
Замена зуба на имплант или установка коронки — болезненная и дорогая процедура. Одна из самых сложных частей в восстановлении — дизайн протеза в CAD-системе, которым занимаются зубные техники. Каждая коронка проектируется индивидуально под пациента и его челюсть за 8-10 минут. При этом у каждого техника своё субъективное видение, что такое хорошая зубная коронка, а оценка качества одной и той же коронки у разных специалистов одного уровня может варьироваться от «хорошо» до «можно и лучше».
Поэтому неудивительно, что в стоматологии задались целью убрать человеческий фактор и добавить автоматизацию. Сделать это можно с помощью нейросетей. Они сейчас продвинулись настолько, что могут распознавать объекты, находить преступников в толпе, рисовать картины по наброску, и заменять лица актеров в фильмах, например, Ди Каприо на Бурунова в фильме «Великий Гэтсби». С зубами они также помогают справиться, а как это получилось, расскажет Станислав Шушкевич.
Станислав Шушкевич — работает в компании Adalisk Service. Это подрядчик крупнейшего в США производителя зубных протезов. В задачи подрядчика входит автоматизация производства коронок, мостов, имплантов. Станислав обучает глубокие нейронные сети. На Saint HighLoad++ 2019 Станислав выступил с докладом, в котором подробно и доступно рассказал как в компании применяют глубокое обучение для автоматизации классификации входных данных, генерации дизайна и автоматизации моделирования коронок.
Эта статья основана на расшифровке его доклада, из нее вы узнаете, как применять глубокое обучение и генерацию дизайна в производстве зубных протезов, как стабилизировать качество, автоматизировать различные этапы производства с помощью нейронных сетей, постепенно уменьшить человеческий фактор и сократить в несколько раз среднее время, которое тратит зубной техник на коронки и импланты.
Примечание. Группа, в которой работает Станислав, сотрудничает с институтом Беркли (США). Они совместно работали над разработкой глубоких нейронных сетей для автоматизации проектирования зубных имплантов. По результатам этой работы исследователи опубликовали научную статью, но доклад интереснее.
Чтобы погрузить вас в курс дела, расскажу о зубной терминологии. У человека 32 зуба, но чаще 28, потому что зубы мудрости часто не вырастают или вырастают больными и их удаляют. Есть сквозная нумерация от 1 до 32, но удобнее делить челюсть на 4 пронумерованных квадранта по 8 зубов. Поэтому мы говорим, что у человека 32 зуба — с 11 по 48. Первая цифра это номер квадранта, вторая — номер зуба в квадранте.

Стандартная схема нумерации зубов.
После зеркального отражения зубы с левой стороны челюсти похожи на зубы с правой, но верхние не похожи на нижние. Поэтому, когда мы говорим, что надо сгенерировать зуб, обычно имеем в виду 16 зубов — 32 пополам как раз 16.
По форме зубов человека нельзя определить пол. Поэтому, когда на раскопках находят зубы, непонятно, чьи они: мужчины или женщины. При этом по лошадиным челюстям можно понять, кобыла это или конь — у коня есть клыки, а у кобылы нет. Меня всегда веселят такие «зубные» факты.
Синим отмечена культя 36-го зуба — отпилили больной зуб, остался пенек. По-английски культя зуба называется «die». Край культи выделен красным, он называется «margin». Когда стоматолог сажает коронку на зуб, важно, чтобы край коронки почти совпадал с margin, с запасом для «клея», иначе будет некрасивая ступенька.

Трехмерный скан слепка нижней челюсти.
Для нас техник сделал 3D-модель красивой коронки.

Бороздки сверху — анатомия коронки. Они расположены не случайным образом, а своим типичным для каждого номера зуба. Описывать можно долго, но там есть первичная анатомия, вторичная, ортодонтический крест.
Сверху подходит челюсть-антагонист, а если зуб верхний — челюсть-антагонист снизу. Также нам важно направление «вверх», которое называется окклюзионным направлением. Когда в тексте будет встречаться «окклюзионный снимок зуба» — это значит просто снимок сверху.
Как делают зубные коронки? Кто ставил себе зубные коронки, примерно представляют. Остальным расскажу общую схему.
Дантист — зубной техник — дантист. Вы приходите к дантисту, открываете рот, он говорит, что ремонтировать. Подпиливает зуб и дает прикусить пластинку. Она похожа на пластилин на подложке — на ней остается отпечаток верхней и нижней челюсти. Дантист отправляет этот слепок в лабораторию к зубному технику.
