

Часто первые ассоциации со словом «Канбан» — это стикеры и доски. Как будто достаточно сделать рабочую доску с колонками-этапами, повесить на них стикеры задач и… наступит менеджерское счастье. Всё само будет управляемо, понятно, прозрачно и выполняться в срок. Мне, как аккредитованному Канбан-тренеру, всегда жаль, что большинство именно так себе всё и представляют. Меня зовут Василий Савунов, и я представляю компанию ScrumTrek с опытом применения Kanban в ИТ, реальном секторе и в банковской сфере.
В Канбан-методе на самом деле много глубоких и полезных тем. Сегодня мы поговорим о двух его аспектах: визуальном менеджменте и вероятностном прогнозировании. И как на этой базе тимлид может достоверно посчитать срок выполнения любой задачи.

Начнем с довольно типичного диалога:
Бизнес-заказчик. Нам надо внести изменения в работу сервиса. Сколько надо времени, чтобы это сделать?
Опытный Тимлид. А ТЗ есть? Если есть — сможем оценить и вывести сроки.
Бизнес-заказчик. Дайте мне хотя бы примерный срок!
Однако каждый Тимлид, и вообще любой руководитель проектов знает, что это — ловушка! Любой «примерный» срок, озвученный исполнителем, бизнес-заказчик будет воспринимать как реальность. Как обязательство. Он запишет его в календарь и когда срок придет, спросит: «Где то, что вы мне обещали?»

Чтобы избежать этой ловушки, Тимлид говорит, что ему надо обсудить задачу с ведущим Специалистом и проговорить нюансы — и после этого он сможет дать какой-то срок. Звучит логично, и Бизнес-заказчик обычно на это соглашается. И, хотя Специалисту тоже не нравится идея давать «примерный» срок, не имея на руках ТЗ, он, чтобы хоть как-то подстраховаться, называет срок с о-о-о-о-чень большим запасом. Например, один месяц, с чем Тимлид и возвращается к Бизнес-заказчику.
По пути наш Тимлид слышит внутренний голос своего Прошлого опыта: «Нельзя называть срок, который назвал Специалист! Ведь Бизнес-заказчик обязательно попытается уменьшить его как минимум вдвое! Давай умножим месяц на число Пи и прибавим 20% на всякие неожиданности».
Так один месяц легко превращается в четыре.
Бизнес-заказчик, услышав про срок в 4 месяца, переводит всё на деньги и быстро подсчитывает свои показатели возврата инвестиций. И начинает думать — а стоит ли овчинка выделки? Но главное в другом: как опытный человек, он знает про число Пи и 20% на форс-мажоры — и решает надавить на Тимлида, чтобы срезать время выполнения. Например, в два раза. Он ругается и требует объяснений, и в результате торгов появляется срок в два месяца. На него и Тимлид может согласиться, ведь изначально ему был нужен всего месяц. Прошлый опыт Тимлида тоже радуется.

На основании чего считают сроки?
Думаю, многие узнали себя в этом диалоге. Проблема в том, что такого рода «торг» не приближает ни одну из сторон к пониманию, какой срок реалистичен. Потому что разговор идет на уровне экспертных мнений, а не на базе объективных данных. Обычно выбирается одна из трех стратегий:
Используется прошлый опыт Тимлида, и по аналогии дается оценка по текущей задаче;
Используется экспертное мнение Специалиста или Тимлида — как в примере;
Бывает, что за точку отсчета принимают бюджетные или временные ограничения из серии «Вот вам дедлайн и успевайте как хотите».
Но мы живем в XXI веке! У нас терабайты исторических данных и трекер задач, который эти данные собирает. Можем ли мы использовать эти данные? И определять сроки, не отвлекая Специалистов от работы?
Чем нам поможет Канбан-метод
Первое, что рекомендует сделать Канбан-метод — визуализировать рабочий процесс в виде рабочей доски.
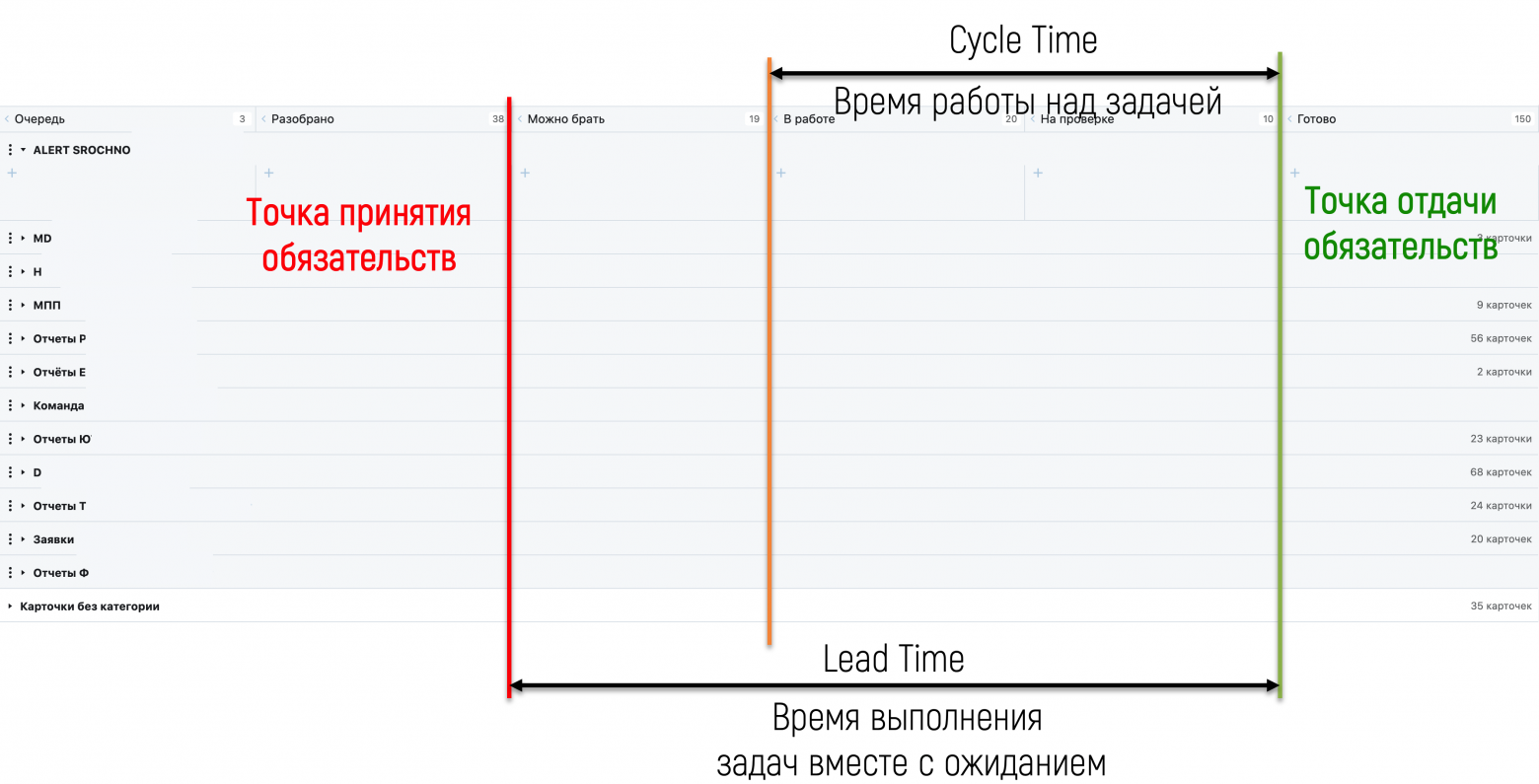
И на этой доске есть две важные точки.
