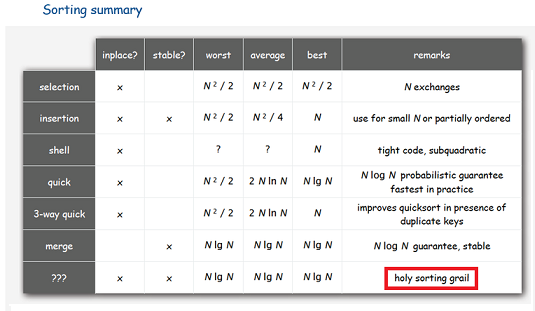
Моделирование простейшего потока
2 мин
Всего с помощью двух слов можно охарактеризовать такие вещи, как
и многое другое. Всё это называется «простейший поток».
Очевидно, что количество вызовов на станции, автомобилей на магистралиявляются случайными в каждый момент времени. Учитывая то, что все три вещи из списка являются довольно важными для всего общества и для его оптимального существования, необходимо научиться моделировать этот поток.
Особенно актуальным является последний пункт приведённого списка, поскольку юзеры, не знающие простых основ компьютера, успевают их нереально задолбать, а зная параметры потока, можно спрогнозировать их количество.
- поток вызовов на телефонной станции
- поток автомобилей на магистрали
- поток абонентов, звонящих в техподдержку
и многое другое. Всё это называется «простейший поток».
Очевидно, что количество вызовов на станции, автомобилей на магистралиявляются случайными в каждый момент времени. Учитывая то, что все три вещи из списка являются довольно важными для всего общества и для его оптимального существования, необходимо научиться моделировать этот поток.
Особенно актуальным является последний пункт приведённого списка, поскольку юзеры, не знающие простых основ компьютера, успевают их нереально задолбать, а зная параметры потока, можно спрогнозировать их количество.


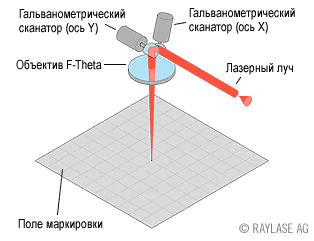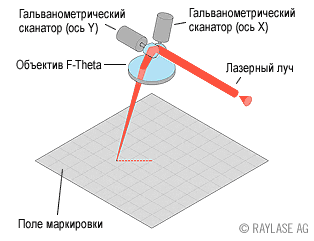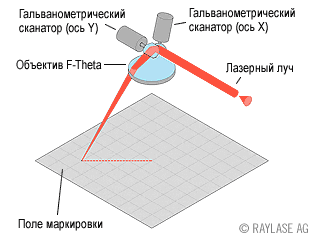

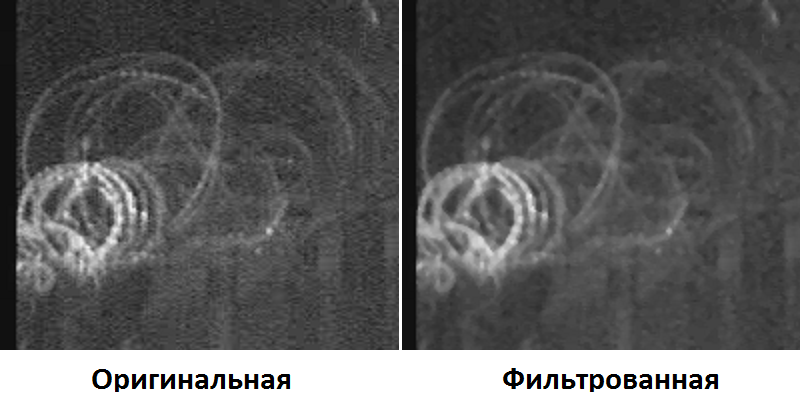
 В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.
В задаче распознавания ключевую роль играет выделение значимых параметров объектов и оценка их численных значений. Тем не менее, даже получив хорошие численные данные, нужно суметь правильно ими воспользоваться. Иногда кажется, что дальнейшее решение задачи тривиальное, и хочется «из общих соображений» получить из численных данных результат распознавания. Но результат в этом случае получается далеко не оптимальный. В этой статье я хочу на примере задачи распознавания показать, как можно легко применить простейшие математические модели и за счет этого существенно улучшить результаты.