Зубной техник сидит в лаборатории и никогда не общается с реальными пациентами. Он строит модели зубов в CAD/CAM системе на компьютере. Из готовой 3D модели зуба изготавливает реальную реставрацию и отсылает обратно дантисту. Дальше дантист уже устанавливает реставрацию на место.
На подготовку 3D-образа коронки у техника уходит 10 минут, при этом он думает о многих параметрах:
Натуральность формы. Это первое, о чем думает зубной техник — для меня это самый загадочный момент. Когда я показываю технику два зуба и он говорит какой из них хороший, я спрашиваю, почему он так решил:
— Не знаю. Я просто вижу, что это натуральный зуб, а это нет.
— Какие-то формальные критерии есть? Для системы автоматического проектирования нужны формальные метрики.
— Я не знаю никаких формальных метрик. Я просто вижу, что это хороший зуб, а этот — плохой.
Это называется «натуральная форма».
При этом техник дополнительно заботится, чтобы коронка не пересекалась с антагонистом и хорошо садилась на «край» культи, о плотном контакте с соседями, выставляет направления и сегментирует челюсть.
Для всякого кейса существует несколько хороших решений. Разные техники для одной и той же челюсти создадут несколько разных хороших зубов.
Почему бы не сделать проще: взять обычную зубную коронку, «поиграться» с формой геометрическим алгоритмом и вставить в челюсть? Эта геометрическая задача проста в воображении, но на практике все не так просто.
Вариабельность. На картинке ниже три изображения коронок.
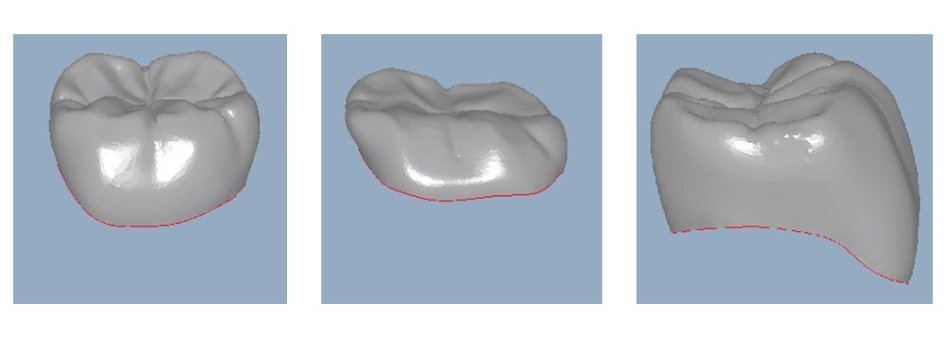
Первый слева — идеальный человеческий зуб. На среднем зазор между антагонистом и культей зуба так мал, что коронка получилась расплющенной. Расстояние между этим зубом и соседом слева было достаточно большим, а нужно, чтобы коронка касалась соседнего зуба, поэтому слева появился наплыв. На правом рисунке все кажется нормальным, но линия «края» культи — не кружок, а сложная пространственная фигура. Для геометрических методов все это сложно из-за большой вариабельности коронок.
Внимание к деталям. Другая важная деталь — характерный размер моделируемых особенностей. Размер 36-го зуба (сзадислевана нижней челюсти) примерно 8 мм, а 200 микрон — это размер только анатомии. Это значит, что если нужна нормальная анатомия, то требуется точность модели хотя бы 100 микрон. Выпиливается она примерно с точностью 20 микрон. 100 микрон мы делим на 8 мм — получаем точность около 1%.
Все это создает проблему — техник тратит много времени на множество факторов. Мы решили упростить его работу и повысить эффективность — больше коронок в единицу времени. Попробовали несколько вариантов и выбрали нейронные сети, которые упростили работу техника.
CAD/CAM. Каждая «зубная» компания создает свою систему. Glidewell Dental, Invisalign, Sirona — все имеют или разрабатывают собственные CAD/CAM-системы. Системы выглядят как AutoCAD или КОМПАС-3D: у вас есть стандартный объект, его можно потянуть, погладить, повернуть. Сейчас техники так работают и тратят 10 минут, чтобы произвести нормальную коронку.
ML — гармонические функции. Это другой способ — относительно простое машинное обучение. Например, если посмотреть на коронку сверху, она будет выглядеть как круг с бороздками, а дальше можно попытаться разложить ее на гармонические функции. Но мы пробовали — с нашими условиями на точность так не получается.
Поэтому в итоге мы обратились к глубоким сетям для генерации трехмерных объектов. Я расскажу две истории, которые связаны с нашим выбором. Первая — пропедевтическая. Это тренировочная или учебная история о сегментации челюсти. Вторая — о генерации коронки.