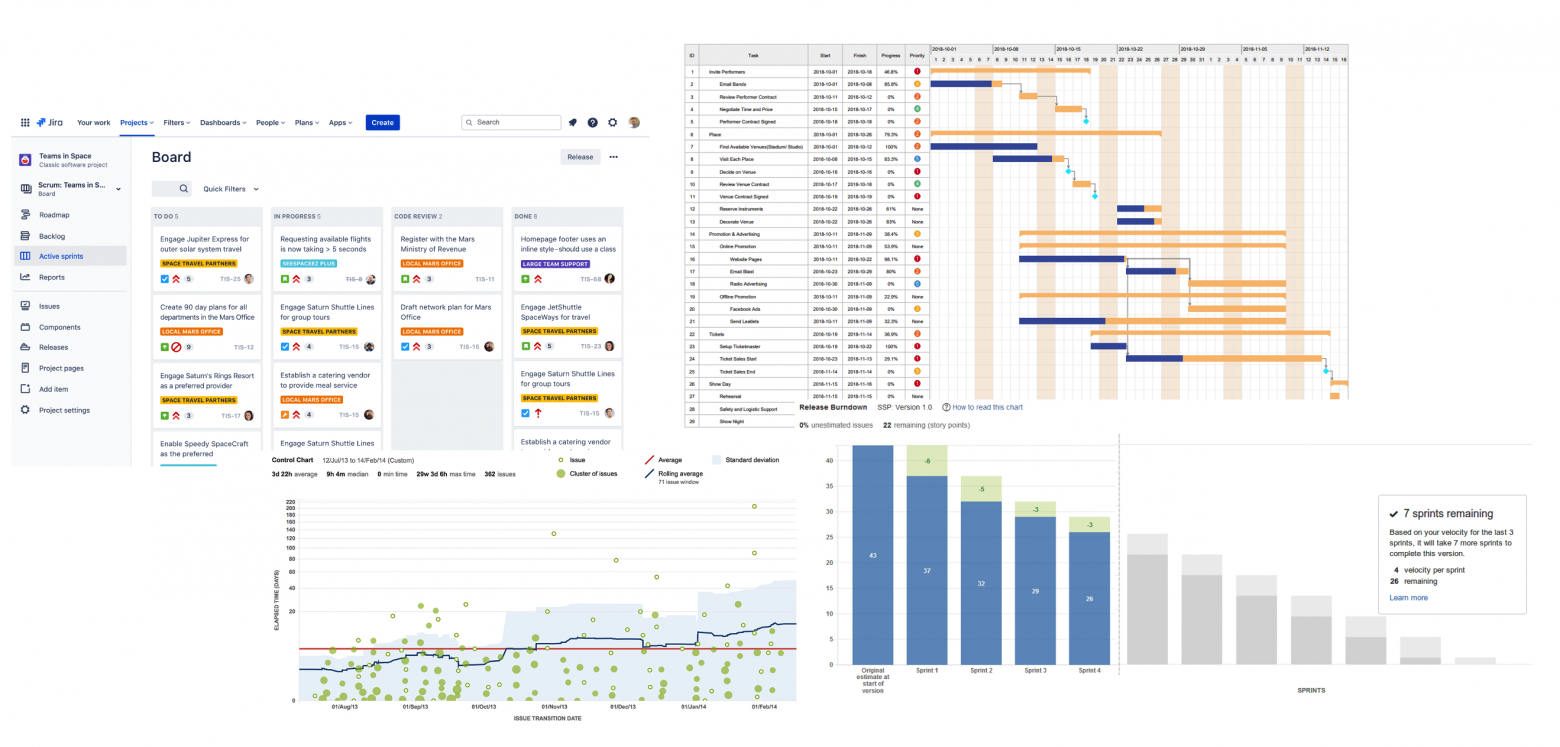
Первая точка принятия обязательств. Когда Тимлид говорит Бизнес-заказчику: «Да, мы берем эту задачу в работу» — то есть мы берем на себя обязательство сделать эту задачу. И задача из списка желаний переходит в список обязательств.
Вторая точка отдачи обязательств. Когда Бизнес-заказчик принял результат выполнения задачи и сказал: «Всё сделано, как я просил» — то есть мы выполнили наши обязательства и больше ничего должны. Задача переходит в разряд готовых.
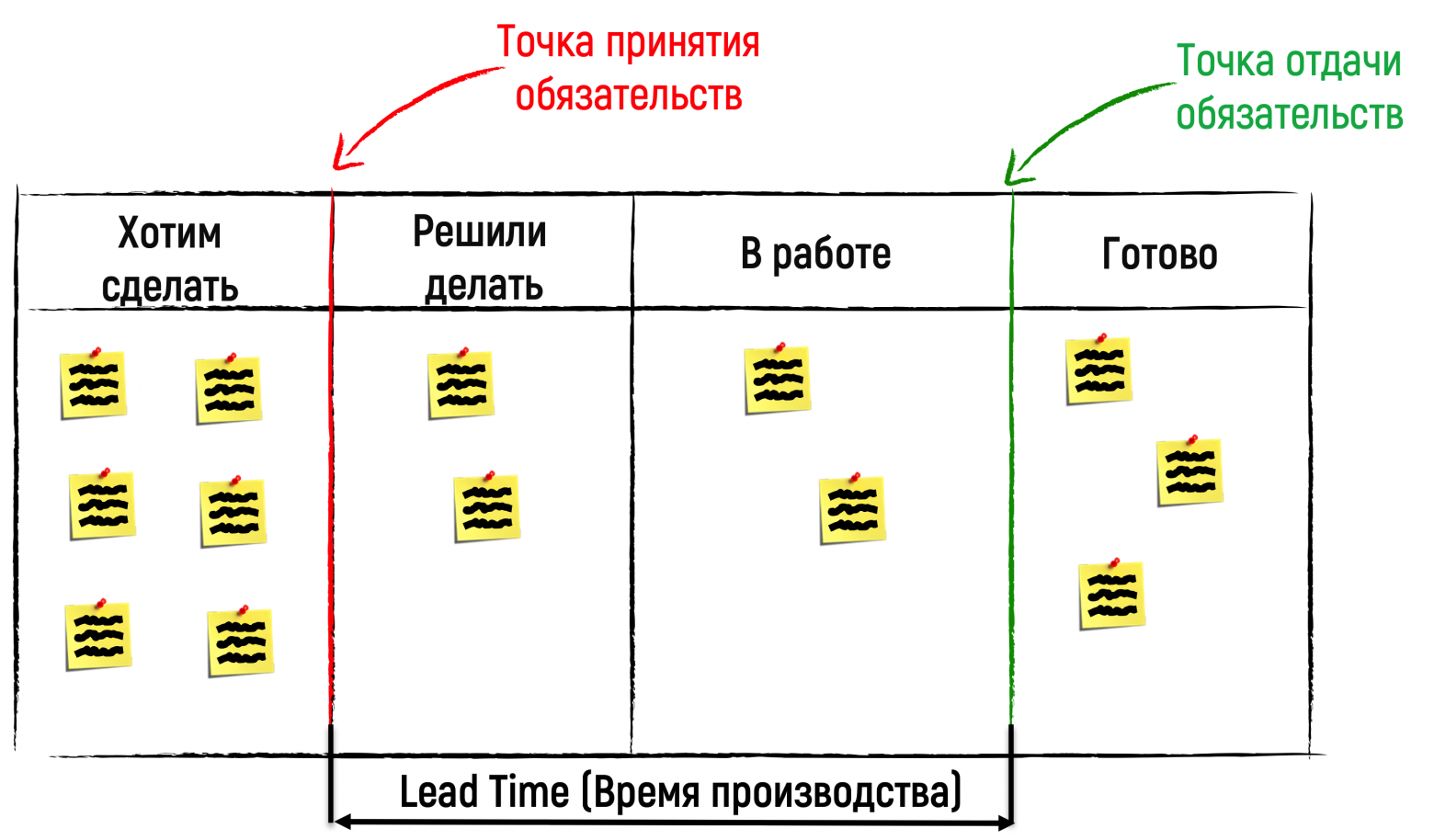
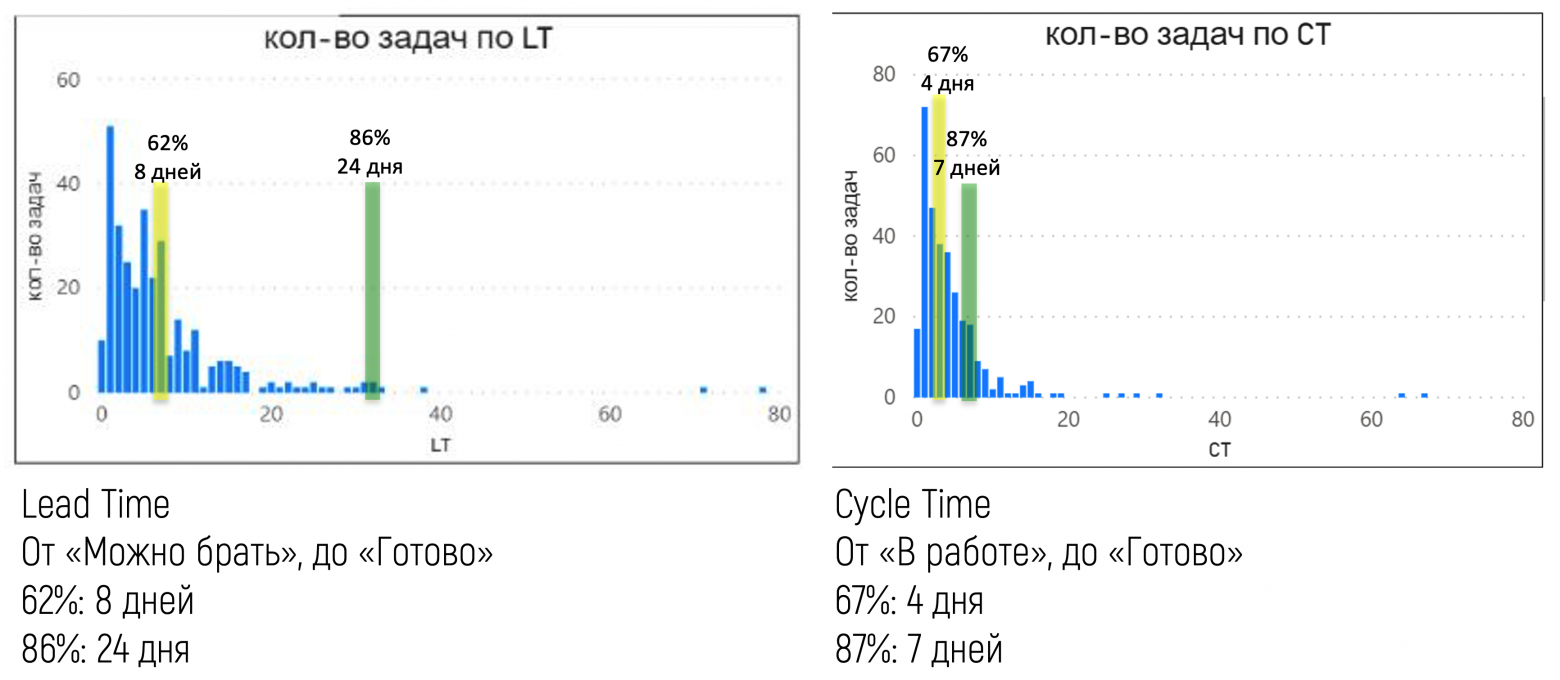
Lead Time (Время производства), за которое задача проходит по доске от одной точки до другой — самая важная метрика для определения прогноза по срокам. Если собрать данные по Lead Time всех задач за достаточно продолжительный период (квартал, полгода), то можно делать вероятностные прогнозы. Для этого строится график, где по горизонтали — Lead Time, от минимального к максимальному. А по вертикали — сколько раз данное значение Lead Time повторялось.
Получается диаграмма распределения Lead Time (Lead Time Distribution Chart):

Что это нам дает? Во-первых, на данном графике могут быть «горбы» — скопления значения вокруг локальных максимумов. Их нужно исследовать, чтобы выяснить, какого рода задачи скапливаются вокруг локальных максимумов. В одном «горбе» могут быть задачи, где не требуется интеграция со сторонними системами, — и поэтому у них одно распределение по времени. И наоборот, в другом «горбе» могут быть задачи, где такие интеграции нужны — тогда проявится другое распределение по времени. А может быть, эти задачи можно объединить по какому-то другому признаку и увидеть некую закономерность.
