Случайный генератор буквоцифр и его варианты
9 мин
Обратиться к теме написания случайных генераторов букв навела мысль о том, что в JS существует нетипичная нативная функция преобразования строки в n-ичное число, где n = 2..36. 36 в стандарте языка придумано не случайно — это сумма количества цифр и малых английских букв, из которых предлагается писать такие числа. Это значит, что парой нативных функций уже можно построить полезный генератор небольших строк из буквоцифр.
Это значит, что для некоторых задач можно не писать относительно честные генераторы на основе унылых строк вида «abcdefghijklmno...».
Math.random().toString(36) //даст числа вида 0.816cwugw2ky, 0.opgqwav8w1m, 0.f0w4ejtq8wk, ...
Это значит, что для некоторых задач можно не писать относительно честные генераторы на основе унылых строк вида «abcdefghijklmno...».
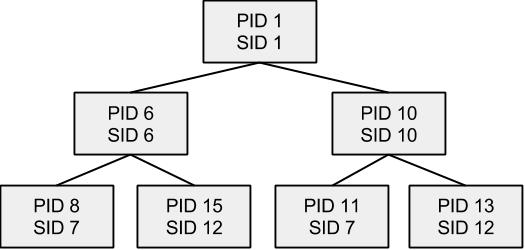
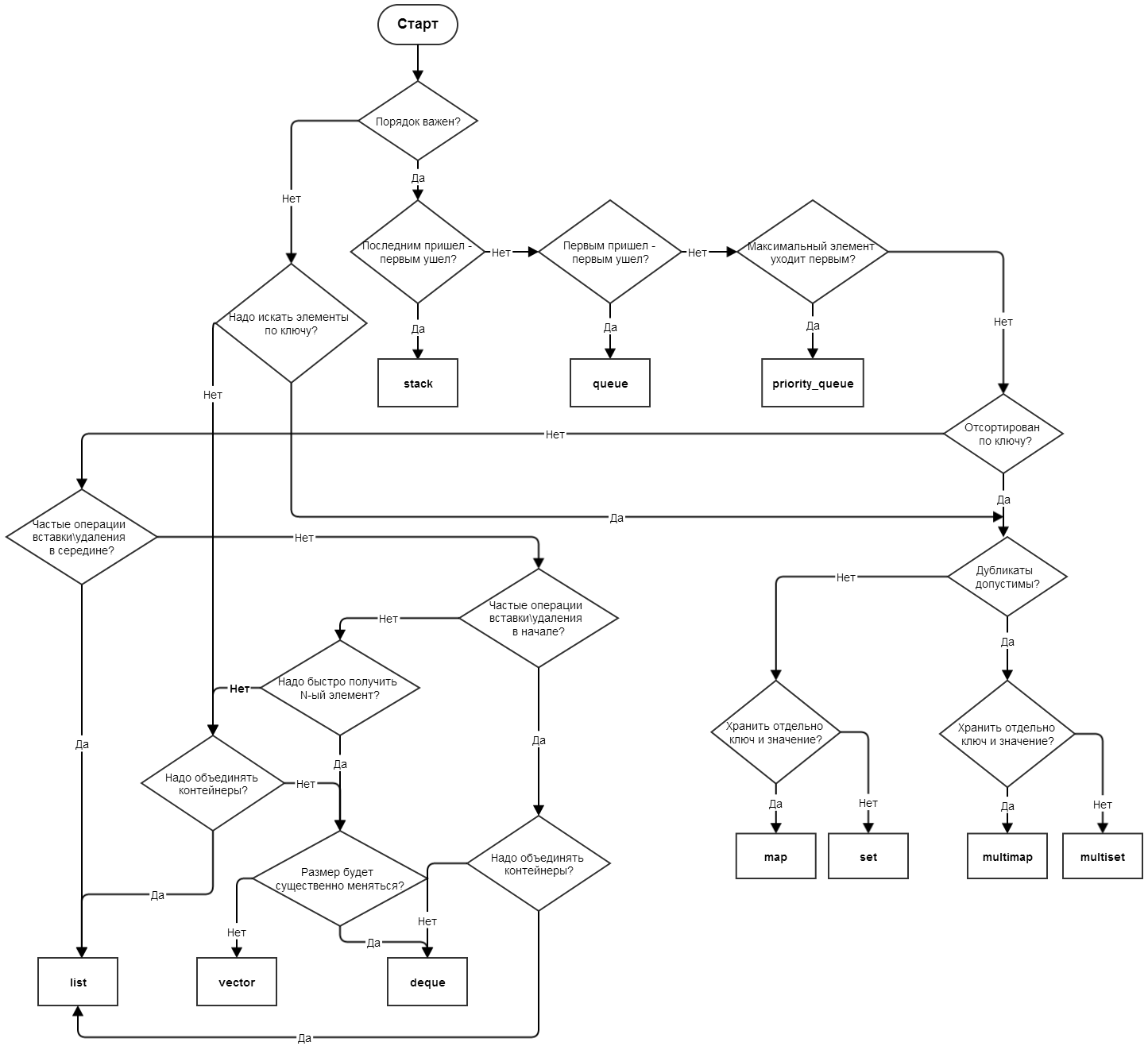
 Сидел я как-то дома, читал
Сидел я как-то дома, читал 


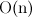 . Здесь я приведу доказательство этого факта.
. Здесь я приведу доказательство этого факта.