Сегментация челюсти — это покраска каждого зуба и десны своим цветом (для примера, на окклюзионном виде).

Сегментация — это важно. Например, пришла челюсть в виде 3D-модели, и на ней обпиленная культя зуба. Чтобы программа поняла, куда ставить зуб, она хотя бы должна спозиционироваться относительно культи. В этом случае обычно сидит человек и мышкой обкликивает её и соседей и только потом программа понимает, где поместить зуб. С автоматической сегментацией все было бы гораздо интересней — она бы автоматически указывала, куда ставить зуб.
Существуют компании, у которых есть датасеты с уже сегментированными зубами. Но они их, конечно, не продают и не отдают. Это ноу-хау и большая ценность каждой компании.
К счастью, у нас был геометрический алгоритм Watershed, о котором я дальше расскажу. Он умеет сегментировать, но с эффективностью в 30% — нормальная сегментация в одном случае из трех. Мы сегментировали алгоритмом 15 тыс кейсов, а затем фильтровали вручную. После фильтрации осталось 5 тыс хороших кейсов, на которых мы обучили SegNet.
Примечание. SegNet — стандартная сеть для сегментации. Конкретная сеть не так важна. Важно, что делать, в какой последовательности и откуда взять данные.

Так выглядит сегментация челюсти с 12 зубами.
Вроде все хорошо — разные красивые цвета, зубы практически не «протекают». Но мало пользы в том, чтобы сегментировать только те кейсы, которые мы уже научились геометрически сегментировать. Нам бы хотелось научиться сегментировать все фазовое пространство. В случае сильной корреляции между геометрическим и нейросетевым алгоритмом, сеть, в основном, будет хорошо сегментировать только те кейсы, которые уже хорошо сегментированы.
Поэтому основной вопрос: есть ли здесь корреляция между тем, что делают Watershed и SegNet? Чтобы ответить на этот вопрос, надо знать, как работают эти алгоритмы.
Watershed работает на 3D-поверхности — это «долины», разделенные «хребтами» с большой пространственной кривизной. Когда мы двигаемся по 3D-поверхности, в некоторых местах возникает резкий перегиб, например, там, где сопрягаются два зуба или один зуб входит в десну. В этих местах возникают «хребты». Watershed «наливает воду» и она покрывает долины, а через «хребты» не переходит.
Алгоритм плохо работает там, где пространственная кривизна сломалась. Например, есть два зуба с общей касательной. Их отсканировали так, что два зуба гладко переходят друг в друга. Алгоритм закрасит два зуба одним цветом.
SegNet работает как всякая сегментирующая сеть. Он знает, что примерно можно получить внутри — отсегментированная картинка обычно выглядит, как 14 кружочков, расположенных дугой, а вокруг десна. SegNet склонен к ошибкам: когда кружочки неправильной формы, у пациента не 14 зубов, а 12 или зуб выпадает из арки — дуги, на которой расположены зубы. На рисунке как раз 12 зубов, было тяжело, но алгоритм справился.
Кажется, что Watershed и SegNet не коррелируют между собой, и все относительно нормально.
Требуется оптимизация на конечного потребителя. Мы могли бы заранее потратить много времени, чтобы избавиться от корреляции, думать над этим, принимать меры. Но и без этого SegNet при обучении на отобранных кейсах дал около 90% правильных сегментаций — сеть 9 из 10 челюстей сегментирует отлично.
Ручной труд очень помогает. Вы узнаете свои данные и отберете то, что вам надо.
Переходим к главному блюду.
Для генерации коронки мы выбрали такую схему: берем окклюзионный вид и с него монохромную карту глубин — depth map.

Коронка с глубокой анатомией (крест) и со вторичной анатомией.
Первый источник данных — натуральные зубы. Есть много слепков челюстей, мы теперь умеем их сегментировать: вырезаем натуральные зубы и тренируемся на них.
Мы их и взяли, но получилось плохо. Натуральные зубы слишком вариативны. Обычные человеческие зубы не очень красивые, даже у молодых людей. Хочется, чтобы коронка была посимпатичнее.
Второй источник данных — это готовые коронки. У нас уже есть 5 млн кейсов объемом 150 Тбайт. Они хранятся в облаке Amazon. Из 5 млн кейсов мы отбираем те, что выполнили техники, и тренируемся на них. Но получилось тоже не очень. Мы внимательно посмотрели на наше обучающее множество и обнаружили, что от половины до двух третей готовых коронок можно выполнить и лучше. В основном это касалось глубины анатомии на готовых коронках — канавки были недостаточно выражены.
