Самая важная составляющая машинного обучения – это данные. Насколько бы ни были хороши модель и метод обучения, если обучающая выборка мала или не описывает большую часть случаев реального мира – добиться высокого качества работы будет почти невозможно. При этом сама задача создания обучающих датасетов является отнюдь не простой и не всем подходит, так как помимо долгого и изнурительного аннотирования данных людьми обычно требуется дополнительное финансирование этого процесса.
Аугментация, или генерирование новых данных на основе имеющихся, позволяет довольно просто и дешево решить часть проблем с обучающей выборкой подручными способами. В случае нейронных сетей, распространенным явлением стало встраивать аугментацию непосредственно в процесс обучения, модифицируя данные каждую эпоху. Однако, в очень малом числе статей акцентируется внимание на важности такого подхода и том, какие свойства он привносит в процесс обучения. В этой статье мы разберем, что полезного можно извлечь из аугментации на лету, и насколько критичен выбор преобразований и их параметров в рамках такого подхода.
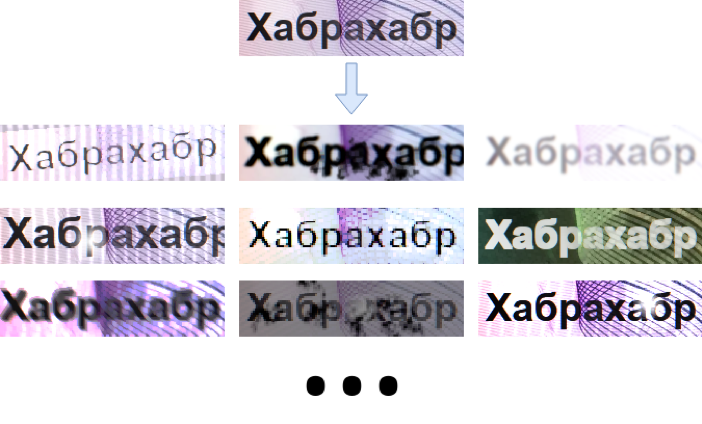
Аугментация: офлайн или онлайн?
Термин “аугментация”, который можно перевести как “увеличение” или “раздутие”, используется в машинном обучении уже давно. В мало каких инженерных или научных задачах наблюдался избыток данных, ввиду чего приходилось замещать отсутствующие данные модификациями имеющихся. Например, в случае данных в виде фотографий – условия съемки, артефакты камеры, деформации объектов и многие другие искажения успешно имитируются методами обработки изображений. За счет такого моделирования деформаций можно легко добиться увеличения качества модели и повысить ее устойчивость к различным шумам во входных данных.
Изначально, аугментация использовалась в так называемом “офлайн” формате – данные искажались единожды перед обучением и докладывались к имеющимся обучающим данным. Недостатки очевидны: требуется гораздо больше места на жестком диске для хранения аугментированной выборки, при этом вариативность данных все еще жестко ограничена. С наступлением эпохи нейросетей, аугментацию стали активно встраивать прямо в процесс обучения. Часть данных из датасета искажается между итерациями, и за счет этого сеть всегда видит “новые” данные, без увеличения объема обучающей выборки на диске. Так, например, одним из первых ярких применений аугментации на лету стало обучение уже ныне классической сети AlexNet, которая с большим отрывом выиграла соревнование по распознаванию ImageNet в 2012 году. Для того, чтобы избежать простоев в ожидании следующей порции данных для обучения, используется распараллеливание: аугментация каждого следующего батча выполняется на CPU, параллельно с тем, как сеть обучается на GPU. Блок-схема такой параллелизации приведена на рисунке 1.
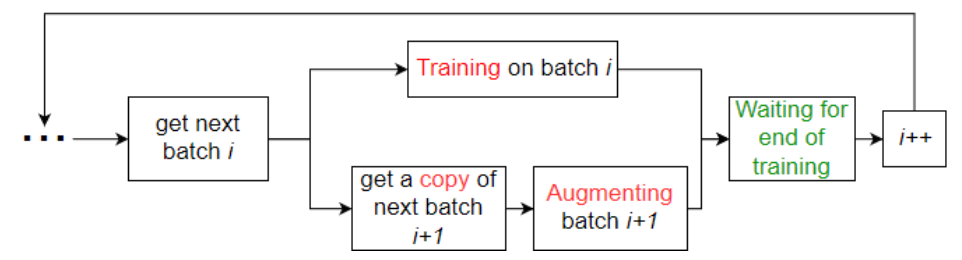
Рис. 1. Блок-схема работы аугментации на лету
Таким образом, аугментация на лету является не только отличным методом увеличения качества сети, но и не замедляет обучение. Однако, она также добавляет несколько дополнительных свойств, которые могут оказать существенное влияние на процесс обучения сетей.
