 Добрый день, Хаброжители!
Добрый день, Хаброжители!Кем бы вы ни были — инженером-программистом, стремящимся войти в мир глубокого обучения, опытным специалистом по обработке данных или любителем, мечтающим создать «вирусное» приложение с использованием ИИ, — наверняка задавались вопросом: с чего начать? Практические примеры из этой книги научат вас создавать приложения глубокого обучения для облачных, мобильных и краевых (edge) систем. Если вы хотите создать что-то необычное, полезное, масштабируемое или просто классное — эта книга для вас.
Многолетний опыт исследований в области глубокого обучения и разработки приложений позволяют авторам научить каждого воплощать идеи в нечто невероятное и необходимое людям в реальном мире.
В этой книге вы:
• Узнаете, как обучать, настраивать и развертывать модели компьютерного зрения с помощью Keras, TensorFlow, Core ML и TensorFlow Lite.
• Изучите интересные проекты, в том числе Not Hotdog из сериала Silicon Valley и еще более 40 примеров.
• Смоделируете беспилотный автомобиль в видеоигровом окружении и создадите миниатюрную версию, использовав технологию обучения с подкреплением.
• Научитесь использовать перенос обучения для быстрого обучения моделей.
• Найдете более 50 практических советов по повышению точности и скорости модели, отладке и масштабированию до многомиллионной аудитории.
Кому подойдет эта книга
Разработчикам
Скорее всего, вы опытный программист. Даже если вы не знакомы с Python, мы надеемся, что с легкостью освоите его и сможете приступить к работе в кратчайшие сроки. Но мы не предполагаем у вас наличие какого-либо опыта в области машинного обучения и искусственного интеллекта.
Мы поможем обрести вам эти знания и уверены, что вы извлечете пользу, узнав из этой книги:
• как создавать продукты c ИИ, ориентированные на пользователя;
• как быстро обучать модели;
• как минимизировать усилия и объем кода, нужные для создания прототипа;
• как сделать модели более производительными и энергоэффективными;
• как внедрять и масштабировать модели глубокого обучения, а также оценивать связанные с этим затраты;
• как применять ИИ на практике на примере более 40 реальных проектов;
• в каких направлениях развиваются знания о глубоком обучении;
• об обобщенных приемах, которые предлагают новые фреймворки (например, PyTorch), предметных областях (например, здравоохранение, робототехника), видах входной информации (например, видео, аудио, текст) и задачах (например, сегментация изображений, обучение с одного раза).
Специалистам по данным
Возможно, вы уже хорошо разбираетесь в машинном обучении и знаете, как работать с моделями глубокого обучения. Тогда у нас хорошие новости. Вы сможете еще больше обогатить набор своих навыков и углубить знания в этой области, которые позволят создавать настоящие продукты.
Эта книга расскажет вам, как эффективнее решать повседневные задачи, а также:
• как ускорить обучение, в том числе в кластерах с множеством нод;
• как развить интуицию, нужную для разработки и отладки моделей, включая настройку гиперпараметров для значительного повышения их точности;
• как работает модель, как выявить предвзятость в данных, а также как автоматически подобрать лучшие гиперпараметры и архитектуру модели с помощью AutoML;
• даст советы и приемы от других практиков, в том числе касающиеся быстрого сбора данных, организации экспериментов, обмена моделями с другими специалистами во всем мире и получения самой свежей информации о лучших доступных моделях для вашей задачи;
• как использовать инструменты для развертывания и масштабирования своей лучшей модели для реальных пользователей, и даже автоматически (без участия DevOps-команды).
Студентам
Сейчас самое время подумать о будущей карьере в области ИИ — это следующая революционная технология после появления интернета и смартфонов. Здесь уже достигнуты большие успехи, но многое еще предстоит открыть. Надеемся, что эта книга станет для вас первым шагом к карьере в области ИИ и, что еще лучше, к развитию более глубоких теоретических знаний. Самое замечательное, что не нужно тратить много денег на покупку дорогостоящего оборудования — можно тренироваться на мощном оборудовании совершенно бесплатно, пользуясь лишь браузером (спасибо, Google Colab!).
