

Меня зовут Эдуард Тянтов, я руковожу командой Computer Vision в Mail.ru Group. За несколько лет существования наша команда решила десятки задач компьютерного зрения, и сегодня расскажу вам о том, какие методики мы используем для успешного создания моделей машинного обучения, которые работают на широком спектре задач. Поделюсь трюками, которые могут ускорить получение модели на всех этапах: постановка задачи, подготовка данных, обучение и развертывание в продакшен.
Computer Vision в Mail.ru
Начну с того, что такое Computer Vision в Mail.ru, и какими проектами мы занимаемся. Мы предоставляем решения в наши продукты, такие как Почта, Облако Mail.ru (приложение для хранения фото и видео), Vision (B2B-решения на основе компьютерного зрения) и другие. Приведу несколько примеров.
В Облаке (это наш первый и основной клиент) хранится 60 млрд фотографий. Мы разрабатываем различные фичи на основе машинного обучения для их умной обработки, например распознавание лиц и достопримечательностой (про это есть отдельный пост). Все фотографии пользователя прогоняются через модели распознавания, что позволяет организовать поиск и группировку по людям, тэгам, посещенным городам и странам и так далее.


Для Почты мы делали OCR — распознавание текста с картинки. О нем я сегодня чуть подробнее расскажу.
Для В2В-продуктов мы делаем распознавание и подсчет людей в очередях. Например, есть очередь на горнолыжный подъемник, и требуется посчитать, сколько в ней человек. Для начала, чтобы протестировать технологию и поиграться, мы развернули прототип в столовой в офисе. Там есть несколько касс и соответственно несколько очередей, и мы, используя несколько камер (по одной на каждую из очередей), с помощью модели считаем, сколько людей в очередях и сколько примерно минут в каждой из них стоять. Таким образом, мы можем лучше балансировать очереди в столовой.

Постановка задачи
Начнем с критически важной части любой задачи — ее постановки. Практически любая ML-разработка занимает минимум месяц (это в лучшем случае, когда вы знаете, что надо делать), а в большинстве случаев несколько месяцев. Если неверно или неточно поставить задачу, то велик шанс в конце работы услышать от продакт-менеджера что-то в духе: «Все неправильно. Это не годится. Я хотел другое». Чтобы этого не произошло, нужно предпринимать некие шаги. В чем особенность продуктов на основе ML? В отличие от задачи на разработку сайта, задачу в машинном обучении нельзя формализовать одним только текстом. Более того, как правило, неподготовленному человеку кажется, что и все и так очевидно, и просто требуется сделать все «красиво». А уж какие там мелкие детали, постановщик задачи, может быть, даже не знает, никогда о них не думал и не подумает, пока не увидит финальный продукт и скажет: «Что же вы наделали?»
Проблемы
Давайте на примере поймем, какие могут быть проблемы. Допустим, перед вами стоит задача распознавания лиц. Вы ее получаете, радуетесь и звоните маме: «Ура, интересная задача!» Но можно ли прямо срываться и начинать делать? Если так поступить, то в конце вас могут ожидать сюрпризы:
- Бывают разные национальности. Например, в датасете не было азиатов или еще кого-то. Ваша модель, соответственно, совсем не умеет их распознавать, а продукту это оказалось надо. Или наоборот, вы потратили лишние три месяца на доработку, а в продукте будут только европеоиды, и делать это было необязательно.
- Бывают дети. Для таких бездетных отцов, как я, все дети на одно лицо. Я абсолютно солидарен с моделью, когда она всех детей отправляет в один кластер — реально ж непонятно, чем отличаются большинство детей! ;) Но у людей, у которых есть дети, совершенно другое мнение. Обычно они еще и твои руководители. Или бывают еще забавные ошибки распознавания, когда голова ребенка успешно сравнивается с локтем или головой лысого мужика (true story).
- Что делать с рисованными персонажами, вообще непонятно. Надо их распознавать или нет?
Такие аспекты задачи очень важно определить в начале. Поэтому с менеджером надо работать и общаться с самого начала «на данных». Нельзя принимать устные объяснения. Надо смотреть именно на данные. Желательно из того же распределения, на котором модель будет работать.
В идеале в процессе этого обсуждения будет получен некоторый тестовый датасет, на котором финально можно запустить модель и проверить, так ли она работает, как хотел менеджер. Желательно часть тестового датасета отдать самому менеджеру, чтобы вы не имели к нему никакого доступа. Потому что вы запросто можете переобучиться на этот тестовый сет, вы же разработчик ML!
Постановка задачи в ML — это постоянная работа между продакт-менеджером и специалистом по ML. Даже если вначале вы хорошо поставите задачу, то дальше по мере разработки модели будут появляться все новые проблемы, новые особенности, которые вы будете узнавать про свои данные. Все это нужно постоянно обсуждать с менеджером. Хорошие руководители всегда транслируют своим ML-командам, что надо брать ответственность на себя и помогать менеджеру ставить задачи.
Почему так? Машинное обучение — это достаточно новая сфера. У менеджеров нет (или мало) опыта ведения таких задач. Как чаще всего люди учатся решать новые задачи? На ошибках. Если вы не хотите, чтобы ваш любимый проект стал ошибкой, то надо вовлекаться и брать ответственность на себя, учить продакт-менеджера грамотно ставить задачу, вырабатывать чек-листы и политики; все это здорово помогает. Я каждый раз себя одергиваю (или меня одергивает кто-то из коллег), когда приходит новая интересная задача, и мы бежим ее делать. Все, что я вам сейчас рассказал, я и сам забываю. Поэтому важно иметь какой-то чек-лист, чтобы себя проверять.
Данные
Данные — это суперважно в ML. Для deep learning, чем больше данных скормишь модели, тем лучше. Синий график показывает, что обычно модели deep learning сильно улучшаются при добавления данных.