Это было неприятное открытие, ведь мы взяли результаты специалистов, которым должны подражать. Но мы уже знали как поступать в таких случаях.
Мы взяли 10 тыс кейсов и вручную разбили их на хорошие и плохие. Получили 5 тыс хороших на которых можно учиться. Но экспериментально нам было известно, что для обучения требуется от 10 до 15 тыс хороших кейсов. Чтобы их получить, надо отсортировать вручную 30 тыс кейсов на зуб — это слишком много. Поэтому мы натренировали простую вспомогательную сеть которой показывали зубы, и она отделяла хорошие от плохих.

На рисунке видно, что у трех верхних зубов глубокая анатомия — ясно виден крест, а на нижних вдавленности. На последнем (самом левом) вообще отсутствует анатомия. Техник «зализал» эту коронку так, что анатомия исчезла.
С помощью вспомогательной сети мы можем фильтровать очень большие объемы, и получать по 10-20 тыс кейсов на зуб.
Штрафы. Первое, что пришло в голову, взять генерирующую сеть, показывать ей верхнюю картинку челюсти с культей зуба, требовать от нее нарисовать нижнюю, и накладывать штраф L1. Но теория говорит, что так не сработает, и вот почему.

Сверху челюсть с die — с подпиленным зубом, в середине антагонист, а снизу коронка, которая должна быть создана в результате работы сети.
Мы уже говорили, что существует много хороших решений для одного и того же входа. Если просто наложить штраф L1, то вы будете штрафовать сеть за то, что она не смогла угадать образ коронки в голове у техника в тот момент, когда он ее проектировал. Он мог сделать такую коронку, а мог другую, тоже хорошую. Штрафовать за другую хорошую коронку не надо.
Наш Loss выглядит так:
Важно, что внезапно появился L1. Вы только что прочитали, что он должен что-то портить, но если добавлять ограниченно, то уже не портит. Причина в том, что GAN достаточно нестабилен при тренировке, и L1 сообщает, что зуб в любом случае похож на белое пятно в середине кадра. На начальном этапе обучения он стабилизирует — все сходится лучше, выглядит гладко и аккуратно.
Техническое замечание. Мы долго бились, пытаясь натренировать одну сеть на все задние зубы или одну сеть на пару зубов. Но пришли к выводу, что нужно на каждый зуб, на каждый маленький локализованный кусочек данных, тренировать свою сеть. У нас есть такая возможность.
Мы снова использовали вспомогательные сети и ручной труд:
После всего, что сделали, мы вышли в продакшн. Это не совсем настоящий продакшн — группа Research & Production, но она создает 100 коронок в сутки.
Примечание. На момент публикации статьи, генерирующие сети уже включены в настоящий продукт.
Группа работает с мая — несколько тысяч коронок изготовлены именно GAN’ами. Техник нажимает кнопку и за 20 секунд генерируется образ коронки. Техник проверяет правильность формы, обычно подтягивает контакты, и отправляет на выпилку.
Мы получили существенный выигрыш по времени. Коронка готовится за 8-10 минут, а с привлечением GAN — за 4 минуты. GAN покрывает 80% кейсов — если технику не нравится, что GAN предложил, он моделирует коронку руками и тратит 8 минут.
Оптимизация на конечного потребителя. В процессе работы полезно думать о мерах, метриках, о loss-функции и корреляциях. Но вы все сделали правильно, если довели работу до конца и получили ожидаемый результат.
Использование вспомогательных сетей.
Ручной труд. В ML есть поговорка: «Знай свои данные». Используя ручной труд вы узнаете, что вообще находится в ваших данных. Ручной труд обычно бывает вознагражден, потому что вы «кормите» свою сеть именно тем, что надо.
Баланс «качество — ресурсы». Если есть возможность, смещайтесь в сторону качества. Не жадничайте — добавлять столько сетей, сколько надо.
Поэтому неудивительно, что в стоматологии задались целью убрать человеческий фактор и добавить автоматизацию. Сделать это можно с помощью нейросетей. Они сейчас продвинулись настолько, что могут распознавать объекты, находить преступников в толпе, рисовать картины по наброску, и заменять лица актеров в фильмах, например, Ди Каприо на Бурунова в фильме «Великий Гэтсби». С зубами они также помогают справиться, а как это получилось, расскажет Станислав Шушкевич.