Надеемся, что с помощью этой книги вы:
• начнете карьеру в области ИИ, познакомившись с пакетом интересных проектов;
• обретете знания и навыки, которые помогут подготовиться к стажировке и устройству на работу;
• дадите волю своему творчеству, создавая забавные приложения, например автопилот для автомобиля;
• станете чемпионом состязания «AI for Good» (ИИ во имя добра) и используете свой творческий потенциал для решения насущных проблем, с которыми сталкивается человечество.
Преподавателям
Надеемся, что эта книга поможет разнообразить ваш курс забавными проектами из реального мира. Мы подробно рассматриваем каждый этап пайплайна глубокого обучения, а также эффективные и действенные методы выполнения каждого этапа. Все проекты, представленные в книге, могут пригодиться для совместной или индивидуальной работы в течение семестра. А еще мы подготовили презентации на https://github.com/PracticalDL/Practical-Deep-Learning-Book, которые можно брать для занятий.
Энтузиастам робототехники
Робототехника — это увлекательно. Если вы энтузиаст робототехники, то не нужно убеждать вас в том, что наделение роботов интеллектом — неминуемый шаг. Все функциональные аппаратные платформы: Raspberry Pi, NVIDIA Jetson Nano, Google Coral, Intel Movidius, PYNQ-Z2 и другие — помогают внедрению инноваций в области робототехники. По мере развития промышленной революции 4.0 некоторые из этих платформ будут становиться все более актуальными и повсеместными.
Из этой книги вы узнаете:
• как создать и обучить ИИ, а затем довести его до совершенства;
• как тестировать и сравнивать краевые устройства по производительности, размеру, мощности, энергоэффективности и стоимости;
• как выбрать оптимальный алгоритм ИИ и устройство для конкретной задачи;
• как другие производители создают творческих роботов и машины;
• как добиться дальнейшего прогресса в этой области и показать достижения.
Скорее всего, вы опытный программист. Даже если вы не знакомы с Python, мы надеемся, что с легкостью освоите его и сможете приступить к работе в кратчайшие сроки. Но мы не предполагаем у вас наличие какого-либо опыта в области машинного обучения и искусственного интеллекта.
Мы поможем обрести вам эти знания и уверены, что вы извлечете пользу, узнав из этой книги:
• как создавать продукты c ИИ, ориентированные на пользователя;
• как быстро обучать модели;
• как минимизировать усилия и объем кода, нужные для создания прототипа;
• как сделать модели более производительными и энергоэффективными;
• как внедрять и масштабировать модели глубокого обучения, а также оценивать связанные с этим затраты;
• как применять ИИ на практике на примере более 40 реальных проектов;
• в каких направлениях развиваются знания о глубоком обучении;
• об обобщенных приемах, которые предлагают новые фреймворки (например, PyTorch), предметных областях (например, здравоохранение, робототехника), видах входной информации (например, видео, аудио, текст) и задачах (например, сегментация изображений, обучение с одного раза).
Специалистам по данным
Возможно, вы уже хорошо разбираетесь в машинном обучении и знаете, как работать с моделями глубокого обучения. Тогда у нас хорошие новости. Вы сможете еще больше обогатить набор своих навыков и углубить знания в этой области, которые позволят создавать настоящие продукты.
Эта книга расскажет вам, как эффективнее решать повседневные задачи, а также:
• как ускорить обучение, в том числе в кластерах с множеством нод;
• как развить интуицию, нужную для разработки и отладки моделей, включая настройку гиперпараметров для значительного повышения их точности;
• как работает модель, как выявить предвзятость в данных, а также как автоматически подобрать лучшие гиперпараметры и архитектуру модели с помощью AutoML;
• даст советы и приемы от других практиков, в том числе касающиеся быстрого сбора данных, организации экспериментов, обмена моделями с другими специалистами во всем мире и получения самой свежей информации о лучших доступных моделях для вашей задачи;
• как использовать инструменты для развертывания и масштабирования своей лучшей модели для реальных пользователей, и даже автоматически (без участия DevOps-команды).