А «старые» (классические) алгоритмы с какого-то момента уже не могут улучшиться.
Обычно в ML датасеты грязные. Их размечали люди, которые всегда врут (с). Асессоры часто бывают невнимательны и допускают очень много ошибок. Мы пользуемся такой техникой: берем данные, которые у нас есть, обучаем на них модель, а потом с помощью этой модели прочищаем данные и повторяем цикл заново.
Давайте подробнее на примере того же самого распознавания лиц. Допустим, мы скачали «ВКонтакте» аватарки пользователей. К примеру, у нас есть профиль пользователя с 4 аватарками. Мы детектируем лица, которые есть на всех 4 изображениях, и прогоняем через модель распознавания лиц. Так мы получаем эмбеддинги лиц, с помощью которых можно их «склеивать» похожие лица в группы (кластеризовать). Дальше мы выбираем самый большой кластер, предполагая, что аватарки пользователя в основном содержат именно его лицо. Соответственно, все остальные лица (являющиеся шумом) мы таким образом можем вычистить. После этого мы можем снова повторить цикл: на прочищенных данных обучить модель и с ее помощью прочистить данные. Повторять можно несколько раз.
Практически всегда для подобной кластеризации мы используем алгоритмы CLink. Это иерархический алгоритм кластеризации, в котором очень удобно задавать пороговое значение для «склейки» похожих объектов (это как раз то, что требуется для прочистки). CLink генерирует сферические кластеры. Это важно, так как мы часто учим метрическое пространство этих эмбеддингов. Алгоритм имеет сложность О(n2), что, в принципе, ок.
Иногда данные настолько тяжело достать или разметить, что не остается ничего, как только начать их генерировать. Генеративный подход позволяет производить огромное количество данных. Но для этого надо что-то программировать. Самый простой пример — это OCR, распознавание текста на изображениях. Разметка текста для этой задачи дико дорогая и шумная: нужно каждую строчку и каждое слово выделить, подписать текст и так далее. Даже сотню страниц текста асессоры (люди, занимающиеся разметкой) будут размечать крайне долго, а для обучения нужно гораздо больше. Очевидно, что можно каким-то образом сгенерировать текст и как-то его «пошевелить», чтобы модель на нем училась.
Мы вывели для себя, что самый лучший и удобный инструментарий для этой задачи — это комбинация из PIL, OpenCV и Numpy. В них есть все для работы с текстом. Можно каким угодно образом усложнить изображение с текстом, чтобы сеть не переобучалась на простые примеры.

Иногда нам нужны какие-то объекты реального мира. Например, товары на полках магазинов. Одна их этих картинок автоматически сгенерирована. Как вы думаете, левая или правая?

На самом деле, обе сгенерированы. Если не присматриваться к мелким деталям, то отличия от реальности не заметить. Делаем мы это с помощью Blender (аналог 3dmax).

