Этот пост написан по мотивам лекции Джеймса Смита, профессора Висконсинского университета в Мадисоне, специализирующегося в микроэлектронике и архитектуре вычислительных машин.
История компьютерных наук в целом сводится к тому, что учёные пытаются понять, как работает человеческий мозг, и воссоздать нечто аналогичное по своим возможностям. Как именно учёные его исследуют? Представим, что в XXI веке на Землю прилетают инопланетяне, никогда не видевшие привычных нам компьютеров, и пытаются исследовать устройство такого компьютера. Скорее всего, они начнут с измерения напряжений на проводниках, и обнаружат, что данные передаются в двоичном виде: точное значение напряжения не важно, важно только его наличие либо отсутствие. Затем, возможно, они поймут, что все электронные схемы составлены из одинаковых «логических вентилей», у которых есть вход и выход, и сигнал внутри схемы всегда передаётся в одном направлении. Если инопланетяне достаточно сообразительные, то они смогут разобраться, как работают
комбинационные схемы — одних их достаточно, чтобы построить сравнительно сложные вычислительные устройства. Может быть, инопланетяне разгадают роль тактового сигнала и обратной связи; но вряд ли они смогут, изучая современный процессор, распознать в нём фон-неймановскую архитектуру с общей памятью, счётчиком команд, набором регистров и т.п. Дело в том, что по итогам сорока лет погони за производительностью в процессорах появилась целая иерархия «памятей» с хитроумными протоколами синхронизации между ними; несколько параллельных конвейеров, снабжённых предсказателями переходов, так что понятие «счётчика команд» фактически теряет смысл; с каждой командой связано собственное содержимое регистров, и т.д. Для реализации микропроцессора достаточно нескольких тысяч транзисторов; чтобы его производительность достигла привычного нам уровня, требуются сотни миллионов. Смысл этого примера в том, что для ответа на вопрос «как работает компьютер?» не нужно разбираться в работе сотен миллионов транзисторов: они лишь заслоняют собой простую идею, лежащую в основе архитектуры наших ЭВМ.
Моделирование нейронов
Кора человеческого мозга состоит из порядка ста миллиардов нейронов. Исторически сложилось так, что учёные, исследующие работу мозга, пытались охватить своей теорией всю эту колоссальную конструкцию. Строение мозга описано иерархически: кора состоит из долей, доли — из
«гиперколонок», те — из
«миниколонок»… Миниколонка состоит из примерно сотни отдельных нейронов.
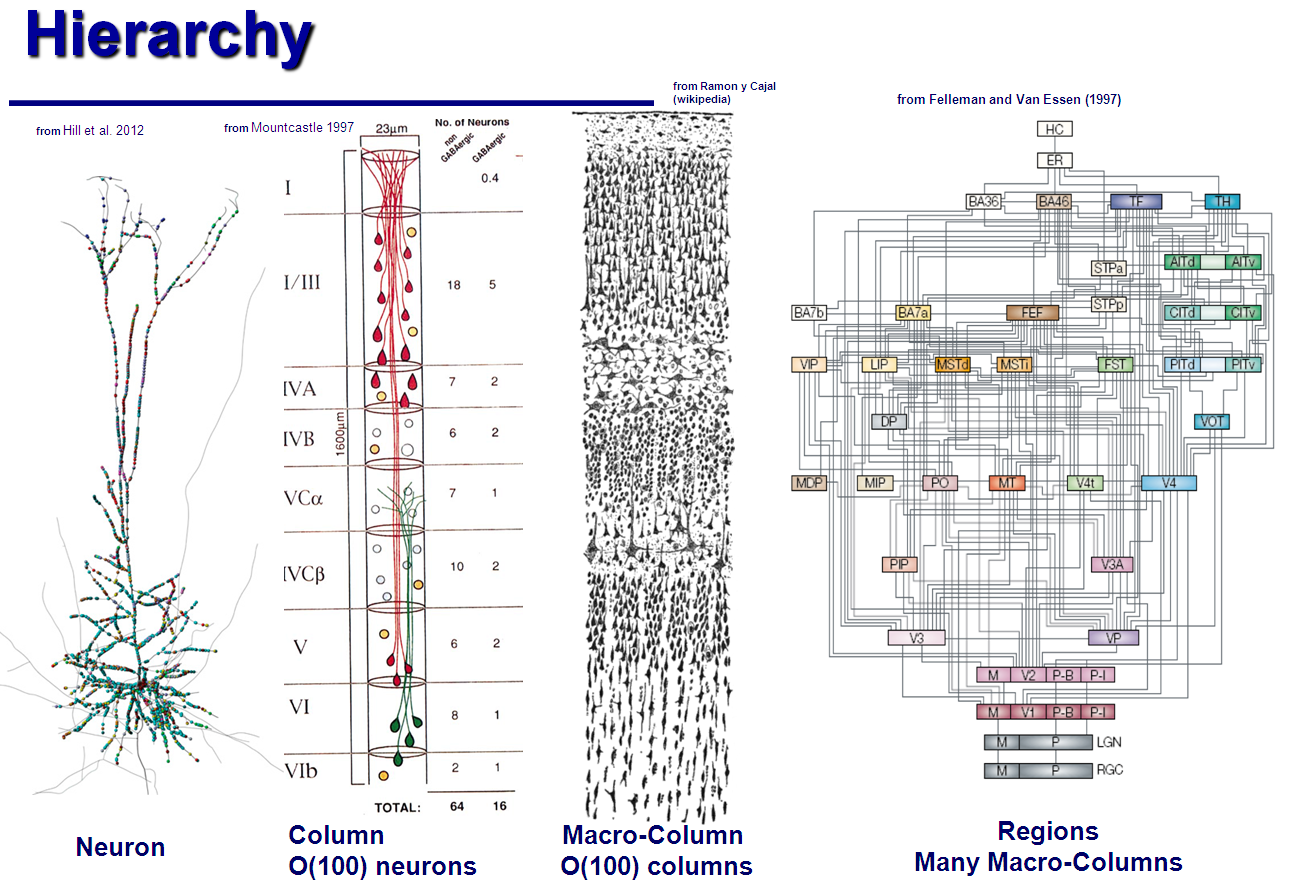
По аналогии с устройством компьютера, абсолютное большинство этих нейронов нужны для скорости и эффективности работы, для устойчивости ко сбоям, и т.п.; но основные принципы устройства мозга так же невозможно обнаружить при помощи микроскопа, как невозможно обнаружить счётчик команд, рассматривая под микроскопом микропроцессор. Поэтому более плодотворный подход — попытаться понять устройство мозга на самом низком уровне, на уровне отдельных нейронов и их колонок; и затем, опираясь на их свойства — попытаться предположить, как мог бы работать мозг целиком. Примерно так пришельцы, поняв работу логических вентилей, могли бы со временем составить из них простейший процессор, — и убедиться, что он эквивалентен по своим способностям настоящим процессорам, даже хотя те намного сложнее и мощнее.