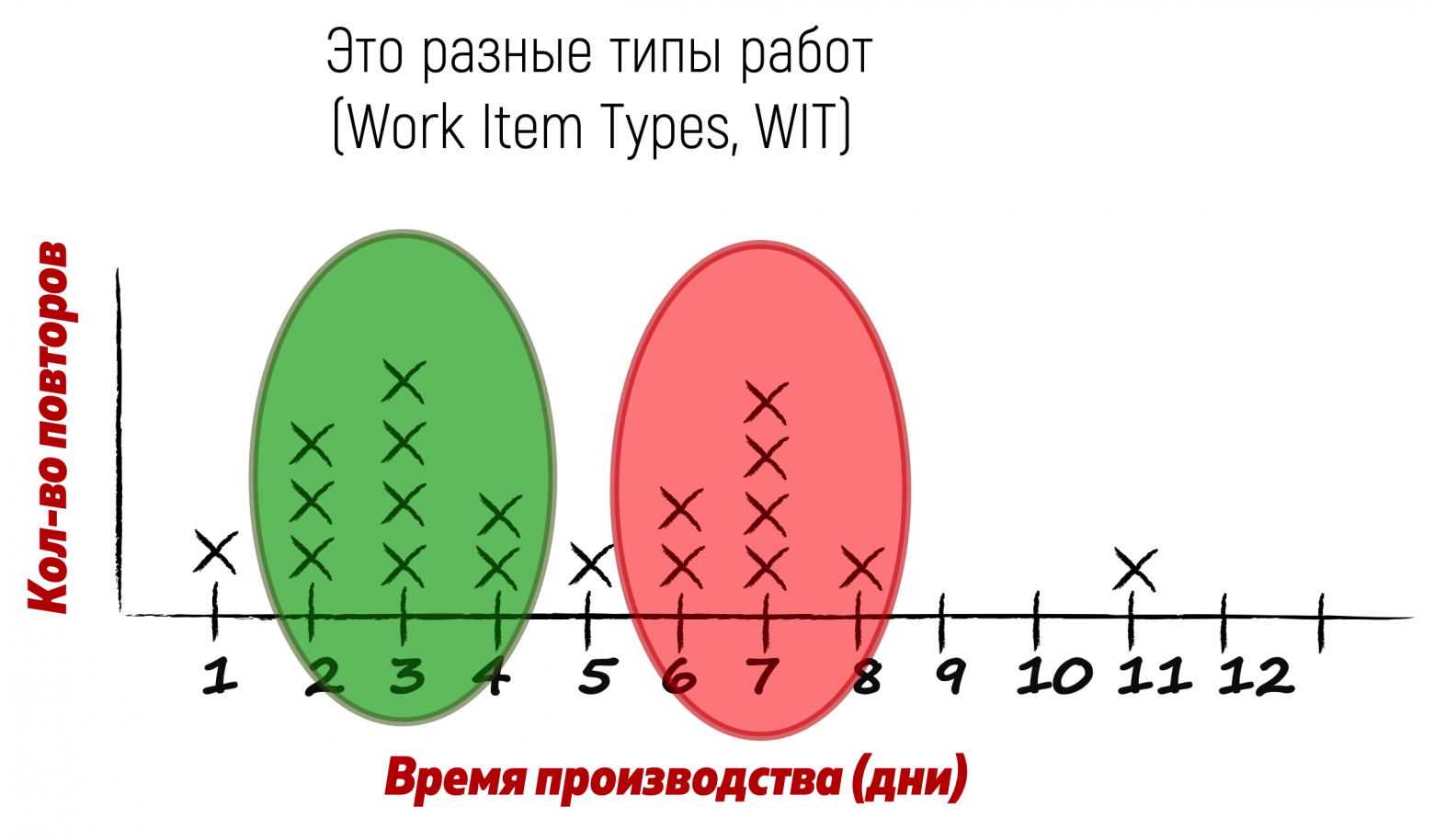
С точки зрения Канбан-метода, группировка задач по какому-то признаку в «горбах» на графике — разные типы работ. Они, как правило, отличаются еще и тем, что последовательность действий для их завершения (workflow) — тоже разная. Именно разный workflow диктует разное распределение по времени на графике распределения Lead Time (Lead Time Distribution Chart).
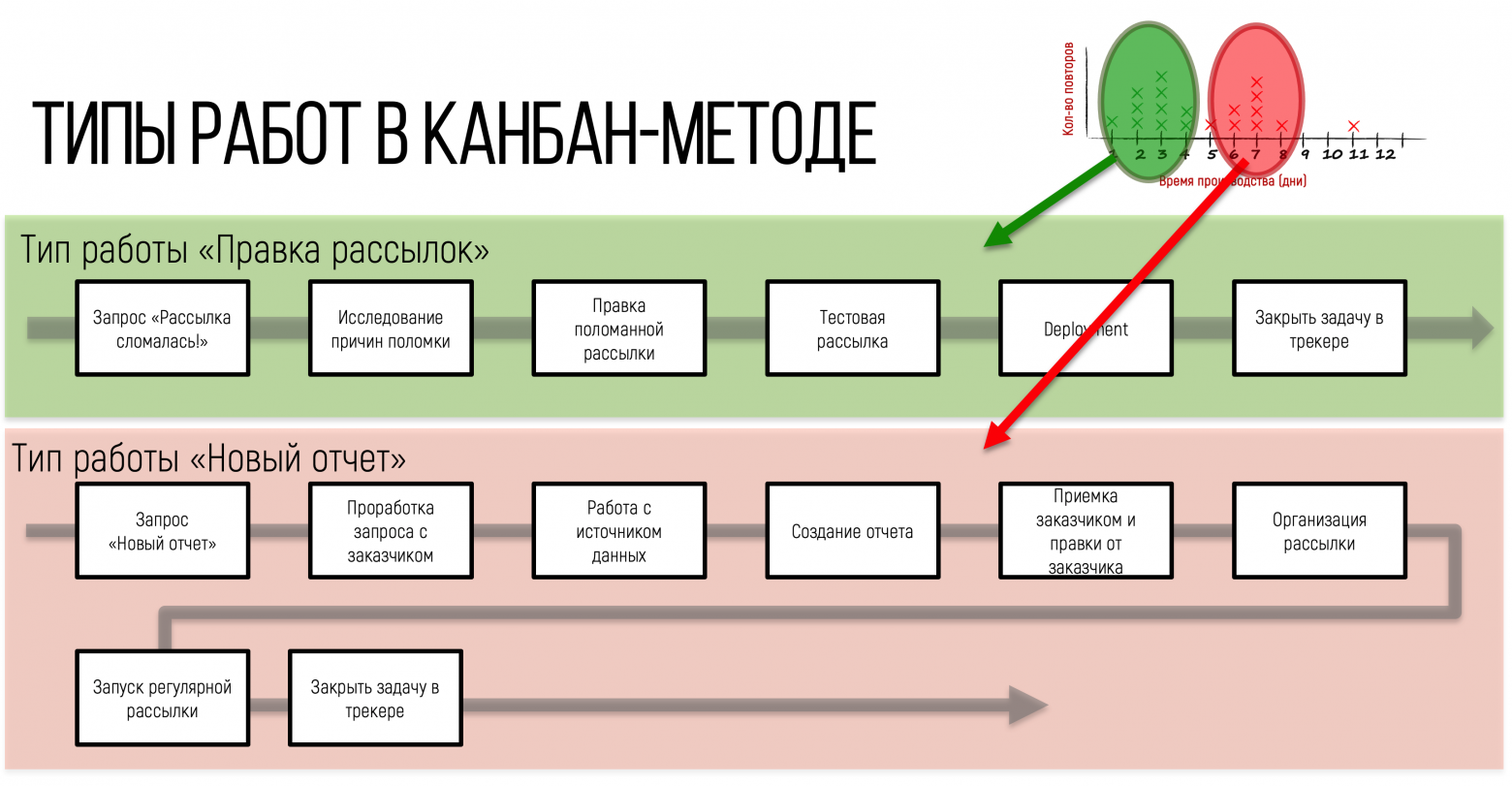
Разделяя статистику по типам работ, мы можем делать гораздо более точные вероятностные прогнозы. Конечно, в реальной жизни такое четкое разделение, как показано на графике очень маловероятно. Но мы возьмем этот случай для иллюстрации подхода вероятностного прогнозирования.
Из наших данных видно, что «зеленые» задачи никогда не делались дольше четырех дней. То есть, в ответ на вопрос заказчика мы обоснованно можем ответить: «Со 100% вероятностью задачу такого типа мы сделаем за 4 дня».