Основное важное преимущество — это то, что он open source. У него есть отличный Python API, который позволяет прямо в коде размещать объекты, конфигурировать и рандомизировать процесс и в итоге получить разнообразный датасет.
Для рендеринга используется ray tracing. Это достаточно затратная процедура, но она выдает результат с отличным качеством. Самый главный вопрос: где брать модели для объектов? Как правило, их надо покупать. Но если вы бедный студент и хотите с чем-то поэкспериментировать, всегда есть торренты. Понятно, что для продакшена нужно закупать или заказывать у кого-то отрисованные модели.
На этом про данные всё. Перейдем к обучению.
Metric learning
Цель Metric learning — обучить сеть таким образом, чтобы она похожие объекты переводила в похожие регионы в метрическом пространстве embedding. Приведу снова пример с достопримечательностями, который необычен тем, что в сущности это задача классификации, но на десятки тысяч классов. Казалось бы, зачем здесь metric learning, который, как правило, уместен в задачах типа face recognition? Давайте попробуем разобраться.
Если использовать стандартные лоссы при обучении задачи классификации, например Softmax, то классы в метрическом пространстве хорошо разделятся, но в embedding пространстве точки разных классов могут находится близко друг к другу…

Это создает потенциальные ошибки при генерализации, т.к. небольшое отличие в исходных данных может изменить результат классификации. Нам бы очень хотелось, чтобы точки были более компактные. Для этого применяют различные техники metric learning. Например, Center loss, идея которого крайне простая: мы просто стягиваем точки к обучаемому центру каждого класса, которые по итогу становятся более компактными.

Center loss программируется буквально в 10 строчек на Python, работает очень быстро, а что самое главное — улучшает качество классификации, т.к. компактность приводит к лучшей обобщающей способности.
Angular Softmax
Мы пробовали множество разных методов metric learning, и пришли к выводу, что Angular Softmax приводит к самым лучшим результатам. Среди research-сообщества он также считается state of the art.

Давайте разберем его на примере face recognition. Вот у нас есть два человека. Если воспользоваться стандартным Softmax, то будет проведена разделяющая плоскость между ними — на основе двух векторов весов. Если сделать норму эмбеддингов 1, то точки лягут на окружность, т.е. на сферу в n-мерном случае (картинка справа).

Тогда можно заметить, что за разделение классов уже отвечает угол между ними, и его можно оптимизировать. Но только этого недостаточно. Если мы просто перейдем к оптимизации угла, то задача по факту не изменится, т.к. мы ее просто переформулировали в других терминах. Наша цель, напомню, сделать кластеры более компактными.
Нужно каким-то образом потребовать больший угол между классами — усложнить задачу нейронной сети. Например, таким образом, чтобы она думала, что угол между точками одного класса больше, чем на самом деле, чтобы она их пыталась все больше и больше сжать. Это достигается за счет введение параметра m, который управляет разницей косинусов углов.

Есть несколько вариантов Angular Softmax. Все они играются с тем, умножать на m этот угол или прибавлять, или умножать и прибавлять. State-of-the-art — ArcFace.
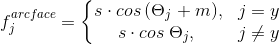
На самом деле, этот достаточно просто встраивается в пайплайн классификации.

Разберем на примере Джека Николсона. Прогоняем его фотографию через сетку в процессе обучения. Получаем эмбеддинг, прогоняем через линейный слой для классификации и получаем на выходе скоры, которые отражают степень принадлежности к классу. В данном случае у фотографии Николсона скор 20, самый большой. Далее по формуле из ArcFace мы снижаем скор с 20 до 13 (делается только для groundtruth класса), усложнив таск для нейросети. Дальше мы делаем все, как обычно: Softmax + Cross Entropy.
Итого, обычный линейный слой заменяется на слой ArcFace, который пишется уже не в 10, а в 20 строчек, но дает отличные результаты и минимум оверхеда на внедрение. По итогу ArcFace на большей части задач лучше всех прочих методов. Он отлично встраивается в задачи классификации и улучшает качество.
Transfer learning
Второе, о чем я хотел рассказать, — это Transfer learning — использование предобученной сети на схожем таске для дообучения на новой задаче. Таким образом, происходит перенос знаний с одной задачи на другую.
Мы сделали свой поиск по изображениям. Суть задачи — выдавать по изображению (query) семантически похожие из базы.

Логично брать сеть, которая уже училась на большом количестве изображений — на датасетах ImageNet или OpenImages, в которых миллионы картинок, и дотренировывать на наших данных.

Мы набрали данных для этой задачи на основе по похожести картинок и кликов пользователей и получили 200к классов. После обучения с ArсFace мы получили следующий результат.

