Некоторые современные подходы в области обработки естественного языка
4 мин
Результаты научных исследований, полученные в последние годы в задачах распознавания речи [1], машинного перевода [2], определения оттенка предложения [3] и частей речи [4] показали перспективность нейросетевых алгоритмов глубокого обучения в сравнении с классическими методами обработки естественного языка (natural language processing). Однако, в области вопросно-ответных и диалоговых систем еще остается много нерешенных задач [5, 6]. В данной статье дан обзор результатов применения современных алгоритмов для задач обработки и понимания естественного языка. Обзор содержит описание нескольких разных подходов и не претендует на полноту исследований.

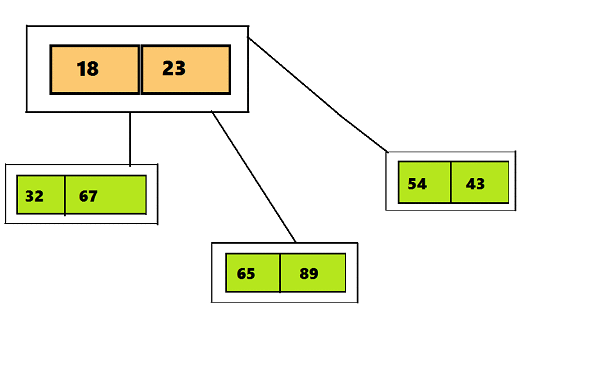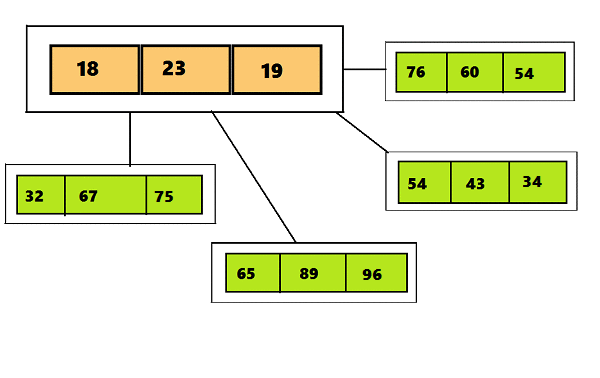
Human: how many legs does a cat have ?
Machine: four, i think .
Human: What do you think about messi ?
Machine: he ’s a great player .
Human: where are you now ?
Machine: i ’m in the middle of nowhere .
(из статьи A Neural Conversational Model. КДПВ из фильма Ex Machina)
Human: how many legs does a cat have ?
Machine: four, i think .
Human: What do you think about messi ?
Machine: he ’s a great player .
Human: where are you now ?
Machine: i ’m in the middle of nowhere .
(из статьи A Neural Conversational Model. КДПВ из фильма Ex Machina)