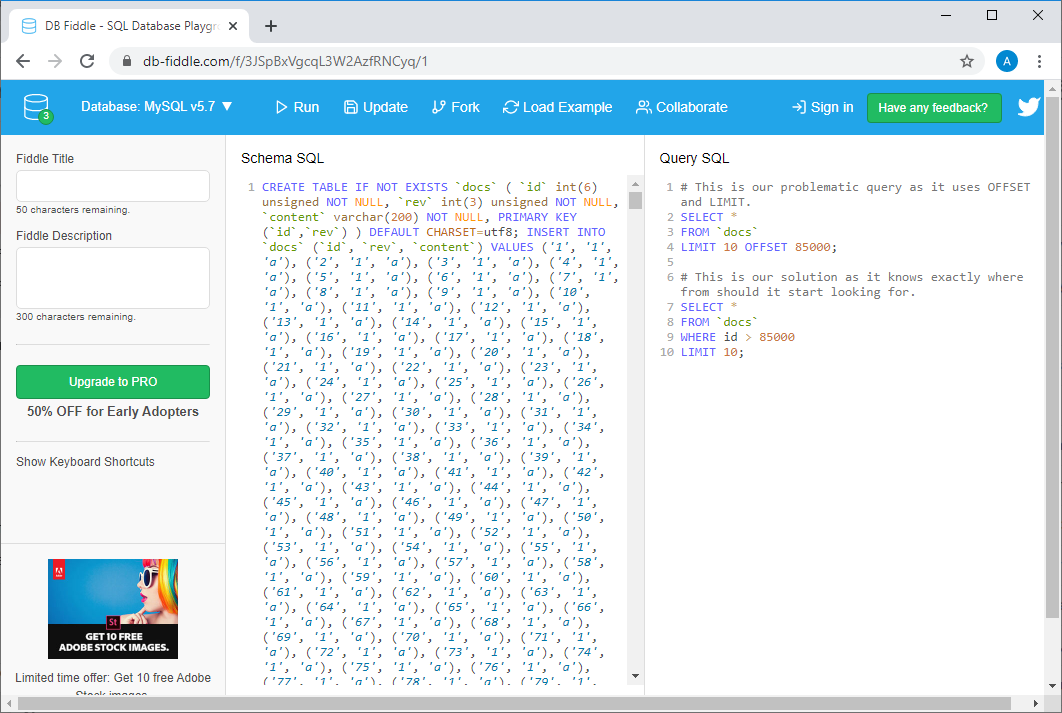
Если не верите — взгляните на пример, который я создал, пользуясь возможностями db-fiddle.com.
Пример на db-fiddle.com
Там, слева, в поле
Schema SQL, имеется код, выполняющий вставку в базу данных 100000 строк, а справа, в поле Query SQL, показаны два запроса. Первый, медленный, выглядит так:SELECT *
FROM `docs`
LIMIT 10 OFFSET 85000;
А второй, который представляет собой эффективное решение той же задачи, так:
SELECT *
FROM `docs`
WHERE id > 85000
LIMIT 10;
Для того чтобы выполнить эти запросы, достаточно нажать на кнопку
Run в верхней части страницы. Сделав это, сравним сведения о времени выполнения запросов. Оказывается, что на выполнение неэффективного запроса уходит, как минимум, в 30 раз больше времени, чем на выполнение второго (от запуска к запуску это время различается, например, система может сообщить о том, что на выполнение первого запроса ушло 37 мс, а на выполнение второго — 1 мс).А если данных будет больше, то всё будет выглядеть ещё хуже (для того чтобы в этом убедиться — взгляните на мой пример с 10 миллионами строк).
То, что мы только что обсудили, должно дать вам некоторое понимание того, как, на самом деле, обрабатываются запросы к базам данных.
Учитывайте, что чем больше значение
OFFSET — тем дольше будет выполняться запрос.Что стоит использовать вместо комбинации OFFSET и LIMIT?
Вместо комбинации
OFFSET и LIMIT стоит использовать конструкцию, построенную по такой схеме:SELECT * FROM table_name WHERE id > 10 LIMIT 20
Это — выполнение запроса с разбиением на страницы, основанное на курсоре (Cursor based pagination).
Вместо того, чтобы локально хранить текущие
OFFSET и LIMIT и передавать их с каждым запросом, нужно хранить последний полученный первичный ключ (обычно — это ID) и LIMIT, в результате и будут получаться запросы, напоминающие вышеприведённый.Почему? Дело в том, что в явном виде указывая идентификатор последней прочитанной строки, вы сообщаете своей СУБД о том, где ей нужно начинать поиск нужных данных. Причём, поиск, благодаря использованию ключа, будет осуществляться эффективно, системе не придётся отвлекаться на строки, находящиеся за пределами указанного диапазона.
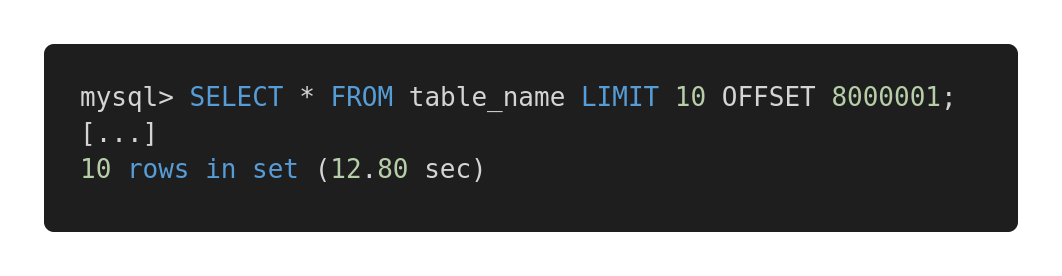
Давайте взглянем на следующее сравнение производительности различных запросов. Вот неэффективный запрос.
Медленный запрос
А вот — оптимизированная версия этого запроса.
Быстрый запрос
Оба запроса возвращают в точности один и тот же объём данных. Но на выполнение первого уходит 12,80 секунд, а на второй — 0,01 секунда. Чувствуете разницу?
Возможные проблемы
Для обеспечения эффективной работы предложенного метода выполнения запросов нужно, чтобы в таблице присутствовал бы столбец (или столбцы), содержащий уникальные, последовательно расположенные индексы, вроде целочисленного идентификатора. В некоторых специфических случаях это может определять успех применения подобных запросов ради повышения скорости работы с базой данных.
Естественно, конструируя запросы, нужно учитывать особенности архитектуры таблиц, и выбирать те механизмы, которые наилучшим образом покажут себя на имеющихся таблицах. Например, если нужно работать в запросах с большими объёмами связанных данных, вам может показаться интересной эта статья.
Если перед нами стоит проблема отсутствия первичного ключа, например, если имеется таблица с отношением «многие-ко-многим», то традиционный подход, предусматривающий применение
OFFSET и LIMIT, нам гарантированно подойдёт. Но его применение может привести к выполнению потенциально медленных запросов. В подобных случаях я порекомендовал бы использовать первичный ключ с автоинкрементом, даже если он нужен только для организации выполнения запросов с разбиением на страницы.Если вам интересна эта тема — вот, вот и вот — несколько полезных материалов.
Итоги
Главный вывод, который мы можем сделать, заключаются в том, что всегда, о каких бы размерах баз данных ни шла речь, нужно анализировать скорость выполнения запросов. В наше время крайне важна масштабируемость решений, и если с самого начала работы над некоей системой спроектировать всё правильно, это, в будущем, способно избавить разработчика от множества проблем.
Как вы анализируете и оптимизируете запросы к базам данных?