На картинке выше мы видим, что для запрашиваемого пеликана, в выдачу попали еще и воробьи. Т.е. embedding получился семантически верный — это птица, но расово неверный. Самое обидное, что изначальная модель, с которой мы дообучались, знала эти классы и прекрасно их различала. Здесь мы видим эффект, который свойственен всем нейросетям, под названием catastrophic forgetting. То есть сеть при дообучении забывает предыдущий таск, иногда даже полностью. Это как раз то, что мешает в данной задаче достичь лучшего качества.
Knowledge distillation
Лечится это с помощью техники под названием knowledge distillation, когда одна сеть учит другую и “передает ей свои знания”. Как это выглядит (полный пайплайн обучения на картинке ниже).

У нас уже знакомый пайплайн классификации с Arcface. Вспомним, что у нас есть сеть, с которой мы претрейнились. Мы ее заморозили и просто вычисляем ее эмбеддинги на всех фотографиях, на которых мы учим нашу сеть, и получаем скоры классов OpenImages: пеликаны, воробьи, машины, люди и т.д… От исходной обучаемой нейросети отпочковываемся, и учим еще один эмбеддинг под классы OpenImages, который выдает аналогичные скоры. С помощью BCE мы заставляем сеть выдавать похожее распределение этих скоров. Таким образом, с одной стороны мы учим новый таск (в верхней части картинки), но и заставляем сеть не забывать ее корни (в нижней части) — помнить о тех классах, которые она раньше знала. Если правильно сбалансировать градиенты в условной пропорции 50/50, то это позволит оставить всех пеликанов в топе и выкинуть оттуда всех воробьев.

Когда мы это применили, мы получили целый процент в mAP. Это достаточно много.
| Модель | mAP |
|---|---|
| Arcface | 92,8 |
| + Knowledge distil | 93,8 (+1 %) |
Так что если ваша сеть забывает предыдущий таск, то лечите с помощью knowledge distillation — это отлично работает.
Дополнительные головы
Базовая идея очень простая. Снова на примере Face Recognition. У нас в датасете есть набор персон. Но также часто в датасетах есть прочие характеристики лица. Например, сколько лет, какой цвет глаз и т.д. Все это можно добавлять как еще один доп. сигнал: учить отдельные головы на предсказание этих данных. Таким образом, у нас сеть получает больше разнообразного сигнала, и может, как следствие, лучше выучить основной таск.

Еще один пример: детект очередей.

Часто в датасетах с людьми помимо туловища есть отдельная разметка положения головы, что, очевидно, можно использовать. Поэтому мы добавили в сеть к предсказанию bounding box’а человека еще и предсказание bounding box’а головы, и получили прирост в 0,5% к точности (mAP), что прилично. А главное — бесплатно с точки зрения производительности, т.к. на продакшне дополнительная голова «отключается».

OCR
Более сложный и интересный кейс — это OCR, уже упомянутый выше. Стандартный пайплайн такой.

Пусть имеется постер с пингвином, на нем написан текст. С помощью модели детектирования мы выделяем этот текст. Дальше мы этот текст подаем на вход модели распознавания, которая выдает распознанный текст. Допустим, наша сеть ошибается и вместо «i» в слове penguins предсказывает «l». Это на самом деле очень распространенная проблема в OCR, когда сеть путает похожие символы. Вопрос в том, как этого избежать — pengulns перевести в penguins? Когда человек смотрит на этот пример, ему очевидно, что это ошибка, т.к. у него есть знания о структуре языка. Поэтому следует встроить в модель знания о распределении символов и слов в языке.
Мы для этого использовали штуку под названием BPE (byte-pair encoding). Это алгоритм сжатия, который вообще был изобретен еще в 90-х не для машинного обучения, но сейчас он очень популярен и используется в deep learning. Смысл алгоритма в том, что часто встречающиеся подпоследовательности в тексте заменяются на новые символы. Допустим, у нас есть строка «aaabdaaabac», и мы хотим получить для нее BPE. Мы находим, что пара символов «аа» — самая частая в нашем слове. Мы заменяем ее на новый символ «Z», получаем строку «ZabdZabac». Повторяем итерацию: видим, что ab — самая частая подпоследовательность, заменяем ее на «Y», получаем строку «ZYdZYac». Теперь «ZY» — самая частая подпоследовательность, ее мы заменяем на «X», получаем «XdXac». Таким образом, мы кодируем некие статистические зависимости в распределении текста. Если мы встречаем слово, в котором очень «странные» (редкие для обучающего корпуса) подпоследовательности, значит, это слово подозрительное.
aaabdaaabac
ZabdZabac Z=aa
ZYdZYac Y=ab
XdXac X=ZYКак это всё встраивается в распознавание.