Станислав Шушкевич — работает в компании Adalisk Service. Это подрядчик крупнейшего в США производителя зубных протезов. В задачи подрядчика входит автоматизация производства коронок, мостов, имплантов. Станислав обучает глубокие нейронные сети. На Saint HighLoad++ 2019 Станислав выступил с докладом, в котором подробно и доступно рассказал как в компании применяют глубокое обучение для автоматизации классификации входных данных, генерации дизайна и автоматизации моделирования коронок.
Эта статья основана на расшифровке его доклада, из нее вы узнаете, как применять глубокое обучение и генерацию дизайна в производстве зубных протезов, как стабилизировать качество, автоматизировать различные этапы производства с помощью нейронных сетей, постепенно уменьшить человеческий фактор и сократить в несколько раз среднее время, которое тратит зубной техник на коронки и импланты.
Примечание. Группа, в которой работает Станислав, сотрудничает с институтом Беркли (США). Они совместно работали над разработкой глубоких нейронных сетей для автоматизации проектирования зубных имплантов. По результатам этой работы исследователи опубликовали научную статью, но доклад интереснее.
Зубная терминология
Чтобы погрузить вас в курс дела, расскажу о зубной терминологии. У человека 32 зуба, но чаще 28, потому что зубы мудрости часто не вырастают или вырастают больными и их удаляют. Есть сквозная нумерация от 1 до 32, но удобнее делить челюсть на 4 пронумерованных квадранта по 8 зубов. Поэтому мы говорим, что у человека 32 зуба — с 11 по 48. Первая цифра это номер квадранта, вторая — номер зуба в квадранте.
Стандартная схема нумерации зубов.
После зеркального отражения зубы с левой стороны челюсти похожи на зубы с правой, но верхние не похожи на нижние. Поэтому, когда мы говорим, что надо сгенерировать зуб, обычно имеем в виду 16 зубов — 32 пополам как раз 16.
По форме зубов человека нельзя определить пол. Поэтому, когда на раскопках находят зубы, непонятно, чьи они: мужчины или женщины. При этом по лошадиным челюстям можно понять, кобыла это или конь — у коня есть клыки, а у кобылы нет. Меня всегда веселят такие «зубные» факты.
Синим отмечена культя 36-го зуба — отпилили больной зуб, остался пенек. По-английски культя зуба называется «die». Край культи выделен красным, он называется «margin». Когда стоматолог сажает коронку на зуб, важно, чтобы край коронки почти совпадал с margin, с запасом для «клея», иначе будет некрасивая ступенька.
Трехмерный скан слепка нижней челюсти.
Для нас техник сделал 3D-модель красивой коронки.
Бороздки сверху — анатомия коронки. Они расположены не случайным образом, а своим типичным для каждого номера зуба. Описывать можно долго, но там есть первичная анатомия, вторичная, ортодонтический крест.
Сверху подходит челюсть-антагонист, а если зуб верхний — челюсть-антагонист снизу. Также нам важно направление «вверх», которое называется окклюзионным направлением. Когда в тексте будет встречаться «окклюзионный снимок зуба» — это значит просто снимок сверху.
Путешествие коронки
Как делают зубные коронки? Кто ставил себе зубные коронки, примерно представляют. Остальным расскажу общую схему.
Дантист — зубной техник — дантист. Вы приходите к дантисту, открываете рот, он говорит, что ремонтировать. Подпиливает зуб и дает прикусить пластинку. Она похожа на пластилин на подложке — на ней остается отпечаток верхней и нижней челюсти. Дантист отправляет этот слепок в лабораторию к зубному технику.
Зубной техник сидит в лаборатории и никогда не общается с реальными пациентами. Он строит модели зубов в CAD/CAM системе на компьютере. Из готовой 3D модели зуба изготавливает реальную реставрацию и отсылает обратно дантисту. Дальше дантист уже устанавливает реставрацию на место.
Наше приложение сил в центре этой схемы.Дантист — зубной техник + ML — дантист. Сейчас зубной техник работает в программе, которая похожа на AutoCAD. Но в идеале он должен делать так: приходит кейс в виде слепка, техник сканирует его и получает готовое предложение для коронки. Наша группа ML работает с зубными техниками и за несколько лет собрала 5 млн кейсов и 150 Тбайт данных, которые лежат на Amazon — есть из чего выбрать.
На подготовку 3D-образа коронки у техника уходит 10 минут, при этом он думает о многих параметрах:
- натуральная форма;
- антагонист;
- плотные контакты;
- линия margin;
- сегментация челюсти;
- глубокая анатомия;
- направления;
- арка;
- заполнение бумаг и другие.
