В начале 2018 года у нас активно пошел процесс цифровизации производства и процессов в компании. В секторе нефтехимии это не просто модный тренд, а новый эволюционный шаг в сторону повышения эффективности и конкурентоспособности. Учитывая специфику бизнеса, который и без всякой цифровизации показывает неплохие экономические результаты, перед «цифровизаторами» стоит непростая задача: всё-таки менять устоявшиеся процессы в компании — довольно кропотливая работа.
Наша цифровизация началась с создания двух центров и соответствующих им функциональных блоков.
Это «Функция цифровых технологий», в которую включены все продуктовые направления: цифровизация процессов, IIoT и продвинутая аналитика, а также центр управления данными, ставший самостоятельным направлением.

И вот как раз главная задача дата-офиса заключается в том, чтобы полноценно внедрить культуру принятия решений, основанных на данных (да, да, data-driven decision), а также в принципе упорядочить всё, что касается работы с данными: аналитика, обработка, хранение и отчетность. Особенность в том, что все наши цифровые инструменты должны будут не только активно использовать собственные данные, то есть те, которые генерируют сами (например, мобильные обходы, или датчики IIoT), но и внешние данные, с четким пониманием, где и зачем их нужно использовать.
Меня зовут Артем Данилов, я руководитель направления «Инфраструктура и технологии» в СИБУРе, в этом посте я расскажу, как и на чем мы строим большую систему обработки и хранения данных для всего СИБУРа. Для начала поговорим только о верхнеуровневой архитектуре и о том, как можно стать частью нашей команды.





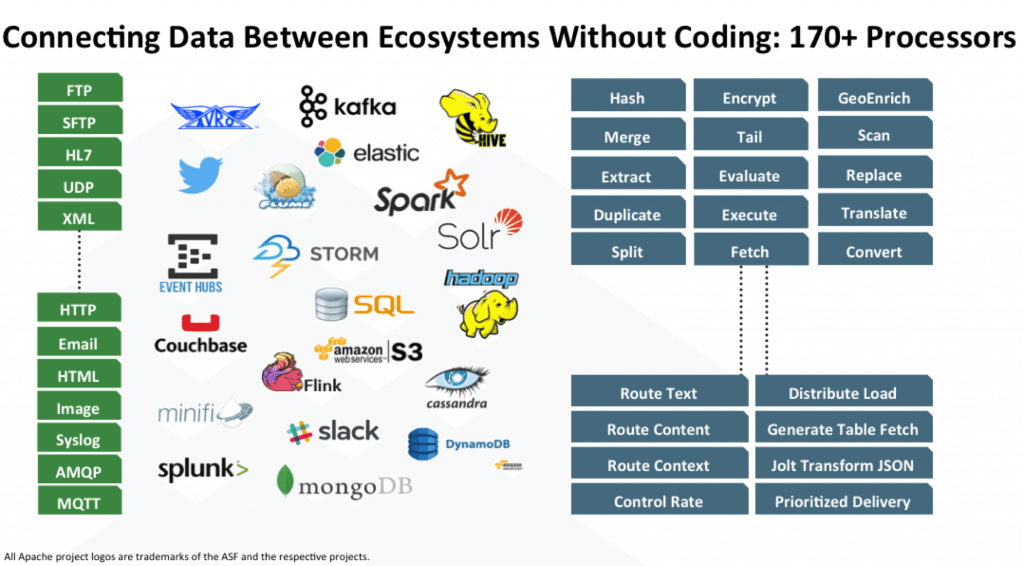





 Зачем эта статья?
Зачем эта статья? Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших».
Есть в технических кругах шутка, что «Большие данные» это данные, для обработки которых недостаточно Excel 2010 на мощном ноутбуке. То есть если для решения задачи вам надо оперировать 1 миллионом строк на листе и более или 16 тысяч столбцов и более, то поздравляем, ваша данные относятся к разряду «Больших». Конечно, на слово мне никто верить не должен, поэтому специально для Хабра я сорвался на самолёт в Москву, чтобы пообщаться с начальником отдела разработки спецпроектов в Сбербанк-Технологиях. Вадим Сурпин потратил на меня чуть больше часа, а в этом интервью будут только самые важные мысли из нашего разговора. Кроме того, удалось уговорить Вадима подать заявку на участие в
Конечно, на слово мне никто верить не должен, поэтому специально для Хабра я сорвался на самолёт в Москву, чтобы пообщаться с начальником отдела разработки спецпроектов в Сбербанк-Технологиях. Вадим Сурпин потратил на меня чуть больше часа, а в этом интервью будут только самые важные мысли из нашего разговора. Кроме того, удалось уговорить Вадима подать заявку на участие в