Мы выделили слово «penguin», отправили его в сверточную нейросеть, которая выдала пространственный эмбеддинг (вектор фиксированной длины, например 512). В этом векторе закодирована пространственная информация о символах. Далее мы используем рекуррентную сеть (UPD: на самом деле, мы уже используем модель Transformer), она выдает некие скрытые состояния (зеленые столбики), в каждом из которых зашито распределение вероятностей — какой по мнению модели символ изображен на конкретной позиции. Дальше с помощью CTC-Loss мы раскручиваем эти состояния и получаем наше предсказание для всего слова, но с ошибкой: L на месте i.

Теперь интеграция BPE в пайплайн. Мы хотим уйти от предсказания отдельных символов к словам, поэтому мы делаем ответвление от состояний, в которых зашита информация о символах, и натравливаем на них еще одну рекуррентную сеть; она и предсказывает BPE. В случае с описанной выше ошибкой получается 3 BPE: «peng», «ul», «ns». Это значительно отличается от правильной последовательности для слова penguins, то есть «pen», «gu», «ins». Если посмотреть на это с точки зрения обучения модели, то при посимвольном предсказании сеть ошиблась только в одной букве из восьми (ошибка 12,5 %); а в терминах BPE она ошиблась в 100%, неверно предсказав все 3 BPE. Это гораздо бóльший сигнал для сети, что что-то пошло не так, и надо исправить свое поведение. Когда мы это внедрили, то смогли исправить ошибки подобного рода и уменьшили Word Error Rate на 0,25% — это много. Эта дополнительная голова при инференсе убирается, выполнив свою роль при обучении.
FP16
Последнее, что я хотел сказать про обучение, — это FP16. Так исторически сложилось, что сети обучались на GPU в единичной точности, то есть FP32. Но это избыточно, в особенности для инференса, где хватает и половинной точности (FP16) без потери качества. Однако при обучении это не так.

Если мы посмотрим на распределение градиентов, информацию, которая обновляет наши веса при распространении ошибки, то мы увидим, что в нуле огромный пик. И вообще, очень много значений рядом с нулем. Если мы просто переведем все веса в FP16, то получится, что мы отрежем левую часть в районе нуля (от красной линии).

То есть мы будем обнулять очень большое количество градиентов. А правая часть, в рабочем рейнже FP16, вообще никак не используется. В итоге, если обучать в лоб на FP16, то процесс скорее всего разойдется (серый график на картинке ниже).

Если обучать, используя технику mixed precision, то результат получается практически идентичный FP32. Mixed precision реализует два трюка.
Первый: мы просто умножаем loss на константу, например, 128. Таким образом, мы скейлим все градиенты, и перемещаем их значения от нуля в сторону рабочего рейнджа FP16. Второй: мы храним мастер-версию весов FP32, которая используется только для обновления, а в операциях вычисления forward и backward pass сетей используется только FP16.
Мы используем Pytorch для обучения сетей. NVIDIA сделала для него специальную сборку с так называемым APEX, который реализует описанную выше логику. У него есть два режима. Первый — Automatic mixed precision. По коду ниже можно убедиться на сколько просто его использовать.

В код обучения добавляется буквально две строчки, которые оборачивают loss и процедуру инициализации модели и оптимизаторов. Что делает AMP? Он monkey patch’ит все функции. Что конкретно происходит? Например, он видит, что есть функция свертки, а она получает профит от FP16. Тогда он ее заменяет на свою, которая сначала делает cast к FP16, а потом уже выполняет операцию свертки. Так AMP делает для всех функций, которые могут использоваться в сети. Для каких-то не делает, т.к. не будет ускорения. Для большинства задач этот метод подойдет.
Второй вариант: FP16 optimizer для любителей полного контроля. Подходит в случае, если вы хотите сами задавать какие слои будут в FP16, а какие в FP32. Но в нем есть ряд ограничений и сложностей. Он не заводится с полпинка (по крайней мере нам пришлось попотеть, чтобы его завести). Также FP_optimizer работает только с Adam, да и то только с тем Adam, который есть в APEX (да, у них свой Adam в репозитории, который имеет совершенно другой интерфейс, чем пайторчевый).
Мы провели сравнение при обучении на картах Tesla T4.