Студентам
Сейчас самое время подумать о будущей карьере в области ИИ — это следующая революционная технология после появления интернета и смартфонов. Здесь уже достигнуты большие успехи, но многое еще предстоит открыть. Надеемся, что эта книга станет для вас первым шагом к карьере в области ИИ и, что еще лучше, к развитию более глубоких теоретических знаний. Самое замечательное, что не нужно тратить много денег на покупку дорогостоящего оборудования — можно тренироваться на мощном оборудовании совершенно бесплатно, пользуясь лишь браузером (спасибо, Google Colab!).
Надеемся, что с помощью этой книги вы:
• начнете карьеру в области ИИ, познакомившись с пакетом интересных проектов;
• обретете знания и навыки, которые помогут подготовиться к стажировке и устройству на работу;
• дадите волю своему творчеству, создавая забавные приложения, например автопилот для автомобиля;
• станете чемпионом состязания «AI for Good» (ИИ во имя добра) и используете свой творческий потенциал для решения насущных проблем, с которыми сталкивается человечество.
Преподавателям
Надеемся, что эта книга поможет разнообразить ваш курс забавными проектами из реального мира. Мы подробно рассматриваем каждый этап пайплайна глубокого обучения, а также эффективные и действенные методы выполнения каждого этапа. Все проекты, представленные в книге, могут пригодиться для совместной или индивидуальной работы в течение семестра. А еще мы подготовили презентации на https://github.com/PracticalDL/Practical-Deep-Learning-Book, которые можно брать для занятий.
Энтузиастам робототехники
Робототехника — это увлекательно. Если вы энтузиаст робототехники, то не нужно убеждать вас в том, что наделение роботов интеллектом — неминуемый шаг. Все функциональные аппаратные платформы: Raspberry Pi, NVIDIA Jetson Nano, Google Coral, Intel Movidius, PYNQ-Z2 и другие — помогают внедрению инноваций в области робототехники. По мере развития промышленной революции 4.0 некоторые из этих платформ будут становиться все более актуальными и повсеместными.
Из этой книги вы узнаете:
• как создать и обучить ИИ, а затем довести его до совершенства;
• как тестировать и сравнивать краевые устройства по производительности, размеру, мощности, энергоэффективности и стоимости;
• как выбрать оптимальный алгоритм ИИ и устройство для конкретной задачи;
• как другие производители создают творческих роботов и машины;
• как добиться дальнейшего прогресса в этой области и показать достижения.
Рецепт идеального решения задачи глубокого обучения
Прежде чем приступить к приготовлению блюд, Гордон Рамзи проверяет наличие всех ингредиентов. То же относится к решению задач с помощью глубокого обучения (рис. 1.8).
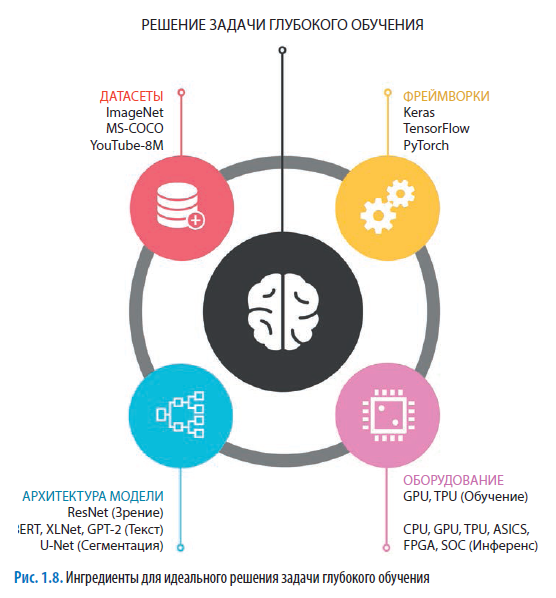
И вот ваш набор ингредиентов для глубокого обучения:
Датасет + Модель + Фреймворк + Оборудование = Решение задачи глубокого обучения
Рассмотрим каждый из них поближе.
