Апдейт для тех, кто сочтет статью полезной и занесет в избранное. Есть приличный шанс, что пост уйдет в минуса, и я буду вынужден унести его в черновики. Сохраняйте копию!
Краткий и несложный материал для неспециалистов, рассказывающий в наглядной форме о различных методах поиска регрессионных зависимостей. Это все и близко не академично, зато надеюсь что понятно. Прокатит как мини-методичка по обработке данных для студентов естественнонаучных специальностей, которые математику знают плохо
, впрочем как и автор. Расчеты в Матлабе, подготовка данных в Экселе — так уж повелось в нашей местности

Введение
Зачем это вообще надо? В науке и около нее очень часто возникает задача предсказания какого-то неизвестного параметра объекта исходя из известных параметров этого объекта (предикторов) и большого набора похожих объектов, так называемой учебной выборки. Пример. Вот мы выбираем на базаре яблоко. Его можно описать такими предикторами: красность, вес, количество червяков. Но как потребителей нас интересует вкус, измеренный в попугаях по пятибалльной шкале. Из жизненного опыта нам известно, что вкус с приличной точностью равен 5*красность+2*вес-7*количество червяков. Вот про поиск такого рода зависимостей мы и побеседуем. Чтобы обучение пошло легче, попробуем предсказать вес девушки исходя из ее 90/60/90 и роста.

 Несколько дней назад на xkcd.com был опубликован
Несколько дней назад на xkcd.com был опубликован 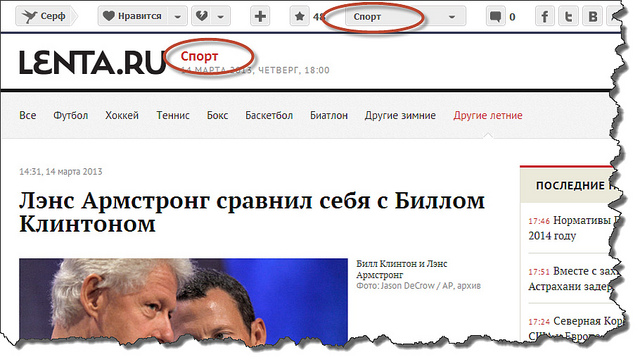
 В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект
В настоящей заметке я расскажу о том, как можно построить систему оптического распознавания структурной информации, опираясь на алгоритмы, применяющиеся в обработке изображений и их реализации в рамках библиотеки OpenCV. За описанием системы стоит активно развивающийся open source проект 

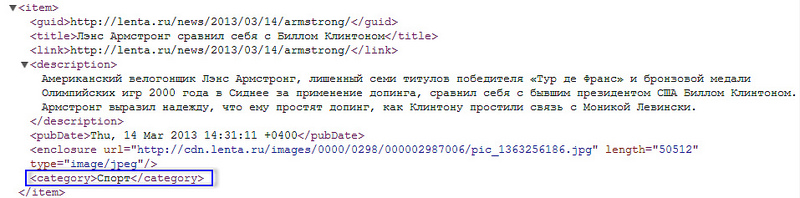
 Один из сотрудников Google в свободное время разработал новый алгоритм сжатия
Один из сотрудников Google в свободное время разработал новый алгоритм сжатия 