Однако вероятность 100% редко нужна в бизнес-задачах. Если только нам не нужно к определенному сроку выполнить регуляторное требование. Или мы запускаем космический корабль — и нужно успеть точно в срок. Но в большинстве случаев нам достаточно прогноза с вероятностью 80-90%.
Как считать вероятность?
Из курса высшей математики известно, что вероятность какого-то события P считается как:
P = N / M, где M — общее количество случаев за определенные период времени, а N — количество случаев, которые завершились с нужным для нас исходом.
Допустим, мы хотим вычислить: какова вероятность того, что «зеленая» задача будет выполнена в течении 3-х дней? На графике общее количество таких задач M = 10, а количество задач в диапазоне до 3-х дней N = 8. Таким образом, вероятность того, что «зеленая» задача будет выполнена в течении трех дней, будет равна P = 8 / 10 = 0,8 или 80%. Что мы и можем обоснованно сказать заказчику.
Аналогично посчитаем с «красными» задачами: у нас есть 100% вероятность выполнить такую задачу за 11 дней и 77% вероятности — за 7 дней:

Так у нас появляются данные, на основе которых наши Бизнес-заказчик, Тимлид и Специалист могут делать обоснованные прогнозы выполнения задач. Это станет основой доверия между этими ролями, и у каждого из них будет уверенность в озвучиваемых сроках.
Но откуда же брать данные для такой статистики? И тут нам помогают те самые стикеры и доски. Всё это — инструменты сбора данных. Чем лучше мы спроектируем визуализацию рабочего процесса в виде рабочей доски, тем более богатую и достоверную статистику мы сможем собрать для анализа
Посмотрим на реальном кейсе
В компании Sokolov есть аналитический отдел, задачей которого является подготовка аналитических отчетов на ежедневной основе для шести бизнес-подразделений. Эти отчеты очень важны — на их основе принимаются управленческие решения. При этом каждый из шести заказчиков считает, что его отчет самый важный — и, конечно, хочет получить его раньше остальных.

В отношениях между заказчиками и аналитическим отделом было много недоверия и напряжения. Заказчики были недовольны сроками и их непредсказуемостью. Аналитики были недовольны постоянным давлением со стороны заказчиков, переработками и трудностями с «добыванием» данных от других отделов.
Мы начали с исследования их текущей рабочей доски, это была система YouTrack. Вместе с сотрудниками мы проанализировали, где на доске точка принятия обязательств, и где — точка отдачи обязательств.

Собрав данные по Lead Time за три месяца, мы увидели распределение по времени выполнения всех задач. Уже можно было давать первые вероятностные прогнозы. Но кое-что в данных у нас все еще вызывало вопросы:

На графике явно были видны несколько единичных значений, очень сильно отстоящие в стороне от остального массива значений. Эти аномалии стоило поисследовать. Мы повспоминали с ребятами, как велась работа по этим задачам, и какие события мешали закончить ее быстрее. Оказалось, что во всех случаях было одновременное стечение многих неудачных обстоятельств, которое редко случается вместе:
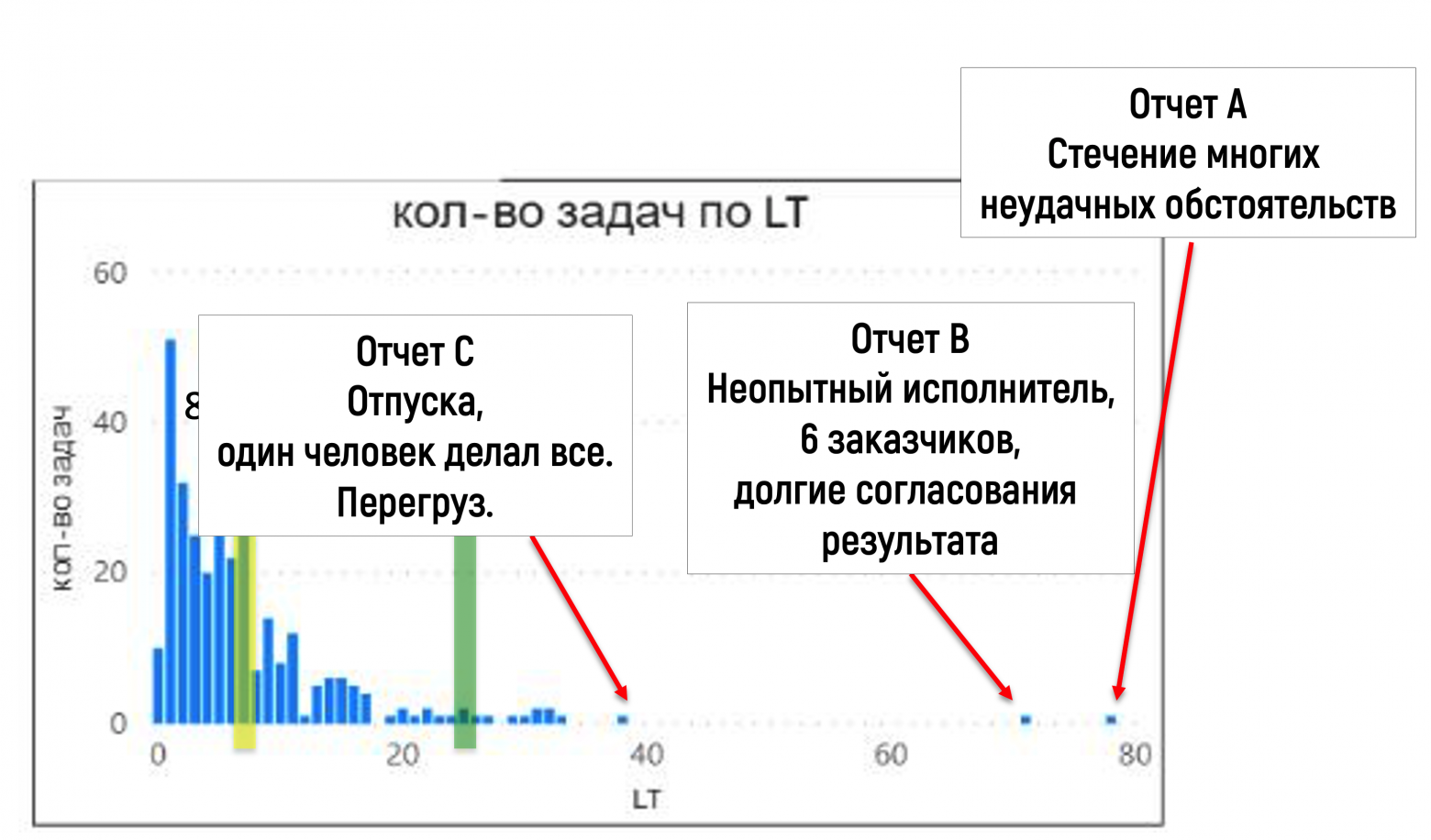
То есть эти аномальные значения не носили систематического характера, и их нельзя учитывать при долгосрочном прогнозе. Мы их отбросили, получив тем самым более достоверную картину:

Без аномалий статистика по задачам выглядела уже более привлекательно. Однако мы все еще оперировали данными по всем задачам, без деления на типы работ. Для большей точности прогноза мы посмотрели на «горбы» и, проанализировав эти данные, увидели повторяющиеся паттерны. Которые подтвердили, что присутствуют разные типы работ и статистику по ним стоит разделить:

Мы взяли самые характерные задачи из разных типов работ и построили графики распределения Lead Time по каждому из них:
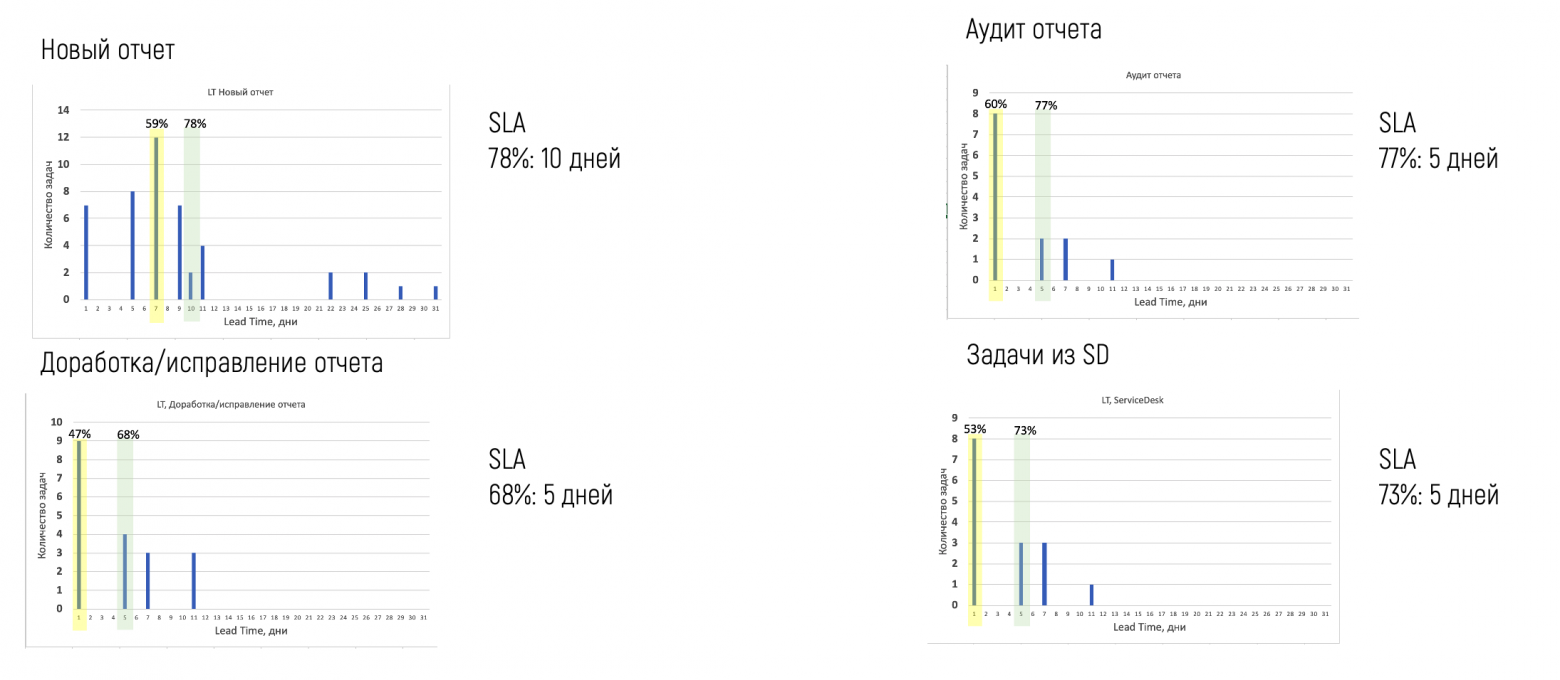
Эту статистику мы и показали бизнес-заказчикам. Разговор был непростым, но мы смогли заинтересовать нескольких из них, чтобы начать работать с ними на основе этих данных. Мы договорились с заказчиками об SLA по разным типам работ, и это стало ориентиром при планировании работ в будущем. Позже эту практику переняли и остальные заказчики.
Эффективность потока задач
Дополнительно мы решили собрать данные по реальному времени выполнения задачи: от момента, когда кто-то из сотрудников аналитического отдела освободился, взял задачу из колонки «Можно брать» и начал ее делать — и до перехода задачи, после ее приемки заказчиком, в колонку «Готово». Это время мы назвали Cycle Time:
Данные оказались любопытными — распределение по времени Cycle Time оказалось намного короче, чем Lead Time. То есть время, когда над задачей трудились специалисты отдела, было меньше, чем ожидание заказчика. Что означало: любая задача ждет в колонке «Можно брать» какое-то время, прежде чем освободившийся специалист начнет с ней что-то делать:
На практике это означало, что пропускная способность аналитического отдела меньше, чем частота поступления новых запросов от заказчиков. Грубо говоря, заказчики пытались «впихнуть» в аналитический отдел больше задач, чем он мог «переварить» в единицу времени. Представление заказчиков о возможностях аналитического отдела были нереалистичными:

Для проверки мы собрали данные о медианном времени, которое задача проводила в разных колонках:
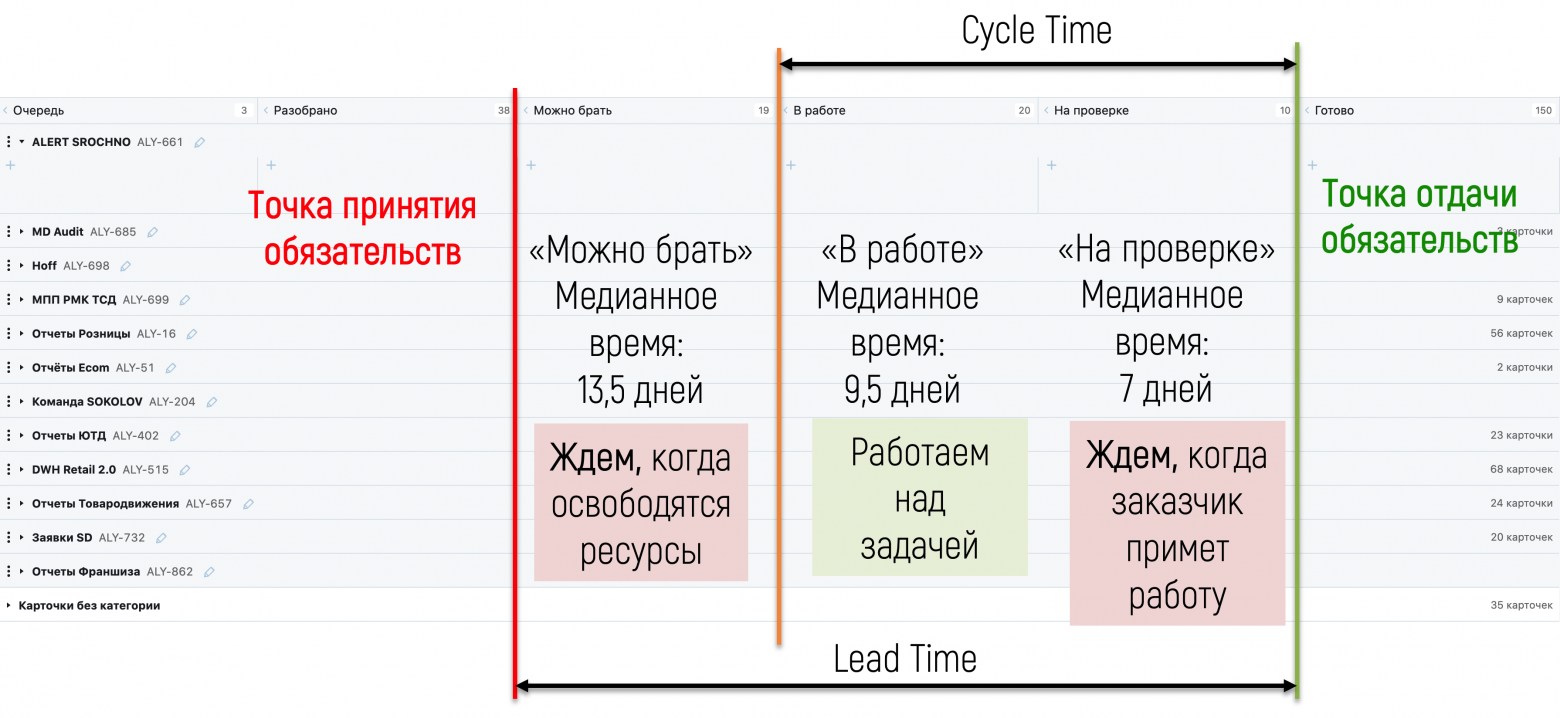
Получилось, что около 13,5 дней задача была в ожидании, пока освободится специалист, и еще 7 дней ждала, когда заказчик примет работу. Работа над задачей занимала 9,5 дней. Двадцать дней ожидания против девяти с половиной дней работы — весьма красноречивое и неприятное соотношение. И при этом заказчики могли непосредственно повлиять на уменьшение времени приемки задач, сократив Lead Time на 23%. В результате мы договорились с заказчиками о частоте пополнения входящей очереди задач, чтобы не перегружать отдел.