Датасеты
Как моряк Попай страстно жаждет шпинат, так глубокое обучение страстно жаждет данных — много данных. Для выявления значимых закономерностей, которые помогают делать надежные прогнозы, нужны огромные объемы данных. В 1980-х и 1990-х годах нормой считалось традиционное машинное обучение, использовавшее сотни или тысячи образцов. Глубокие нейронные сети, построенные с нуля, напротив, требуют намного больше данных даже для типовых задач прогнозирования. Но в этом есть свой плюс — прогнозы получаются гораздо точнее.
Сейчас мы наблюдаем взрывной рост накопления данных: каждый день создаются квинтиллионы байтов данных — изображений, текста, видео, информации от датчиков и многого другого. Но чтобы использовать эти данные, нужны метки. Чтобы создать классификатор настроений, отделяющий положительные отзывы на Amazon от отрицательных, нужны тысячи таких отзывов с присвоенными им метками настроения. Чтобы обучить систему сегментации лица для Snapchat, нужны тысячи изображений, на которых точно отмечено расположение глаз, губ, носа и т. д. Чтобы обучить беспилотный автомобиль, нужны фрагменты видео, на которых показаны реакции человека-водителя на дорожную обстановку и его воздействие на органы управления автомобилем — тормоза, акселератор, рулевое колесо и т. д. Эти метки выступают в роли учителя нашего ИИ, и размеченные данные гораздо ценнее неразмеченных.
Создание меток может обходиться очень дорого. Неудивительно, что есть целая индустрия, которая занимается поиском исполнителей для решения задач разметки. Каждая метка стоит от нескольких центов до нескольких долларов, в зависимости от времени, потраченного исполнителем. Например, во время разработки датасета Microsoft COCO (Common Objects in Context — обычные объекты в контексте) требовалось примерно три секунды, чтобы присвоить метку с названием каждому объекту на изображении; примерно 30 секунд, чтобы определить ограничивающую рамку вокруг каждого объекта, и 79 секунд, чтобы обрисовать контур каждого объекта. Теперь представьте, что эти операции нужно произвести с сотнями тысяч изображений, и вы поймете, какие средства были вложены в создание некоторых из наиболее крупных датасетов. Отдельные компании, занимающиеся разметкой, — Appen и Scale.AI, уже оцениваются более чем в миллиард долларов каждая.
На нашем счете может не быть миллиона долларов. Но, к счастью для нас, в этой революции глубокого обучения произошло два хороших события.
- Крупные компании и университеты щедро поделились с нами, обнародовав гигантские наборы размеченных данных.
- Был разработан метод под названием «перенос обучения» (transfer learning), который позволяет настраивать модели с использованием небольших датасетов, насчитывающих всего несколько сотен образцов, при условии, что эти модели предварительно были обучены на более крупных наборах, аналогичных текущему. Мы неоднократно использовали этот метод в книге, в том числе в главе 5, где экспериментально доказали, что этот прием способен обеспечить достойное качество даже при наличии всего нескольких десятков обучающих образцов. Возможность переноса обучения развенчивает миф о том, что для обучения хорошей модели необходимы большие данные. Добро пожаловать в мир крошечных данных!
В табл. 1.2 перечислены некоторые из популярных датасетов для различных задач глубокого обучения.

Архитектура модели
Модель — это просто функция. Она принимает один или несколько входных параметров и возвращает результат. Входными данными могут быть текст, изображения, аудио, видео или что-то еще, а результатом является прогноз. Хорошей считается модель, прогнозы которой достаточно точно соответствуют ожидаемой реальности. Точность модели, обученной на некотором датасете, является основным определяющим фактором ее пригодности для реального использования. Для большинства это все, что нужно знать о моделях глубокого обучения. Но если заглянуть внутрь модели, взору откроется множество интересных деталей (рис. 1.9).

Внутри модели находится граф, состоящий из вершин и ребер. Вершины — это математические операции, а ребра представляют потоки данных между узлами. Другими словами, если выход одной вершины связать со входом одной или нескольких других вершин, то эти связи между вершинами будут представлены ребрами. Структура графа определяет потенциальную точность, скорость, количество потребляемых ресурсов (память, продолжительность вычислений и электроэнергия), а также тип входных данных, которые она может обрабатывать.
