Big Data головного мозга
14 мин
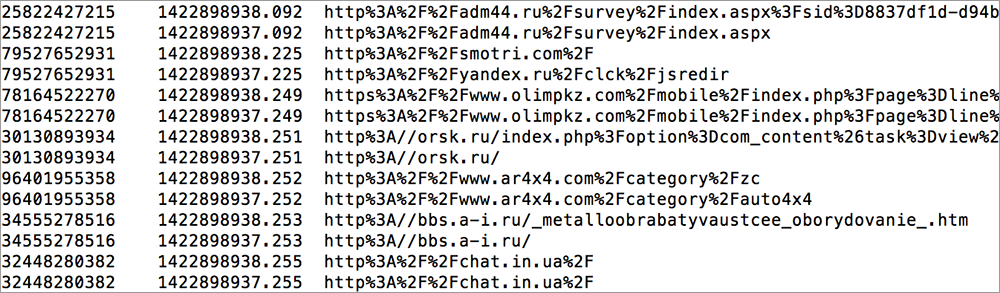
Наверно, в мире данных нет подобного феномена настолько неоднозначного понимания того, что же такое Hadoop. Ни один подобный продукт не окутан таким большим количеством мифов, легенд, а главное непонимания со стороны пользователей. Не менее загадочным и противоречивым является термин "Big Data", который иногда хочется писать желтым шрифтом(спасибо маркетологам), а произносить с особым пафосом. Об этих двух понятиях — Hadoop и Big Data я бы хотел поделиться с сообществом, а возможно и развести небольшой холивар.
Возможно статья кого-то обидит, кого-то улыбнет, но я надеюсь, что не оставит никого равнодушным.

Демонстрация Hadoop пользователям











 [@tsafin — Обладателя
[@tsafin — Обладателя