Визуализируем скрытое
Было и еще кое-что, что нам стоило прояснить: колонка «В работе» не давала деталей происходящего. Задача просто там «висела», и всё, что можно было отследить — это сколько времени она там была. Мы решили дифференцировать статистику по этой колонке, и заглянуть внутрь рабочего процесса.
С помощью сотрудников мы визуализировали их рабочий процесс — как он проходил на самом деле, и он получился довольно сложным. Но даже в этом сложном процессе мы смогли выделить повторяющиеся этапы:
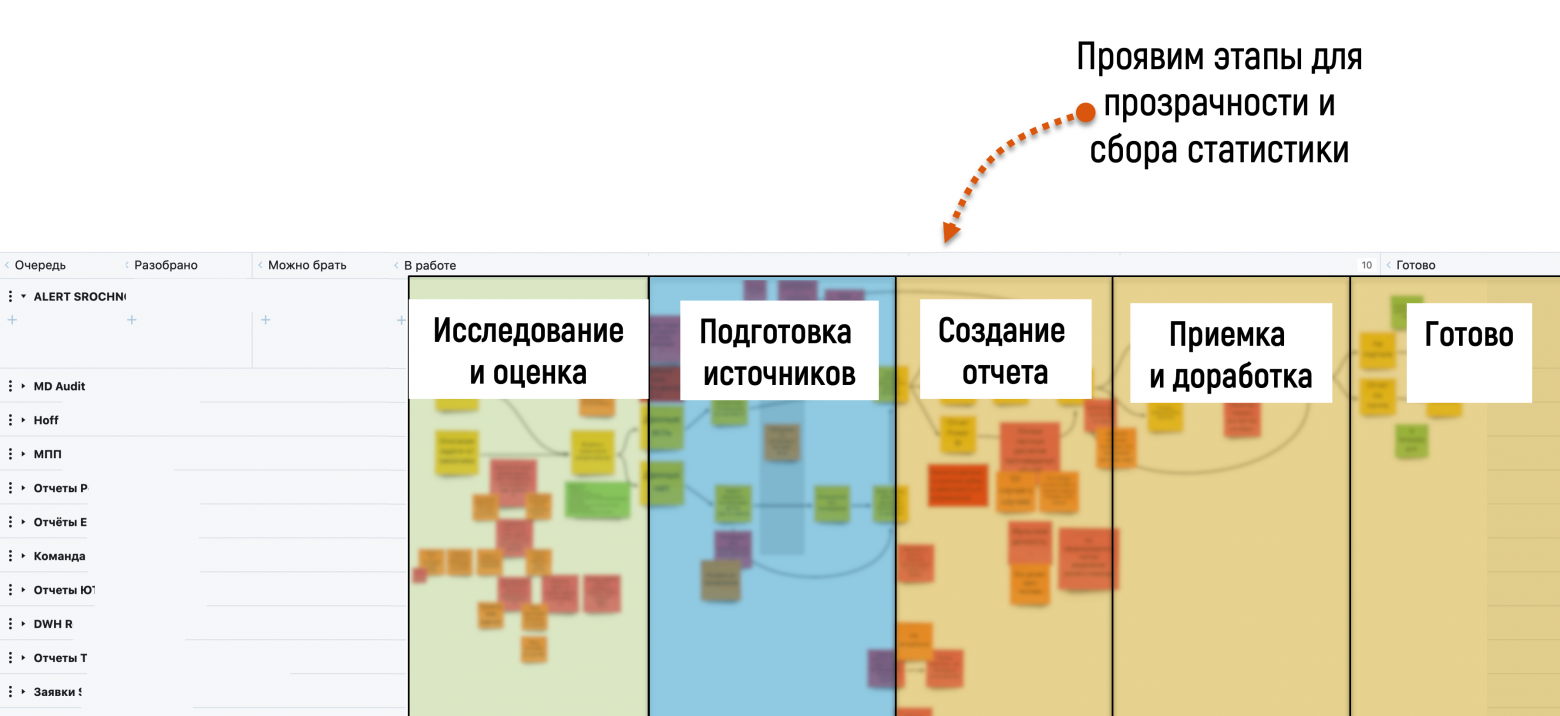
Благодаря этому прояснилось, что одной из главных причин задержек было не настроенное взаимодействие с другими отделами, от которых нужно было получать данные для формирования отчетов. Чтобы это решить, мы собрали статистику по «блокерам» — событиям, которые препятствуют выполнению задачи в данный момент. Например, утром на планерке, дата-инженер озвучивает, что он не может продолжать работу по задаче, так как не получил доступов к данным 1С — за которые отвечает другой отдел. С точки зрения Канбан-метода это событие и есть «блокер».
Мы визуализировали все «блокеры» на доске, отметили их причины и ответственных за снятие этих блокировок. И главное — отметили количество дней, которое каждый «блокер» не давал продвинуться в выполнении задачи. «Блокеры» мы коллекционировали и собирали в течение двух месяцев, после чего их сгруппировали:

Внутренние «блокеры» находились в зоне контроля аналитического отдела — их можно устранить, оптимизировав рабочий процесс. Другая группа лежала вне зоны влияния отдела, то есть это были внешние «блокеры». Среди них были и «блокеры», которые произошли по причине ожидания ответа или выполнения задачи от других отделов: 1С, логистики, финансового отдела. Эти данные мы показали руководителям отделов и с некоторыми смогли договориться о правилах игры, взаимном информировании и SLA на выполнение задач. Эти SLA аналитический отдел стал учитывать при планировании своей работы и закладывать в свои сроки. Данные по отделам, с которыми не смогли договориться, мы подняли на уровень генерального директора, и это сдвинуло проблему с мертвой точки.