Параметры
Натуральность формы. Это первое, о чем думает зубной техник — для меня это самый загадочный момент. Когда я показываю технику два зуба и он говорит какой из них хороший, я спрашиваю, почему он так решил:
— Не знаю. Я просто вижу, что это натуральный зуб, а это нет.
— Какие-то формальные критерии есть? Для системы автоматического проектирования нужны формальные метрики.
— Я не знаю никаких формальных метрик. Я просто вижу, что это хороший зуб, а этот — плохой.
Это называется «натуральная форма».
При этом техник дополнительно заботится, чтобы коронка не пересекалась с антагонистом и хорошо садилась на «край» культи, о плотном контакте с соседями, выставляет направления и сегментирует челюсть.
Для всякого кейса существует несколько хороших решений. Разные техники для одной и той же челюсти создадут несколько разных хороших зубов.
Почему бы не сделать проще: взять обычную зубную коронку, «поиграться» с формой геометрическим алгоритмом и вставить в челюсть? Эта геометрическая задача проста в воображении, но на практике все не так просто.
Вариабельность. На картинке ниже три изображения коронок.
Первый слева — идеальный человеческий зуб. На среднем зазор между антагонистом и культей зуба так мал, что коронка получилась расплющенной. Расстояние между этим зубом и соседом слева было достаточно большим, а нужно, чтобы коронка касалась соседнего зуба, поэтому слева появился наплыв. На правом рисунке все кажется нормальным, но линия «края» культи — не кружок, а сложная пространственная фигура. Для геометрических методов все это сложно из-за большой вариабельности коронок.
Внимание к деталям. Другая важная деталь — характерный размер моделируемых особенностей. Размер 36-го зуба (сзадислевана нижней челюсти) примерно 8 мм, а 200 микрон — это размер только анатомии. Это значит, что если нужна нормальная анатомия, то требуется точность модели хотя бы 100 микрон. Выпиливается она примерно с точностью 20 микрон. 100 микрон мы делим на 8 мм — получаем точность около 1%.
Все это создает проблему — техник тратит много времени на множество факторов. Мы решили упростить его работу и повысить эффективность — больше коронок в единицу времени. Попробовали несколько вариантов и выбрали нейронные сети, которые упростили работу техника.
Методы решения
CAD/CAM. Каждая «зубная» компания создает свою систему. Glidewell Dental, Invisalign, Sirona — все имеют или разрабатывают собственные CAD/CAM-системы. Системы выглядят как AutoCAD или КОМПАС-3D: у вас есть стандартный объект, его можно потянуть, погладить, повернуть. Сейчас техники так работают и тратят 10 минут, чтобы произвести нормальную коронку.
ML — гармонические функции. Это другой способ — относительно простое машинное обучение. Например, если посмотреть на коронку сверху, она будет выглядеть как круг с бороздками, а дальше можно попытаться разложить ее на гармонические функции. Но мы пробовали — с нашими условиями на точность так не получается.
Поэтому в итоге мы обратились к глубоким сетям для генерации трехмерных объектов. Я расскажу две истории, которые связаны с нашим выбором. Первая — пропедевтическая. Это тренировочная или учебная история о сегментации челюсти. Вторая — о генерации коронки.
Сегментация челюсти
Сегментация челюсти — это покраска каждого зуба и десны своим цветом (для примера, на окклюзионном виде).
Сегментация — это важно. Например, пришла челюсть в виде 3D-модели, и на ней обпиленная культя зуба. Чтобы программа поняла, куда ставить зуб, она хотя бы должна спозиционироваться относительно культи. В этом случае обычно сидит человек и мышкой обкликивает её и соседей и только потом программа понимает, где поместить зуб. С автоматической сегментацией все было бы гораздо интересней — она бы автоматически указывала, куда ставить зуб.
Поэтому мы решили покрасить зубы с помощью нейронных сетей.Для обучения нейронных сетей требуются данные. Для сегментации лиц, поз людей, букв есть открытые датасеты — люди с удовольствием ездят на конференции и делятся друг с другом успехами в тренировках. Но найти датасет для сегментирования зубов сложно.
Существуют компании, у которых есть датасеты с уже сегментированными зубами. Но они их, конечно, не продают и не отдают. Это ноу-хау и большая ценность каждой компании.
К счастью, у нас был геометрический алгоритм Watershed, о котором я дальше расскажу. Он умеет сегментировать, но с эффективностью в 30% — нормальная сегментация в одном случае из трех. Мы сегментировали алгоритмом 15 тыс кейсов, а затем фильтровали вручную. После фильтрации осталось 5 тыс хороших кейсов, на которых мы обучили SegNet.
