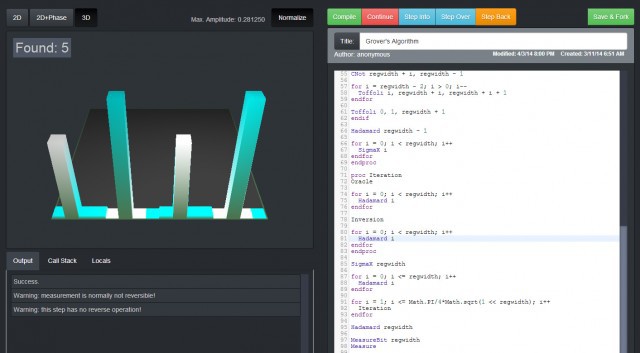
Обзор некоторых MOOC Coursera по компьютерным наукам
3 мин
Скорее всего, если вы зашли на Хабр и читаете эту статью, то хоть раз в жизни да слышали про MOOC-курсы.
Но если все же не слышали, то MOOC (по-русски принято произносить «мук») означает «Massive Open Online Course» — массовый открытый онлайн-курс. Это настоящий феномен в образовании XXI века. Газета «New York Times» назвала даже 2012 год «годом MOOC» в связи с появлением на рынке дистанционного образования 3-х «китов» — Coursera, Udacity и EdX. MOOC-ам посвящено множество статей, кто-то видит в них будущее образования, кто-то, наоборот, угрозу. Пытаются также предсказать «традиционную» и «дистанционную» составляющии обучения будущего.






Однако в этой статье я не буду обсуждать перспективы развития дистанционного образования, а расскажу про свой опыт знакомства с курсами на платформе Coursera. Эти курсы будут полезны студентам, изучающим прикладную математику и информатику, в особенности анализ данных. Многое из того, что мне дали эти курсы, как я потом понял — это знания, которыми должен обладать любой уважающий себя исследователь данных (так я предпочитаю переводить профессию Data Scientist).
Но если все же не слышали, то MOOC (по-русски принято произносить «мук») означает «Massive Open Online Course» — массовый открытый онлайн-курс. Это настоящий феномен в образовании XXI века. Газета «New York Times» назвала даже 2012 год «годом MOOC» в связи с появлением на рынке дистанционного образования 3-х «китов» — Coursera, Udacity и EdX. MOOC-ам посвящено множество статей, кто-то видит в них будущее образования, кто-то, наоборот, угрозу. Пытаются также предсказать «традиционную» и «дистанционную» составляющии обучения будущего.
Однако в этой статье я не буду обсуждать перспективы развития дистанционного образования, а расскажу про свой опыт знакомства с курсами на платформе Coursera. Эти курсы будут полезны студентам, изучающим прикладную математику и информатику, в особенности анализ данных. Многое из того, что мне дали эти курсы, как я потом понял — это знания, которыми должен обладать любой уважающий себя исследователь данных (так я предпочитаю переводить профессию Data Scientist).



 Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно,
Сегодня мы посмотрим на структуру данных, называемую Scapegoat-деревом. «Scapegoat», кто не в курсе, переводится как «козёл отпущения», что делает дословный перевод названия структуры каким-то странным, поэтому будем использовать оригинальное название. Деревьев поиска, как вы, возможно,