Расположение вершин и ребер определяется архитектурой модели. По сути, это план здания. Но кроме плана нужно еще само здание. Обучение — это строительство здания с помощью плана. Обучение модели происходит многократным выполнением нескольких этапов: 1) на вход подаются исходные данные; 2) извлекаются выходные данные; 3) определяется, насколько прогноз далек от ожидаемой реальности (то есть от меток, связанных с данными); затем 4) величина ошибки распространяется через модель в обратном направлении, чтобы она могла исправить себя. Этот процесс обучения повторяется снова и снова, пока не будет достигнут удовлетворительный уровень прогнозирования.
Результатом обучения является набор чисел (также известных как веса), которые присваиваются каждой из вершин. Эти веса являются необходимыми параметрами вершин в графе, обеспечивающими правильную обработку входных данных. Перед началом обучения весам обычно присваиваются случайные значения. Целью процесса обучения фактически является постепенная настройка значений этих весов, пока они не обеспечат получение удовлетворительных прогнозов.
Чтобы лучше понять, как работают веса, рассмотрим следующий датасет с двумя входами и одним выходом:
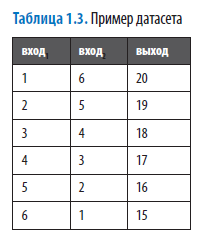
Применив методы линейной алгебры (или посчитав в уме), мы можем прийти к выводу, что этому датасету соответствует следующее уравнение:
выход = f(вход1, вход2) = 2 × вход1+ 3 × вход2.
В данном случае веса равны 2 и 3. Глубокая нейронная сеть имеет миллионы таких весовых параметров.
Разные типы используемых вершин определяют разные виды архитектур моделей, каждая из которых лучше подходит для входных данных определенного типа. Например, для анализа изображения и звука обычно используются сверточные нейронные сети (CNN), а для обработки текста — рекуррентные нейронные сети (RNN) и сети с долгой краткосрочной памятью (LSTM).
В общем случае обучение одной из таких моделей с нуля может потребовать довольно много времени, возможно, недели. К счастью, многие исследователи уже проделали всю тяжелую работу по обучению своих моделей на универсальных датасетах (например, ImageNet) и сделали их доступными для всех. Благодаря этому можно взять эти модели и настроить их для своего конкретного датасета. Этот процесс называется переносом обучения (transfer learning) и подходит для большинства практических потребностей.
По сравнению с обучением с нуля перенос обучения дает двойное преимущество: значительно сокращается время обучения (от нескольких минут до часов вместо недель), и он дает хорошие результаты даже при использовании относительно небольшого датасета (от сотен до тысяч образцов вместо миллионов). В табл. 1.4 перечислены некоторые примеры известных архитектур моделей.
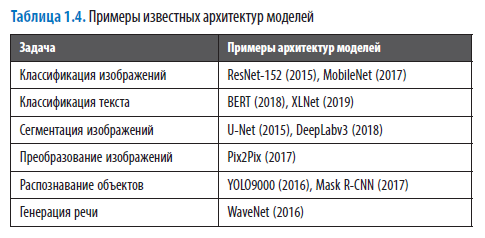
Для всех моделей, перечисленных в табл. 1.4, опубликованы показатели точности на эталонных датасетах (например, для моделей классификации — на наборе ImageNet, для моделей распознавания объектов — на наборе MS COCO). Кроме того, разные архитектуры имеют свои характерные требования к ресурсам (размер модели в мегабайтах или требование к производительности в виде количества операций с плавающей запятой в секунду — floating-point operations in second, FLOPS).
Подробнее о переносе обучения поговорим в следующих главах, а сейчас познакомимся с доступными фреймворками и сервисами глубокого обучения.