С чего вам стоит начать?
Если вас заинтересовал данный метод, то первое, с чего вам стоит начать — сбор данных с вашего трекера задач. У вас наверняка есть какой-то рабочий процесс. Может быть, не идеальный, но он есть. Вам нужно определиться с точкой принятия обязательств и точкой отдачей обязательств. Без их определения собранная статистика будет неточной и бесполезной.

Если у вас пока нет трекера задач, но есть хотя бы физическая рабочая доска, то на ней вы тоже сможете собирать статистику, просто это будет чуть сложнее. Отмечайте на стикере время начала работы (когда стикер пересекает точку принятия обязательств). А когда задача пересекает точку отдачи обязательств — вписывайте время завершения. Коллекционируйте стикеры работы в течение пары месяцев, и вы сможете построить диаграмму распределения времени выполнения работ (Lead Time Distribution Chart):
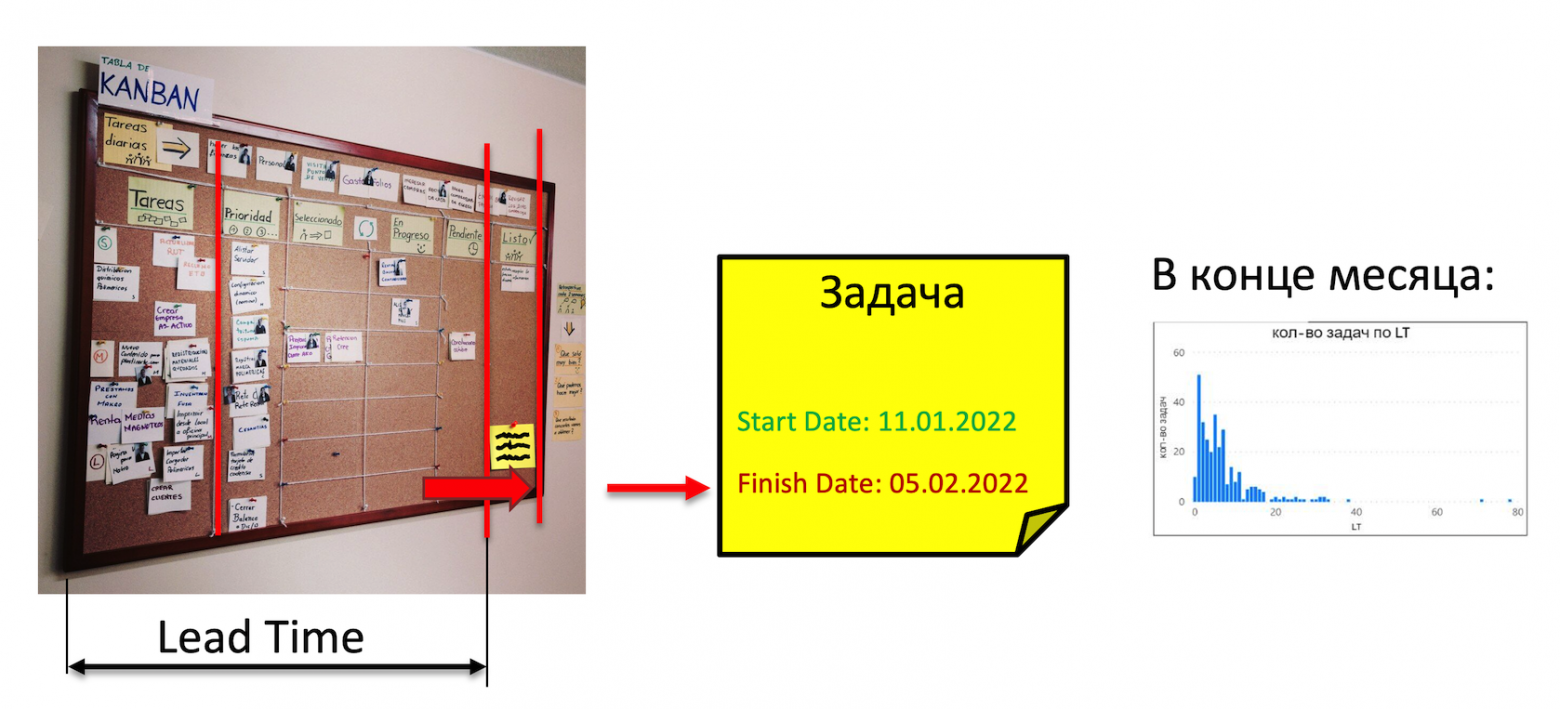
Какую вероятность выбрать?
100% вероятность прогноза выполнения задачи означает, что вы учитываете всё, что может повлиять на проект. Включая цунами, землетрясения, падение метеорита и прочие форс-мажорные обстоятельства. Это всегда пессимистичный срок. Но он может быть полезен, если у вас есть задача с не сдвигаемым сроком (регуляторное требование, например) и вам важно оценить, успеваете вы или нет.
Для большинства бизнес-задач достаточно срока с вероятностью 80-90%. У таких задач есть «желательный срок» и ошибка в 10-20% не так существенна. Тем не менее это всегда предмет разговора с заказчиками, так как только они знают реалии своего бизнеса и потребности в точности прогноза.
А что, если у нас Scrum?
Если вы работаете по Scrum, то может показаться, что все вышеописанное не для вас. Конечно, если у вас все задачи, взятые в одном спринте, в нем же и заканчиваются — у вас абсолютно предсказуемый рабочий процесс, в котором Lead Time по любой задаче равен длине спринта.
Но обычно есть задачи, которые выполняются несколько спринтов. А это означает, что и в вашем случае есть некоторое вероятностностное распределение времени выполнения задач. Вопрос в том, знаете ли вы его? Сбор статистики по Lead Time проявит для вас реальное положение вещей и поможет с оценкой больших задач.
Как правило, большие задачи трудно оценивать в Story Point, потому что в них много неопределенности. Но если вы соберете статистику Lead Time по всем задачам, вы сможете лучше понимать возможности вашей Scrum-команды и точнее оценивать сроки задач.
Что почитать
Книги, которые я рекомендую к изучению
«Визуализируйте работу» Доминики Деграндис — о том, как правильно проектировать рабочую доску, чтобы хорошо собирать статистику.
«Канбан метод» Майка Барроуза — для тех, кто хочет разобраться в Канбан-методе. Книга хорошо написана, и автор подробно разбирает много нюансов.
Так же рекомендую посмотреть видео про Канбан-метод на сайте LeanKanban.ru, и обзоры книг про Канбан-метод
Для более глубокого погружения приглашаю вас посетить тренинг “Основы Канбан-систем” где мы на примере кейсов и с помощью симуляционных игр подробно разбираем механики Канбан-метода и его применение для решения проблем.
В Санкт-Петербурге 26-27 сентября пройдет Saint TeamLead Conf 2022. Это единственная профессиональная конференция только для тимлидов. Много вдохновляющих идей, каждый доклад — решение конкретной задачи.
Билеты можно купить здесь.
