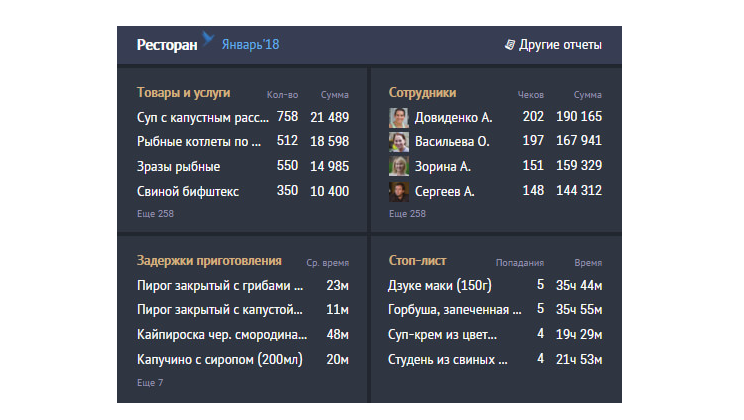
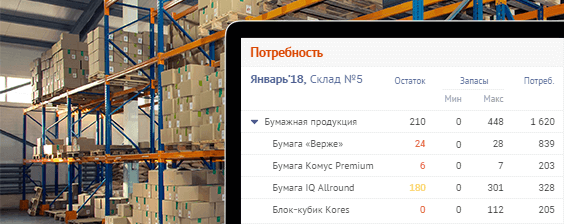
В предыдущей части мы научились эффективно передавать данные вспомогательным потокам из основного через разделяемую память, используя Atomics-операции и блокировки.
Но мы рассматривали все-таки идеальную ситуацию, когда основной поток больше ничем не занимался, кроме обмена с "подчиненными" уже заранее готовыми данными. В реальных же приложениях такое встречается достаточно редко - обычно эти самые данные приходится готовить непосредственно перед передачей. И, бывает, в этом участвует существенная доля синхронного кода, что для JavaScript крайне неприятно, но иногда неизбежно - например, при вычислении регулярных выражений.
Давайте оценим, насколько синхронные операции "роняют" производительность нашего тестового приложения. И узнаем, как можно в разы улучшить ее, "скрестив ужа с ежом", используя выделенный поток-координатор из позапрошлой части статьи совместно с разделяемой памятью.