Примечание. SegNet — стандартная сеть для сегментации. Конкретная сеть не так важна. Важно, что делать, в какой последовательности и откуда взять данные.
Так выглядит сегментация челюсти с 12 зубами.
Вроде все хорошо — разные красивые цвета, зубы практически не «протекают». Но мало пользы в том, чтобы сегментировать только те кейсы, которые мы уже научились геометрически сегментировать. Нам бы хотелось научиться сегментировать все фазовое пространство. В случае сильной корреляции между геометрическим и нейросетевым алгоритмом, сеть, в основном, будет хорошо сегментировать только те кейсы, которые уже хорошо сегментированы.
Поэтому основной вопрос: есть ли здесь корреляция между тем, что делают Watershed и SegNet? Чтобы ответить на этот вопрос, надо знать, как работают эти алгоритмы.
Принцип работы Watershed и SegNet
Watershed работает на 3D-поверхности — это «долины», разделенные «хребтами» с большой пространственной кривизной. Когда мы двигаемся по 3D-поверхности, в некоторых местах возникает резкий перегиб, например, там, где сопрягаются два зуба или один зуб входит в десну. В этих местах возникают «хребты». Watershed «наливает воду» и она покрывает долины, а через «хребты» не переходит.
Алгоритм плохо работает там, где пространственная кривизна сломалась. Например, есть два зуба с общей касательной. Их отсканировали так, что два зуба гладко переходят друг в друга. Алгоритм закрасит два зуба одним цветом.
SegNet работает как всякая сегментирующая сеть. Он знает, что примерно можно получить внутри — отсегментированная картинка обычно выглядит, как 14 кружочков, расположенных дугой, а вокруг десна. SegNet склонен к ошибкам: когда кружочки неправильной формы, у пациента не 14 зубов, а 12 или зуб выпадает из арки — дуги, на которой расположены зубы. На рисунке как раз 12 зубов, было тяжело, но алгоритм справился.
Кажется, что Watershed и SegNet не коррелируют между собой, и все относительно нормально.
Промежуточные итоги
Требуется оптимизация на конечного потребителя. Мы могли бы заранее потратить много времени, чтобы избавиться от корреляции, думать над этим, принимать меры. Но и без этого SegNet при обучении на отобранных кейсах дал около 90% правильных сегментаций — сеть 9 из 10 челюстей сегментирует отлично.
Ручной труд очень помогает. Вы узнаете свои данные и отберете то, что вам надо.
Переходим к главному блюду.
Генерация коронки
Для генерации коронки мы выбрали такую схему: берем окклюзионный вид и с него монохромную карту глубин — depth map.
Коронка с глубокой анатомией (крест) и со вторичной анатомией.
Источники данных
Первый источник данных — натуральные зубы. Есть много слепков челюстей, мы теперь умеем их сегментировать: вырезаем натуральные зубы и тренируемся на них.
Мы их и взяли, но получилось плохо. Натуральные зубы слишком вариативны. Обычные человеческие зубы не очень красивые, даже у молодых людей. Хочется, чтобы коронка была посимпатичнее.
Второй источник данных — это готовые коронки. У нас уже есть 5 млн кейсов объемом 150 Тбайт. Они хранятся в облаке Amazon. Из 5 млн кейсов мы отбираем те, что выполнили техники, и тренируемся на них. Но получилось тоже не очень. Мы внимательно посмотрели на наше обучающее множество и обнаружили, что от половины до двух третей готовых коронок можно выполнить и лучше. В основном это касалось глубины анатомии на готовых коронках — канавки были недостаточно выражены.
Это было неприятное открытие, ведь мы взяли результаты специалистов, которым должны подражать. Но мы уже знали как поступать в таких случаях.
Мы взяли 10 тыс кейсов и вручную разбили их на хорошие и плохие. Получили 5 тыс хороших на которых можно учиться. Но экспериментально нам было известно, что для обучения требуется от 10 до 15 тыс хороших кейсов. Чтобы их получить, надо отсортировать вручную 30 тыс кейсов на зуб — это слишком много. Поэтому мы натренировали простую вспомогательную сеть которой показывали зубы, и она отделяла хорошие от плохих.
На рисунке видно, что у трех верхних зубов глубокая анатомия — ясно виден крест, а на нижних вдавленности. На последнем (самом левом) вообще отсутствует анатомия. Техник «зализал» эту коронку так, что анатомия исчезла.
С помощью вспомогательной сети мы можем фильтровать очень большие объемы, и получать по 10-20 тыс кейсов на зуб.