Об авторах
Анирад Коул (Anirudh Koul) — известный эксперт в области ИИ, спикер UN/TEDx и бывший старший научный сотрудник в Microsoft AI & Research, где он основал Seeing AI — после iPhone считается самой используемой технологией среди слабовидящих. Анирад возглавляет отдел искусственного интеллекта и исследований в компании Aira, признанной журналом Time одной из лучших компаний 2018 года в своей сфере. Он раскрыл новые возможности для миллиардов пользователей и имеет более чем десятилетний опыт прикладных исследований с использованием петабайтных наборов данных. Активно занимается разработкой технологий с использованием методов ИИ в сфере дополненной реальности, робототехники, речи, повышения производительности и доступности. Его работы, представленные на саммите AI for Good, которые в IEEE назвали «судьбоносными», удостоены наград от CES, FCC, MIT, Cannes Lions и Американского совета общества слепых; демонстрировались на мероприятиях ООН, Всемирного экономического форума, Белого дома, Палаты лордов, Netflix и National Geographic и заслужили похвалу мировых лидеров, включая Джастина Трюдо (Justin Trudeau) и Терезу Мэй (Theresa May).
Сиддха Ганджу (Siddha Ganju), исследователь ИИ, которого журнал Forbes включил в свой список «30 Under 30», является архитектором беспилотных автомобилей в NVIDIA. В качестве советника по ИИ в NASA FDL она помогла построить автоматизированный конвейер обнаружения метеоритов для проекта CAMS в NASA, с помощью которого была обнаружена комета. Ранее, работая в Deep Vision, Сиддха разрабатывала модели глубокого обучения для краевых устройств с ограниченными ресурсами. Занималась созданием самых разных систем, от поиска ответов на визуальные вопросы до генеративно-состязательных сетей и сбора информации из петабайтных массивов данных в CERN, сведения о которых публиковались на ведущих конференциях, включая CVPR и NeurIPS. Была членом жюри нескольких международных технических конкурсов, включая CES.
Мехер Казам (Meher Kasam) — опытный разработчик программного обеспечения, приложениями которого ежедневно пользуются десятки миллионов людей. В настоящее время занимается разработкой программного обеспечения для iOS в компании Square, а прежде работал в Microsoft и Amazon. Участвовал в создании ряда приложений для iPhone, от Square Point of Sale до Bing. В период работы в Microsoft руководил разработкой мобильного приложения Seeing AI, получившего широкое признание и награды от Mobile World Congress, CES, FCC, Американского совета общества слепых и многих других организаций. Хакер в душе, склонный к быстрому созданию прототипов, он выиграл несколько хакатонов и воплотил найденные решения во многие широко используемые продукты. Также является судьей международных конкурсов, в том числе Global Mobile Awards и Edison Awards.
Сиддха Ганджу (Siddha Ganju), исследователь ИИ, которого журнал Forbes включил в свой список «30 Under 30», является архитектором беспилотных автомобилей в NVIDIA. В качестве советника по ИИ в NASA FDL она помогла построить автоматизированный конвейер обнаружения метеоритов для проекта CAMS в NASA, с помощью которого была обнаружена комета. Ранее, работая в Deep Vision, Сиддха разрабатывала модели глубокого обучения для краевых устройств с ограниченными ресурсами. Занималась созданием самых разных систем, от поиска ответов на визуальные вопросы до генеративно-состязательных сетей и сбора информации из петабайтных массивов данных в CERN, сведения о которых публиковались на ведущих конференциях, включая CVPR и NeurIPS. Была членом жюри нескольких международных технических конкурсов, включая CES.
Мехер Казам (Meher Kasam) — опытный разработчик программного обеспечения, приложениями которого ежедневно пользуются десятки миллионов людей. В настоящее время занимается разработкой программного обеспечения для iOS в компании Square, а прежде работал в Microsoft и Amazon. Участвовал в создании ряда приложений для iPhone, от Square Point of Sale до Bing. В период работы в Microsoft руководил разработкой мобильного приложения Seeing AI, получившего широкое признание и награды от Mobile World Congress, CES, FCC, Американского совета общества слепых и многих других организаций. Хакер в душе, склонный к быстрому созданию прототипов, он выиграл несколько хакатонов и воплотил найденные решения во многие широко используемые продукты. Также является судьей международных конкурсов, в том числе Global Mobile Awards и Edison Awards.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — Интеллект