На Inference у нас ожидаемое ускорение в два раза. При обучении мы видим, что фреймворк Apex дает 20 % ускорения относительно просто FP16. В итоге мы получаем тренировку, которая в два раза быстрее и потребляет в 2 раза меньше памяти, а качество обучения никак не страдает. Халява.
Inference
Т.к. мы используем PyTorch, то стоит остро вопрос, как же его деплоить в продакшен.

Есть 3 варианта, как его это делать (и все из них мы использовали(-ем).
- ONNX -> Caffe2
- ONNX -> TensorRT
- И с недавнего времени Pytorch C++
Давайте разберем каждый из них.
ONNX и Caffe2
1,5 года назад появился ONNX. Это специальный фреймворк для конвертации моделей между различными фреймворками. А Caffe2 — фреймворк, смежный с Pytorch, оба разрабатывают в Facebook. Исторически Pytorch развивается гораздо быстрее, чем Caffe2. Caffe2 отстает по фичам от Pytorch, поэтому не каждую модель, которую вы обучили в Pytorch, можно конвертнуть в Caffe2. Часто приходится переучивать с другими слоями. К примеру, в Caffe2 нет такой стандартной операции как upsampling с nearest neighbor interpolation. В итоге мы пришли к тому, что под каждую модель завели специальный docker image, в котором мы прибиваем версии фреймворков гвоздями во избежания расхождений при их будущих обновлений, чтобы когда в очередной раз обновится какая-нибудь из версий, мы не тратили время на их совместимость. Все это не очень удобно и удлиняет процесс деплоя.
Tensor RT
Есть еще Tensor RT, фреймворк от NVIDIA, который оптимизирует архитектуру сети для ускорения инференса. Мы произвели свои замеры (на карте Tesla T4).

Если посмотреть на графики, то можно увидеть, что переход от FP32 к FP16 дает 2x ускорение на Pytorch, а TensorRT при этом дает аж 4x. Очень существенная разница. Мы это тестировали на Tesla T4, у которой есть тензорные ядра, которые как раз очень хорошо утилизируют вычисления FP16, что очевидно отличное используется в TensorRT. Поэтому, если есть высоконагруженная модель, работающая на десятках видеокартах, то есть все мотиваторы попробовать Tensor RT.
Однако при работе с TensorRT еще больше боли, чем в Caffe2: в нем еще меньше поддерживается слоев. К сожалению, каждый раз, когда мы используем этот фреймворк, то приходится немного пострадать, чтобы конвертнуть модель. Но для высоконагруженных моделей приходится это делать. ;) Замечу, что на картах без тензорных ядер такого массивного прироста не наблюдается.
Pytorch C++
И последнее — Pytorch C++. Полгода назад разработчики Pytorch осознали всю боль людей, которые используют их фреймворк, и выпустили TorchScript tutorial, который позволяет трейсить и сериализовать Python модель в статический граф без лишних телодвижений (JIT). Она вышла в декабре 2018, мы сразу же начали ей пользоваться, сразу же словили несколько багов производительности и ждали несколько месяцев фикса от Чинталы. Но сейчас это достаточно стабильная технология, и мы ее активно используем для всех моделей. Единственное, не хватает документации, которая активно дополняется. Конечно, всегда можно посмотреть по *.h-файлам, но людям, не знающим плюсы, это тяжело. Но зато там действительно идентичная работа с Python. В C++ запускается от-jit’енный код на минимальном интерпретаторе Python’а, что практически гарантирует идентичность С++ с Python.
Выводы
- Постановка задачи — это суперважно. С продакт-менеджерами общаться нужно обязательно на данных. Перед тем, как начать делать задачу, желательно иметь готовый тестсет, на котором замеряем финальные метрики перед стадией внедрения.
- Сами данные мы чистим с помощью кластеризации. Получаем модель на исходных данных, чистим данные с помощью кластеризации CLink и повторяем процесс до сходимости.
- Metric learning: помогает даже классификации. State-of-the-art — ArcFace, который легко интегрировать в процесс обучения.
- Если вы делаете transfer learning с предобученной сети, то, чтобы сеть не забывала старый таск, используйте knowledge distillation.
- Также полезно использовать несколько голов сети, которые будут утилизировать разные сигналы из данных, для улучшения основного таска.
- Для FP16 надо использовать сборки Apex от NVIDIA, Pytorch.
- И на инференсе удобно использовать Pytorch C++.