Технические подробности генерации
Штрафы. Первое, что пришло в голову, взять генерирующую сеть, показывать ей верхнюю картинку челюсти с культей зуба, требовать от нее нарисовать нижнюю, и накладывать штраф L1. Но теория говорит, что так не сработает, и вот почему.
Сверху челюсть с die — с подпиленным зубом, в середине антагонист, а снизу коронка, которая должна быть создана в результате работы сети.
Мы уже говорили, что существует много хороших решений для одного и того же входа. Если просто наложить штраф L1, то вы будете штрафовать сеть за то, что она не смогла угадать образ коронки в голове у техника в тот момент, когда он ее проектировал. Он мог сделать такую коронку, а мог другую, тоже хорошую. Штрафовать за другую хорошую коронку не надо.
«Голый» штраф L1 — плохая идея.Дискриминатор. Хорошая идея — обучить дискриминатор, который на все хорошие коронки будет говорить «Хорошо», а на плохие «Плохо». Он будет учитывать сложную поверхность хороших коронок (поверхность в пространстве коронок). К тому же GAN, как оказалось, давит высокочастотный шум.
Наш Loss выглядит так:
Loss = D_GAN + L1 + AntagonistIntersectionPenalty.D_GAN — учитывает сложную поверхность возможных хороших решений. AntagonistIntersectionPenalty добавлен, чтобы зуб не пересекался с антагонистом.Важно, что внезапно появился L1. Вы только что прочитали, что он должен что-то портить, но если добавлять ограниченно, то уже не портит. Причина в том, что GAN достаточно нестабилен при тренировке, и L1 сообщает, что зуб в любом случае похож на белое пятно в середине кадра. На начальном этапе обучения он стабилизирует — все сходится лучше, выглядит гладко и аккуратно.
Техническое замечание. Мы долго бились, пытаясь натренировать одну сеть на все задние зубы или одну сеть на пару зубов. Но пришли к выводу, что нужно на каждый зуб, на каждый маленький локализованный кусочек данных, тренировать свою сеть. У нас есть такая возможность.
Один зуб — одна сеть.Это важно — это ваш trade-off между стабильностью решения и используемыми ресурсами. Если вы потратите лишние 200 Мбайт видеопамяти, то (обычно) ничего не случится. Зато вы будете держать отдельную сеть для каждого зуба и тренировать ее по необходимости.
Промежуточные итоги
Мы снова использовали вспомогательные сети и ручной труд:
- сортировали руками, разбили 10 тыс кейсов на «хорошие и плохие»;
- на результатах ручной сортировки учили вспомогательную сеть;
- массово просеивали еще не размеченные кейсы.
Ура, мы вышли в продакшн!
После всего, что сделали, мы вышли в продакшн. Это не совсем настоящий продакшн — группа Research & Production, но она создает 100 коронок в сутки.
Примечание. На момент публикации статьи, генерирующие сети уже включены в настоящий продукт.
Группа работает с мая — несколько тысяч коронок изготовлены именно GAN’ами. Техник нажимает кнопку и за 20 секунд генерируется образ коронки. Техник проверяет правильность формы, обычно подтягивает контакты, и отправляет на выпилку.
Мы получили существенный выигрыш по времени. Коронка готовится за 8-10 минут, а с привлечением GAN — за 4 минуты. GAN покрывает 80% кейсов — если технику не нравится, что GAN предложил, он моделирует коронку руками и тратит 8 минут.
Уроки
Оптимизация на конечного потребителя. В процессе работы полезно думать о мерах, метриках, о loss-функции и корреляциях. Но вы все сделали правильно, если довели работу до конца и получили ожидаемый результат.
Использование вспомогательных сетей.
Ручной труд. В ML есть поговорка: «Знай свои данные». Используя ручной труд вы узнаете, что вообще находится в ваших данных. Ручной труд обычно бывает вознагражден, потому что вы «кормите» свою сеть именно тем, что надо.
Баланс «качество — ресурсы». Если есть возможность, смещайтесь в сторону качества. Не жадничайте — добавлять столько сетей, сколько надо.
Не за горами следующая конференция Saint HighLoad++. 6 и 7 апреля в Санкт-Петербурге мы обязательно снова услышим примеры использования нейросетей и машинного обучения в сложных продакшенах и, естественно, способы достижения высокой производительности. Если вы как раз хотите поделиться таким опытом — скорее подавайте доклад, времени до дедлайна Call for Papers совсем мало. Или следите за анонсами докладов, которые мы вот-вот начнем утверждать в программу, в рассылке, чтобы вовремя решиться участвовать в конференции.