Синтез данных и аугментация на лету позволяют создавать неограниченные обучающие выборки
Одним из существенных преимуществ аугментации на лету является значительное увеличение разнообразия в данных: за все время обучения сеть может увидеть все возможные реализации и комбинации заданных нами преобразований. Но здесь необходимо оговориться: используя только аугментацию, мы все еще ограничены допустимыми функциями модификации данных. Имея фотографию автомобиля, мы можем смоделировать размытие в движении, различные цвета, даже погодные условия – но при этом ракурс съемки, например, все еще остается фиксированным.
И в этом месте появляется еще один термин из науки о данных: синтез данных. На сегодня мы имеем возможность моделировать довольно реалистичные изображения самых разных объектов, будь то текст, фотографии дорог или даже танки (спасибо игровым движкам и наработкам в компьютерной графике). Таким образом, подвязав к обучению не только аугментацию, но еще и синтез данных, мы имеем возможность обучаться на выборке безграничного размера! При этом, роль аугментации здесь будет не только в моделировании различных условий получения картинки, но и в нивелировании несовершенства алгоритмов синтеза. На рисунке 2 показано, насколько становится вариативна синтетическая выборка с использованием аугментации.

Рис. 2. Аугментация значительно повышает вариативность синтезированного изображения текста
Правильная аугментация значительно увеличивает качество
Как правило, параметры аугментации выбираются “на глаз” на основе просмотренных данных и не меняются в процессе обучения. Однако, в отличии от офлайн подхода, аугментация на лету более чувствительна к параметрам заданных преобразований. Некорректно настроенные искажения будут стабильно портить картинки из обучающей выборки на протяжении всего времени обучения, а главное – уследить за этим относительно сложно. Поэтому, правильный подбор параметров является одной из приоритетных проблем аугментации на лету, и в этой области ведется некоторое количество исследований (например, AutoAugment от Google, который автоматически подбирает параметры по ходу обучения). Один из самых простых способов контроля аугментации на лету – отписывание ошибок сети во время обучения с последующим добавлением или настройкой искажений. Такая настройка на лету может помочь получить хорошо работающую сеть за максимально короткое время, без ее переобучения с нуля или дополнительного дообучения ради, например, большей устойчивости к размытым изображениям.
Аналогично важны и сами используемые преобразования. Редко когда в статьях рассматриваются новые искажения, которые могут помочь в решении определенной задачи: чаще всего используются дефолтные повороты/размытия/отражения. Отсюда второй посыл – многие задачи требуют специфичных искажений, которые позволят еще дальше продвинуть качество модели, не прибегая к усложнению архитектуры. Так, например, при распознавании текста могут быть полезны нелинейные деформации изображений символов вдоль оси (AxialWarp), накладывание случайных структурных элементов для имитации неоднородностей фона (RandStructElem) или нелинейное изменение яркости случайной монотонной функцией [1] (BrightnessMod). Примеры этих функций приведены на рисунке 3.

Рис. 3. Специфичные для задачи преобразования позволяют улучшить качество без увеличения размера модели
Однако, при подборе преобразований могут возникать ситуации, когда одновременное применение нескольких из них портит данные. Поэтому, также крайне важно настраивать еще и параметры их применения, например:
- указание вероятностей применения;
- вынос схожих искажений в разные наборы преобразований, или, как их иногда называют, политики аугментации (например, для исключения одновременного применения гауссового размытия вместе с размытием движения);
- введение некоторой константы, которая будет уменьшать вероятность применения последующих искажений с учетом уже применившихся. Например, при применении каждого следующего преобразования, вероятность применения остальных умножается на 0.9.
Подобные простые модификации позволяют тонко настраивать аугментацию (причем прямо во время обучения), делая ее полностью применимой для любых данных, будь они синтетическими или натуральными (испортить которые гораздо проще). Совокупность выше приведенных мер, например, позволили довольно легко получить 10% сокращение числа ошибок на датасете SVHN (Street View House Numbers, классификация цифр номеров домов, полученных с Google Street View), что показано в таблице 1. В качестве модели сети мы использовали SimpleNet [2] – простую LeNet подобную архитектуру, содержащую небольшое число параметров, но способную выдавать приемлемое качество работы. Причем для достижения этого результата мы использовали только аугментацию, без каких изменений в архитектуре или процессе обучения. Примеры аугментированных картинок приведены на рисунке 4.
Таблица 1. Результаты обучения SimpleNet на SVHN
| Архитектура, число коэффициентов | Error rate, без аугментации | Error rate, с аугментацией на лету |
| SimpleNet, 310 тыс. | 2.37% | 2.17% |

Рис. 4. Исходные (первый столбец) и аугментированные изображения из датасета SVHN
Аугментация позволяет упростить модель, сохранив качество
Чем больше данных, тем меньше можно думать о локальных особенностях датасета и учить более глобальные признаки. Аугментация на лету, как уже говорилось выше, как раз позволяет порождать бесконечное множество условий получения данных, тем самым увеличивая обучающую выборку. Видя постоянно новые данные, сеть не может настраивать лишние фильтры для выцепления специфичных особенностей конкретного набора данных, и поэтому появляется смысл уменьшения числа параметров в сети – будь то предварительное облегчение архитектуры или прореживание уже обученной модели.
Чтобы продемонстрировать этот эффект аугментации, мы взяли за основу известную ResNet-подобную архитектуру [3] в двух модификациях, отличающихся числом параметров и умножений (что было достигнуто только за счет изменения числа фильтров в сверточных слоях, топология сохранена). Описание архитектуры приведено на рисунке 5. В качестве датасета использовался SVHN. Обучив эти две сети, мы получили, что аугментация на лету позволяет легкой модели сравняться по качеству с тяжелой, обученной без аугментации (см. таблицу 2). При этом легкая сеть более чем в 2 раза компактнее – как по числу умножений, так и по количеству коэффициентов! Этот эксперимент явно показывает, насколько высока эффективность аугментации, особенно в случае легких сетей.
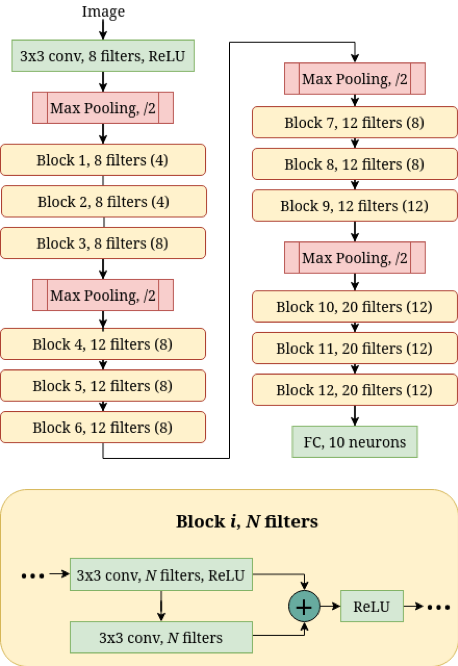
Рис. 5. Архитектура базовой ResNet-подобной сети. Число в скобках — количество фильтров в блоке в облегченной версии этой архитектуры
Таблица 2. Результаты обучения ResNet на SVHN
| Архитектура w: число коэффициентов mul: число умножений |
Error rate, без аугментации | Error rate, с аугментацией на лету |
| ResNet, w: 40 тыс., mul: 1.63 млн. | 5.68% | 5.06% |
| ResNet, w: 18 тыс., mul: 730 тыс. | 6.71% | 5.73% |
Заключение
Аугментация является одним из главных инструментов для улучшения качества сетей. Будучи встроенной в процесс обучения, она добавляет ему новые свойства, среди которых – большая чувствительность сети к параметрам преобразований, а также потенциал к уменьшению архитектуры с сохранением качества. И если первое важно учитывать при общем повышении качества сети, то второе критично для получения компактных и простых сетей, которые могут быть использованы в мобильных устройствах.
Также, мы вновь возвращаемся к проблеме правильной настройки аугментации. Так как универсального критерия “правильности” в данном случае не существует, набор преобразований всегда задается исходя из специфики конкретной задачи. И вместо утяжеления архитектуры и прочих подходов с усложнением процесса обучения, в первую очередь всегда необходимо анализировать датасет и попытаться смоделировать встречающиеся в нем артефакты – ведь данные, а не архитектура, играют главную роль в получении хорошо работающей сети.
Данный пост сделан с использованием материалов доклада с международной конференции по машинному зрению ICMV 2018 (Германия, г. Мюнхен): Gayer, A., Chernyshova, Y., & Sheshkus, A. (2019). Effective real-time augmentation of training dataset for the neural networks learning. Proceedings of SPIE, 11041, 110411I-110411I-8
Литература
- Емельянов С.О. Методы аугментации обучающих выборок в задачах классификации изображений / Емельянов С.О., Иванова А.А., Швец Е.А., Николаев Д.П. // Сенсорные системы. 2018. Т. 32. № 3
- Hasanpour S. H., Rouhani M., Mohsen F., Sabokrou M. Let’s keep it simple, Using simple architectures to outperform deeper and more complex architectures // ArXiv e-prints https://arxiv.org/abs/1608.06037
- K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. // ArXiv e-prints https://arxiv.org/abs/1512.03385
